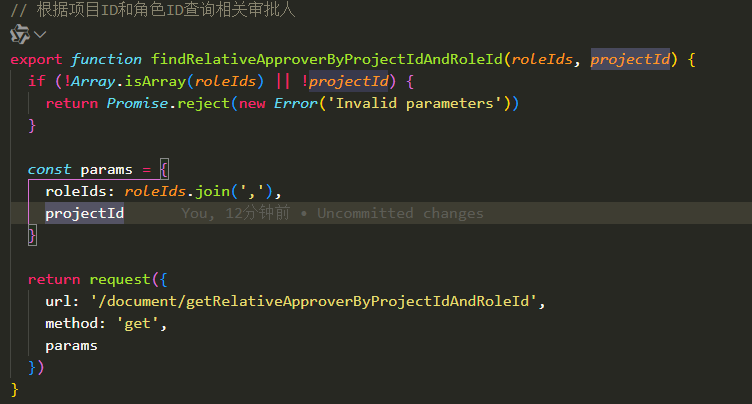
在 Apache Flink 中,并行度(Parallelism) 是控制任务并发执行的核心参数之一。Flink 提供了 多个层级设置并行度的方式 ,优先级从高到低如下:
层级 描述 设置方式 Operator Level 为某个具体的算子设置并行度 operator.setParallelism(n)Execution Environment Level 为整个流处理环境设置默认并行度 env.setParallelism(n)Client Level(提交作业时) 通过命令行指定全局并行度 flink run -p nSystem Level(系统配置) 在 flink-conf.yaml 中定义全局默认值 parallelism.default: n
Operator Level(算子级别) 优先级最高 可以为特定算子设置不同并行度,适用于数据倾斜或资源敏感操作 DataStream < String > = env. fromElements ( "a" , "b" , "c" ) ;
stream. map ( new MyMapFunction ( ) )
. setParallelism ( 4 )
. print ( ) ;
某个算子计算密集,需要更多资源 数据源分区数较少,但后续算子可并行化处理 Execution Environment Level(执行环境级别) 设置整个 Job 的默认并行度 如果未对某些算子单独设置,并使用此值 StreamExecutionEnvironment env = StreamExecutionEnvironment . getExecutionEnvironment ( ) ;
env. setParallelism ( 4 ) ;
DataStream < String > = env. fromElements ( "a" , "b" , "c" ) ;
stream. map ( new MyMapFunction ( ) ) . print ( ) ;
Client Level(客户端提交作业时) 使用命令行参数动态设置并行度 不修改代码即可适配不同运行环境(如测试/生产) flink run -p 4 -c com.example.MyJob ./myjob.jar
System Level(系统级别) 在 flink-conf.yaml 中设置全局默认并行度 对所有提交的作业生效(除非被更高级别覆盖) flink-conf.yaml):parallelism.default : 4
设置方式 是否推荐 场景 覆盖关系 Operator Level ✅✅✅ 特定算子优化 最高优先级 Execution Environment Level ✅✅ 整体统一配置 被 Operator 覆盖 Client Level (-p) ✅ 动态部署 被前两者覆盖 System Level (flink-conf.yaml) ⚠️ 兜底默认值 最低优先级
开发/测试环境 :使用 .setParallelism() 或 -p 命令行设置较小值(如1~4)生产环境 :
使用 flink-conf.yaml 设置基础并行度 使用 env.setParallelism() 明确控制默认值 为关键算子单独设置更高并行度(如窗口聚合、复杂逻辑) StreamExecutionEnvironment env = StreamExecutionEnvironment . getExecutionEnvironment ( ) ;
env. setParallelism ( 4 ) ;
env. fromSource ( kafkaSource, WatermarkStrategy . noWatermarks ( ) , "Kafka Source" )
. setParallelism ( 8 )
. map ( new MyMapFunction ( ) )
. keyBy ( keySelector)
. window ( TumblingEventTimeWindows . of ( Time . seconds ( 5 ) ) )
. process ( new MyProcessWindowFunction ( ) )
. print ( ) ;
并行度 TaskManager 数量 Slot 数量 资源要求 ≤ TM × slot ✅ 正常运行 ✅ 正常运行 资源充足 > TM × slot ❌ 无法启动 ❌ 无法启动 资源不足
✅ 建议:确保总并行度 ≤ 总 slot 数量
场景 建议设置 Kafka Source 并行度 = Kafka Topic 分区数 Map / FlatMap 根据 CPU 利用率设置 Keyed Window Aggregation 可适当提高并行度提升吞吐 Join / CoGroup 视数据分布决定是否提高并行度 Sink 若写入慢可适当增加并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment . getExecutionEnvironment ( ) ;
env. setParallelism ( 4 ) ;
env. fromElements ( "a" , "b" , "c" )
. map ( x -> x)
. setParallelism ( 2 )
. print ( ) ;
env. execute ( "Parallelism Example" ) ;
flink run -p 8 -c com.example.MyJob ./myjob.jar
层级 用途 是否推荐使用 Operator Level 控制单个算子并行度 ✅✅✅ 强烈推荐用于关键路径优化 Execution Environment Level 设置默认并行度 ✅✅ 推荐作为基础配置 Client Level 动态设置并行度 ✅ 适合多环境部署 System Level 全局兜底配置 ⚠️ 推荐配合其他方式使用