本文目录:
- 一、检测数据集中的缺失值
- (一)缺失值的判断规则:
- (二)代码如下:
- 二、缺失值加载处理&缺失值设置
- (一)缺失值加载处理
- (二)缺失值设置
- 三、缺失值可视化
- 四、缺失值的处理
- (一)删除缺失值
- (二)缺失值填充
- 1.非时间序列数据缺失值填充**
- 2.时间序列数据缺失值填充**
- 最后,关于数据集缺失值~三两话
前言:实际业务中的数据集常常存在缺失值,这时就需要对缺失值进行了解和处理,不然会影响到我们整体的数据分析。
数据库中缺失值表示为NULL,有些编程语言中缺失值表示为NA,缺失值也可能是空字符串(‘’)或数值,在Pandas中使用NaN(来自NumPy库)表示缺失值。
一、检测数据集中的缺失值
(一)缺失值的判断规则:
(1)不可通过==判断,只可以通过API(方法)判断;
(2)pandas有 isnull() / isna()等两个方法用于判断缺失值,结果返回True或者False;
(3)pandas有notnull() / notna()等两个方法用于判断是否是缺失值,结果返回True或者False。
(二)代码如下:
# 导包
import numpy as np
# 1. 缺失值不是 True, False, 空字符串, 0等, 它"毫无意义"
print(np.NaN == False)
print(np.NaN == True)
print(np.NaN == 0)
print(np.NaN == '')
# 2. np.nan np.NAN np.NaN 都是缺失值, 这个类型比较特殊, 不同通过 == 方式判断, 只能通过API
print(np.NaN == np.nan)
print(np.NaN == np.NAN)
print(np.nan == np.NAN)
# 3. Pandas 提供了 isnull() / isna()方法, 用于测试某个值是否为缺失值
import pandas as pd
print(pd.isnull(np.NaN)) # True
print(pd.isnull(np.nan)) # True
print(pd.isnull(np.NAN)) # True
print(pd.isna(np.NaN)) # True
print(pd.isna(np.nan)) # True
print(pd.isna(np.NAN)) # True
# isnull() / isna()方法判断数据.
print(pd.isnull(20)) # False
print(pd.isnull('abc')) # False
#实例:
df = pd.DataFrame({
'A': [1, np.nan, 3],
'B': ['x', None, pd.NA],
'C': [pd.Timestamp('2023-01-01'), pd.NaT, 2]
})
# 使用isnull()或isna()结果相同
print(df.isnull()) # 等价于 df.isna()
实例运行结果:
A B C
0 False False False
1 True True True
2 False True False
#Pandas的notnull() / notna() 方法可以用于判断某个值是否为缺失值
print(pd.notnull(np.NaN)) #np.NaN是缺失值,返回False
print(pd.notnull('abc')) # 'abc'不是缺失值,返回True
二、缺失值加载处理&缺失值设置
(一)缺失值加载处理
keep_default_na=False:设置后将禁用默认识别缺失值并转化为NaN,null、NULL、空值等将保持原样;
代码如下:
例:
import pandas as pd #导包
**#1.默认时(keep_default_na=True)**
file1=pd.read_csv(r"D:\weight_loss.csv")
print(file1)
运行结果:
Name Month Week Weight
0 Bob Jan Week 1 291.0
1 Amy Jan Week 1 197.0
2 Bob Jan NaN NaN #null、空值都转为NaN
3 Amy Jan Week 2 189.0
4 Bob Jan Week 3 NaN #NA转为NaN
5 Amy Jan NaN 189.0 #NULL转为NaN
6 Bob Jan Week 4 283.0
**#2.设置keep_default_na=False**
file2=pd.read_csv(r"D:\weight_loss.csv",keep_default_na=False)
print(file2)
运行结果:
0 Bob Jan Week 1 291
1 Amy Jan Week 1 197
2 Bob Jan null #null、空值均保持不变,未转为NaN
3 Amy Jan Week 2 189
4 Bob Jan Week 3 NA #NA保持不变,未转为NaN
5 Amy Jan NULL 189 #NULL保持不变,未转为NaN
6 Bob Jan Week 4 283
(二)缺失值设置
na_values=[值1, 值2…]:表示加载数据时, 设定哪些值为缺失值。
代码如下:
例:
# 仅将 "MISSING" 和空值视为缺失值
df = pd.read_csv(data.csv,
keep_default_na=False,
na_values=["MISSING", ""])
备注:keep_default_na=False + na_values代表严格自定义缺失值标记。
三、缺失值可视化
顾名思义,也就是通过画图的方式将缺失值呈现出来,运用的是missingno模块(专门呈现缺失值)。
代码如下:
例:
# 1. 加载数据
train = pd.read_csv('data/titanic_train.csv')
test = pd.read_csv('data/titanic_test.csv')
train.shape
train.head()
# 2. 查看是否获救数据.
train['Survived'].value_counts() # 0: 没获救. 1: 获救
# 3. 缺失值可视化(了解)
# 如果没有安装这个包, 需要先装一下.
# pip install missingnode
# 导包
import missingno as msno
# 柱状图, 展示: 每列的 非空值(即: 非缺失值)个数.
msno.bar(train)
# 绘制缺失值热力图, 发现缺失值之间是否有关联, 是不是A这一列缺失, B这一列也会缺失.
msno.heatmap(train)
四、缺失值的处理
发现缺失值后,通常需要处理缺失值:删除(dropna)或者填充(fillna、interpolate等)。
(一)删除缺失值
dropna()函数, 参数介绍如下:
-
subset=None :默认是删除有缺失值的行, 如果要删除列,可以通过参数来指定,如: subset = [‘Age’] ,即当“Age”列有缺失值时会被删除;
-
inplace=False :通用参数, 是否修改原始数据默认False;
-
axis=0 :通用参数,按行或按列删除,默认按行(axis=0);
-
how=‘any’ :只要有缺失就会删除 还可以传入’all’ ,即全部都是缺失值才会被删除。
代码如下:
例:
train.shape # 原始数据, 891行, 12列
# 方式1: 删除缺失值
# 删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值
# 按行删除: 删除包含缺失值的记录
# train.dropna().shape # 默认按行删(该行只要有空值, 就删除该行), 结果为: 183行, 12列
train.loc[:10].dropna() # 获取前11行数据, 删除包含空值的行.
# any: 只要有空值就删除该行|列, all: 该行|列 全为空才删除 subset: 参考哪些列的空值. inplace=True 在原表修改
train.dropna(subset=['Age'], how='any')
# 该列值只要有空, 就删除该列值.
train.dropna(how='any', axis=1) # 0(默认): 行, 1: 列
train.isnull().sum() # 快速计算是否包含缺失值
(二)缺失值填充
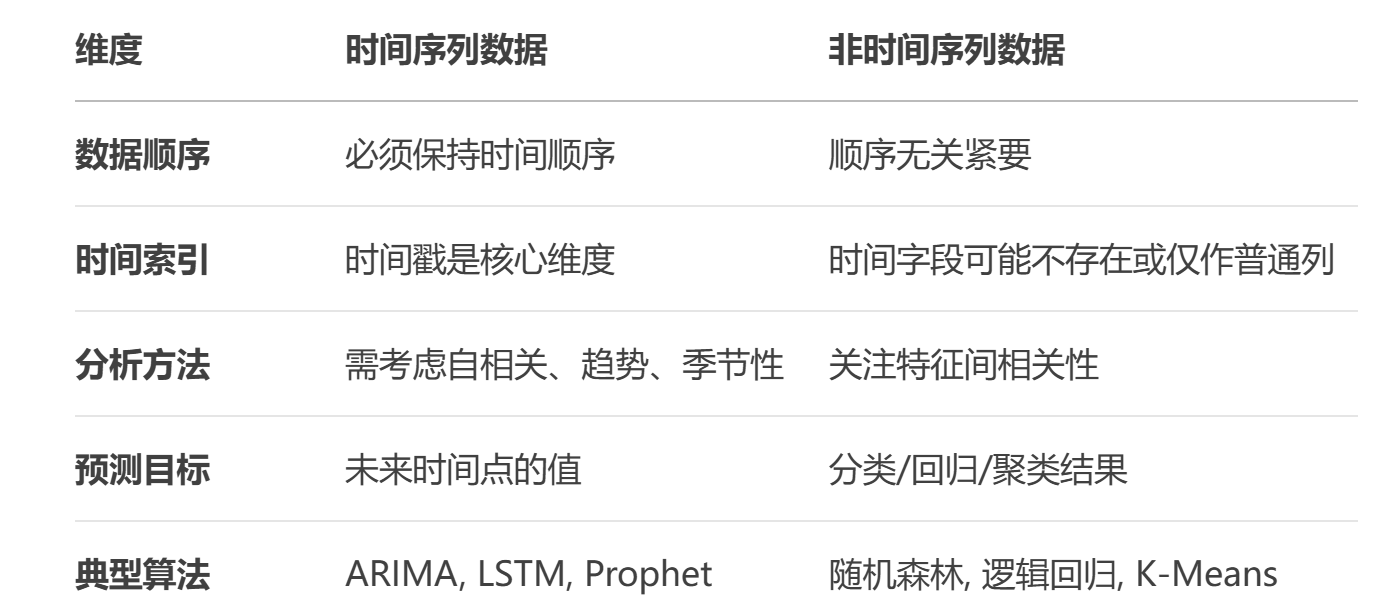
我们的数据分为时间序列数据和非时间序列数据,而它们的缺失值填充方法不同。
两种数据的特点:
1.非时间序列数据缺失值填充**
非时序数据的缺失值填充, 直接使用fillna(值, inplace=True)
- 可以使用统计量 众数 , 平均值, 中位数 …
- 也可以使用默认值来填充 。
代码如下:
# 填充缺失值是指用一个估算的值来去替代缺失数
# 非时间序列数据, 可以使用常量来替换(默认值)
# 用 0 来填充 空值.
train.fillna(0)
# 查看填充后, 每列缺失值情况.
train.fillna(0).isnull().sum()
# 用平均年龄, 来替换年龄列的空值.
train['Age'].fillna(train['Age'].mean())
2.时间序列数据缺失值填充**
时序数据的缺失值填充, 可以使用fillna( method=ffill),表示使用前一个值填充;
- 也可以使用fillna( method=bfill),表示使用后一个值填充;
- 还可以使用统计量 众数 , 平均值, 中位数 …
- 最后也可以使用线性插值方法:interpolate()填充缺失值。
代码如下:
# 1. 加载时间序列数据,数据集为印度城市空气质量数据(2015-2020)
# parse_dates: 把某些列转成时间列.
# index_col: 设置指定列为 索引列
city_day = pd.read_csv('data/city_day.csv', parse_dates=['Date'], index_col='Date')
# 2. 查看缺失值情况.
city_day.isnull().sum()
# 3. 数据中有很多缺失值,比如 Xylene(二甲苯)和 PM10 有超过50%的缺失值
# 3.1 查看包含缺失数据的部分
city_day['Xylene'][50:64]
# 3.2 用固定值填充, 例如: 该列的平均值.
# 查看平均值.
city_day['Xylene'].mean() # 3.0701278234985114
# 用平均值来填充.
city_day.fillna(city_day['Xylene'].mean())[50:64]['Xylene']
# 3.3 使用ffill 填充,用时间序列中空值的上一个非空值填充
# NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81
city_day.fillna(method='ffill')[50:64]['Xylene']
# 3.4 使用bfill填充,用时间序列中空值的下一个非空值填充
# NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209
city_day.fillna(method='bfill')[50:64]['Xylene']
# 3.5 线性插值方法填充缺失值
# 时间序列数据,数据随着时间的变化可能会较大。使用bfill和ffill进行插补并不是解决缺失值问题的最优方案。
# 线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。
# 参数limit_direction: 表示线性填充时, 参考哪些值(forward: 向前, backward:向后, both:前后均参考)
city_day.interpolate(limit_direction="both")[50:64]['Xylene']
最后,关于数据集缺失值~三两话
- 1.能不删就不删 , 如果某列数据有大量的缺失值(50% 以上是缺失值), 具体情况具体分析;
- 2.如果是类别型的缺失值,可以考虑使用字段 ‘缺失’ 来进行填充;
- 3.如果是数值型的缺失值,可以用一些统计量 (均值/中位数/众数) 或者业务的默认值来填充。
今天的分享到此结束。