前言:
在前面的 Elasticsearch 系列文章中,分享了 Elasticsearch 的各种查询,分页查询也分享过,本篇将再次对 Elasticsearch 分页查询进行专题分析,“深度分页” 这个名词对于我们来说是一个非常常见的业务场景,本篇再次进行 Elasticsearch 分页查询进行分析,也是围绕深度分页这个业务场景来展开的。
Elasticsearch 系列文章传送门
Elasticsearch 基础篇【ES】
Elasticsearch Windows 环境安装
Elasticsearch 之 ElasticsearchRestTemplate 普通查询
Elasticsearch 之 ElasticsearchRestTemplate 聚合查询
Elasticsearch 之 ElasticsearchRestTemplate 嵌套聚合查询【嵌套文档聚合查询】
分页查询前景回顾
我们来回忆下在之前的分页查询,代码如下:
public List<CarDO> pageList(int currentPage, int pageSize) {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withPageable(PageRequest.of(currentPage - 1, pageSize)).build();
queryBuilder.withQuery(QueryBuilders.matchQuery("color", "雅灰"));
SearchHits<CarDO> search = elasticsearchRestTemplate.search(queryBuilder.build(), CarDO.class);
return search.getSearchHits().stream().map(SearchHit::getContent).collect(Collectors.toList());
}
以上代码我们使用了 【queryBuilder.withPageable】来实现的分页查查询,通过 PageRequest 传入了当前页和分页大小构建了一个分页对象,以上分页会有什么问题?
Elasticsearch 分页原理探讨
Elasticsearch 分页官方文档
官方文档描述如下:
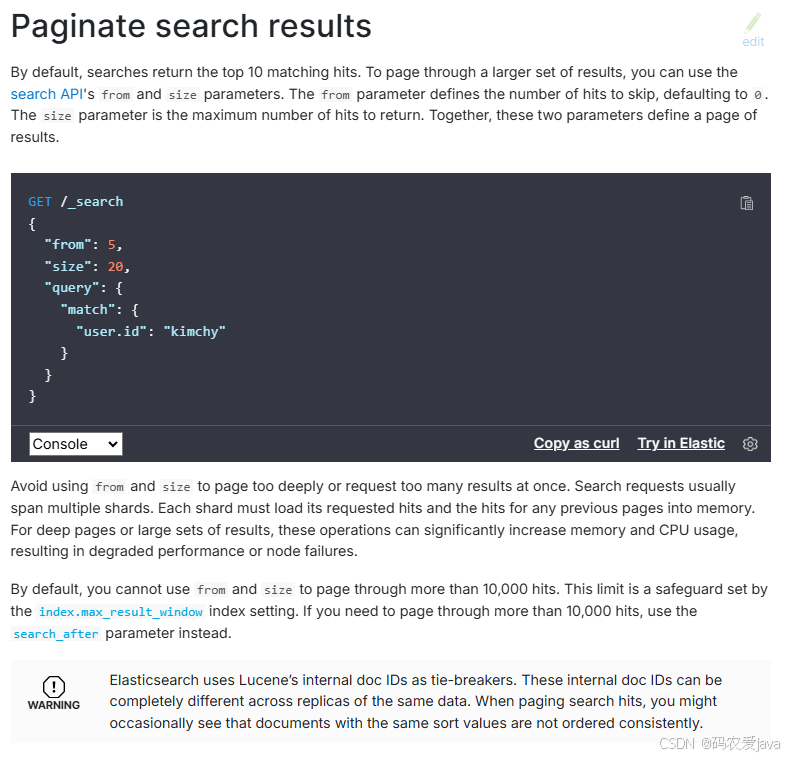
官方文档说的大概意思如下:
默认情况下,搜索会返回前 10 个匹配结果,如果要翻阅更多结果,可以使用搜索 API 的 from 和 size 参数来实现。from 参数定义要跳过的匹配数,默认为 0。size 参数是返回的最大匹配数,这两个参数一起定义了一页结果。
但是要避免使用 from 和 size 分页太深或一次请求太多结果的情况。搜索请求通常跨越多个分片。每个分片必须将其请求的命中和任何先前页面的命中加载到内存中。对于深层页面或大量结果,这些操作可能会显著增加内存和 CPU 使用率,从而导致性能下降或节点故障。
默认情况下,不能使用 from 和 size 来翻阅超过 10000 个匹配结果。此限制是 index.max_result_window 索引设置设定的一项保障措施。如果您需要翻阅超过 10,000 个匹配项,请使用 search_after 来实现。
简单概括就是 Elasticsearch 使用的 from 和 size 来实现分页,但是不建议使用 from 和 size 这种方式来实现深度分页,当分页深度超过 10000 的时候就不建议使用 from 和 size 来实现了,否则会大量占用内存和 CPU,也就是说我们上面的分页在深度分页的时候会有性能问题。
Elasticsearch 分页的内部执行过程分析
在 Elasticsearch 搜索是一个两阶段的过程,分别为查询阶段和取回阶段。
查询阶段
- 广播查询请求:客户端发送查询请求到某个节点,该节点会将查询请求广播到索引的所有分片上。
- 分片处理:每个分片在本地执行独立查询,根据查询条件得到符合条件的文档,并会为每个文档计算得分,每个分片中会按照得分来对文档进行排序,然后保留得分靠前的文档 ID。
- 合并结果:各分片将本地的部分结果返回给协调节点,协调节点会对这些结果进行合并排序,得到需要返回的额文档 ID。
取回阶段
- 获取文档详情:根据文档 ID,向包含这些文档的分片发送查询请求,获取文档的详细内容。
- 返回结果到客户端:协调节点在收到所有的文档内容后,再进行整理得到最终的文档,返回给客户端。
Elasticsearch 分页过程的问题
假设在一个有 3 个主分片的索引中进行分页搜索,每 10 个文档为一页数据,当请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,返回给协调节点 ,协调节点对 30 个结果排序得到全部结果的前 10 个,这个并没有什么问题。
当我们请求第 1000 页的时候,就需要每个分片返回 10001 到 10010 的文档,然后返回给协调节点,最后协调节点对全部 30030 个结果排序,最后丢弃掉这些结果中的 30020 个结果,很明显这里有一个非常大的内存占用的浪费,这就是 from 和 size 方式分页的问题,也就是我们常说的深度分页问题。
Elasticsearch 分页之 Search After
Elasticsearch 官方文档关于 Search After 的介绍比较多,这里简单截图如下,想了解更多点击以下超链接跳转。
Elasticsearch 分页官方文档
Elasticsearch 分页之 Search after
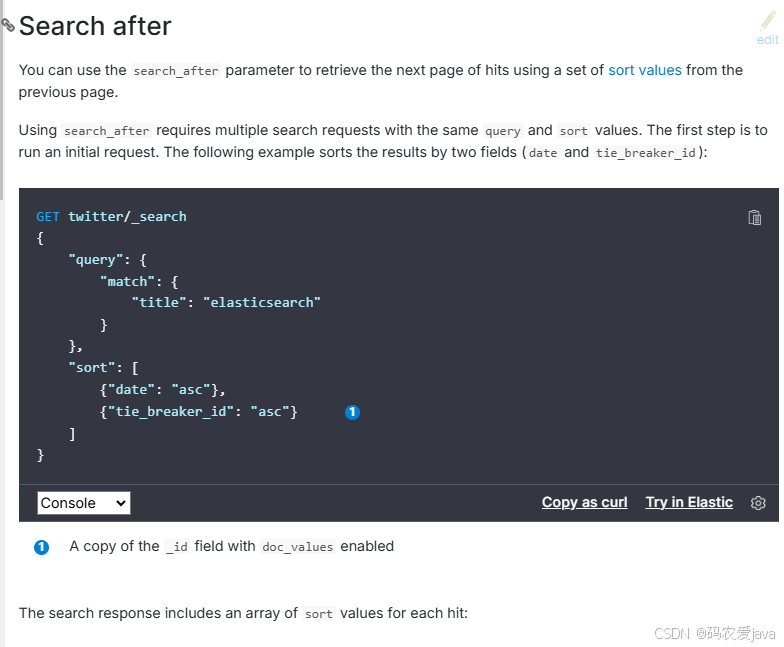
Elasticsearch 的 Search after 的分页是基于上一次查询结果的最后一条数据的指定字段值来进行下一页数据的查询,它通过在查询请求中指定 search_after 参数来实现。与传统的分页方式(from 和 size 参数)不同,Search after 不需要记录页码,也不会受到 from + size 的深度限制,能更高效地处理深层分页问题,因为每一页的数据依赖于上一页最后一条数据,所以无法进行跳页。
Java API 使用 Elasticsearch 的 search_after 实现分页
我们上面了解了 Elasticsearch 的 search_after 分页原理,现在我们使用 Java API 实现分页。代码如下:
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public List<CarDO> searchAfter(int lastId, int pageSize) {
//使用 searchAfter 分页
SearchRequest searchRequest = new SearchRequest("car_7");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查询所有的数据
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//使用 search after 分页需要设置 from 为 0
searchSourceBuilder.from(0);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.searchAfter(new Object[]{lastId});
//设置超时时间 超过 60秒还没有返回则返回一个超时错误
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//定义排序规则
SortBuilder<FieldSortBuilder> id4Sort = SortBuilders.fieldSort("id").order(SortOrder.ASC);
searchSourceBuilder.sort(id4Sort);
searchRequest.source(searchSourceBuilder);
List<CarDO> carList = new ArrayList<>();
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
org.elasticsearch.search.SearchHit[] hits = search.getHits().getHits();
if (Objects.nonNull(hits) && hits.length > 0) {
//下一次分页的起始点
lastId = Integer.parseInt(hits[hits.length - 1].getSortValues()[0].toString());
}
for (org.elasticsearch.search.SearchHit hit : hits) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
CarDO carDO = JSON.parseObject(JSON.toJSONString(sourceAsMap), CarDO.class);
carDO.setLastId(lastId);
carList.add(carDO);
}
} catch (IOException e) {
e.printStackTrace();
}
return carList;
}
我们来分析一下上面这段代码:
- lastId:上一次查询的最后一个 id,我们需要使用这个 id 来查询下一页的数据。
- pageSize:每页显示的条数。
- from:从第几条开始查询,使用 search_after 的时候需要设置为 0。
- searchSourceBuilder.searchAfter(new Object[]{lastId}):从 lastId 开始查询,用于指定分页的起始位置,它接收上一页最后一条数据的排序值数组。
- searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)):设置超时时间,超过 60 秒还没有返回则返回一个超时错误。
- searchSourceBuilder.sort(id4Sort):指定排序的字段和顺序,用于确定 search_after 分页的顺序,这里我们按照 id 排序,使用 search_after 进行分页查询,必须定义一个排序字段。也可以指定按照某个日期字段升序或降序排序,或者按照多个字段的组合排序,排序字段的选择要确保在整个查询过程中能够唯一标识每一条数据。
以上就是使用 search_after 实现 Elasticsearch 分页的核心代码的解释。
scroll-search 分页
Elasticsearch 还提供了 scroll-search 的方式来实现分页,官方文档如下:
scroll-search 分页官方文档
官方文档不建议使用 scroll-search 实现 Elasticsearch 深度分页,推荐使用 search_after 实现深度分页,因为官方文档已经不在推荐使用,这里就不在对 scroll-search 分页进行代码演示了,这里只简单对 scroll-search 进行简单优缺点分析如下:
优点:
- 深度分页性能较好:可以满足大量数据的深度分页场景,在处理深度分页时性能稳定,不会像 from/size 分页那样,随着分页深度的增加,ES 需要遍历和丢弃的文档增多而导致性能显著下降(但已不推荐使用,推荐使用 search_after 来实现)。
- 打破结果窗口限制:不受 index.max_result_window 限制,能方便地进行全量数据的遍历处理,可用于导出大量数据操作。
- 查询结果稳定性好:因为 scroll-search 基于快照查询,在整个 scroll 查询过程中,只要快照有效,查询结果是稳定的,不会出现遗漏或重复数据的情况,对于需要准确获取大量数据但对数据实时性要求不敏感的场景非常实用。
缺点:
- 数据实时性差:因为 scroll-search 是基于快照查询,Scroll 上下文维护的搜索结果是在快照创建时的数据状态,因此有可能查询到的不是最新的数据,不适合数据实时性要求高的业务场景。
- 内存占用问题:因为 scroll-search 是基于快照查询,需要维护快照,会占用额外的内存资源,如果处理的数据量非常大,可能会对服务器内存造成较大压力,需要合理设置相关参数并关注服务器资源使用情况。
- 数据过期问题:scroll-search 查询结果是快照查询,如果快照过期,过期后需要重新初始化查询,会导致整个过程变的更为复杂。
- 不支持跳页。
总结:本篇分享了 Elasticsearch 三种分页方式的实现,并对两种常用的分页方式进行了代码演示,深度分页推荐使用 search_after 的方式实现,希望可以帮助到对 Elasticsearch 分查询不太熟悉的朋友。
如有不正确的地方欢迎各位指出纠正。