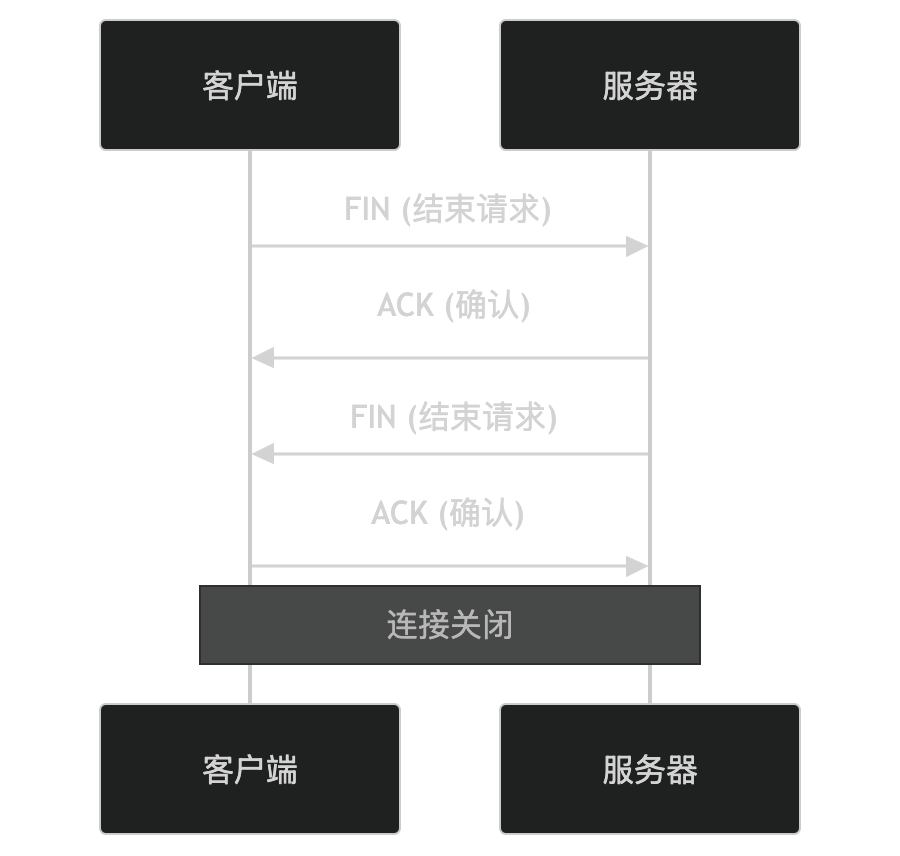
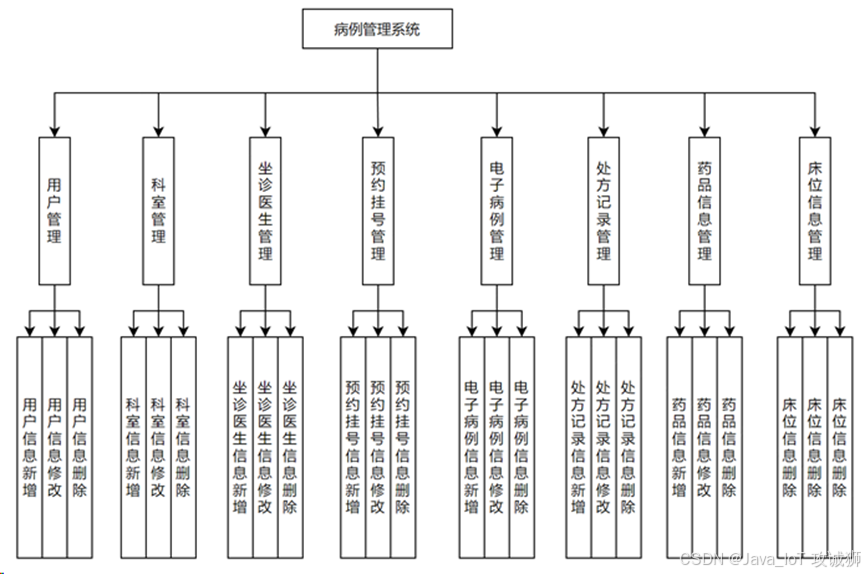
什么是分类问题?
分类问题涉及到预测某物是一种还是另一种。
例如,你可能想要:
| 问题类型 | 具体内容 | 例子 |
|---|---|---|
| 二元分类 | 目标可以是两个选项之一,例如yes或no | 根据健康参数预测某人是否患有心脏病。 |
| 多类分类 | 目标可以是两个以上选项之一 | 判断一张照片是食物、人还是狗。 |
| 多标签分类 | 目标可以被分配多个选项(标签) | 预测维基百科文章的分类(例如数学、科学和哲学) |
分类和回归是最常见的机器学习问题之一。
在本笔记本中,我们将使用PyTorch解决几个不同的分类问题。
换句话说,获取一组输入并预测这些输入属于哪个类。
本篇文章包括的内容
在本文中,我们将重申PyTorch工作流。
除了试图预测一条直线(预测一个数字,也称为回归问题),我们将研究一个分类问题。
具体来说,我们将涵盖:
| 主题 | 内容 |
|---|---|
| 分类神经网络的结构 | 神经网络几乎可以有任何形状或大小,但它们通常遵循类似的平面图。 |
| 准备好二进制分类数据 | 数据几乎可以是任何东西,但为了开始,我们将创建一个简单的二进制分类数据集。 |
| 构建PyTorch分类模型 | 在这里,我们将创建一个模型来学习数据中的模式,我们还将选择损失函数,优化器并构建特定于分类的训练循环。 |
| 将模型拟合到数据(训练) | 我们已经有了数据和模型,现在让模型尝试在(训练)数据中找到模式。 |
| 做出预测和评估模型(推理) | 我们的模型在数据中发现了模式,让我们将其发现与实际(测试)数据进行比较。 |
| 改进模型(从模型的角度) | 我们已经训练和评估了一个模型,但它不起作用,让我们尝试一些事情来改进它。 |
| 非线性 | 到目前为止,我们的模型只能模拟直线,那么非线性(非直线)的直线呢? |
| 复制非线性函数 | 我们使用非线性函数来帮助建模非线性数据,但是这些函数是什么样子的呢? |
| 用多类分类把它们放在一起 | 让我们把到目前为止我们所做的关于二分类和一个多类分类问题结合起来。 |
0 分类神经网络的结构
在开始编写代码之前,让我们先看看分类神经网络的一般架构:
| 超参数 | 二元分类 | 多元分类 |
|---|---|---|
| 输入层形状(in_features) | 与心脏病预测的特征数量相同(例如年龄、性别、身高、体重、吸烟状况的5项) | 相同 |
| 隐藏层 | 特定问题,最小值= 1,最大值=无限 | 相同 |
| 每个隐藏层的神经元 | 特定于问题,一般为10到512 | 相同 |
| 输出层形状(out_features) | 1(一类或另一个类) | 每类一个 |
| 隐藏层激活 | 通常是ReLU(整流线性单元),但也可以是许多其他单元 | 相同 |
| 输出激活 | Sigmoid (torch.sigmoidin PyTorch) | Softmax (torch.softmax in PyTorch) |
| 损失函数 | 二进制交叉熵 Binary crossentropy (torch.nn.BCELossin PyTorch) | Cross entropy (torch.nn.CrossEntropyLoss in PyTorch) |
| 优化器 | SGD (stochastic gradient descent随机梯度下降), Adam (see torch.optim for more options) |
相同 |
当然,这个分类神经网络组件的成分表将根据您正在处理的问题而有所不同。
但这已经足够开始了。
我们将在本文中亲身体验这种设置。
1 准备好二进制分类数据
让我们从制作一些数据开始。
我们将使用Scikit-Learn中的make_circles()方法生成两个带有不同颜色圆点的圆。
from sklearn.datasets import make_circles
# Make 1000 samples
n_samples = 1000
# Create circles
X, y = make_circles(n_samples,
noise=0.03, # a little bit of noise to the dots
random_state=42) # keep random state so we get the same values
print(X)
print(y)
输出为:
[[ 0.75424625 0.23148074]
[-0.75615888 0.15325888]
[-0.81539193 0.17328203]
...
[-0.13690036 -0.81001183]
[ 0.67036156 -0.76750154]
[ 0.28105665 0.96382443]]
[1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 0 1 1 0 1 0 0 1 0 0 0 1 1 1 0 0 1 0 0 0 1
...
1 1 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 1 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0
0]
数据有些多,我们只看前五个数值。
print(f"First 5 X features:\n{
X[:5]}")
print(f"\nFirst 5 y labels:\n{
y[:5]}")
输出为:
First 5 X features:
[[ 0.75424625 0.23148074]
[-0.75615888 0.15325888]
[-0.81539193 0.17328203]
[-0.39373073 0.69288277]
[ 0.44220765 -0.89672343]]
First 5 y labels:
[1 1 1 1 0]
看起来每个y值对应两个X值。
让我们继续遵循数据浏览器的座右铭:可视化、可视化、可视化,并将它们放入pandas DataFrame中。
# Make DataFrame of circle data
import pandas as pd
circles = pd.DataFrame({
"X1": X[:, 0],
"X2": X[:, 1],
"label": y
})
print(circles.head(10))
输出为:
X1 X2 label
0 0.754246 0.231481 1
1 -0.756159 0.153259 1
2 -0.815392 0.173282 1
3 -0.393731 0.692883 1
4 0.442208 -0.896723 0
5 -0.479646 0.676435 1
6 -0.013648 0.803349 1
7 0.771513 0.147760 1
8 -0.169322 -0.793456 1
9 -0.121486 1.021509 0
看起来每一对X特征(X1和X2)的标签(y)值为0或1。
这告诉我们,我们的问题是二元分类,因为只有两个选项(0或1)。
每个类有多少个值?
# Check different labels
print(circles.label.value_counts())
输出为:
label
1 500
0 500
Name: count, dtype: int64
每个500,又好又平衡。
我们把它们画出来。
# Visualize with a plot
import matplotlib.pyplot as plt
plt.scatter(x=X[:, 0],
y=X[:, 1],
c=y,
cmap=plt.cm.RdYlBu)
plt.show()

好吧,看来我们有问题要解决了。
让我们来看看如何构建PyTorch神经网络来将点分类为红色(0)或蓝色(1)。
[!NOTE]
这个数据集通常被认为是机器学习中的一个玩具问题(一个用来尝试和测试事物的问题)。
但它代表了分类的关键,你有一些用数值表示的数据你想建立一个能够分类的模型,在我们的例子中,把它分成红点或蓝点。
1.1输入输出形状
深度学习中最常见的错误之一是形状错误。
张量和张量操作的形状不匹配将导致模型错误。
我们会在整个课程中看到很多这样的例子。
没有办法保证它们不会发生,但它们会发生。
相反,您可以做的是不断地熟悉您正在处理的数据的形状。
我喜欢把它称为输入和输出形状。
问问你自己:
“我的输入和输出是什么形状?”
让我们来看看。
# Check the shapes of our features and labels
print(X.shape)
print( y.shape)
输出为:
(1000, 2)
(1000,)
看来我们在第一个维度上找到了匹配。
有1000个X和1000个y。
但是X上的第二次元是什么?
它通常有助于查看单个样本的值和形状(特征和标签)。
这样做将帮助您了解期望从模型中得到的输入和输出形状。
# View the first example of features and labels
X_sample = X[0]
y_sample = y[0]
print(f"Values for one sample of X: {
X_sample} and the same for y: {
y_sample}")
print(f"Shapes for one sample of X: {
X_sample.shape} and the same for y: {
y_sample.shape}")
输出为:
Values for one sample of X: [0.75424625 0.23148074] and the same for y: 1
Shapes for one sample of X: (2,) and the same for y: ()
这告诉我们X的第二维意味着它有两个特征(向量),而y只有一个特征(标量)。
我们有两个输入对应一个输出。
1.2将数据转换为张量,并创建训练和测试分割
我们已经研究了数据的输入和输出形状,现在让我们为使用PyTorch和建模做好准备。
具体来说,我们需要:
1 将我们的数据转换为张量(现在我们的数据是在NumPy数组中,PyTorch更倾向使用PyTorch张量)。
2 将我们的数据分成训练集和测试集(我们将在训练集上训练一个模型来学习X和y之间的模式,然后在测试数据集上评估这些学习到的模式)。
# Turn data into tensors
# Otherwise this causes issues with computations later on
import torch
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# View the first five samples
print(X[:5])
print(y[:5])
输出为:
tensor([[ 0.7542, 0.2315],
[-0.7562, 0.1533],
[-0.8154, 0.1733],
[-0.3937, 0.6929],
[ 0.4422, -0.8967]])
tensor([1., 1., 1., 1., 0.])
现在我们的数据是张量格式,让我们把它分成训练集和测试集。
为此,让我们使用Scikit-Learn中的有用函数train_test_split()。
我们将使用test_size=0.2(80%训练,20%测试),因为分割是随机发生的,所以我们使用random_state=42,这样分割是可重复的。
# Split data into train and test sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2, # 20% test, 80% train
random_state=42) # make the random split reproducible
print(len(X_train), len(X_test), len(y_train), len(y_test) )
输出为:
800 200 800 200
好了!看起来我们现在有800个训练样本和200个测试样本。
2 构建PyTorch分类模型
我们已经准备好了一些数据,现在是时候建立一个模型了。
我们将把它分成几个部分。
1 设置与设备无关的代码(所以我们的模型可以在CPU或GPU上运行,如果它可用的话)。
2 通过子类化nn. module来构造一个模型。
3 定义损失函数和优化器。
4 创建一个训练循环(这将在下一节中介绍)。
好消息是,我们已经在上一篇章中完成了上述所有步骤。
不过现在我们要对它们进行调整,让它们与分类数据集一起工作。
让我们从导入PyTorch和torch.nn以及设置设备认知代码。
# Standard PyTorch imports
import torch
from torch import nn
# Make device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
输出为:
cuda
很好,现在设备已经设置好了,我们可以将它用于我们创建的任何数据或模型,PyTorch将在CPU(默认)或GPU上处理它(如果它可用)。
我们创建一个模型怎么样?
我们需要一个能够处理X数据作为输入并产生y数据形状的输出的模型。
换句话说,给定X(特征),我们希望我们的模型预测y(标签)。
这种有特征和标签的设置被称为监督学习。因为你的数据告诉你的模型,给定一个特定的输入,输出应该是什么。
要创建这样一个模型,它需要处理X和y的输入和输出形状。
还记得我说过输入和输出形状很重要吗?下面我们来看看为什么。
让我们创建一个模型类:
1 子类nn。Module(几乎所有PyTorch模型都是nn.Module的子类)。
2 创建2nn。构造函数中的线性层,能够处理X和y的输入和输出形状。
3 定义一个forward()方法,该方法包含模型的前向传递计算。
4 实例化模型类并将其发送到目标设备。
# 1. Construct a model class that subclasses nn.Module
class CircleModelV0(nn.Module):
def __init__(self):
super().__init__()
# 2. Create 2 nn.Linear layers capable of handling X and y input and output shapes
self.layer_1 = nn.Linear(in_features=2, out_features=5) # takes in 2 features (X), produces 5 features
self.layer_2 = nn.Linear(in_features=5, out_features=1) # takes in 5 features, produces 1 feature (y)
# 3. Define a forward method containing the forward pass computation
def forward(self, x):
# Return the output of layer_2, a single feature, the same shape as y
return self.layer_2(self.layer_1(x)) # computation goes through layer_1 first then the output of layer_1 goes through layer_2
# 4. Create an instance of the model and send it to target device
model_0 = CircleModelV0().to(device)
print(model_0)
输出为:
CircleModelV0(
(layer_1): Linear(in_features=2, out_features=5, bias=True)
(layer_2): Linear(in_features=5, out_features=1, bias=True)
)
这是怎么回事?
我们之前已经看到了一些这样的步骤。
唯一主要的变化是self.ayer_1和self.layer_2之间发生的变化。
self.ayer_1接受2个输入特征in_features=2,并产生5个输出特征out_features=5。
这被称为有5个隐藏单元或神经元。
这一层将输入数据从2个特征变成5个特征。
为什么要这样做?
这使得模型可以从5个数字而不仅仅是2个数字中学习模式,从而可能产生更好的输出。
我说潜在,是因为有时它不起作用。
你可以在神经网络层中使用的隐藏单元的数量是一个超参数(一个你可以自己设置的值),你不需要使用固定的值。
一般来说,越多越好,但也有太多的情况。您选择的数量将取决于您正在使用的模型类型和数据集。
由于我们的数据集既小又简单,我们将保持它很小。
隐藏单位的唯一规则是下一层,在我们的例子中,self。Layer_2必须采用与前一层out_features相同的in_features。
这就是为什么self.layer_2有in_features=5,它从self.layer_1出out_features=5。并对它们执行线性计算,将它们转换为out_features=1(与y相同的形状)。
如下图所示:

您也可以使用nn. Sequential执行与上述相同的操作。
nn.Sequential按照各层出现的顺序对输入数据执行前向传递计算。
# Replicate CircleModelV0 with nn.Sequential
model_0 = nn.Sequential(
nn.Linear(in_features=2, out_features=5),
nn.Linear(in_features=5, out_features=1)
).to(device)
print(model_0)
输出为:
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Linear(in_features=5, out_features=1, bias=True)
)
哇,这看起来比子类化nn,Module 简单多了。那么,为什么不总是使用nn.Sequential呢?
nn.Sequential对于直接计算来说是非常棒的,但是,正如名称空间所说,它总是按顺序运行。
因此,如果您希望发生其他事情(而不仅仅是直接的顺序计算),您将需要定义自己的自定义nn,Module子类。
现在我们有了一个模型,让我们看看当我们通过它传递一些数据时会发生什么。
# Make predictions with the model
untrained_preds = model_0(X_test.to(device))
print(f"Length of predictions: {
len(untrained_preds)}, Shape: {
untrained_preds.shape}")
print(f"Length of test samples: {
len(y_test)}, Shape: {
y_test.shape}")
print(f"\nFirst 10 predictions:\n{
untrained_preds[:10]}")
print(f"\nFirst 10 test labels:\n{
y_test[:10]}")
输出为:
Length of predictions: 200, Shape: torch.Size([200, 1])
Length of test samples: 200, Shape: torch.Size([200])
First 10 predictions:
tensor([[ 0.2511],
[ 0.3828],
[-0.1777],
[ 0.3730],
[-0.3103],
[-0.2288],
[ 0.2471],
[ 0.1035],
[-0.1714],
[ 0.3902]], device='cuda:0',