中文Wiki语料库主要指的是从中文Wikipedia(中文维基百科)提取的文本数据。维基百科是一个自由的、开放编辑的百科全书项目,覆盖了从科技、历史到文化、艺术等广泛的主题。
对于基于RAG的应用来说,把Wiki语料作为一个公有的语料库去更新大模型的知识时效,是非常有价值的,能够极大地提升模型的性能和应用范围。
-
Step 1. 首先,准备下 中文 的Wiki语料库
中文wiki语料库链接:Index of /zhwiki/latest/
外网下载,需执行以下命令进行学术加速:
export http_proxy=http://172.168.1.240:4080export https_proxy=http://172.168.1.240:4080 
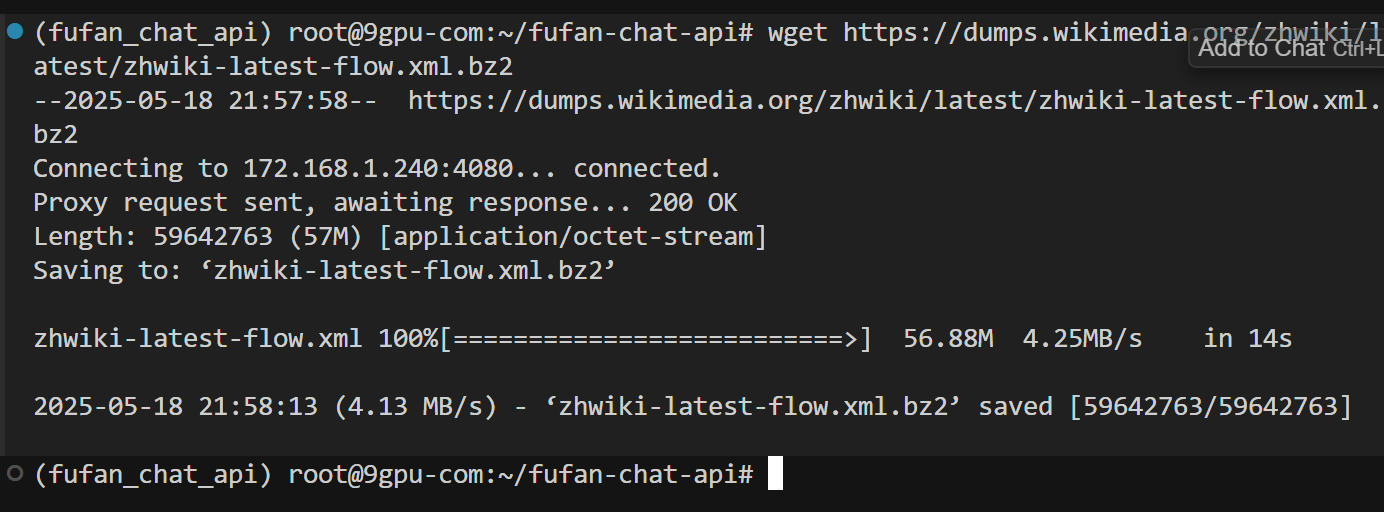
选择自己需要的压缩文件复制好下载链接后,在命令行终端执行代码:
wget https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-flow.xml.bz2文件将下载到当前目录下
-
Step 2. 执行前,安装第三方依赖包wikiextractor
WikiExtractor 是一个用于从维基百科等维基媒体项目的数据库 dumps 中提取文本的工具。做文本预处理和数据清洗。
pip install wikiextractor==0.1
-
Step 3. 下载文本处理模型
# 执行下载代码
python -m spacy download zh_core_web_lg-
Step 4. 查看数据处理脚本存放位置:/scripts/preprocess_wiki.py
import argparse
from tqdm import tqdm
import re
import html
import spacy
import os
import json
import subprocess
from pathlib import Path
import shutil
from concurrent.futures import ThreadPoolExecutor
from multiprocessing import Pool
import os
import json
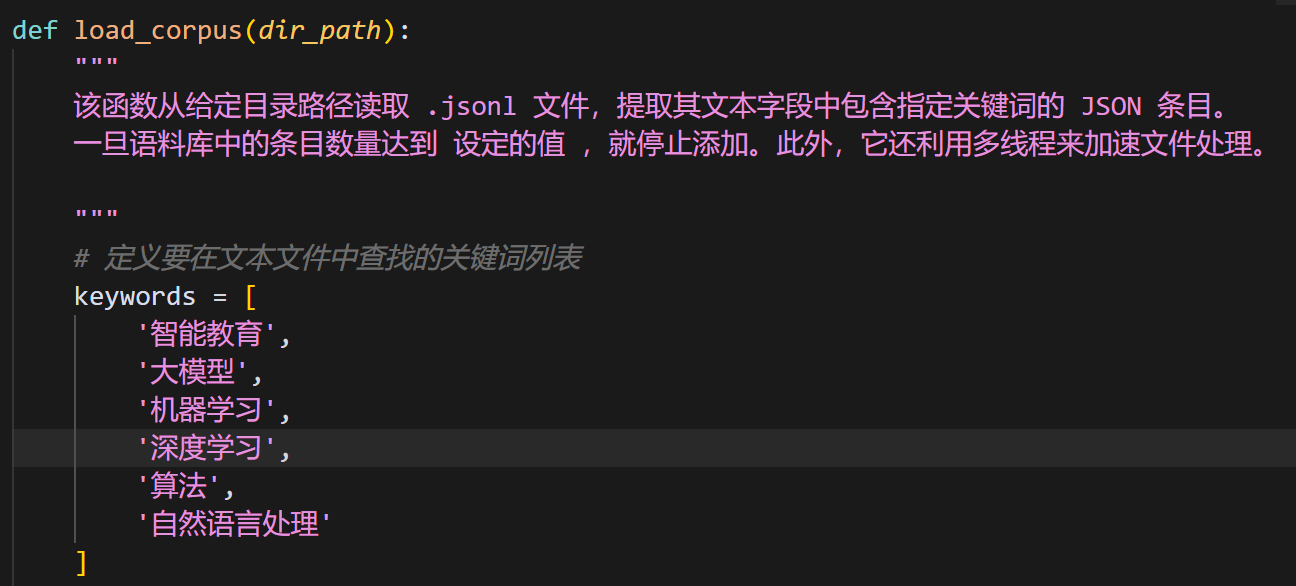
def load_corpus(dir_path):
"""
该函数从给定目录路径读取 .jsonl 文件,提取其文本字段中包含指定关键词的 JSON 条目。
一旦语料库中的条目数量达到 设定的值 ,就停止添加。此外,它还利用多线程来加速文件处理。
"""
# 定义要在文本文件中查找的关键词列表
keywords = [
'智能教育',
'大模型',
'机器学习',
'深度学习',
'算法',
'自然语言处理'
]
def iter_files(path):
"""遍历位于根路径下的所有文件。"""
if os.path.isfile(path):
# 如果路径是文件,直接返回该文件
yield path
elif os.path.isdir(path):
# 如果路径是目录,遍历该目录中的每个文件
for dirpath, _, filenames in os.walk(path):
for f in filenames:
yield os.path.join(dirpath, f)
else:
# 如果路径既不是目录也不是文件,抛出错误
raise RuntimeError('Path %s is invalid' % path)
def read_jsonl_file(file_path):
"""读取 .jsonl 文件的行,并将相关数据添加到语料库中。"""
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
json_data = json.loads(line)
# 检查 JSON 数据的文本字段中是否包含任何关键词
if any(keyword in json_data['text'] for keyword in keywords):
corpus.append(json_data)
# 如果语料库大小达到 100,停止添加
if len(corpus) == 100:
break
# 从目录中收集所有文件路径
all_files = [file for file in iter_files(dir_path)]
# 初始化语料库列表
corpus = []
# 使用 ThreadPoolExecutor 并行读取文件
with ThreadPoolExecutor(max_workers=args.num_workers) as executor:
# 提交任务以读取每个文件
for file_path in all_files:
executor.submit(read_jsonl_file, file_path)
# 返回填充好的语料库
return corpus
def create_segments(doc_text, max_length, stride):
"""
数据预处理,在处理需要特定输入长度限制的NLP模型时,如某些类型的文本分类或语言理解模型。
通过控制 max_length 和 stride 参数,可以灵活调整每个文本段的长度和重叠程度,以适应不同的处理需求。
"""
# 去除文档文本的首尾空白字符
doc_text = doc_text.strip()
# 使用NLP工具SpaCy解析文本,得到文档对象
doc = nlp(doc_text)
# 从文档对象中提取句子,并去除每个句子的首尾空格
sentences = [sent.text.strip() for sent in doc.sents]
# 初始化一个空列表,用于存储所有生成的文本段落
segments = []
# 使用步长 stride 遍历句子列表的索引
for i in range(0, len(sentences), stride):
# 将从当前索引开始的 max_length 个句子连接成一个字符串
segment = " ".join(sentences[i:i + max_length])
# 将构建的段落添加到列表中
segments.append(segment)
# 如果当前索引加上最大长度超过了句子列表的长度,停止循环
if i + max_length >= len(sentences):
break
# 返回包含所有段落的列表
return segments
def basic_process(title, text):
# 使用html.unescape函数来解码HTML实体,恢复文本中的特殊字符
title = html.unescape(title)
text = html.unescape(text)
# 删除文本首尾的空白字符
text = text.strip()
# # 如果标题含有特定的消歧义标记,则不处理这类页面
if '(disambiguation)' in title.lower():
return None, None
if '(disambiguation page)' in title.lower():
return None, None
# 排除以列表、索引或大纲开头的页面,这些页面大多只包含链接
if re.match(r'(List of .+)|(Index of .+)|(Outline of .+)',
title):
return None, None
# 排除重定向页面
if text.startswith("REDIRECT") or text.startswith("redirect"):
return None, None
# 如果文本以 ". References." 结尾,则删除该部分
if text.endswith(". References."):
text = text[:-len(" References.")].strip()
# 删除文本中的特定格式标记,如引用标记
text = re.sub('\{\{cite .*?\}\}', ' ', text, flags=re.DOTALL)
# 替换或删除不必要的格式和标签
text = text.replace(r"TABLETOREPLACE", " ")
text = text.replace(r"'''", " ")
text = text.replace(r"[[", " ")
text = text.replace(r"]]", " ")
text = text.replace(r"{{", " ")
text = text.replace(r"}}", " ")
text = text.replace("<br>", " ")
text = text.replace(""", "\"")
text = text.replace("&", "&")
text = text.replace("& amp;", "&")
text = text.replace("nbsp;", " ")
text = text.replace("formatnum:", "")
# 删除特定HTML标签内的文本,如<math>, <chem>, <score>
text = re.sub('<math.*?</math>', '', text, flags=re.DOTALL)
text = re.sub('<chem.*?</chem>', '', text, flags=re.DOTALL)
text = re.sub('<score.*?</score>', '', text, flags=re.DOTALL)
# 使用正则表达式删除样式相关的属性,例如:item_style, col_style等
text = re.sub('\| ?item[0-9]?_?style= ?.*? ', ' ', text)
text = re.sub('\| ?col[0-9]?_?style= ?.*? ', ' ', text)
text = re.sub('\| ?row[0-9]?_?style= ?.*? ', ' ', text)
text = re.sub('\| ?style= ?.*? ', ' ', text)
text = re.sub('\| ?bodystyle= ?.*? ', ' ', text)
text = re.sub('\| ?frame_?style= ?.*? ', ' ', text)
text = re.sub('\| ?data_?style= ?.*? ', ' ', text)
text = re.sub('\| ?label_?style= ?.*? ', ' ', text)
text = re.sub('\| ?headerstyle= ?.*? ', ' ', text)
text = re.sub('\| ?list_?style= ?.*? ', ' ', text)
text = re.sub('\| ?title_?style= ?.*? ', ' ', text)
text = re.sub('\| ?ul_?style= ?.*? ', ' ', text)
text = re.sub('\| ?li_?style= ?.*? ', ' ', text)
text = re.sub('\| ?border-style= ?.*? ', ' ', text)
text = re.sub('\|? ?style=\".*?\"', '', text)
text = re.sub('\|? ?rowspan=\".*?\"', '', text)
text = re.sub('\|? ?colspan=\".*?\"', '', text)
text = re.sub('\|? ?scope=\".*?\"', '', text)
text = re.sub('\|? ?align=\".*?\"', '', text)
text = re.sub('\|? ?valign=\".*?\"', '', text)
text = re.sub('\|? ?lang=\".*?\"', '', text)
text = re.sub('\|? ?bgcolor=\".*?\"', '', text)
text = re.sub('\|? ?bg=\#[a-z]+', '', text)
text = re.sub('\|? ?width=\".*?\"', '', text)
text = re.sub('\|? ?height=[0-9]+', '', text)
text = re.sub('\|? ?width=[0-9]+', '', text)
text = re.sub('\|? ?rowspan=[0-9]+', '', text)
text = re.sub('\|? ?colspan=[0-9]+', '', text)
text = re.sub(r'[\n\t]', ' ', text)
text = re.sub('<.*?/>', '', text)
text = re.sub('\|? ?align=[a-z]+', '', text)
text = re.sub('\|? ?valign=[a-z]+', '', text)
text = re.sub('\|? ?scope=[a-z]+', '', text)
text = re.sub('<ref>.*?</ref>', ' ', text)
text = re.sub('<.*?>', ' ', text)
text = re.sub('File:[A-Za-z0-9 ]+\.[a-z]{3,4}(\|[0-9]+px)?', '', text)
text = re.sub('Source: \[.*?\]', '', text)
# 清理可能因XML导出错误而残留的格式标签
# 使用正则表达式匹配并替换各种样式相关的属性
text = text.replace("Country flag|", "country:")
text = text.replace("flag|", "country:")
text = text.replace("flagicon|", "country:")
text = text.replace("flagcountry|", "country:")
text = text.replace("Flagu|", "country:")
text = text.replace("display=inline", "")
text = text.replace("display=it", "")
text = text.replace("abbr=on", "")
text = text.replace("disp=table", "")
title = title.replace("\n", " ").replace("\t", " ")
return title, text
def split_list(lst, n):
"""将一个列表分割成 n 个大致相等的部分。"""
# k 是每个部分的基本大小,m 是 len(lst) 除以 n 的余数
k, m = divmod(len(lst), n)
# 使用列表推导来生成子列表
# 计算每个部分的起始和结束索引
return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
def single_worker(docs):
"""
处理一个文档列表,对每个文档应用清洗和格式化操作。
"""
# 初始化结果列表,用于存储处理后的文档
results = []
# 遍历文档列表,使用 tqdm 库显示进度条
for item in tqdm(docs):
# 应用基础处理函数 basic_process 来处理每个文档的标题和文本
title, text = basic_process(item[0], item[1])
# 如果处理后的标题是 None(可能因为文档不符合处理要求),则跳过当前循环
if title is None:
continue
# 格式化标题,加上双引号
title = f"\"{title}\""
# 将处理和格式化后的标题和文本以元组形式添加到结果列表中
results.append((title, text))
return results
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Generate clean wiki corpus file for indexing.')
parser.add_argument('--dump_path', type=str)
parser.add_argument('--seg_size', default=None, type=int)
parser.add_argument('--stride', default=None, type=int)
parser.add_argument('--num_workers', default=4, type=int)
parser.add_argument('--save_path', type=str, default='clean_corpus.jsonl')
args = parser.parse_args()
# 设置临时目录用于存储WikiExtractor的输出
temp_dir = os.path.join(Path(args.save_path).parent, 'temp')
# 创建临时目录
os.makedirs(temp_dir)
# 使用wikiextractor从维基百科转储中提取文本,输出为JSON格式,过滤消歧义页面
subprocess.run(['python', '-m',
'wikiextractor.WikiExtractor',
'--json', '--filter_disambig_pages', '--quiet',
'-o', temp_dir,
'--process', str(args.num_workers),
args.dump_path])
# 载入处理后的语料库
corpus = load_corpus(temp_dir)
# 加载Spacy中文模型
nlp = spacy.load("zh_core_web_lg")
# 初始化一个字典来存储文档,以避免页面重复
documents = {}
# 使用tqdm显示进度条
for item in tqdm(corpus):
title = item['title']
text = item['text']
# # 检查标题是否已存在于字典中,以合并同一个标题下的不同部分
if title in documents:
documents[title] += " " + text
else:
documents[title] = text
# 开始预处理文本
print("Start pre-processing...")
documents = list(documents.items())
# 使用Python的多进程库,创建进程池进行并行处理
with Pool(processes=args.num_workers) as p:
result_list = list(tqdm(p.imap(single_worker, split_list(documents,args.num_workers))))
result_list = sum(result_list, [])
all_title = [item[0] for item in result_list]
all_text = [item[1] for item in result_list]
print("Start chunking...")
idx = 0
clean_corpus = []
# 使用spaCy的pipe方法进行高效的文本处理,指定进程数和批处理大小
for doc in tqdm(nlp.pipe(all_text, n_process=args.num_workers, batch_size=10), total=len(all_text)):
# 获取当前文档的标题
title = all_title[idx]
# 索引递增,指向下一个标题
idx += 1
# 初始化段落列表
segments = []
# 初始化单词计数器
word_count = 0
# 初始化段落的token列表
segment_tokens = []
# 遍历文档中的每个token
for token in doc:
# token(包括空格)添加到段落令牌列表
segment_tokens.append(token.text_with_ws)
# 如果令牌不是空格也不是标点
if not token.is_space and not token.is_punct:
# 单词计数加一
word_count+=1
# 如果单词计数达到100,则重置计数器,生成一个新段落
if word_count == 100:
word_count = 0
segments.append(''.join([token for token in segment_tokens]))
segment_tokens = []
# 检查最后是否还有剩余的单词没有形成完整段落
if word_count != 0:
for token in doc:
segment_tokens.append(token.text_with_ws)
if not token.is_space and not token.is_punct:
word_count+=1
if word_count == 100:
word_count = 0
segments.append(''.join([token for token in segment_tokens]))
break
# 检查最后一组token是否已添加到segments
if word_count != 0:
segments.append(''.join([token for token in segment_tokens]))
for segment in segments:
text = segment.replace("\n", " ").replace("\t", " ")
# 将处理后的标题和文本以字典形式添加到清洗后的语料库列表
clean_corpus.append({"title": title, "text": text})
# 删除临时目录及其内容
shutil.rmtree(temp_dir)
print("Start saving corpus...")
# 检查保存路径的目录是否存在,如果不存在则创建
os.makedirs(os.path.dirname(args.save_path), exist_ok=True)
# 打开指定的文件路径进行写入,设置编码为utf-8
with open(args.save_path, "w", encoding='utf-8') as f:
# 遍历清洗后的语料库列表,每个元素都是一个包含标题和文本的字典
for idx, item in enumerate(clean_corpus):
# 将字典转换为JSON字符串格式,确保使用UTF-8编码来处理Unicode字符
json_string = json.dumps({
'id': idx, # 添加唯一ID
'title': item['title'], # 文章标题
'contents': item['text'] # 文章内容
}, ensure_ascii=False) # 确保不将Unicode字符编码为ASCII
# 将JSON字符串写入文件,并在每个条目后添加换行符
f.write(json_string + '\n')
print("Finish!")
-
Step 5. 定制化修改
-
Step 6. 执行数据处理脚本,将 wiki 数据转储处理成 JSONL 格式。
cd fufan-chat-api/scripts
conda activate fufan_chat_api
python preprocess_wiki.py
# 这里是 存放 wiki 原始数据的绝对路径
--dump_path /root/fufan-chat-api/zhwiki-latest-flow.xml.bz2
# 这里是 处理完文本的存储路径
--save_path /root/fufan-chat-api/knowledge_base/wiki/education.jsonl
python preprocess_wiki.py --dump_path /root/fufan-chat-api/zhwiki-latest-flow.xml.bz2 --save_path /root/fufan-chat-api/knowledge_base/wiki/education.jsonl