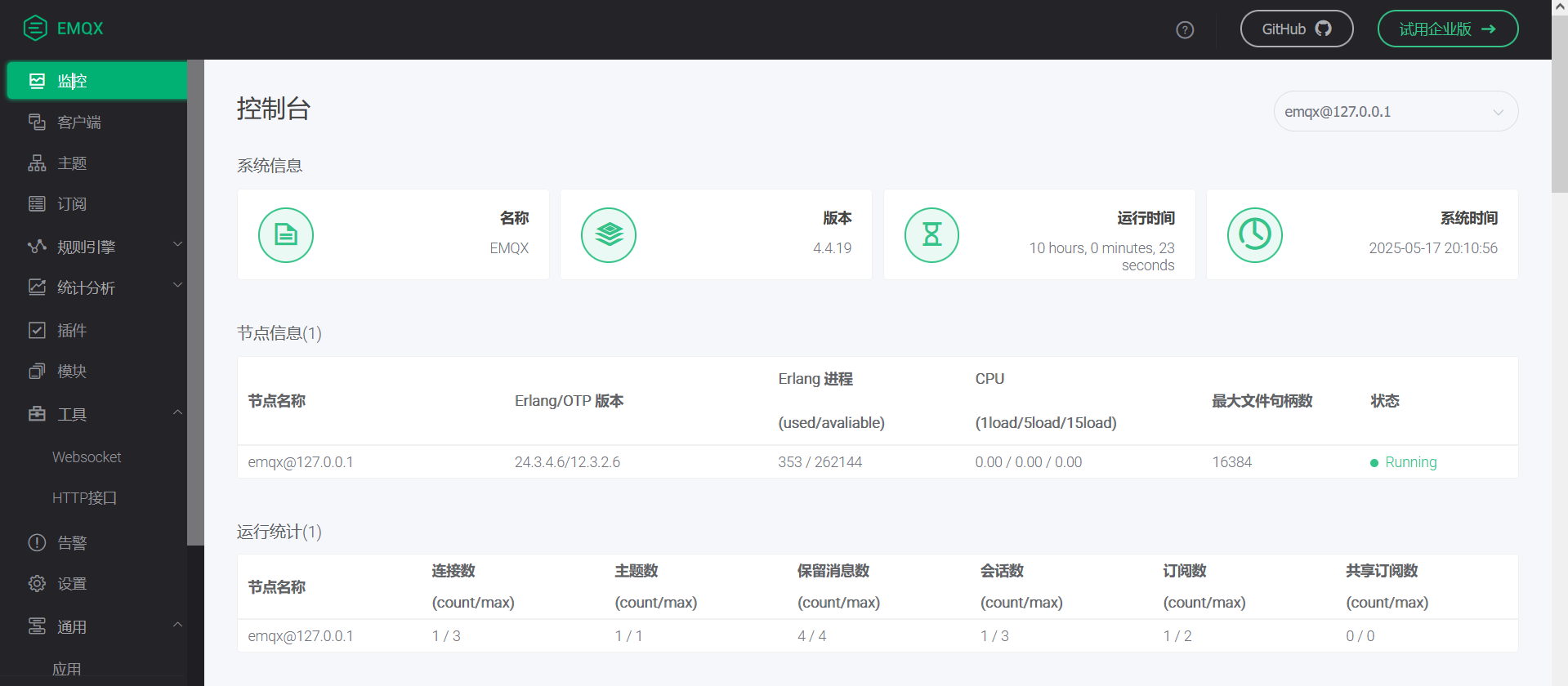
保证RabbitMQ消息的顺序性是一个常见的需求,尤其是在处理需要严格顺序的消息时。然而,默认情况下,RabbitMQ不保证消息的全局顺序,因为消息可能会通过不同的路径(例如不同的网络连接或线程)到达队列,并且消费者也可能并发地处理这些消息。不过,通过一些策略和设计模式,可以实现一定程度上的顺序性。
实现方法
1. 单个生产者与单个消费者
最直接的方式是确保只有一个生产者向特定队列发送消息,并且只有一个消费者从该队列中读取消息。这样可以保证消息的顺序性,因为没有其他生产者干扰消息的发送顺序,也没有其他消费者并行处理消息。
- 优点:实现简单。
- 缺点:缺乏扩展性和高可用性,性能受限于单一生产者和消费者的处理能力。
实现步骤:
- 单一队列:确保所有需要保持顺序的消息发送到同一个队列中。
- 单一消费者:在该队列上只配置一个消费者处理消息。如果有多个消费者,那么消息可能会被并行处理,从而破坏顺序。
- 消息持久化与确认机制:使用持久化消息和手动确认机制来确保消息不会因为消费者故障而丢失,同时维持消息的处理顺序。
代码示例
生产者代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class SingleProducer {
private final static String QUEUE_NAME = "orderly_queue";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明队列
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
String message = "Hello World!";
// 发布消息
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
}
}消费者代码
import com.rabbitmq.client.*;
public class SingleConsumer {
private final static String QUEUE_NAME = "orderly_queue";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
// 处理完消息后手动确认
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
};
// 设置为手动确认模式
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> {});
}
}关键点解释
-
队列声明:在两个地方都调用了
channel.queueDeclare方法,这确保了队列的存在。如果队列不存在,则会创建它;如果存在,则直接使用。 -
消息发布:生产者端使用
basicPublish方法向指定队列发送消息。这里没有设置任何特殊的属性或标志,因为我们主要关注的是消息的顺序性而非其他特性。 -
消费与确认:消费者端设置了手动确认模式(第二个参数为
false),这意味着只有当消息被成功处理后才会从队列中移除。这样即使处理过程中出现异常,消息也不会丢失,且重新投递时仍然能保持顺序。
通过上述方式,我们可以确保消息以它们被发送的顺序被接收和处理,前提是只有一个生产者和一个消费者在操作这个特定的队列。如果有多个生产者或者需要更复杂的顺序控制逻辑,则可能需要引入额外的机制如消息分组、事务等。
2. 使用优先级队列
RabbitMQ支持优先级队列,你可以设置消息的优先级。虽然这不是为了保证消息的顺序性而设计的,但在某些场景下可以通过调整消息的优先级来间接控制消息处理的顺序。
如何配置和使用优先级队列
1. 配置优先级队列
要创建一个支持优先级的消息队列,需要在声明队列时指定x-max-priority参数来定义队列的最大优先级级别。
2. 发送带优先级的消息
发送消息时,可以通过设置消息属性中的priority字段来指定该消息的优先级。
注意:使用优先级队列可能会影响性能,因为它要求RabbitMQ在存储和检索消息时进行额外的工作。虽然不能直接保证全局消息顺序,但可以通过设定消息的优先级来控制某些关键消息的处理顺序。
示例代码
以下是如何在Java客户端中配置和使用优先级队列的例子:
生产者代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class PriorityProducer {
private final static String QUEUE_NAME = "priority_queue";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明队列,并设置最大优先级
channel.queueDeclare(QUEUE_NAME, true, false, false,
Map.of("x-max-priority", 10));
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
for (int i = 0; i < 5; i++) {
int priority = i % 2 == 0 ? 5 : 1; // 设置不同的优先级
AMQP.BasicProperties properties = builder.priority(priority).build();
String message = "Message with priority: " + priority;
channel.basicPublish("", QUEUE_NAME, properties, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
}
}
}消费者代码
import com.rabbitmq.client.*;
public class PriorityConsumer {
private final static String QUEUE_NAME = "priority_queue";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列,注意这里不需要再次设置x-max-priority
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
};
boolean autoAck = false;
channel.basicConsume(QUEUE_NAME, autoAck, deliverCallback, consumerTag -> {});
}
}注意事项
- 性能影响:启用优先级队列可能会对性能产生一定影响,尤其是在高负载情况下。
- 公平分发:如果有多个消费者同时监听同一个队列,建议合理设置QoS(服务质量)限制,以避免某些消费者过载。
- 不保证绝对顺序:尽管优先级队列可以帮助你控制消费顺序,但在存在多个消费者的情况下,仍不能保证消息按照它们被发送的确切顺序被处理。
通过这种方式,你可以利用RabbitMQ的优先级队列功能来更好地管理你的消息处理顺序,特别是当你需要根据业务逻辑或紧急程度来调整消息处理顺序时。
3. 使用消息属性中的MessageId和CorrelationId
通过在发送消息时设置唯一的MessageId和关联的CorrelationId,可以在消费者端进行排序和验证。
注意:这种方法较复杂并且不是一种标准做法,两个属性主要用于标识消息和关联请求与响应,而不是用于控制消息的投递顺序。然而,我们可以结合这些属性和其他机制来间接地帮助我们管理和追踪消息顺序。通常需要自己管理消息的序列化与反序列化以及存储状态。
MessageId 和 CorrelationId 的用途
-
MessageId:通常用于唯一标识一条消息。它可以用来跟踪特定的消息实例,尤其是在分布式系统中。
-
CorrelationId:一般用于RPC(远程过程调用)场景,它将一个请求和它的响应关联起来。发送者可以在请求消息中设置
CorrelationId,然后接收者在响应消息中使用相同的值,这样发送者就可以识别出哪个响应对应于哪个请求。
保证消息顺序性的方法
虽然MessageId和CorrelationId不能直接用来保证消息的顺序性,但你可以结合以下策略来实现:
-
使用独立队列:为每种类型的消息创建单独的队列,并确保每个队列只有一个消费者处理消息。这可以避免多个消费者同时处理同一类型的消息导致的顺序问题。
-
消息分组:根据业务逻辑对消息进行分组,并确保同组内的消息按顺序处理。这可以通过设置路由键(Routing Key)或使用头信息(Headers Exchange)来实现。
-
应用层排序:如果上述方法不可行,你还可以考虑在应用层面对消息进行排序。例如,基于时间戳或者序列号,在消费端重新排序消息。
结合MessageId和CorrelationId的应用
尽管MessageId和CorrelationId不直接用于保证顺序性,它们可以帮助你在分布式环境中更好地追踪和管理消息:
- 使用
MessageId作为消息的唯一标识符,便于后续查询、重试等操作。 - 在需要执行请求-响应模式时,利用
CorrelationId匹配请求和响应,确保正确处理异步结果。
示例代码
下面提供了一个简单的示例,展示如何在生产者和消费者之间使用MessageId和CorrelationId,但这主要是一个演示,关于消息顺序性的保证仍需依赖前面提到的其他策略。
生产者代码片段
import com.rabbitmq.client.*;
// 设置连接和通道...
channel.basicPublish("", QUEUE_NAME,
new AMQP.BasicProperties.Builder()
.messageId("unique-message-id") // 设置MessageId
.correlationId("unique-correlation-id") // 设置CorrelationId
.build(),
messageBodyBytes);消费者代码片段
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String messageId = delivery.getProperties().getMessageId();
String correlationId = delivery.getProperties().getCorrelationId();
System.out.println("Received message with MessageId: " + messageId + ", CorrelationId: " + correlationId);
// 处理消息逻辑...
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {});综上所述,要保证RabbitMQ消息的顺序性,建议采用设计良好的消息路由和队列策略,而MessageId和CorrelationId更多是用于增强消息的可追踪性和关联性。
4. 消息分组
如果你的应用程序能够容忍部分消息无序,但对一组相关消息的顺序有严格要求,那么可以考虑将消息分组,并为每个组指定一个唯一的标识符。然后,确保同一组内的所有消息由同一个消费者处理。
实现思路
-
定义消息类型或组标识:首先,你需要为每条消息定义一个类型或者组标识符,用于区分不同的消息组。这可以通过消息的属性(如routing key)来实现。
-
创建独立的队列:针对每个消息组创建独立的队列。这样,属于同一组的所有消息都将被发送到同一个队列中,并由该队列对应的消费者按顺序处理。
-
配置交换机与队列的绑定规则:使用直接交换机(Direct Exchange)或主题交换机(Topic Exchange),并根据消息的类型或组标识进行绑定。这样,只有匹配特定路由键的消息才会被发送到相应的队列。
-
单个消费者处理每个队列:为了确保顺序性,应确保每个队列为单个消费者服务。如果需要提高消费能力,可以考虑增加更多队列和消费者,但要确保相同组的消息始终由同一个消费者处理。
示例代码
以下是一个简化的示例,展示了如何基于消息类型(即消息组)来路由消息,以保证其顺序性:
生产者端代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class MessageProducer {
private final static String EXCHANGE_NAME = "group_exchange";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
// 发送不同组的消息
String[] groups = {"groupA", "groupB"};
for (String group : groups) {
String message = "Message from " + group;
channel.basicPublish(EXCHANGE_NAME, group, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
}
}
}消费者端代码
import com.rabbitmq.client.*;
public class MessageConsumer {
private final static String EXCHANGE_NAME = "group_exchange";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
String queueName = channel.queueDeclare().getQueue();
// 绑定两个不同的组到各自的队列
channel.queueBind(queueName, EXCHANGE_NAME, "groupA");
channel.queueBind(queueName, EXCHANGE_NAME, "groupB");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
};
channel.basicConsume(queueName, true, deliverCallback, consumerTag -> {});
}
}注意,在这个例子中,所有消息都被发送到了同一个队列,但实际上,你可能想要为每个组创建独立的队列,并确保每个队列只有一个消费者来保证顺序性。
注意事项
- 确保你的应用逻辑正确地利用了消息分组的概念,使得相关的消息确实能够被正确分组。
- 考虑到性能和可扩展性,适当调整队列和消费者的数量。
- 对于高吞吐量的应用程序,还需要考虑如何高效地管理大量队列和绑定,以及如何优化资源使用。
这种方法虽然不能保证全局的消息顺序,但对于需要保证特定类型消息顺序的应用来说,是一个有效的方法。