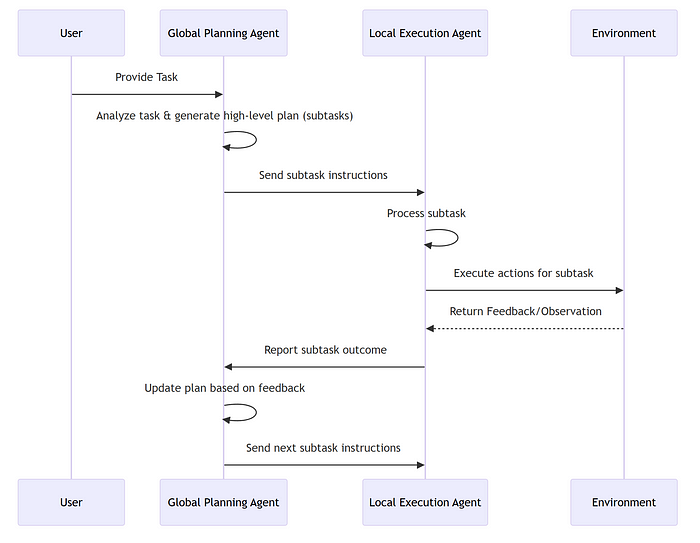
SfM → Point-NeRF → 3D Gaussian Splatting
🟦SfM
Structure-from-Motion(运动恢复结构,简称 SfM)是一种计算机视觉技术,可以:
利用多张从不同角度拍摄的图像,恢复出场景的三维结构和相机的位置。
举个例子:
你拿着手机从不同角度拍一座雕像,然后用 SfM 工具(如 COLMAP)处理这些图片,结果是:
-
相机每个拍摄位置的三维坐标(相机轨迹);
-
场景中每个被识别出来的点在三维空间中的坐标(称为 SFM points);
-
这些点与哪些图片对应(点和图像的关系);
这些恢复出来的三维点,就叫做 SfM点云(或简称 SfM points)。
🟦 Point-NeRF
Point-NeRF 是一种 基于点云的神经辐射场(Neural Radiance Field)渲染方法。
它的目标是:
在已有三维点云的基础上,通过神经网络对这些点进行增强,实现高质量的新视角图像合成。
这项工作是由 Xu et al., 2022 提出的,论文标题为:
Point-NeRF: Point-based Neural Radiance Fields
你可以这样理解 Point-NeRF:
把点云(比如从 SfM 或深度相机得到的)看作是“粗糙的模型骨架”,然后用神经网络“涂上颜色和光照”,让它从任意角度看起来都非常真实。
🟧 Point-NeRF 的核心流程如下:
1. 输入稀疏点云
-
可以是通过 SfM、深度相机等方式得到的;
-
每个点有位置、颜色、可选法向量等属性;
2. 点特征学习
-
每个点会被加上 learnable 的特征向量;
-
这些特征会输入到一个神经网络里,学习如何从不同角度“看”这些点;
3. 体积渲染(Volume Rendering)
-
和 NeRF 类似,它也用体积渲染;
-
从相机角度发射光线,在光线上采样点;
-
使用附近的点云点和其特征,通过网络预测颜色和密度;
-
混合出最终像素值。
🔵 与 3D Gaussian Splatting 有什么不同?
| 特征 | Point-NeRF | 3D Gaussian Splatting |
|---|---|---|
| 点云来源 | 预先计算的稀疏点云 | SfM + 优化后的高斯点 |
| 渲染方式 | 神经网络 + 体积渲染 | 显式几何 + 高斯渲染 |
| 是否训练 | 是(要训练网络) | 渲染无需网络,训练是为了优化点的参数 |
| 实时性 | 不是实时(需推理) | 支持实时(直接渲染高斯) |
| 易复现性 | 相对复杂,需要训练 | 更容易测试,尤其是预训练模型 |
✅ 总结一段话
Point-NeRF 是一种将稀疏点云与 NeRF 结合起来的方法,通过给点添加神经特征,并利用体积渲染完成新视角合成;而 3D Gaussian Splatting 则是用可渲染的高斯分布表示场景点,摆脱了神经网络渲染的成本,实现了更高效的实时效果。
🟦 Plenoxels
Plenoxels 是 “Plenoptic Voxels” 的缩写,是一种:
不依赖神经网络、用稀疏体素网格直接存储和优化颜色与密度 的快速 NeRF 替代方法。
它的全名是:
Plenoxels: Radiance Fields without Neural Networks
论文链接:[2112.05131] Plenoxels: Radiance Fields without Neural Networks
由 Alex Yu 等人于 2022 年 提出。
🟩 用大白话来说:
如果我们把 NeRF 比作用神经网络“慢慢画出照片”的艺术家,
那 Plenoxels 就是一个“预先把颜色和密度填在三维格子里”的像素工程师。
它不再用神经网络来学习,而是:
直接在一个稀疏的三维体素网格中,把每一个小格子(voxel)里的颜色和体积密度当作参数来优化。
🟨 核心思想:
| 步骤 | 描述 |
|---|---|
| 1. 初始化稀疏体素网格 | 用稀疏数据结构(哈希表)存储有效体素 |
| 2. 每个体素里存颜色+密度+SH系数 | 颜色用球谐函数(Spherical Harmonics)建模,提升角度表现力 |
| 3. 光线投射 & 渲染 | 和 NeRF 一样,光线穿过场景,在体素网格上采样 |
| 4. 反向传播优化参数 | 直接优化每个体素里的值(不用训练神经网络) |
🟧 优势与局限
| 优势 | 局限 |
|---|---|
| 不用神经网络,训练速度快(几分钟) | 占用内存较大(尤其是高分辨率场景) |
| 实现简单,效果媲美NeRF | 对小物体/细节支持不如高容量神经模型 |
| 渲染速度也快(支持实时) | 需要稀疏数据结构支持和预处理点云 |
🔵 与 3D Gaussian Splatting 对比:
| 特征 | Plenoxels | 3D Gaussian Splatting |
|---|---|---|
| 数据结构 | 稀疏体素(Sparse Voxel Grid) | 3D 高斯点 |
| 表示方式 | 每格有颜色密度 + SH | 每点有位置、朝向、颜色、协方差等 |
| 是否神经网络 | ❌ 不用 | ❌ 也不用 |
| 渲染方式 | 类似体积渲染(沿光线采样) | 显式 splatting 渲染(可GPU并行) |
| 实时性 | 较快(可实时) | 真正实时(更快) |
| 适合场景 | 中等复杂场景 | 动态、密集、真实场景 |
✅ 总结一段话
Plenoxels 是一种完全抛弃神经网络的 NeRF 变体,用稀疏体素网格表示场景,每个体素中保存颜色与密度等信息,训练和渲染都非常快。它是从“神经渲染”走向“直接优化”的关键过渡点之一,也为后来的 3D Gaussian Splatting 这种“完全可显式渲染”的方法铺平了道路。
论文具体方法
1.可微的3D高斯splatting
✅ 每个高斯点都包含了哪些核心信息?
论文中,每个 3D 高斯点包含以下 五类信息:
| 类别 | 具体字段 | 作用 |
|---|---|---|
| 几何信息 | 位置 𝜇、协方差矩阵 Σ | 决定点的在哪里、形状和朝向 |
| 外观信息 | 颜色(通过球谐函数表示) | 决定点的颜色随视角如何变化 |
| 透明度 | 不透明度 α | 决定点的遮挡/透明程度 |
| 辐射函数 | 球谐函数系数(SH) | 表示颜色的方向依赖性(类似 NeRF) |
| 附加参数 | 缩放因子、梯度优化量等 | 用于训练阶段微调点属性 |
🟦 1. 点的位置 μ(Mu)
-
就是这个高斯点在三维空间里的中心坐标。
-
表示的是:这个点在哪儿。
-
数学形式:一个三维向量 (x, y, z)。
📌 作用:
-
决定点投影到相机时在画面上的位置;
-
决定光线经过它的可能性。
点云中的点是“没有体积、没有方向、没有属性的几何点”,而高斯点是“有形状、有方向、有颜色函数的可渲染单位”。
🟦 1. 定义上的区别
| 项目 | 点云中的点(Point Cloud Point) | 高斯点(Gaussian Point) |
|---|---|---|
| 本质 | 一个空间中的三维坐标点 | 一个有体积/形状的 3D 高斯分布 |
| 表示 | (x, y, z) 可能加颜色 | (位置, 协方差, α, 颜色SH) |
| 形状 | 没有形状,是一个数学点 | 是一个模糊、椭球形的体积分布 |
🟨 2. 属性上的区别
| 属性 | 点云中的点 | 高斯点 |
|---|---|---|
| 位置 | ✅ 有 | ✅ 有 |
| 颜色 | 可能有 | ✅ 有(且是方向相关颜色) |
| 形状/大小 | ❌ 没有 | ✅ 有(由协方差矩阵控制) |
| 透明度 | ❌ 没有 | ✅ 有(α 参数) |
| 视角依赖性 | ❌ 没有 | ✅ 有(球谐函数 SH) |
| 可渲染性 | ⛔️ 不可直接渲染 | ✅ 可直接 GPU splatting 渲染 |
🟧 3. 数据来源和用途
| 项目 | 点云中的点 | 高斯点 |
|---|---|---|
| 来源 | SfM / 深度相机 / 激光雷达等 | 初始化自点云 + 优化生成 |
| 用途 | 建图、建模、几何分析 | 实时渲染、新视角图像合成 |
| 优化 | 通常静态,不参与优化 | 可微优化,参数是可学习的 |
| 表达力 | 稀疏且无纹理 | 稠密且能模拟真实外观 |
🧠 更形象的理解:
| 类比 | 点云点 | 高斯点 |
|---|---|---|
| 类比为“点” | 像一颗小钉子 | 像一个会发光、可调大小的彩色气泡 |
| 是否能直接用于图像合成? | ❌ 不行 | ✅ 可以 |
| 是否能表示视角变化? | ❌ 不行 | ✅ 可以(SH系数) |
| 是否能学习优化? | ❌ 一般不行 | ✅ 是可微优化的参数点 |
🔵 举个具体例子:
假设你用 COLMAP 重建了一个场景,有一万个 SfM 点(也就是点云):
-
每个点只有位置
(x, y, z),加个平均颜色(r, g, b)。 -
如果你把这些点直接画在屏幕上,就是一个稀稀疏疏的点状模型,没法真实地渲染。
然后你把这些点转为 3D Gaussian points:
-
每个点会变成一个椭球体;
-
会被赋予方向、大小、透明度;
-
颜色也不再是固定的,而是跟视角相关;
-
这些点还可以被训练优化,变成真实照片般的合成图像。
✅ 总结一句话:
点云点是原始几何信息,高斯点是带有可学习外观与空间结构的“可渲染光斑”,它把三维重建变成了一种实时图像生成方式。
🟨 2. 协方差矩阵 Σ(Sigma)
-
决定这个高斯点的形状和方向。
-
是一个 3x3 对称正定矩阵,但论文中为了简化通常只优化一个对角矩阵或通过旋转矩阵和缩放矩阵表示。
📌 作用:
-
控制这个点在空间中是像球一样、椭球一样,还是拉长的;
-
决定它投影到图像上是小圆点还是长条形;
-
实现方向感和空间覆盖,提升细节表达能力。
🟩 3. 不透明度 α(Alpha)
-
表示该点的透明程度,0 = 完全透明,1 = 完全不透明。
-
在渲染时用于 alpha blending(α混合)。
📌 作用:
-
控制该点对最终图像的影响程度;
-
表示遮挡、深度的“参与度”;
-
用于模拟材质、边缘的模糊感。
🟧 4. 球谐函数系数(Spherical Harmonics, SH)
-
用于模拟点的颜色如何随视角变化。
-
因为一个物体从不同角度看,颜色/亮度会变化(如镜面高光、阴影等);
-
所以每个点不只是一个 RGB 颜色,而是一个 方向相关的颜色函数,用 球谐函数(SH) 来表达。
📌 作用:
-
模拟视角依赖的外观;
-
替代 NeRF 中的 MLP 输出颜色;
-
使得渲染时可以直接用 SH 快速计算颜色(比 MLP 快很多)。
数学形式:
-
通常用 02 阶球谐函数,每个通道大概 916 个系数。
🔵 总结一下用类比帮助你记住:
| 参数 | 像什么? | 决定什么? |
|---|---|---|
位置 μ | 这个点在哪 | 空间位置 |
协方差 Σ | 点长成啥样 | 尺寸与方向(变成椭圆) |
α 不透明度 | 点有多实在 | 遮挡与透明效果 |
| SH 系数 | 从哪个角度看变什么颜色 | 模拟视角依赖的颜色 |
| 颜色函数 | RGB颜色被“编码”成一个方向函数 | 快速渲染 |
🧠 总结一段话
在 3D Gaussian Splatting 中,每个点不是一个死板的小球,而是一个“活”的、高斯形状的、带有方向感和颜色变化规律的“发光斑点”。它包含位置、形状(协方差)、透明度、球谐函数颜色表达等参数,这些使得渲染过程可以高度并行且实时,同时保留丰富细节与真实感。
3D 高斯的公式
🟦 为什么用高斯?
论文的核心思想是:
用一个个 3D 高斯分布(椭球形状) 来表示场景中能“发光”的点,再将它们投影到图像上进行 快速渲染(splatting)。
这个“高斯”其实不是指概率分布,而是作为一个模糊、可渲染的小体积单位,具有空间形状和方向。
🟩 高斯的核心公式概念(3D场景中的分布)
论文中使用的 3D 高斯是一个各向异性的三维分布(可以是椭球),它的密度函数如下:
✅ 高斯密度函数:
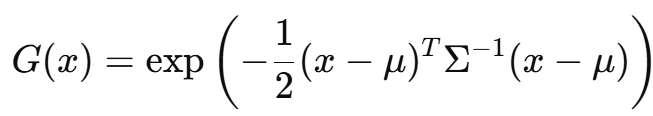
| 符号 | 含义 | 中文说明 |
|---|---|---|
| x | 查询点坐标 | 你想看看“某个位置”的值 |
| μ | 高斯中心点的位置 | 就是这个点的位置(中心) |
| Σ | 协方差矩阵 | 控制高斯的大小、方向、拉伸形状 |
| Σ−1 | 协方差的逆 | 控制点周围的“下降速度” |
| exp() | 指数函数 | 构成了高斯“钟形”结构 |
这个函数值越大,表示离中心越近,点的贡献越大。
🟨 如何从 3D 高斯投影到 2D 图像?
论文做的事情不是在 3D 空间看高斯密度,而是把它 投影到图像平面,然后做“splatting 渲染”。
📌 步骤是这样的:
-
把 3D 高斯点的位置
μ投影到图像上,得到 2D 中心坐标。 -
把协方差矩阵
Σ也投影到图像上,得到图像平面上的椭圆大小与方向。
这个投影涉及一个公式:
✅ 投影协方差公式:
![]()
解释:
-
J:是相机投影的雅可比矩阵(Jacobian),描述 3D 到 2D 的变换;
-
Σ3D:原始高斯点的 3D 协方差;
-
Σ2D:高斯投影到图像后形成的椭圆外观。
🟧 渲染公式核心:颜色混合
每个高斯点投影到图像上后,会在其椭圆区域“撒”出颜色值,叠加形成最终图像。
论文中提出了一种基于 alpha blending(α 混合)的公式:
✅ 前向混合(Front-to-Back Compositing):
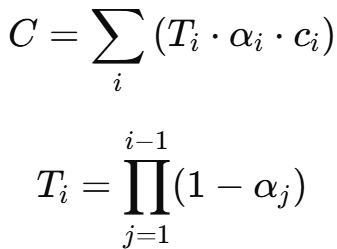
| 符号 | 含义 |
|---|---|
| ci | 第 i 个高斯的颜色(通过球谐函数计算) |
| αi | 不透明度,控制遮挡 |
| Ti | 前面所有高斯点“没遮住”的透明传输量 |
| C | 渲染出的最终像素颜色 |
它模拟了“雾”的效果:前面透明就继续看后面,前面不透明就遮住了。
🟦 球谐函数(SH)上场:
高斯点的颜色不是一个固定 RGB,而是一个 方向相关函数:
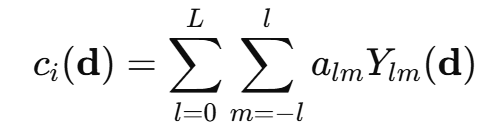
| 成分 | 含义 |
|---|---|
| d | 观察方向 |
| Ylm | 球谐基函数(方向函数) |
| alm | 系数,控制每个方向的颜色强度 |
👉 也就是说,从不同角度看,高斯点会呈现出不同的颜色,这就是为什么能产生立体真实感的原因。
🔵 整体流程回顾:
-
初始化一堆带位置/大小/颜色/透明度的高斯点;
-
把它们从 3D 空间投影到图像(2D)上,得到一个个椭圆;
-
每个点按不透明度 & 球谐颜色对图像贡献;
-
多个点用前向混合累加,得到最终图像。
✅ 最终一句总结
论文中使用了一个 可微、可投影的 3D 高斯模型,每个点具有形状(协方差)、透明度(α)和方向相关颜色(SH系数),渲染时投影成椭圆,用快速的 splatting 和前向混合方式生成图像,既能保真又能加速训练和推理。
2.优化与自适应密度控制
✅ (1)随机梯度下降(SGD)优化:训练方法
在训练过程中,3DGS 不使用神经网络权重,而是对 每个高斯点的参数(位置、协方差矩阵、颜色 SH、α等)直接进行优化。
优化目标:
-
最小化训练图像与渲染图像之间的 重建损失,比如 MSE 或 PSNR loss。
被优化的参数:
-
点的位置
μ -
协方差
Σ(变成缩放参数 + 旋转) -
不透明度
α -
颜色的球谐系数(SH)
优化方式:
使用 Adam 优化器(比 SGD 更平稳)——
optimizer = torch.optim.Adam(gaussian_params, lr=0.001)
每次迭代会:
-
对一小批图像 patch 进行前向渲染;
-
计算损失;
-
对上述所有参数进行反向传播;
-
用 Adam 更新。
✅ (2)CUDA 核心 & 快速光栅化(Fast Rasterization)
问题:
你可能会想:“渲染图像不是慢吗?”
论文提出了一个 专门用 CUDA 编写的、高度并行的 rasterizer(光栅器),来替代传统慢速渲染。
它做了什么:
-
高斯点在图像上的投影 → 转换成屏幕上的椭圆
-
每个像素仅处理那些覆盖它的高斯点(通过层级 bounding box + early Z-culling)
-
在 CUDA 上用一个核心模块实现并行累加(类似光栅化)
🔧 这一部分关键优势是:
-
所有操作都是 tensor 化的,可微分;
-
实现极高的训练 & 渲染效率;
-
每一步都可以 GPU 上做。
✅ (3)自适应密度控制(Adaptive Densification)
这是论文中最令人惊艳的机制之一。
问题:
刚开始初始化的点数量不够、太稀疏,会影响渲染质量。
解决办法:动态添加高斯点
论文提出了 在训练过程中自动新增点 的机制,称为:
Adaptive Densification(自适应加密)
机制逻辑如下:
-
每隔 N 步检查一次点云中的点:
-
如果某个点的梯度非常大 ➜ 说明它需要学习更多细节 ➜ 就从它周围复制出新点
-
如果某个点的透明度 α 非常低 ➜ 没啥贡献 ➜ 就删除它
-
判据:
使用两个 激活函数(activation functions):
-
用于 控制点的透明度 α 的优化行为
具体是:
-
论文中使用了两个非线性函数:
-
softplus:用于保持透明度 α 始终为正值
-
![]()
- sigmoid 或 tanh:用于压缩协方差参数、尺度参数等到合理范围
✅ 它们起到了两个作用:
-
限制不合理值(如负值、过大数值);
-
保持参数空间光滑可导,便于梯度传播。
✅ 4. 总结表格
| 机制 | 用途 | 技术细节 | 优势 |
|---|---|---|---|
| 随机梯度下降 | 优化点参数 | Adam 优化器,最小化渲染损失 | 可微训练,无需 MLP |
| CUDA 光栅化 | 快速渲染 | 椭圆 bounding box + 并行累加 | GPU 加速,超快 |
| 自适应加密 | 增加点密度 | 梯度判据 + α 删除机制 | 自动精细化、节省显存 |
| 激活函数 | 控制数值范围 | softplus、sigmoid、tanh | 保持参数稳定可导 |
总结一句话:
论文提出了一种 无需神经网络,仅优化可微高斯点 的训练方法,配合 CUDA 加速和自动加密机制,使得整个系统能在训练初期迅速提升质量,在训练后期精雕细琢,真正实现了“即快又精”。
🔧 核心目标:控制点云质量和密度
论文中指出,如果点云不加管理:
-
会出现 冗余、高重叠、漂浮点(floaters)
-
也会出现 某些区域采样不足、重建质量差
因此作者提出了一系列 周期性清理与重建补充机制,在训练过程中自动进行。
✅ 机制一:每 100 步迭代移除不透明度低的点
目的:剔除对图像贡献很小的无效点,释放内存 & 加快训练
做法:
每隔 100 步,检查所有点的
α(不透明度),小于阈值(如 0.005)的点将被直接移除。
这种点通常:
-
被 occlusion 遮挡
-
或处于背景、没被用上
-
或不再有优化价值
🔎 论文中原文描述(意译):
“We periodically remove Gaussians with low opacity (α < 0.005), typically every 100 steps.”
✅ 机制二:周期性将部分点的不透明度重置为 0 —— 去除 floaters(漂浮点)
目的:自动检测那些 似乎没用但还留在点云中 的点
做法:
定期将一部分点的
α设置为 0,让它们“失效”,观察是否还会通过训练自动恢复(即重新变为有效点)。
如果:
-
某点在 reset 后又因 loss 梯度重新激活 ➜ 它就是有用的 ➜ 保留
-
否则 ➜ 它可能是漂浮点 ➜ 后续会被清除
📌 这种机制是对不透明度的一种“软清理”,允许模型自我恢复真正有价值的点。
✅ 机制三:周期性移除“太大”的高斯点(避免重叠)
目的:控制协方差过大的点,避免大高斯“笼罩一大片”,导致视觉模糊 & 冗余重叠
做法:
设定一个高斯尺度阈值(如 σ > max_threshold),定期清理掉过大的高斯点。
这些大点可能来源于:
-
初始化时设置太宽
-
或未被有效优化收缩
📌 太大的高斯点容易遮挡多个像素,降低图像清晰度,因此需要定期清理。
✅ 机制四:重建不足区域会有较大的梯度 —— 用于新点插入(densification)
目的:自动补充点云中“稀疏”的区域
做法:
在每次训练中,记录每个点参数的梯度,如果某些区域的梯度大 ➜ 表示这些点想学更多内容 ➜ 从这些点复制出新点(克隆 + 添加扰动)
📌 梯度大 = 模型对这区域不满意 ➜ 自动 densify
这就是论文提出的:
gradient-based point splitting / cloning for adaptive densification
📋 总结
| 机制 | 描述 | 周期 | 目的 |
|---|---|---|---|
| ✅ 删除低 α 点 | 移除透明度很低的点 | 每 100 步 | 清理无用点 |
| ✅ α 重置机制 | 周期性将部分 α 设为 0 | 若干轮迭代 | 检测漂浮点 |
| ✅ 移除超大高斯 | 删除 σ 超过阈值的点 | 周期性检查 | 控制点形状合理 |
| ✅ 高梯度密度控制 | 根据梯度增密点 | 连续监控 | 补足细节区域 |
🔧 技术背后价值:
这些机制共同实现了:
-
结构紧凑:只保留最有用的点
-
自我优化:通过梯度反馈判断区域是否需要更多点
-
训练稳定性:避免 α 爆炸或协方差崩坏
-
高效可视化:点少、图像清晰、渲染速度快
3.快速可微光栅化
✳️ 背景理解:什么是“光栅化”(Rasterization)?
在传统图形学中,光栅化是指将几何图元(如点、线、三角形)转换为图像像素的过程。NeRF 使用体积渲染(体积积分,慢),而3DGS则“抛弃了积分”,改为用 2D 椭圆 + 屏幕空间 splatting 实现显式投影。
这也是为什么3DGS 不再需要 ray marching,速度极快。
🌟 Tile-based Rasterization 的五个关键步骤详解
✅ 步骤 1:将图像划分为 16×16 的 tiles(图像块)
目的:减少计算量 + 并行处理
整个图像被切割成许多小块(tiles),每个 tile 大小为 16×16 像素。
-
每个 tile 单独处理 ➜ 易于 GPU 并行化
-
每个 tile 只处理覆盖它的高斯点 ➜ 避免无关计算
🔧 类似 CUDA block/thread 的思想,一 tile 一批线程。
✅ 步骤 2:筛选置信度大于 99% 的高斯 + 按深度排序
目的:只处理“有效”的高斯点,并确保渲染顺序正确
✔️ 什么是“置信度”?
每个高斯点投影到图像空间后,会形成一个椭圆覆盖若干像素。论文中使用高斯分布函数(probability > 99%)裁剪椭圆边界范围,减少多余像素。
即:
高斯点在图像上只影响置信度 > 99% 的像素范围。
✔️ 为什么要按深度排序?
因为:
-
多个点会“splat”在同一个像素上
-
为了模拟遮挡关系,需要从 远 → 近 的顺序渲染(先画远处,再叠加近处)
✅ 步骤 3:每个 tile 中并行执行 splatting(点到像素渲染)
目的:GPU 并行投影高斯点
✔️ splatting 是什么?
Splat = “抛洒”:将一个 3D 高斯点投影成一个 2D 椭圆,并分布其 RGB/α 值到影响的像素上,按高斯核函数分权平均。
✔️ 如何实现?
每个像素接收多个高斯的颜色 + 不透明度,使用类似 alpha blending 的合成方法:

这种操作适合大规模并行,每个 tile 中线程可以独立执行。
✅ 步骤 4:早停机制(Early Termination)节省计算
目的:若像素已经完全不透明,就不再继续渲染更多高斯点
比如某个像素已经叠加了多个高斯的 α 值,达到完全遮挡(如 α ≈ 1.0),后面再画更多点其实是浪费计算。
所以采用:
-
如果像素 α 累加 > 某阈值 ➜ 终止对应线程 ➜ 节省资源
这个类似于 NeRF 中的 ray early termination。
✅ 步骤 5:反向传播(backward)——块索引 + 高效梯度计算
目的:训练时也要让高斯点支持梯度更新
-
每个 tile 保留其影响的高斯点列表
-
当需要计算损失对高斯点参数的梯度时,只需反向传播到这些点 ➜ 避免全图参与
-
可以高效更新:
-
点的位置(μ)
-
协方差(控制椭圆形状)
-
不透明度 α
-
球谐系数(颜色)
-
这一过程也是 可微的,所以整个 pipeline 是“端到端训练友好”的。
🎯 可视化流程图(逻辑)
全图划分为 tile(16×16)
↓
每 tile 找出覆盖它的高斯点(置信度 > 99%)
↓
对这些点按深度排序(远→近)
↓
并行 splatting 到像素(高斯投影、加权和)
↓
若某像素 α > 1.0,可提前停止渲染
↓
保存哪些高斯影响了哪些 tile
↓
训练时从这些 tile 反向传播,更新参数
🧠 总结
| 步骤 | 技术关键词 | 目的 |
|---|---|---|
| 1 | 图像分块 tile | 加速并行处理 |
| 2 | 高斯筛选 + 深度排序 | 避免冗余、支持遮挡 |
| 3 | splatting 渲染 | 显式可微、像素合成 |
| 4 | 提前终止线程 | 减少无效计算 |
| 5 | 块索引梯度反传 | 高效训练、可微优化 |
整体流程一览图
📸 多视角照片(输入)
↓
📌 SfM / COLMAP → 生成稀疏点云 + 相机位姿
↓
📌 初始化:将点云转为3D高斯点(位置、颜色、透明度、协方差等)
↓
🔁 训练阶段(优化高斯参数)
- 每次从不同角度渲染(3D高斯 → 2D 图像)
- 与真实照片进行比对(像素级 loss)
- 反向传播优化高斯点参数
↓
🎬 渲染阶段(inference)
- 给定任意视角
- 将优化好的3D高斯实时投影生成2D图像
✅ 最终输出:**任意视角下的2D图像(非常逼真、几乎是照片)**