本文一定要阅读我上篇文章!!!
超详细VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客
本文是基于上篇文章遗留下的问题进行说明的。
一、本文解决的问题
问题1:我明明只部署了qwen3-4B的模型,为什么启动VLLM推理框架后能占到显存的0.9,占了22GB显存?
问题2:VLLM框架部署Qwen3-4B的GPU最小配置应该是多少,怎么计算?
问题3:VLLM框架预留更多的GPU资源对模型推理速度影响多大?
问题4:并发处理10-20人的访问本地模型请求,GPU配置应该怎么计算,怎么分配?
二、解决问题1
问题1:我明明只部署了qwen3-4B的模型,为什么启动VLLM推理框架后能占到显存的0.9,占了22GB显存?
官网回答图片,可以知道VLLM框架是预置了0.9的显存给这个模型,但是模型实际不一定需要要那么多显存。还有最大输入的token默认值是40960,正常我们输入的长文本不需要那么大。

因此可以自定义分配GPU显存给VLLM服务,测试一下,当然你分配的显存越少,推理速度越慢。
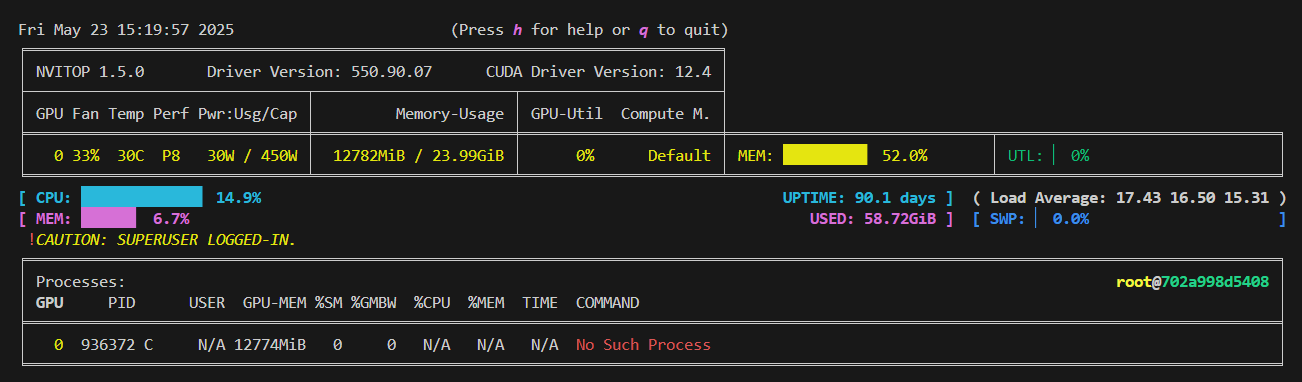
比如我分配了0.5的显存重启VLLM服务,就可以看到分配的显存就是0.5左右。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
三、解决问题2
问题2:VLLM框架部署Qwen3-4B的GPU最小配置应该是多少,怎么计算?
执行完下述命令后
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
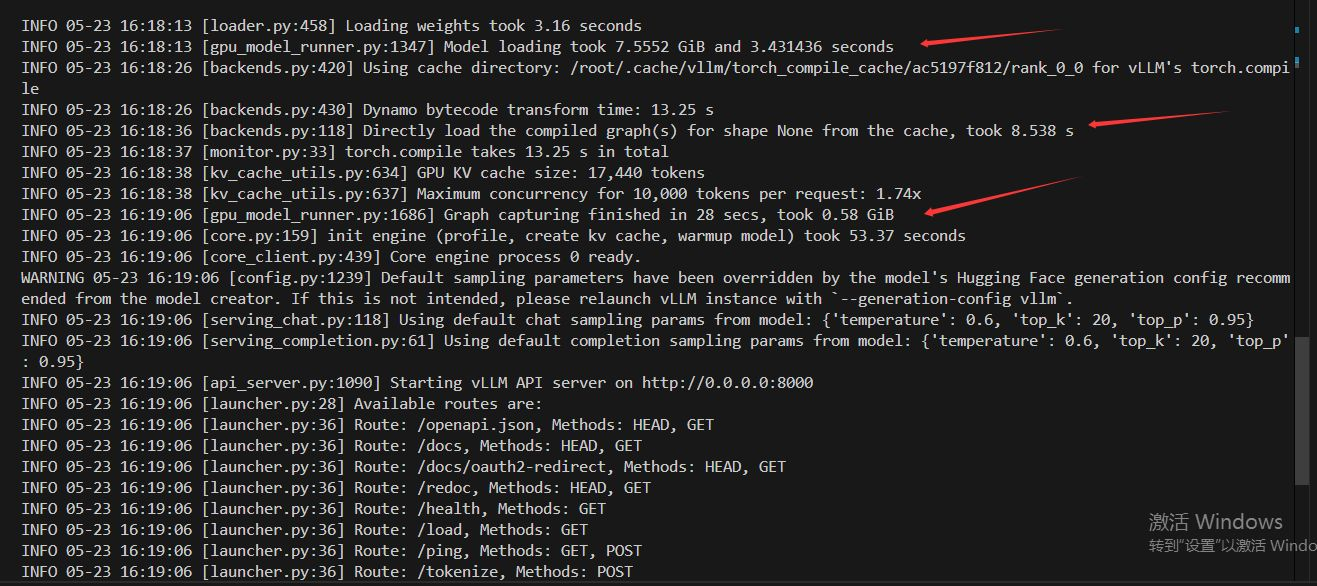
首先先分析配置日志
-
显存占用
- 模型加载:7.552 GiB(主模型权重)。
- KV缓存:17,440 tokens(具体显存需结合模型参数,但日志未直接给出数值)。
- 图捕获阶段:0.58 GiB(动态编译优化时的临时占用)。
- 总计显存:主模型+临时操作约为 8.13 GiB左右(KV缓存需额外计算,但日志未明确)。
- 总计显存:主模型+临时操作约为 8.13 GiB左右
也就是说,除了自定义的KV缓存,至少8.13GB
我们还可以自己计算KV显存,根据模型的配置文件和下述公式,得到缓存是1.37GB,也可以直接把模型配置发给deepseek叫它计算。

KV缓存总量 = batch_size × 序列长度 × 模型层数 × 2 × d_model × sizeof(float16)
因此VLLM部署Qwen3-4B的在--max-model-len 10000GPU的情况下模型占用的GPU资源是,8.13GB+1.37GB=9.5GB
如果是默认情况--max-model-len 40960,模型占用的GPU资源是,8.13GB+5.62GB=13.75GB
小技巧,如果你不相信AI计算的结果,可以执行默认的最长输入命令。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --gpu-memory-utilization 0.5
发现报错
raise ValueError( ValueError: To serve at least one request with the models's max seq len (40960), (5.62 GiB KV cache is needed, which is larger than the available KV cache memory (2.39 GiB). Based on the available memory, Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
错误提示显示5.62 GiB KV cache is needed,而当前可用显存仅2.39 GiB。KV缓存用于存储Transformer模型中各层的键值向量。
我们就可以自己计算,10000的token所占用的应该KV缓存的GPU大小,10000/40960*5.62GB=1.37GB。说明AI计算的是正确的。
四、解决问题3
问题3:VLLM框架预留更多的GPU资源对模型推理速度影响多大?
使用下面代码进行测试分配不同的GPU,推理时间变化多少。因为每次生成的token数量不一样,所以我们主要是以tokens/s为衡量标准进行测试。
import time
from openai import OpenAI# 初始化客户端
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)# 使用高精度计时器
start_time = time.perf_counter() # 比time.time()精度更高[3](@ref)chat_response = client.chat.completions.create(
model="/root/lanyun-tmp/modle/Qwen3-4B",
messages=[
{"role": "user", "content": "你有什么功能"},
],
max_tokens=8192,
temperature=0.7,
top_p=0.8,
presence_penalty=1.5,
extra_body={
"top_k": 20,
"chat_template_kwargs": {"enable_thinking": True},
},
)end_time = time.perf_counter()
elapsed = end_time - start_timeprint("Chat response:", chat_response)
print(f"\n[性能报告] 请求耗时: {elapsed:.4f}秒")
print(f"生成token数: {chat_response.usage.completion_tokens} tokens")
print(f"每秒生成速度: {chat_response.usage.completion_tokens/elapsed:.2f} tokens/s")
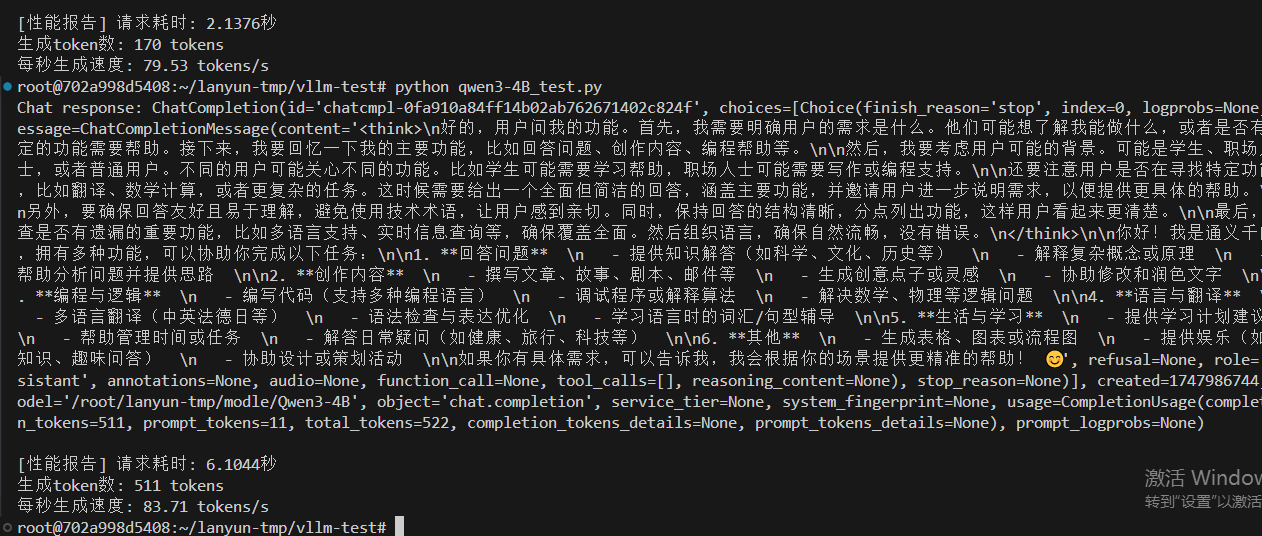
情况一,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
有思考83.71 tokens/s,无思考79.53 tokens/s
情况二,设置最大10000token数量,分配0.8GPU,20GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
有思考77.09 tokens/s,无思考 78.18 tokens/s
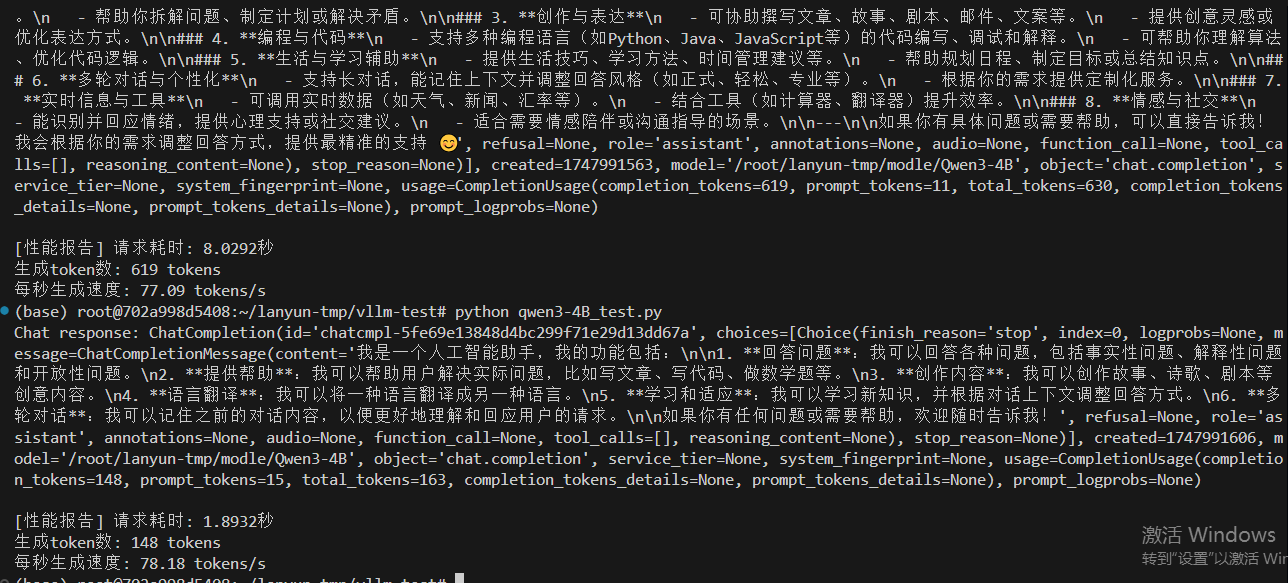
通过两个情况的对比,预留给VLLM服务的GPU空间大小没有对速度有太大影响,甚至空间小一定,生成速度还更多,但是多运行几次,发现速度是差不多的。
五、解决问题4
问题4:如何测试多人并发访问大模型服务,多少人是上限,生成的速度变化是怎么样的?
我们可以创建一个并发测试的代码concurrency_test.py
# concurrency_test.py
import argparse
import threading
import time
from queue import Queue
# qwen3-4B_test.py
import time
from openai import OpenAI
def send_request(prompt="你有什么功能", max_tokens=8192, temperature=0.7):
"""单次请求测试函数"""
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1",
)
start_time = time.perf_counter()
try:
response = client.chat.completions.create(
model="/root/lanyun-tmp/modle/Qwen3-4B",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
temperature=temperature,
extra_body={"top_k": 20}
)
elapsed = time.perf_counter() - start_time
return {
"success": True,
"time": elapsed,
"tokens": response.usage.completion_tokens,
"speed": response.usage.completion_tokens/elapsed,
"response": response.choices[0].message.content
}
except Exception as e:
return {
"success": False,
"error": str(e),
"time": time.perf_counter() - start_time
}
class ConcurrentTester:
def __init__(self, num_users):
self.num_users = num_users
self.results = Queue()
self.start_barrier = threading.Barrier(num_users + 1) # 同步所有线程同时启动
def _worker(self, user_id):
"""单个用户的请求线程"""
self.start_barrier.wait() # 等待所有线程就绪
result = send_request(prompt=f"测试用户{user_id}的并发请求")
self.results.put((user_id, result))
def run(self):
# 创建并启动所有线程
threads = []
for i in range(self.num_users):
t = threading.Thread(target=self._worker, args=(i+1,))
t.start()
threads.append(t)
# 等待所有线程准备就绪
self.start_barrier.wait()
start_time = time.perf_counter()
# 等待所有线程完成
for t in threads:
t.join()
total_time = time.perf_counter() - start_time
# 统计结果
success = 0
total_tokens = 0
speeds = []
errors = []
while not self.results.empty():
user_id, res = self.results.get()
if res['success']:
success += 1
total_tokens += res['tokens']
speeds.append(res['speed'])
else:
errors.append(f"用户{user_id}错误:{res['error']}")
return {
"total_time": total_time,
"success_rate": success/self.num_users,
"avg_speed": sum(speeds)/len(speeds) if speeds else 0,
"total_tokens": total_tokens,
"errors": errors
}
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--users", type=int, required=True,
help="并发用户数量")
args = parser.parse_args()
tester = ConcurrentTester(args.users)
print(f"开始{args.users}用户并发测试...")
results = tester.run()
print("\n测试报告:")
print(f"总耗时:{results['total_time']:.2f}秒")
print(f"成功请求:{results['success_rate']*100:.1f}%")
print(f"平均生成速度:{results['avg_speed']:.2f}tokens/s")
print(f"总生成token数:{results['total_tokens']}")
if results['errors']:
print("\n错误列表:")
for err in results['errors']:
print(f"• {err}")
分别测试上述两个情况:
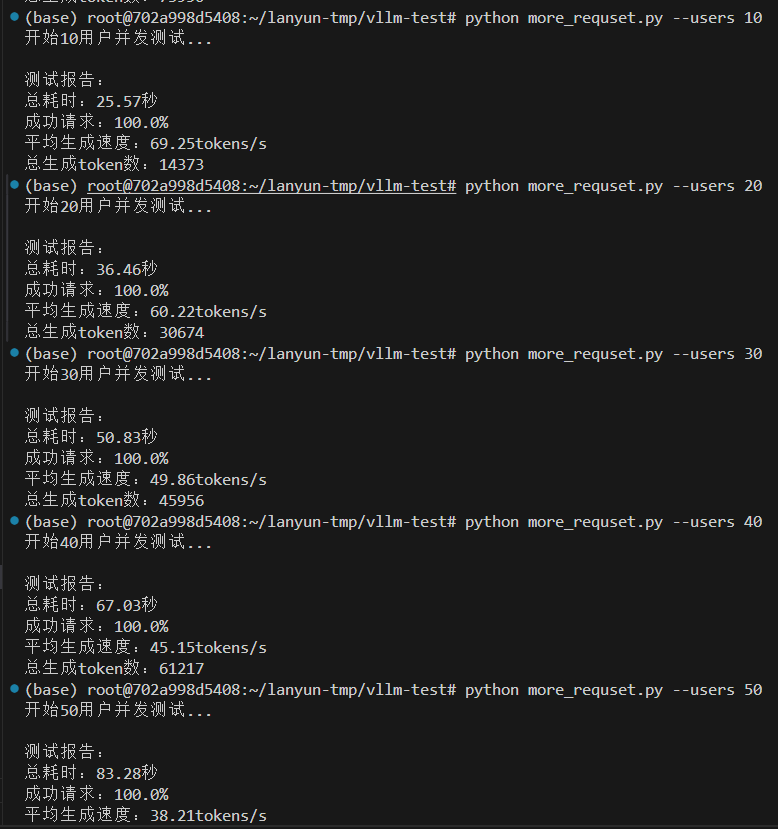
情况一,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
情况二,设置最大10000token数量,分配0.8GPU,20GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为10.5GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.8
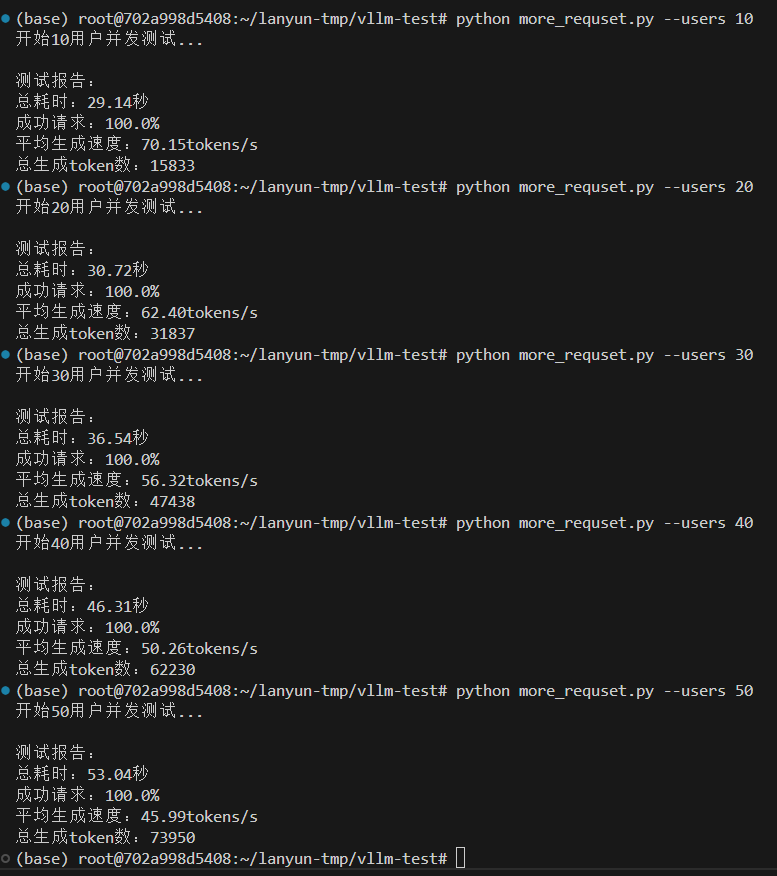
情况三,设置最大10000token数量,分配0.5GPU,12.7GB给VLLM服务,除去大模型的启动占用9.5GB,还给VLLM服务预留空间为3.2GB。
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000 --gpu-memory-utilization 0.5
终极测试500个并发请求,可以看到VLLM框架一次性是处理11个请求,然后分批次排队处理这么多的并发请求。然后越到后面处理的请求越少。
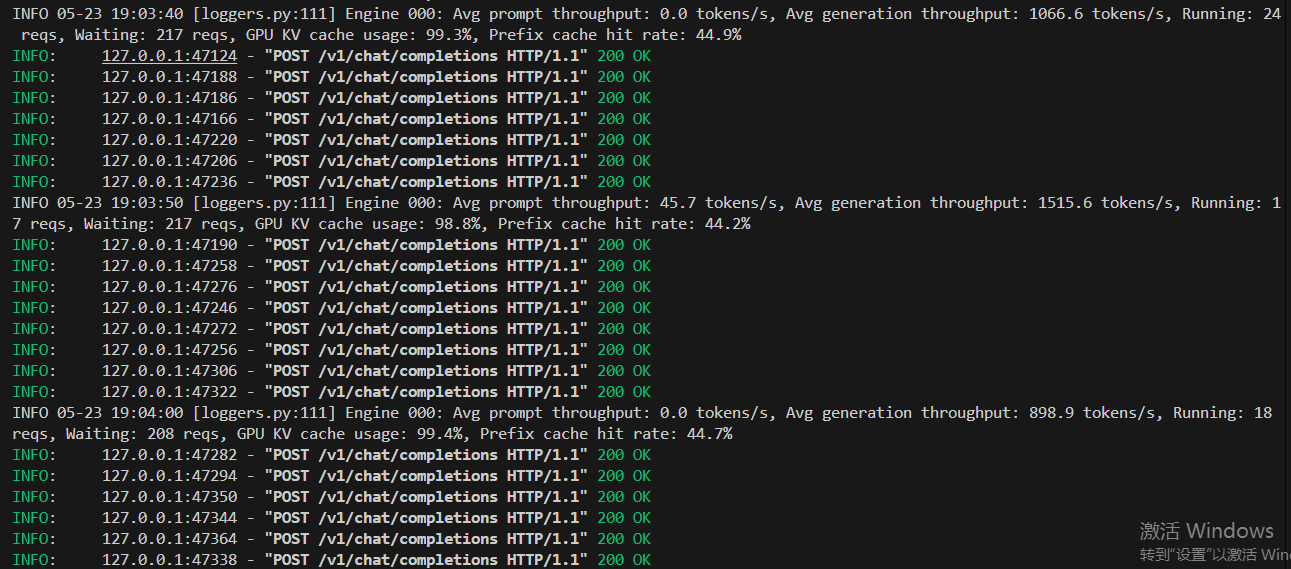
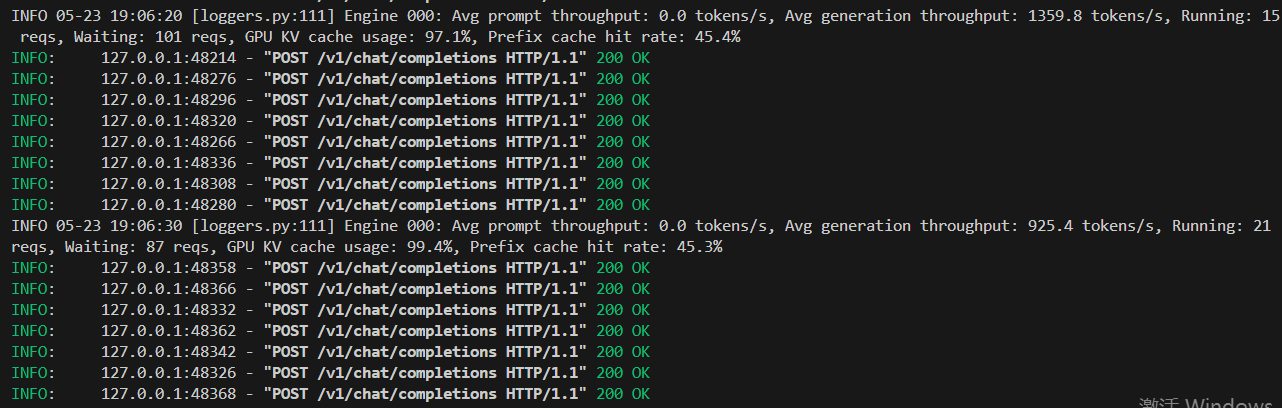
结论,VLLM处理框架处理并发的能力是可以的,它是通过并发处理11给请求,别的请求是排队处理。所以只要模型通过VLLM部署起来,理论上它解决无上限的并发请求,就是要排队等着大模型回复。
![[测试_3] 生命周期 | Bug级别 | 测试流程 | 思考](https://i-blog.csdnimg.cn/img_convert/ed9ea7b9ac71fa12c845ab46b4bcc29e.png)