为了后续查阅方便,推荐工具先放到前面
推荐工具
数字取证基础工具
综合取证平台
| 工具名称 | 类型 | 主要功能 | 适用场景 |
|---|---|---|---|
| EnCase Forensic | 商业 | 全面的证据获取和分析、强大的搜索能力 | 法律诉讼、企业调查 |
| FTK (Forensic Toolkit) | 商业 | 高性能处理和索引、集成内存分析 | 大规模数据处理 |
| Autopsy | 开源 | 多种分析模块、可扩展的插件系统 | 一般调查、教育环境 |
| X-Ways Forensics | 商业 | 低资源消耗、精细的数据分析 | 技术调查、详细分析 |
| Magnet AXIOM | 商业 | 计算机、移动和云取证、AI分析 | 整合多源证据 |
磁盘和文件系统分析
| 工具名称 | 类型 | 主要功能 | 适用场景 |
|---|---|---|---|
| The Sleuth Kit | 开源 | 低级文件系统分析、多种文件系统支持 | 文件系统调查 |
| TestDisk | 开源 | 分区恢复、boot扇区修复 | 数据恢复 |
| WinHex | 商业 | 十六进制编辑、磁盘检查 | 底层数据分析 |
| FTK Imager | 免费 | 磁盘镜像创建、基本分析 | 证据获取 |
| R-Studio | 商业 | 高级数据恢复、RAID重建 | 复杂恢复场景 |
内存取证
| 工具名称 | 类型 | 主要功能 | 适用场景 |
|---|---|---|---|
| Volatility Framework | 开源 | 全面内存分析、多系统支持 | 内存分析、恶意代码检测 |
| DumpIt | 免费 | 内存获取、易用性 | 快速内存采集 |
| Redline | 免费 | 内存和文件分析、威胁狩猎 | 恶意软件检测 |
| Rekall | 开源 | 内存分析框架、Python接口 | 高级内存分析 |
| Memoryze | 免费 | 内存获取和分析、恶意代码检测 | 事件响应 |
网络取证
| 工具名称 | 类型 | 主要功能 | 适用场景 |
|---|---|---|---|
| Wireshark | 开源 | 深入的协议分析、强大的过滤功能 | 网络通信分析 |
| NetworkMiner | 免费/商业 | 网络取证分析、数据提取 | 通信重建 |
| Zeek (Bro) | 开源 | 网络监控、安全分析 | 大规模网络分析 |
| Xplico | 开源 | 互联网流量解码、内容重建 | 通信内容分析 |
| Netwitness | 商业 | 网络威胁检测、取证分析 | 企业网络监控 |
其他网上收集来的(差不多都在github)。
反取证工具合集
-
Awesome-anti-forensic - 强大的反取证和取证工具集合,包括加密、隐写和属性修改工具。提供独立的启动映像,可安全擦除硬盘;取证浏览器;NTFS检查工具;Facebook内存取证工具;PDF分析工具;隐写检测工具以及安全删除工具等。
-
Awesome-memory-forensics - 为DFIR策划的内存取证研究资源列表,主要用于调查复杂的计算机攻击,尤其是那些足够隐蔽不会在硬盘上留下数据的攻击。
-
Awesome-forensics-1 - 丰富的取证资源集合,包含近300个开源取证工具和600篇取证博客文章。
日志与痕迹清除
-
WinLogs-Killer - 清除Windows保存的各种日志和历史文件的工具。可以删除Windows事件日志、远程桌面历史和最近打开的文件记录。
-
Forensia - 专为红队成员设计的反取证工具,可减少有效载荷耗尽并增加检测倒计时。功能包括卸载Sysmon驱动、根据古特曼算法粉碎文件、禁用USNJrnl和prefetch、删除日志、禁用事件日志、修改UserAssist时间戳等。
-
emerg - 内核模块,用于紧急启动二进制文件或脚本。在后台运行,当输入特定口令时触发预定义的操作。
数据隐藏与保护
-
Fishy - 基于文件系统的数据隐藏技术工具包,使用Python实现。收集多种利用文件系统层数据结构的方法,从常见文件访问方法中隐藏数据。
-
Myool - 提供取证保护、隐写和数据渗漏功能。使用AES-256加密文件并将其隐藏在PDF文件中,支持Windows和Linux平台。
-
Metadata Remover - 简单的元数据删除工具,用于从图像和视频中删除元数据以改善隐私。Python版本还支持音频和torrent文件。
高级反取证与监控
-
Kaiser - 具有无文件持久性、攻击和反取证能力的恶意软件概念验证。设计用于展示反取证和无文件功能,包括无文件保存、二进制执行、禁用事件日志服务,以及主动阻止被感染机器的取证分析。
-
Lockwatcher - 反取证监测软件,用于寻找未经授权的访问迹象并清除密钥或关闭系统。基于假设:如果有人试图在计算机被锁定时使用,可能试图获取实时数据,因此需要销毁这些数据。
反取证技术资源
-
Anti-forensic technologies - 反取证方法概述,介绍工作原理,包括修改时间戳、usnjrnl、元数据修改以及USB反取证等技术。
-
Anti Forensics - 关于在计算机上不留痕迹的艺术,旨在与常见取证工具对抗,防止取证测试。包含对取证保护方法的定义和调整说明。
-
Anti Forensics研究 - 展示常用取证工具包优势和劣势的研究报告,分为隐藏、修改和破坏数据的反取证工具研究,流行的多合一取证工具包评估,以及对这些工具包的文档策略研究。
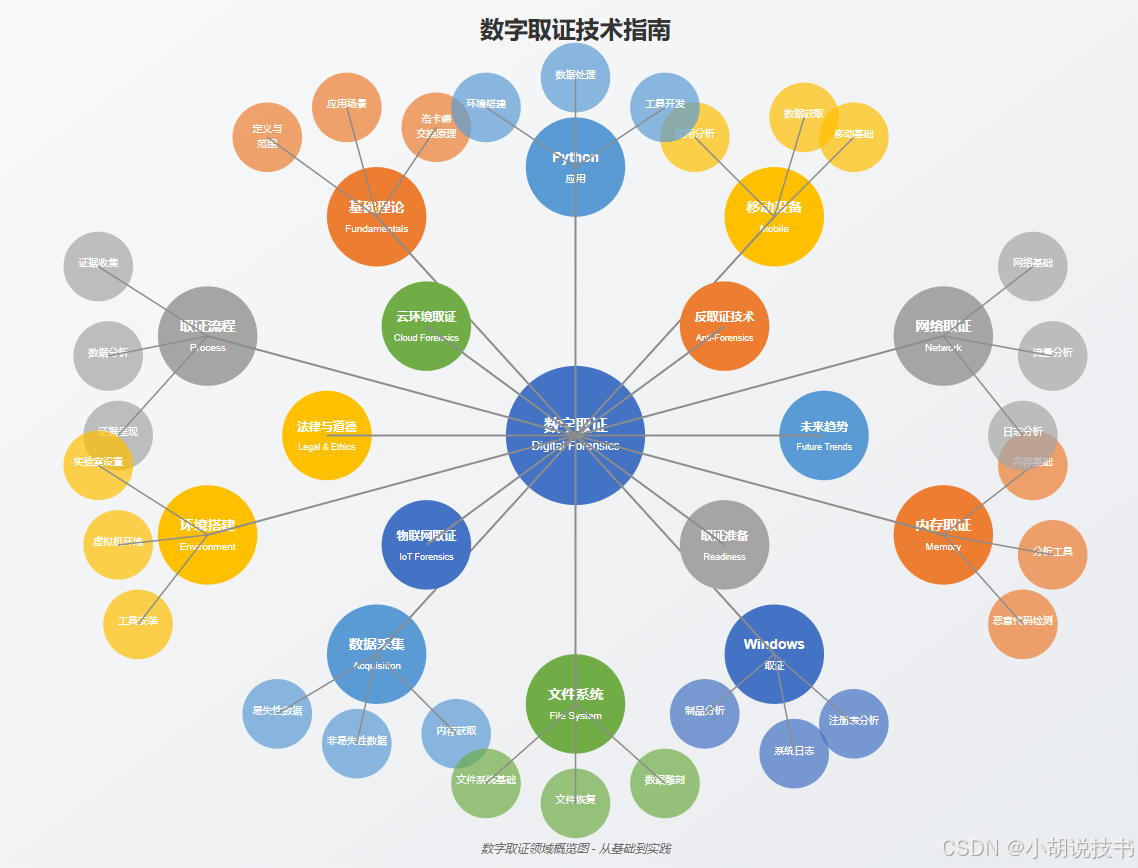
文章目录
- 推荐工具
- 一、数字取证基础
- 1.1 数字取证的定义与范围
- 1.2 数字取证的应用场景
- 1.3 洛卡德交换原理在数字取证中的应用
- 1.4 数字证据的特性与分类
- 二、数字取证流程与方法学
- 2.1 数字取证的基本流程
- 2.2 证据收集与保存
- 2.3 数据获取方法
- 2.4 数据分析技术
- 2.5 证据报告与呈现
- 三、数字取证环境搭建
- 3.1 取证实验室设置
- 3.2 虚拟机环境配置
- 3.3 取证工具安装与配置
- 四、数据采集技术
- 4.1 易失性数据采集
- 4.2 非易失性数据采集
- 4.3 内存获取技术
- 4.4 磁盘映像创建
- 五、文件系统取证
- 5.1 文件系统基础
- 5.2 Windows文件系统取证
- 5.3 Linux文件系统取证
- 5.4 文件恢复与数据雕刻
- 六、Windows系统取证
- 6.1 注册表分析
- 6.2 系统日志分析
- 6.3 Windows制品分析
- 6.4 时间线分析
- 七、内存取证
- 7.1 内存取证基础
- 7.2 内存采集技术
- 7.3 内存分析工具与方法
- 7.4 恶意代码检测
- 八、网络取证
- 8.1 网络取证基础
- 8.2 网络流量捕获与分析
- 8.3 网络日志分析
- 8.4 Web浏览器取证
- 九、移动设备取证
- 9.1 移动设备取证基础
- 9.2 移动设备数据获取
- 9.3 移动应用程序取证
- 9.4 云服务取证
- 十、Python在数字取证中的应用
- 10.1 Python取证环境搭建
- 10.2 使用Python处理取证数据
- 10.3 开发自定义取证工具
- 10.4 案例分析
- 十一、反取证技术与对抗
- 11.1 反取证概念与目标
- 11.2 数据隐藏技术
- 11.3 数据伪造与混淆
- 11.4 反取证对策
- 十二、数字取证工具推荐
- 12.1 商业取证工具
- 12.2 开源取证工具
- 12.3 反取证工具
- 12.4 专业领域取证工具
- 十三、云环境取证
- 13.1 云取证基础与挑战
- 13.2 云数据获取方法
- 13.3 主要云服务取证
- 13.4 云取证分析技术
- 十四、物联网与嵌入式设备取证
- 14.1 物联网取证的范围与挑战
- 14.2 嵌入式设备数据获取
- 14.3 智能家居设备取证
- 14.4 可穿戴设备和健康监测器
- 十五、取证准备与规划
- 15.1 取证就绪性概念
- 15.2 企业环境的取证准备
- 15.3 取证实验室设置与认证
- 15.4 事件响应与数字取证的集成
- 十六、法律与道德考虑
- 16.1 数字取证法律框架
- 16.2 证据可采性与法庭呈现
- 16.3 职业道德与最佳实践
- 十七、未来趋势与发展
- 17.1 人工智能与机器学习在取证中的应用
- 17.2 量子计算与加密挑战
- 17.3 区块链取证
- 17.4 新兴设备与技术
- 十八、结论与资源
- 18.1 数字取证的未来发展
- 18.2 持续教育与专业发展
- 18.3 推荐学习资源
- 18.4 总结与展望
可以先看理论:从逻辑学视角探析证据学的理论框架与应用体系;《证据学》大纲参考
一、数字取证基础
1.1 数字取证的定义与范围
数字取证(Digital Forensics)是一门应用科学,主要关注数字设备中的证据获取、保存、分析和呈现。作为传统法医学在数字世界的延伸,数字取证是连接计算机科学与法律系统的重要桥梁。
数字取证的核心目标包括:
- 确保数据完整性和不被篡改
- 恢复被删除、隐藏或加密的数据
- 重建数字事件的时间线
- 以符合法律标准的方式提供分析结果
随着技术的快速发展,数字取证的范围不断扩大,从早期的计算机和服务器取证,扩展到如今的移动设备、物联网设备、云环境以及虚拟现实等领域。
1.2 数字取证的应用场景
数字取证在多种场景中具有关键作用,不仅限于网络犯罪调查,还扩展到企业内部的信息安全维护和数据恢复等领域。
根据《Cyber Forensics up and Running》中的分类,数字取证主要应用于以下场景:
-
计算机犯罪调查:针对黑客入侵、恶意软件攻击等直接针对计算机系统的犯罪活动进行调查。
-
企业间谍与知识产权盗窃:调查公司内部或外部人员盗取商业机密、专利技术等行为。
-
金融欺诈与贪污:调查利用数字系统进行的金融犯罪活动。
-
电子证据发现(E-Discovery):在民事或刑事诉讼中,搜集和分析电子文档和数据。
-
人口贩卖与毒品犯罪:分析犯罪组织使用的数字通信和交易记录。
-
儿童保护:调查与儿童性剥削相关的数字证据。
-
谋杀案调查:从数字设备中获取可能与案件相关的信息,如位置数据、通信记录等。
-
反恐调查:分析恐怖组织的数字通信和活动痕迹。
近年来,企业内部的数字取证需求显著增长,主要用于内部调查、合规审计以及事件响应。
1.3 洛卡德交换原理在数字取证中的应用
洛卡德交换原理(Locard’s Exchange Principle)源于传统法医学,由法国犯罪学家埃德蒙·洛卡德提出,其核心理念是:“每次接触都会留下痕迹”。
在数字环境中,这一原理同样适用:用户与数字系统的每次交互都会留下数字痕迹,无论是有意还是无意。例如:
- 访问网站会在浏览器历史、缓存和cookies中留下记录
- 文件操作会修改文件的元数据和时间戳
- 系统活动会记录在各种日志文件中
- 网络连接会留下流量记录和会话信息
洛卡德交换原理为数字取证提供了理论基础,使调查人员能够通过收集和分析这些数字痕迹来重建事件,确定行为模式,并在某些情况下识别责任方。
1.4 数字证据的特性与分类
数字证据具有许多独特特性,包括:
- 易变性:数字证据易受到修改,可能被意外或恶意破坏
- 复制性:可以创建完全相同的副本,不会损失证据价值
- 潜在的隐藏性:证据可能被隐藏、加密或伪装
- 跨境性:数字证据可能分布在不同司法管辖区
- 数量庞大:可能涉及海量数据的筛选与分析
数字证据可以分为两大类:易失性数据和非易失性数据。易失性数据指存储在RAM等暂存介质中,断电后会丢失的数据,如运行中的进程、网络连接、打开的文件等。非易失性数据指存储在硬盘等持久存储设备中,断电后仍然保存的数据,如文件、注册表、系统日志等。
数字证据还可按来源分类:
- 计算机系统数据(操作系统、应用程序等)
- 网络数据(流量、日志、通信记录等)
- 移动设备数据(短信、通话记录、应用数据等)
- 云服务数据(在线存储、应用数据等)
- 物联网设备数据(智能家居设备、可穿戴设备等)
二、数字取证流程与方法学
2.1 数字取证的基本流程
数字取证流程需要系统化、标准化的方法,以确保证据的完整性和可靠性。遵循系统化流程至关重要,因为它能够确保调查过程的一致性和结果的可重现性,同时防止因操作不当导致的证据损坏或无效。
一个标准的数字取证流程通常包括以下几个阶段:
- 识别阶段(Identification):确定潜在证据的位置和类型,包括设备、数据源和存储介质。
- 收集阶段(Collection):以符合法律和技术标准的方式获取数字证据。
- 检验阶段(Examination):使用专业工具和技术处理收集到的数据,还原被删除的文件,提取元数据等。
- 分析阶段(Analysis):对检验结果进行深入分析,建立事件时间线,确定关联性。
- 呈现阶段(Presentation):以清晰、准确的方式呈现调查发现,撰写专业报告。
每个阶段都需要严格的文档记录,以建立证据链(Chain of Custody),确保证据的合法性和可接受性。
2.2 证据收集与保存
证据收集是数字取证中的关键环节,需要确保保持证据的完整性和法律效力。证据链(Chain of Custody)是跟踪证据从收集到呈现整个过程的文档记录,详细记录谁、何时、以何种方式接触和处理了证据。
证据收集与保存的基本原则包括:
- 最小化影响:尽可能减少对原始数据的改动,防止证据污染。
- 完整性验证:使用哈希值(如MD5、SHA-1、SHA-256)验证数据完整性。
- 详细记录:记录所有操作步骤、工具版本、硬件环境等。
- 安全存储:使用物理或逻辑写保护措施防止证据被更改。
- 多重备份:创建多个证据副本,保持原始证据的完整性。
保存数字证据完整性的方法包括:建立证据链、使用哈希算法验证、加密保护、数字签名、写保护器和写保护的证据存储设备。这些措施确保证据在法庭上的可接受性和可靠性。
2.3 数据获取方法
数据获取需要考虑易失性顺序(Order of Volatility),即先获取最易丢失的数据。一般的易失性顺序为:处理器缓存和寄存器 → 内存(RAM) → 交换文件和临时文件 → 磁盘数据 → 远程日志和监控数据 → 物理配置和网络拓扑。
主要的数据获取方法包括:
- 实时获取(Live Acquisition):在系统运行状态下获取数据,适用于捕获易失性数据。
- 离线获取(Dead Acquisition):关闭系统后获取数据,减少对原始数据的污染。
- 物理获取(Physical Acquisition):直接复制存储介质的物理扇区,可恢复被删除的数据。
- 逻辑获取(Logical Acquisition):复制文件系统中的文件和文件夹。
- 混合获取(Hybrid Acquisition):结合实时和离线方法的优势。
数字取证镜像格式主要包括:原始格式(dd/Raw)、专有格式(如E01/EnCase)和AFF(高级取证格式)。原始格式直接复制原始数据;专有格式通常包括元数据和压缩功能;AFF是开源格式,提供压缩和加密功能。
2.4 数据分析技术
数据分析是将原始数据转化为有意义信息的过程,涉及多种技术和方法:
- 时间线分析:根据时间戳重建事件序列,识别异常活动。
- 关键词搜索:查找与调查相关的特定词汇或短语。
- 文件签名分析:验证文件类型与扩展名是否匹配,识别伪装文件。
- 元数据分析:提取和分析文件的创建时间、修改时间、作者等信息。
- 数据恢复:恢复被删除或隐藏的数据。
- 日志分析:分析系统、应用和网络日志,识别可疑活动。
- 网络流量分析:检查网络通信,识别恶意连接和数据泄露。
- 关联分析:建立不同数据源之间的关联,形成全面的证据链。
绘制事件时间线和可视化表示是关键的分析技术,可以帮助调查人员理解复杂事件的顺序和关系。链接分析则可以揭示不同数据元素之间的关联,帮助识别模式和关系网络。
2.5 证据报告与呈现
证据的呈现是数字取证过程的最后阶段,需要将技术发现转化为清晰、客观的报告。好的取证报告应详细记录所进行的工作和使用的方法,同时以适合不同受众(如技术专家、法律专业人士或非技术人员)理解的方式呈现结果。
一份专业的数字取证报告通常包括:
- 执行摘要:简明扼要地概述主要发现和结论。
- 调查背景:描述案件背景、调查目标和范围。
- 方法学:详细说明使用的工具、技术和程序。
- 证据收集:描述证据的来源、获取方式和保存措施。
- 分析过程:记录分析步骤和使用的方法。
- 调查发现:详细呈现分析结果,包括支持性数据。
- 结论:基于证据的客观结论和专业意见。
- 附录:技术细节、工具输出、屏幕截图等辅助材料。
报告应保持客观性,避免主观判断,确保所有结论都有证据支持。根据不同受众可能需要准备多个版本的报告,如详细技术报告和高层次摘要报告。
三、数字取证环境搭建
3.1 取证实验室设置
搭建专业的数字取证实验室需要考虑多方面因素,包括物理安全、数据隔离、工具配置和流程标准化,以确保取证活动的合法性和有效性。
数字取证实验室的关键组成部分包括:
- 认证与资质:符合相关国际标准(如ISO/IEC 17025)
- 组织框架:明确的责任分工和汇报机制
- 安全策略:防止未经授权的访问和数据泄露
- 记录控制:完整的文档和证据管理系统
- 流程和程序:标准化的工作流程和实验室规程
- 方法论:经过验证的取证技术和方法
- 人员:具备专业资质的取证分析师
- 行为准则:确保工作的客观性和公正性
- 工具:经过验证的取证软硬件
实验室设置需要考虑:
- 物理安全:访问控制、监控系统、防火设施
- 电源保障:不间断电源(UPS)和备用发电系统
- 网络隔离:隔离的内部网络,防止证据污染和外部攻击
- 存储系统:安全、冗余的证据存储解决方案
- 工作区域:硬件分析区、证据存储区、文档区等
3.2 虚拟机环境配置
虚拟机环境在数字取证中至关重要,它提供了一个隔离的、可控的工作环境,避免对原始证据的污染,并允许重复实验而不影响原始状态。虚拟机环境的优势包括:隔离性、可重复性、快照功能、资源优化和便携性。
设置虚拟机环境的基本步骤:
- 选择适合的虚拟化平台(如VirtualBox、VMware)
- 创建虚拟机,分配适当的资源(CPU、内存、存储)
- 安装操作系统(建议同时准备Windows和Linux环境)
- 配置网络设置(通常使用NAT或隔离网络)
- 创建快照,以便在需要时恢复到干净状态
虚拟机克隆和快照是重要的功能:克隆可以创建完全相同的虚拟机副本;快照可以保存虚拟机在特定时间点的状态,允许在实验或分析后恢复到初始状态。
推荐的虚拟机配置:
- Windows虚拟机:用于运行Windows特定的取证工具和分析Windows制品
- Linux虚拟机:优选基于Ubuntu或Kali Linux的发行版,预装许多开源取证工具
- 专用取证发行版:如SANS SIFT、Paladin或CAINE,预配置了大量取证工具
3.3 取证工具安装与配置
数字取证需要多种专业工具,从基础的十六进制编辑器到复杂的综合取证平台。每个工具都有特定的用途和优势,组合使用可以提供全面的分析能力。
必备的基本取证工具包括:
-
十六进制编辑器:用于底层数据检查,比如WinHex或HxD,允许直接查看和编辑文件的二进制内容。
-
The Sleuth Kit(TSK)与Autopsy:开源数字取证工具集,TSK提供命令行工具,Autopsy是其图形界面。支持多种文件系统分析、关键词搜索、时间线创建等功能。
-
Volatility:内存取证框架,用于分析内存转储,支持提取进程、网络连接、加载模块等信息。
-
PowerForensics:Windows PowerShell模块,提供低级文件系统访问和取证功能。
-
SQLite工具:分析SQLite数据库,在移动设备和浏览器取证中特别有用。
-
Plaso和Log2timeline.py:用于创建超级时间线的工具,整合多个来源的时间戳数据。
其他常用工具包括:
- FTK Imager:创建磁盘镜像和内存转储
- Wireshark:网络数据包分析
- RegRipper:Windows注册表分析
- ExifTool:元数据提取和分析
- Bulk Extractor:批量提取电子邮件、URL、信用卡号等信息
安装工具时应注意版本兼容性,定期更新,并在使用前验证工具的功能和准确性。
四、数据采集技术
4.1 易失性数据采集
易失性数据采集是数字取证中的首要任务,因为这些数据存储在RAM等临时介质中,断电后将永久丢失。及时、准确地获取这些数据对事件调查至关重要。
易失性数据与非易失性数据的主要区别在于持久性:易失性数据在断电后会丢失,而非易失性数据则会保持。取证过程遵循易失性顺序原则,先获取最易消失的数据,再处理持久性数据。
易失性数据采集主要关注内存(RAM)中的数据,常用工具包括:
- DumpIt:Windows内存获取工具,简单一键操作
- PMEM和WinPmem:开源内存采集工具,支持多种获取模式
- FTK Imager:商业工具,支持内存转储和磁盘镜像创建
- Linux Memory Extractor(LiME):Linux系统内存采集内核模块,也支持Android设备
易失性数据采集的最佳实践:
- 使用经过验证的工具,避免未知工具可能造成的系统变更
- 记录系统时间和执行的每一步操作
- 将采集的数据保存到外部存储设备,避免写入被调查系统
- 创建内存转储的多个哈希值,确保数据完整性
- 尽量减少与系统的交互,避免不必要的数据变更
- 考虑对关键易失性数据如网络连接、开放端口、运行进程等进行实时文档记录
4.2 非易失性数据采集
非易失性数据采集主要关注存储在持久介质(如硬盘、闪存、SSD等)上的数据。取证镜像类型主要包括:物理镜像(完整复制存储介质所有扇区)和逻辑镜像(仅复制文件系统内的文件和文件夹)。
常用的非易失性数据采集工具包括:
- FTK Imager:创建物理和逻辑硬盘镜像的商业工具
- Data Duplicator(dd):Linux命令行工具,创建原始镜像
- Guymager:Linux图形界面镜像工具,支持多种镜像格式
创建取证镜像的步骤:
- 准备目标存储设备,确保容量足够
- 使用写保护器连接源设备,防止意外写入
- 记录设备信息(序列号、型号、容量等)
- 选择适当的镜像格式(如E01、dd、AFF)
- 设置适当的压缩和分段选项
- 创建镜像并计算哈希值
- 验证镜像完整性,确保源设备和镜像哈希值匹配
- 记录所有操作步骤和使用的工具版本
4.3 内存获取技术
内存获取可以从物理系统和虚拟环境中进行。对于虚拟环境,不同的虚拟化平台提供了不同的内存获取方法:
- VirtualBox:可以使用VBoxManage命令导出内存
- VMware:支持通过VMware工具或PowerShell脚本获取内存
- Hyper-V:可以创建检查点或使用专用工具采集内存
内存获取面临的挑战:
- 获取过程会改变部分内存内容(观察者效应)
- 大容量内存需要足够的存储空间和处理时间
- 加密内存区域可能难以解析
- 内存结构随操作系统版本变化,需要相应的配置文件
- 某些反取证技术可能干扰内存采集过程
除主内存外,其他重要的内存相关位置包括:
- 页面文件(pagefile.sys):Windows系统中的虚拟内存文件
- 休眠文件(hiberfil.sys):系统休眠时保存的内存状态
- 交换文件(swap.sys):Windows 10中的额外交换空间
- 卷影副本:Windows系统还原点,可能包含历史内存数据
4.4 磁盘映像创建
磁盘映像创建是保存存储设备完整内容的过程,可分为物理映像(逐位复制)和逻辑映像(仅复制文件系统可见内容)。物理映像可以恢复已删除文件和分析未分配空间,而逻辑映像处理更快但信息有限。
磁盘映像创建的最佳实践:
- 使用写保护器防止原始介质被修改
- 选择适当的映像格式(考虑压缩、分段需求)
- 记录详细的设备信息和采集环境
- 创建前后计算原始设备的哈希值,并与映像哈希值比对
- 为大型存储设备预留足够的时间
- 考虑加密保护敏感数据
- 保留至少两个映像副本,一个作为工作副本,一个作为备份
双工具验证(Dual-Tool Verification)是数字取证中的一种质量保证方法,通过使用两种不同的工具分析同一数据集,比较结果是否一致来验证发现的可靠性。该方法的基本假设是:如果两个不同的工具对数据的解释相似,则结果更可能是有效的。
虽然双工具验证在许多取证指南和标准中被推荐,但它也有一些局限性。工具的有效性取决于它们是否基于不同的库、引擎和方法构建。如果多个工具共享相同的底层代码,可能会出现相同的错误。例如,许多元数据提取工具由于共享相同的代码而在MPEG-4文件时间戳转换中存在相同的错误。
研究显示,双工具验证是数字取证从业者最常用的证据可靠性控制措施。然而,取证人员应该意识到,仅仅依靠工具验证是不够的。最终是专家而非工具在作证,取证专家需要确保证词真实且不具误导性。
五、文件系统取证
5.1 文件系统基础
文件系统是操作系统组织和管理存储介质上文件的方法,是数字取证的基础领域。了解不同文件系统的结构和特性对于有效恢复和分析数据至关重要。
文件识别是文件系统取证的基础,通常通过文件头(Magic Numbers)进行。文件头是文件开头的特定字节序列,用于标识文件类型。即使文件扩展名被更改,通过检查文件头仍然可以确定真实的文件类型。这对于发现伪装文件(如将恶意可执行文件伪装成图片)非常重要。
磁盘结构分为物理结构和逻辑结构:
- 物理结构包括物理扇区、磁头、磁道等硬件层面的组织
- 逻辑结构包括主引导记录(MBR)、分区表、卷、文件系统等软件层面的组织
主引导记录(MBR)位于硬盘的第一个扇区(扇区0),包含两个关键部分:
- 引导代码:用于引导操作系统的程序代码
- 主分区表(Master Partition Table):存储硬盘分区信息
了解这些基本结构对于从损坏的存储介质恢复数据、分析未分配空间和检测隐藏分区至关重要。
5.2 Windows文件系统取证
NTFS(New Technology File System)是Windows系统的主要文件系统。NTFS的核心组件是主文件表(Master File Table, MFT),它记录了分区上所有文件的元数据和位置信息。每个文件和文件夹在MFT中都有一个记录,称为MFT条目,通常大小为1KB。
MFT条目包含多种属性,其中最重要的包括:
- 标准信息($STANDARD_INFORMATION):包含创建、修改、访问和更改时间戳
- 文件名($FILE_NAME):存储文件名和另一组时间戳
- 数据($DATA):存储文件的实际内容或指向内容的指针
- 索引( I N D E X R O O T 、 INDEX_ROOT、 INDEXROOT、INDEX_ALLOCATION):用于目录结构
NTFS的特殊结构和功能包括:
- 交替数据流(ADS):允许在单个文件中存储多个数据流
- 日志机制($LogFile):记录文件系统操作,用于恢复
- 卷影副本服务(VSS):创建数据快照,可用于恢复之前版本的文件
- 索引(INDX):目录的B树结构,包含文件引用和属性
Windows回收站是取证调查中的重要来源,删除的文件会移至回收站,并重命名,原始路径和删除时间存储在特殊文件中。分析回收站可以恢复已删除文件并确定删除时间和原始位置。
5.3 Linux文件系统取证
Linux系统常用的文件系统包括Ext2/3/4(第二、第三和第四扩展文件系统)。这些文件系统的基本结构包括:
- 超级块(Superblock):包含文件系统的基本信息
- 索引节点(Inode):存储文件元数据和数据块指针
- 数据块(Data Blocks):存储文件的实际内容
- 目录条目(Directory Entries):将文件名映射到inode号
Ext文件系统的重要取证特性:
- 日志功能(Ext3/4):可以用于恢复文件系统操作历史
- 删除文件恢复:仅删除指向数据的链接,数据可能仍可恢复
- 时间戳操作:修改时间(mtime)、访问时间(atime)、创建时间(ctime)
- 文件权限和所有权:可能提供关于谁访问和修改文件的线索
Linux系统日志通常存储在/var/log目录下,记录系统活动、用户登录、应用程序事件等。主要的日志文件包括:
- /var/log/auth.log或/var/log/secure:身份验证和授权信息
- /var/log/syslog或/var/log/messages:一般系统消息
- /var/log/kern.log:内核消息
- ~/.bash_history:用户命令历史记录
5.4 文件恢复与数据雕刻
文件恢复是从存储介质中恢复已删除、损坏或丢失文件的过程。文件删除后,操作系统通常只移除文件系统的引用,实际数据仍保留在磁盘上,直到被新数据覆盖。
文件恢复的基本方法:
- 文件系统分析:通过检查文件系统结构(如MFT或inode)恢复已删除文件的引用
- 数据雕刻(File Carving):基于文件特征(如文件头和文件尾)从原始数据恢复文件
- 日志分析:从文件系统日志恢复最近的操作和修改
数据雕刻是一种不依赖文件系统结构的恢复技术,通过识别文件的特征模式(如文件头和文件尾)直接从存储介质提取文件。这种技术特别适用于格式化的驱动器或严重损坏的文件系统。
常用的文件恢复和数据雕刻工具包括:
- Recuva:用户友好的Windows文件恢复工具
- Autopsy:开源数字取证平台,包含文件恢复功能
- Foremost:基于文件头、文件尾和数据结构的数据雕刻工具
- Scalpel:高性能文件雕刻工具,基于Foremost改进
文件雕刻与文件恢复的主要区别:文件恢复依赖文件系统的元数据,而文件雕刻直接分析原始数据,不依赖文件系统结构。当文件系统受损或完全被破坏时,文件雕刻可能是唯一可行的恢复方法。
六、Windows系统取证
6.1 注册表分析
Windows注册表是系统和应用程序配置信息的中央存储库,包含了大量取证价值的数据,如用户活动、系统配置、安装的软件和持久性机制等。
Windows注册表由五个主要的注册表配置单元(Hives)组成,存储在系统盘的不同位置:
- HKEY_LOCAL_MACHINE\SYSTEM (C:\Windows\System32\config\SYSTEM)
- HKEY_LOCAL_MACHINE\SOFTWARE (C:\Windows\System32\config\SOFTWARE)
- HKEY_LOCAL_MACHINE\SAM (C:\Windows\System32\config\SAM)
- HKEY_LOCAL_MACHINE\SECURITY (C:\Windows\System32\config\SECURITY)
- HKEY_CURRENT_USER (C:\Users[username]\NTUSER.DAT)
从取证角度看,注册表包含许多有价值的信息:
- 最近访问的文件:HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs
- 系统信息:HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion
- 持久性机制:如Run、RunOnce、Services等键,常被恶意软件用于在系统重启后自动启动
- USB设备历史:HKLM\SYSTEM\CurrentControlSet\Enum\USBSTOR
- 用户活动记录:如UserAssist键记录程序执行频率和时间
- 网络连接:存储网络配置和历史连接
分析注册表的工具包括Registry Explorer和RegRipper等,它们可以提取和分析注册表内容,帮助调查人员找到关键证据。
6.2 系统日志分析
Windows事件日志是系统活动的重要记录,存储在.evtx文件中,位于C:\Windows\System32\winevt\Logs目录。主要的事件日志包括:
- 系统日志(System.evtx):记录系统组件事件
- 安全日志(Security.evtx):记录安全审计事件
- 应用程序日志(Application.evtx):记录应用程序事件
- 设置日志(Setup.evtx):记录系统设置和更新事件
从取证角度特别有价值的事件ID包括:
- 事件ID 4624:成功登录
- 事件ID 4625:登录失败
- 事件ID 4634/4647:注销
- 事件ID 4688:新进程创建
- 事件ID 7045:新服务安装
- 事件ID 1102:审计日志清除
命令行历史记录是另一个重要的取证来源,Windows PowerShell历史保存在特定文件中:
- Windows PowerShell:%APPDATA%\Microsoft\Windows\PowerShell\PSReadLine\ConsoleHost_history.txt
- Windows命令提示符:可能需要通过命令历史缓冲区或页面文件恢复
6.3 Windows制品分析
Windows系统包含许多取证制品(Artifacts),它们记录了用户活动和系统操作的历史:
-
Shimcache:记录程序执行信息,存储在注册表中
- 位置:HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\AppCompatCache
- 作用:识别程序执行情况,即使程序已被删除
-
Amcache:记录程序执行和文件信息
- 位置:C:\Windows\AppCompat\Programs\Amcache.hve
- 作用:包含程序路径、大小、编译时间和SHA1哈希
-
UserAssist:记录通过Windows资源管理器启动的程序
- 位置:HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist
- 作用:包含程序运行次数和最后执行时间
-
Prefetch:Windows预读文件,加速程序启动
- 位置:C:\Windows\Prefetch
- 作用:记录程序执行次数、上次运行时间和加载的DLL
-
Jumplist:任务栏最近打开文件列表
- 位置:C:\Users[username]\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations
- 作用:提供程序打开的文件记录和时间戳
-
LNK文件:快捷方式文件
- 位置:C:\Users[username]\AppData\Roaming\Microsoft\Windows\Recent
- 作用:包含目标文件路径、大小、时间戳和卷信息
-
ShellBag:记录资源管理器文件夹视图设置
- 位置:注册表的多个位置
- 作用:提供用户访问过的文件夹信息
USB设备活动也留下重要线索,可以从以下位置查找:
- 注册表中的USBSTOR条目
- 安装的设备驱动程序
- 挂载设备记录
- 事件日志中的PnP事件
6.4 时间线分析
时间线分析是将多个来源的时间数据整合成单一事件序列的过程,有助于理解事件的顺序和关系。时间线分析对于理解事件的上下文和识别可疑活动模式至关重要。
Windows系统中的主要时间对象是MAC(b)时间戳:
- M (Modified):文件内容最后修改时间
- A (Accessed):文件最后访问时间
- C (Created):文件创建时间
- b (MFT Entry Modified):文件元数据最后更改时间
时间线分析的主要工具包括:
- Autopsy:图形界面取证工具,包含时间线功能
- Log2timeline/Plaso:创建"超级时间线"的命令行工具
- Timesketch:协作时间线分析和可视化平台
创建全面时间线的关键步骤:
- 收集不同来源的时间数据(文件系统、注册表、日志等)
- 标准化时间格式和时区
- 整合数据创建统一时间线
- 分析时间线,识别模式和异常
- 关注关键事件前后的活动
时间线分析可以揭示隐藏在数据中的故事,例如恶意软件感染顺序、入侵者活动路径或数据泄漏的确切时间。将时间线与其他证据相关联,可以构建更完整的事件图景。
七、内存取证
7.1 内存取证基础
内存取证是分析计算机运行内存(RAM)内容的过程,能够提供磁盘取证无法获取的关键信息,如加密密钥、网络连接和运行进程等。
内存取证的价值在于能够捕获系统的"活动状态",包括以下关键信息:
- 运行中的进程和线程
- 加载的驱动程序和模块
- 打开的文件和网络连接
- 系统配置和用户会话
- 加密密钥和凭据(可能在内存中未加密状态)
- 恶意代码和隐藏进程
内存取证与磁盘取证互为补充:内存取证提供系统活动状态的快照,而磁盘取证提供持久存储的历史记录。结合两者可以创建更完整的证据图景。
内存分析面临的挑战包括:内存的易失性、取证工具对内存的影响、操作系统结构差异,以及反取证技术可能的干扰。
7.2 内存采集技术
内存采集是获取系统RAM内容的过程,需要在系统运行状态下进行。内存采集技术分为软件方法和硬件方法:
软件方法:
- 专用内存获取工具:如DumpIt、WinPmem、FTK Imager和LiME
- 虚拟机内存获取:从VirtualBox、VMware或Hyper-V等虚拟平台获取内存
- 混合方法:结合软件和硬件方法获取内存
硬件方法:
- DMA(直接内存访问):通过FireWire或Thunderbolt端口直接访问内存
- 冷启动攻击:将物理内存快速冷却后移除并读取
- 专用硬件设备:设计用于法医内存采集的特殊设备
每种方法都有优缺点,选择取决于具体场景和可用资源。软件方法更常用,但可能对内存内容有轻微影响;硬件方法干扰较小,但实施更复杂。
除主内存外,其他包含内存数据的位置:
- 页面文件(pagefile.sys):虚拟内存扩展
- 休眠文件(hiberfil.sys):系统休眠时的内存快照
- 交换文件(swapfile.sys):Windows 10中的额外交换空间
- 崩溃转储:系统崩溃时创建的内存内容
7.3 内存分析工具与方法
内存分析需要专门的工具来解释复杂的内存结构。最流行的内存分析框架是Volatility,它支持多种操作系统和内存结构。
Volatility的主要功能包括:
- 进程分析:列出进程、DLL、线程和进程树
- 网络分析:显示网络连接、套接字和路由表
- 注册表分析:从内存转储中提取注册表信息
- 恶意代码检测:查找隐藏进程和rootkit
Volatility命令根据功能分类:
- 进程信息:pslist, pstree, psxview
- 网络信息:netscan, connscan
- 代码注入检测:malfind
- 内存内容提取:memdump, procdump, dlldump
- 注册表分析:hivelist, printkey
内存分析的最佳实践:
- 采集内存后立即验证完整性(计算哈希值)
- 使用系统特定的Volatility配置文件
- 先获取进程列表和网络连接等基本信息
- 针对可疑进程深入分析
- 提取可疑文件和进程进行进一步分析
- 将内存分析结果与磁盘取证数据关联
7.4 恶意代码检测
内存取证是检测和分析恶意代码的强大方法,特别是针对仅驻留在内存中的恶意软件。恶意代码分析涉及:
- 识别可疑进程和模块
- 检测进程注入和代码隐藏技术
- 分析网络连接和通信模式
- 提取恶意代码样本进行深入分析
Volatility提供多种恶意代码检测功能:
- malfind:检测可执行内存页和进程注入
- ldrmodules:查找未链接的DLL(可能被隐藏)
- apihooks:检测API钩子(常见的恶意代码技术)
- dlllist:分析加载的DLL是否异常
- yarascan:使用Yara规则在内存中查找已知恶意代码特征
结合内存分析和Yara规则能有效检测已知的恶意代码。Yara是一种模式匹配引擎,允许创建基于特征的规则来识别恶意软件。在内存分析中使用Yara规则可以快速识别已知恶意代码的变体。
恶意代码检测的最佳实践:
- 维护最新的恶意代码指标和Yara规则
- 关注异常的进程关系和网络连接
- 分析可疑进程的内存区域权限和内容
- 提取可疑代码进行离线分析
- 将检测结果与威胁情报数据关联
八、网络取证
8.1 网络取证基础
网络取证涉及收集、分析和保存网络通信数据,以重建网络活动、识别入侵和数据泄露,并提供法律上可接受的证据。
网络取证的基本概念包括网络分层抽象模型(OSI七层模型),从物理层到应用层。每一层都可能包含取证证据:
- 物理层:物理连接和传输介质
- 数据链路层:MAC地址和帧
- 网络层:IP地址和路由信息
- 传输层:TCP/UDP端口和会话
- 会话、表示和应用层:应用程序数据和协议
互联网基础设施组件对网络取证至关重要:
- 互联网骨干网和自治系统(AS)
- 边界网关协议(BGP)路由
- 互联网服务提供商(ISP)
- 域名系统(DNS)
- 网络地址转换(NAT)
常见的网络应用和协议包括:
- 电子邮件(SMTP, POP3, IMAP)
- 万维网(HTTP, HTTPS)
- 点对点网络(BitTorrent)
- 即时通讯和VoIP
- 洋葱路由和匿名网络
网络取证面临的挑战包括NAT设备、匿名技术(如Tor)、加密通信和Web Shell等后门技术。
8.2 网络流量捕获与分析
网络流量捕获是记录通过网络的数据包的过程。数据包捕获(PCAP)文件是网络取证的基本证据类型,可以使用多种工具创建:
- Wireshark:图形界面网络分析工具
- Tshark:Wireshark的命令行版本
- Dumpcap:专注于捕获功能的轻量级工具
- Tcpdump:Unix/Linux系统的命令行工具
捕获网络流量的最佳实践:
- 在适当位置部署捕获设备(如网络出口点)
- 配置适当的过滤器减少不相关数据
- 确保足够的存储空间和处理能力
- 记录捕获的时间、位置和环境
- 使用写保护保存捕获的数据
- 计算哈希值确保数据完整性
网络流量分析可以通过多种方法进行:
- 数据包级分析:检查各个数据包的内容和特性
- 会话重建:重组TCP/UDP会话看完整通信
- 协议分析:分析特定协议的行为和内容
- 流量模式识别:识别异常或可疑的通信模式
常用的网络分析工具包括:
- Wireshark:全功能数据包分析
- NetworkMiner:网络取证分析工具,专注于从PCAP中提取文件和信息
- CloudShark:基于Web的协作PCAP分析平台
- Zeek(前身是Bro):网络安全监控和分析框架
8.3 网络日志分析
网络设备和服务产生的日志是网络取证的重要组成部分:
-
DHCP日志:记录IP地址分配,将MAC地址与IP地址关联
- 包含分配时间、MAC地址、IP地址和主机名
- 有助于识别特定时间内活动的设备
-
Web服务器日志:记录对Web服务器的请求
- 包含客户端IP、请求时间、请求内容、响应代码等
- 可用于跟踪攻击者活动和数据泄露
-
Web应用日志:记录应用层活动
- 包含用户身份、操作类型和应用程序事件
- 有助于识别应用程序漏洞利用和未授权访问
-
代理日志:记录通过代理服务器的请求
- 包含内部用户的Web活动和外部连接
- 可用于检测数据泄露和策略违规
-
NetFlow/IPFIX记录:网络流量摘要
- 包含通信的源、目的、大小和时间,但不包含内容
- 适用于分析大规模网络行为和模式
日志分析的关键步骤:
- 收集和集中来自不同来源的日志
- 标准化时间戳和格式
- 过滤不相关数据
- 识别异常或可疑活动
- 关联不同日志源的事件
- 创建时间线和可视化表示
8.4 Web浏览器取证
Web浏览器是用户活动的重要来源,包含大量潜在证据。主要的浏览器制品包括:
-
历史记录:访问的网站和时间
- Chrome: C:\Users[username]\AppData\Local\Google\Chrome\User Data\Default\History
- Firefox: C:\Users[username]\AppData\Roaming\Mozilla\Firefox\Profiles[profile]\places.sqlite
- Edge: C:\Users[username]\AppData\Local\Microsoft\Edge\User Data\Default\History
-
缓存:临时存储的Web内容
- 可以恢复已删除的Web内容和已经改变的网站
- 包含网站资源如图片、脚本和HTML
-
Cookies:网站存储的小型数据文件
- 包含会话标识符、用户首选项和跟踪数据
- 可以揭示用户登录状态和访问模式
-
下载历史:下载的文件记录
- 包含文件名、URL和下载时间
- 可能包含已删除文件的线索
-
表单数据和密码:用户输入的信息
- 可能存储用户名、密码和自动填充数据
- 通常加密存储,但可能可以恢复
-
书签和收藏夹:用户保存的网站
- 指示用户兴趣和经常访问的站点
- 可能包含工作或个人相关网站
浏览器取证工具包括:
- Browser History Examiner:专用浏览器取证工具
- Autopsy:包含浏览器分析功能
- Browser History Viewer:免费的浏览器历史查看器
- SQLite浏览器:分析浏览器数据库文件
九、移动设备取证
9.1 移动设备取证基础
移动设备取证关注从智能手机、平板电脑和其他便携设备获取和分析数据,这些设备已成为个人和商业活动的中心,包含大量潜在证据。
移动设备取证与传统计算机取证有显著区别:
- 多样的硬件和操作系统
- 专有连接和接口
- 加密和安全措施
- 云数据集成
- 不断更新的操作系统和应用
移动设备可以提供多种类型的证据:
- 通话记录和联系人
- 短信和即时通讯
- 电子邮件和社交媒体活动
- 照片、视频和音频文件
- 位置数据和GPS历史
- 应用数据和用户活动
- 设备使用模式和时间线
移动设备取证面临的挑战包括:
- 数据加密和安全措施
- 快速变化的设备和操作系统
- 云存储和同步
- 法律和隐私考虑
- 物理访问限制(如锁屏和生物识别)
9.2 移动设备数据获取
移动设备数据获取方法根据获取深度和侵入性分为多种类型:
-
物理获取:直接访问设备存储芯片,提供最完整的数据访问
- 芯片脱机(Chip-Off):物理移除存储芯片并直接读取
- JTAG/ISP:通过测试接口直接访问设备内存
- 创建设备的完整二进制副本,包括已删除数据
-
文件系统获取:访问设备文件系统
- 通过设备接口获取文件和文件夹
- 不如物理获取全面,但侵入性较小
- 通常需要设备根访问权限
-
逻辑获取:通过设备API获取数据
- 使用制造商提供的协议和接口
- 限于当前可见的数据
- 包括备份、媒体传输协议和供应商专用协议
-
云获取:从与设备关联的云服务获取数据
- 从iCloud、Google Drive或其他在线备份获取
- 不需要物理访问设备
- 可能需要凭据或法律授权
数据获取工具和技术:
- 商业工具:Cellebrite UFED、Oxygen Forensic Detective、Magnet AXIOM
- 开源工具:Autopsy、libimobiledevice(iOS)、adb(Android)
- 专用硬件:取证设备适配器、JTAG适配器、芯片读取器
处理损坏设备的策略:
- 外部力量损坏:设备部件更换或维修
- 水或液体损坏:专业清洁和干燥
- 电子故障:芯片级数据恢复
9.3 移动应用程序取证
移动应用程序产生大量用户活动和内容数据。应用数据通常存储在:
- 应用数据库(主要是SQLite)
- 配置和偏好文件
- 缓存文件和临时存储
- 加密的数据仓库
常见应用类型的取证分析:
-
消息应用:WhatsApp、Telegram、Signal等
- 通常使用SQLite数据库存储消息
- 可能包含联系人、聊天记录、共享媒体
- 加密级别各不相同
-
社交媒体:Facebook、Instagram、Twitter等
- 存储帖子、评论、联系人、活动时间线
- 可能包含位置数据和设备信息
- 数据可能部分存储在本地,部分在云端
-
电子邮件:Gmail、Outlook等
- 邮件内容、附件、联系人
- 存储模式取决于应用和同步设置
- 可能包含用户账户信息
-
位置应用:地图、导航、运动跟踪
- 搜索历史、路线、兴趣点
- 详细的位置历史和时间戳
- 通常包含用户活动的模式
-
金融应用:银行、支付、交易应用
- 交易记录、账户信息
- 可能高度加密
- 在法律调查中特别重要
应用分析技术包括:
- 数据库分析(主要是SQLite)
- 配置文件检查
- 反向工程应用结构
- 解密受保护数据
- 相关应用间数据关联
9.4 云服务取证
移动设备与云服务深度集成,使得云取证成为移动设备调查的关键组成部分:
-
备份分析:iCloud、Google等云备份
- 可能包含比设备本身更多的历史数据
- 通常需要账户凭据或法律程序
- 可能分布在不同司法管辖区的服务器上
-
同步数据:自动同步的内容
- 联系人、日历、笔记、照片等
- 提供设备删除数据的另一个来源
- 同步历史可能指示设备活动模式
-
服务器端数据:仅存储在云端的数据
- 电子邮件、文档、工作流数据
- 可能需要服务提供商协助获取
- 跨境数据访问可能涉及复杂的法律问题
-
访问方法:
- 法律程序(搜查令、法院命令)
- 账户接管(通过凭据或重置)
- 应用程序接口(API)访问
- 网络取证方法(如网络流量分析)
云取证的挑战和考虑:
- 数据分散在多个服务提供商
- 动态数据可能快速变化
- 多层加密和访问控制
- 国际司法管辖权问题
- 证据完整性和验证复杂性
十、Python在数字取证中的应用
10.1 Python取证环境搭建
Python已成为数字取证的主要编程语言,其简洁的语法、丰富的库和跨平台特性使其成为开发取证工具和自动化分析流程的理想选择。
Python在取证中的优势包括:
- 简洁易读的语法,降低学习门槛
- 丰富的标准库和第三方包
- 强大的文本处理和数据分析能力
- 跨平台兼容性,可在Windows、Linux和macOS上运行
- 活跃的社区和广泛的资源
设置Python取证环境的步骤:
- 安装Python(推荐Python 3.x)
- 选择合适的编辑器或IDE(如IDLE、VS Code、PyCharm)
- 安装关键取证库:
- Standard Library(内置库):处理文件、时间、哈希等
- Third-party libraries:专用取证功能
关键的Python取证库包括:
- hashlib:计算文件哈希值
- os和sys:文件系统操作和系统功能
- struct:解析二进制数据结构
- sqlite3:分析SQLite数据库
- datetime:处理时间戳
- re:正则表达式匹配和搜索
- pandas:数据分析和操作
- matplotlib/seaborn:数据可视化
- pytz:时区处理
- pytsk3:访问磁盘镜像和文件系统
专业取证库:
- volatility:内存取证
- dfvfs:取证卷文件系统
- dfwinreg:Windows注册表分析
- plaso:超级时间线创建
- sleuthkit:文件系统分析
- scapy:网络分析
- NLTK:自然语言处理
10.2 使用Python处理取证数据
Python可以高效处理各种取证数据类型:
- 文件哈希计算:验证文件完整性
import hashlib
def calculate_hash(file_path, algorithm='sha256'):
"""计算文件的哈希值"""
hash_obj = hashlib.new(algorithm)
with open(file_path, 'rb') as file:
for chunk in iter(lambda: file.read(4096), b''):
hash_obj.update(chunk)
return hash_obj.hexdigest()
- 文件系统遍历:递归处理目录结构
import os
def walk_files(root_dir):
"""遍历目录中的所有文件"""
file_list = []
for root, dirs, files in os.walk(root_dir):
for file in files:
file_path = os.path.join(root, file)
file_list.append(file_path)
return file_list
- SQLite数据库分析:处理浏览器历史、应用数据等
import sqlite3
def query_sqlite(db_path, sql_query):
"""执行SQLite查询并返回结果"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute(sql_query)
results = cursor.fetchall()
conn.close()
return results
- 时间戳转换:处理各种格式的时间数据
import datetime
def windows_filetime_to_datetime(filetime):
"""将Windows文件时间转换为Python datetime对象"""
# Windows文件时间是从1601年1月1日开始的100纳秒计数
return datetime.datetime(1601, 1, 1) + datetime.timedelta(microseconds=filetime // 10)
- 日志分析:使用正则表达式和pandas处理日志
import re
import pandas as pd
def parse_log(log_path, pattern):
"""使用正则表达式解析日志文件"""
matches = []
with open(log_path, 'r') as log_file:
for line in log_file:
match = re.search(pattern, line)
if match:
matches.append(match.groupdict())
return pd.DataFrame(matches)
这些基本技术可以组合用于更复杂的取证任务,如提取特定文件类型、创建时间线或分析网络流量。
10.3 开发自定义取证工具
Python的灵活性使其非常适合开发自定义取证工具。一些基本设计原则包括:
- 模块化设计:将功能划分为可重用组件
- 错误处理:确保工具在各种情况下都稳定运行
- 日志记录:记录所有操作以确保证据链
- 可测试性:验证工具输出的准确性
- 配置选项:允许自定义行为而不修改代码
自定义工具开发的基本框架包括:命令行参数处理、日志记录模块、核心功能实现和结果呈现。以下是一个简单的文件哈希工具示例:
import argparse
import hashlib
import os
import logging
import csv
from datetime import datetime
class CSVWriter:
"""CSV文件写入类"""
def __init__(self, csv_path):
self.csv_path = csv_path
self.csv_file = None
self.csv_writer = None
def open(self, fieldnames):
self.csv_file = open(self.csv_path, 'w', newline='')
self.csv_writer = csv.DictWriter(self.csv_file, fieldnames=fieldnames)
self.csv_writer.writeheader()
def write_row(self, row_dict):
self.csv_writer.writerow(row_dict)
def close(self):
if self.csv_file:
self.csv_file.close()
def setup_logging(log_path):
"""设置日志记录"""
logging.basicConfig(
filename=log_path,
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
return logging.getLogger()
def hash_file(file_path, algorithms=None):
"""计算文件的多种哈希值"""
if algorithms is None:
algorithms = ['md5', 'sha1', 'sha256']
hashes = {}
for algorithm in algorithms:
hash_obj = hashlib.new(algorithm)
try:
with open(file_path, 'rb') as file:
for chunk in iter(lambda: file.read(4096), b''):
hash_obj.update(chunk)
hashes[algorithm] = hash_obj.hexdigest()
except Exception as e:
hashes[algorithm] = f"Error: {str(e)}"
return hashes
def walk_path(root_path, logger, csv_writer, hash_algorithms):
"""递归遍历目录并计算哈希值"""
logger.info(f"开始遍历目录: {root_path}")
for root, dirs, files in os.walk(root_path):
for file in files:
file_path = os.path.join(root, file)
logger.info(f"处理文件: {file_path}")
try:
file_size = os.path.getsize(file_path)
file_mtime = datetime.fromtimestamp(os.path.getmtime(file_path))
hashes = hash_file(file_path, hash_algorithms)
row = {
'Path': file_path,
'Size': file_size,
'Modified': file_mtime.isoformat()
}
row.update(hashes)
csv_writer.write_row(row)
logger.info(f"已记录哈希值: {file_path}")
except Exception as e:
logger.error(f"处理文件时出错: {file_path} - {str(e)}")
def parse_commandline():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='文件哈希计算工具')
parser.add_argument('-d', '--directory', required=True, help='要处理的目录')
parser.add_argument('-o', '--output', required=True, help='CSV输出文件路径')
parser.add_argument('-l', '--log', required=True, help='日志文件路径')
parser.add_argument('-a', '--algorithms', nargs='+', default=['md5', 'sha1', 'sha256'],
help='要使用的哈希算法(默认: md5 sha1 sha256)')
return parser.parse_args()
def main():
"""主函数"""
args = parse_commandline()
logger = setup_logging(args.log)
logger.info("=== 文件哈希计算工具启动 ===")
logger.info(f"目标目录: {args.directory}")
logger.info(f"输出文件: {args.output}")
logger.info(f"哈希算法: {args.algorithms}")
# 准备CSV字段
fieldnames = ['Path', 'Size', 'Modified'] + args.algorithms
csv_writer = CSVWriter(args.output)
csv_writer.open(fieldnames)
try:
walk_path(args.directory, logger, csv_writer, args.algorithms)
logger.info("处理完成")
except Exception as e:
logger.critical(f"发生严重错误: {str(e)}")
finally:
csv_writer.close()
logger.info("=== 文件哈希计算工具结束 ===")
if __name__ == "__main__":
main()
这个工具实现了递归遍历目录、计算文件哈希值、记录详细日志和将结果保存到CSV文件的功能。它可以作为更复杂取证工具的起点。
10.4 案例分析
以下是Python在不同取证场景中的应用案例:
案例1:Windows注册表分析 使用Python解析Windows注册表文件,提取最近文档列表:
import winreg
import binascii
def get_recent_docs():
"""获取最近打开的文档列表"""
recent_docs = []
try:
key_path = r"Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs"
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, key_path)
count = winreg.QueryInfoKey(key)[1]
for i in range(count):
name, data, _ = winreg.EnumValue(key, i)
if name != "MRUListEx":
try:
# 解析二进制数据提取文件名
file_name = data.decode('utf-16le').split('\x00')[0]
recent_docs.append(file_name)
except:
pass
winreg.CloseKey(key)
except Exception as e:
print(f"Error: {e}")
return recent_docs
案例2:浏览器历史分析 使用Python分析Chrome浏览器历史数据库:
import sqlite3
import os
import datetime
def get_chrome_history(user_profile):
"""分析Chrome浏览器历史记录"""
history_path = os.path.join(user_profile,
"AppData/Local/Google/Chrome/User Data/Default/History")
if not os.path.exists(history_path):
return []
# 创建历史文件的副本以避免锁定
temp_path = "temp_history_copy"
with open(history_path, 'rb') as src, open(temp_path, 'wb') as dst:
dst.write(src.read())
try:
conn = sqlite3.connect(temp_path)
cursor = conn.cursor()
query = """
SELECT url, title, last_visit_time
FROM urls
ORDER BY last_visit_time DESC
LIMIT 100
"""
cursor.execute(query)
results = []
for url, title, last_visit_time in cursor.fetchall():
# Chrome时间是从1601年1月1日开始的微秒数
chrome_time = datetime.datetime(1601, 1, 1) + datetime.timedelta(microseconds=last_visit_time)
results.append({
"url": url,
"title": title,
"visit_time": chrome_time.strftime("%Y-%m-%d %H:%M:%S")
})
conn.close()
return results
finally:
# 清理临时文件
if os.path.exists(temp_path):
os.remove(temp_path)
案例3:内存转储分析 使用Python和Volatility框架分析内存转储文件:
import subprocess
import json
import os
def analyze_memory_dump(dump_path, output_dir):
"""使用Volatility分析内存转储"""
os.makedirs(output_dir, exist_ok=True)
# 检测内存配置文件
profile_cmd = ["volatility", "-f", dump_path, "imageinfo"]
profile_result = subprocess.run(profile_cmd, capture_output=True, text=True)
# 从输出中提取建议的配置文件
profile_line = [line for line in profile_result.stdout.split('\n')
if "Suggested Profile(s)" in line]
if not profile_line:
return {"error": "无法确定内存配置文件"}
profile = profile_line[0].split(":")[1].strip().split(",")[0]
# 常用的Volatility插件列表
plugins = ["pslist", "netscan", "malfind", "cmdscan", "hashdump"]
results = {}
for plugin in plugins:
output_file = os.path.join(output_dir, f"{plugin}.txt")
cmd = ["volatility", "-f", dump_path, "--profile=" + profile, plugin]
with open(output_file, 'w') as f:
subprocess.run(cmd, stdout=f)
results[plugin] = output_file
return {
"profile": profile,
"results": results
}
这些案例展示了Python在数字取证不同领域的应用,从操作系统制品分析到浏览器取证和内存分析。Python的灵活性使其成为取证分析师的强大工具,能够处理各种取证场景。
十一、反取证技术与对抗
11.1 反取证概念与目标
反取证(Anti-Forensics)是指阻止、干扰或误导取证分析的技术和方法。了解这些技术对取证分析师至关重要,不仅能识别并应对这些挑战,还能开发更强大的取证方法。
反取证的主要目标包括:
- 防止数据恢复:使数据无法被恢复或重建
- 隐藏数据:使数据难以被发现或访问
- 混淆数据:使数据难以被正确解释
- 伪造数据:创建虚假证据或时间线
- 增加分析成本:使取证调查更加耗时和昂贵
反取证技术按照功能可分为四大类:
- 数据隐藏:使数据难以被发现
- 数据混淆:使数据难以被理解
- 数据删除:使数据无法被恢复
- 数据伪造:创建误导性或虚假的证据
了解反取证技术对于取证分析师的意义:
- 识别证据可能被篡改或隐藏的线索
- 开发对抗这些技术的方法
- 评估证据的可靠性和完整性
- 在法庭上解释证据的局限性
11.2 数据隐藏技术
数据隐藏技术尝试将数据存储在通常不被审查的位置或以难以被常规取证工具检测的方式存储数据。
-
隐写术(Steganography):在普通文件中隐藏数据
- 图像隐写:在图像像素中嵌入数据
- 音频隐写:在音频文件中隐藏信息
- 视频隐写:利用视频帧或元数据隐藏数据
- 工具:Steghide、OpenPuff、OutGuess
-
交替数据流(ADS):NTFS文件系统的特性
- 允许文件包含多个数据流,但只有主流在常规文件浏览中可见
- 创建方法:
type malware.exe > innocent.txt:hidden.exe - 检测方法:专用工具如LADS或PowerShell命令
-
特殊分区和卷:利用磁盘结构隐藏数据
- 隐藏分区:未分配给驱动器号的分区
- 隐藏卷:加密容器或虚拟分区
- 工具:VeraCrypt、BitLocker、DiskCryptor
-
元数据和扩展属性:在文件元数据中隐藏数据
- 利用不常检查的字段如评论、作者、标题等
- 在文件系统扩展属性中存储数据
-
系统区域:利用系统保留区域
- 主引导记录(MBR)中未使用的空间
- 磁盘间隙(Disk Slack):文件末尾到簇末尾的空间
- 文件间隙(File Slack):文件末尾到扇区末尾的空间
检测数据隐藏的方法:
- 内容分析:分析文件异常特征
- 熵分析:检测数据随机性变化
- 签名分析:识别已知隐写工具的特征
- 结构检查:验证文件格式的完整性
11.3 数据伪造与混淆
数据伪造和混淆技术旨在创建虚假或误导性的信息,干扰取证调查的准确性。
-
时间戳伪造:修改文件时间属性
- 利用工具修改创建、修改和访问时间
- 创建虚假的时间线和活动序列
- 工具:SetMACE、NewFileTime、touch命令
-
元数据修改:改变文件的元数据属性
- 更改作者、创建者、编辑时间等信息
- 工具:ExifTool、metadata-cleaner
-
日志伪造:创建、修改或删除日志条目
- 清除或修改系统事件日志
- 注入虚假的日志条目
- 工具:PowerSploit、LogParser
-
文件头修改:更改文件类型标识
- 修改文件签名和魔术数字
- 混淆文件类型,使工具误解文件内容
-
数据混淆:使数据难以理解
- 加密:使用加密算法保护数据
- 多态技术:不断变化的编码或加密
- 数据分片:将数据分散存储在多个位置
- 自定义编码:使用非标准编码方案
-
解码程序:使用自毁加密密钥
- 在访问后删除密钥
- 依赖外部触发器提供解密密钥
应对数据伪造和混淆的策略:
- 交叉验证:使用多个来源验证信息
- 时间相关性分析:检查不同数据源的时间一致性
- 数据签名分析:检测已知混淆工具的特征
- 内存分析:获取加密数据的解密版本
- 临时文件分析:寻找处理过程留下的痕迹
11.4 反取证对策
面对反取证技术,取证分析师需要开发和应用特定策略来提高调查的有效性:
-
全面采集:获取所有可能的数据源
- 内存获取优先:捕获易失性数据
- 原始磁盘镜像:不仅获取文件系统,还包括未分配空间
- 多源数据收集:收集相关设备、日志和网络数据
-
双工具验证:使用多种工具交叉验证结果
- 利用不同工具的算法和方法差异
- 比较结果以识别不一致或异常
-
基线比较:与已知正常系统比较
- 识别异常的系统配置和行为
- 检测隐藏的系统修改
-
深度分析:超越常规检查
- 低级文件系统分析:检查文件系统结构异常
- 元数据一致性:验证时间戳、属性和内容的一致性
- 签名分析:识别已知反取证工具的痕迹
-
内存分析:绕过磁盘加密和隐藏
- 获取加密密钥和解密内容
- 检测隐藏进程和注入代码
- 找出反取证工具的痕迹
-
案例特定策略:根据特定案例定制方法
- 针对已知反取证技术的专门分析
- 开发自定义脚本和工具解决特定问题
-
持续教育:了解新兴技术和方法
- 跟踪反取证技术的发展
- 学习对抗这些技术的新方法
- 与取证社区分享知识和经验
-
多层次方法:综合各种取证技术
- 结合内存、磁盘、网络和云取证
- 建立综合证据链,减少单点失败风险
尽管反取证技术不断发展,但通过全面、方法化的取证流程,分析师仍然能够应对这些挑战,发现关键证据。
十二、数字取证工具推荐
12.1 商业取证工具
商业取证工具通常提供全面的功能集、技术支持和定期更新,适用于大型组织和专业取证实验室。这些工具经过验证和优化,具有较高的可靠性。
-
EnCase Forensic:广泛使用的数字取证平台
- 全面的证据获取和分析功能
- 强大的搜索和过滤能力
- 广泛接受的法庭证据格式(E01)
- 适用于:全面的取证调查、法律诉讼
-
FTK (Forensic Toolkit):强大的取证检查工具
- 高性能处理和索引功能
- 先进的过滤和搜索能力
- 集成的内存分析功能
- 适用于:大规模数据处理、企业调查
-
Oxygen Forensic Detective:移动设备取证专家
- 支持广泛的手机和云服务
- 强大的应用数据分析
- 社交媒体和消息应用分析
- 适用于:移动设备和云服务调查
-
X-Ways Forensics:高效的取证检查软件
- 低资源消耗,高性能
- 灵活的文件系统支持
- 精细的数据分析功能
- 适用于:技术调查人员、详细分析
-
Magnet AXIOM:综合取证平台
- 计算机、移动设备和云取证
- 先进的人工智能分析功能
- 用户友好的界面和报告功能
- 适用于:整合多源证据、全面调查
商业工具的优势包括技术支持、定期更新、培训资源和法庭可接受性,但成本较高且通常需要专业培训。
12.2 开源取证工具
开源取证工具提供免费或低成本的解决方案,适用于预算有限的组织和学习目的。这些工具通常由社区驱动,支持广泛的自定义和扩展。
-
Autopsy:基于GUI的数字取证平台
- The Sleuth Kit的图形界面
- 多种分析模块(关键词搜索、文件分析等)
- 可扩展的模块系统
- 适用于:一般取证调查、教育环境
-
SIFT Workstation:SANS调查取证工具套件
- 预配置的Linux取证环境
- 包含多种开源取证工具
- 支持多种取证格式
- 适用于:全面取证调查、事件响应
-
Volatility Framework:内存取证框架
- 支持多种操作系统的内存分析
- 强大的插件系统
- 深入的内存分析能力
- 适用于:内存取证、恶意软件分析
-
Wireshark:网络协议分析器
- 深入的数据包检查功能
- 支持数百种协议
- 强大的过滤和搜索功能
- 适用于:网络取证、通信分析
-
Bulk Extractor:高速取证分析工具
- 快速提取电子邮件、信用卡号码、URL等
- 支持并行处理
- 不依赖文件系统
- 适用于:大规模数据扫描、模式识别
-
Kali Linux:安全和取证的Linux发行版
- 预装多种取证和安全工具
- 定期更新
- 支持多种硬件
- 适用于:全面取证环境、渗透测试
开源工具的优势包括成本效益、灵活性和社区支持,但可能缺乏商业工具的技术支持和用户友好性。
12.3 反取证工具
了解反取证工具对取证分析师很重要,不仅要识别这些工具的使用痕迹,还要了解其工作原理,发展更有效的对抗策略。
-
数据擦除工具:
- Eraser:安全删除文件和磁盘数据
- DBAN (Darik’s Boot and Nuke):完全擦除硬盘
- BleachBit:系统清理和隐私保护工具
-
隐写工具:
- Steghide:图像和音频隐写工具
- OpenPuff:多格式隐写工具
- DeepSound:音频文件隐写工具
-
加密工具:
- VeraCrypt:磁盘加密软件,TrueCrypt后继
- AxCrypt:文件加密工具
- BitLocker:Windows内置磁盘加密
-
元数据工具:
- ExifTool:查看和修改元数据
- Metadata Remover:移除文件元数据
- MAT2 (Metadata Anonymisation Toolkit):清除元数据
-
系统隐藏工具:
- Alternate Data Streams Viewer:管理NTFS交替数据流
- RunAs:以不同用户身份运行程序
- Rootkit工具:隐藏系统活动
取证分析师应了解这些工具的特征和痕迹,以便在调查中识别它们的使用:
- 安装痕迹:软件安装记录和文件
- 配置文件:工具设置和配置
- 系统改变:修改的系统设置和组件
- 使用模式:时间异常和用户行为变化
12.4 专业领域取证工具
不同的取证领域需要专门的工具来处理特定类型的证据和分析:
-
移动设备取证:
- Cellebrite UFED:全面的移动设备取证工具
- Belkasoft X:移动和云取证
- Andriller:Android取证工具
- iLEAPP/ALEAPP:iOS/Android分析工具
-
内存取证:
- Volatility Framework:内存分析框架
- Rekall:内存取证框架
- WinPmem/LinPmem:内存获取工具
- Redline:FireEye的内存分析工具
-
网络取证:
- NetworkMiner:网络取证分析工具
- Zeek (Bro):网络安全监控
- PcapXray:网络流量可视化
- Xplico:互联网流量解码器
-
数据恢复:
- TestDisk:磁盘恢复工具
- PhotoRec:文件恢复工具
- R-Studio:高级数据恢复
- Scalpel:文件雕刻工具
-
云取证:
- Magnet AXIOM Cloud:云数据获取
- Oxygen Forensic Cloud Extractor:云证据提取
- UFED Cloud Analyzer:云内容分析
- CloudTrail:AWS审计和监控
-
恶意软件分析:
- REMnux:恶意软件分析Linux发行版
- Cuckoo Sandbox:自动恶意软件分析
- Ghidra:NSA开发的逆向工程工具
- IDA Pro:交互式反汇编器
-
取证分析环境:
- SIFT Workstation:完整取证环境
- Paladin:取证启动环境
- CAINE (Computer Aided INvestigative Environment):取证Linux发行版
- BlackLight:全面的取证分析平台
选择合适的专业工具取决于特定案例的需求、数据类型和调查目标。通常需要结合多种工具创建完整的工作流程,以处理复杂的取证场景。
十三、云环境取证
13.1 云取证基础与挑战
云取证是响应技术发展的新兴领域,关注从云服务提供商的基础设施、平台和软件中获取和分析数据。云环境的分散性、虚拟化和多租户特性带来了独特的取证挑战。
云计算的三种主要服务模型对取证产生不同影响:
- 基础设施即服务(IaaS):提供虚拟机和存储,调查人员可能有更多访问底层组件的能力
- 平台即服务(PaaS):提供开发和部署平台,访问权限通常限于应用程序和数据
- 软件即服务(SaaS):提供应用程序,取证通常仅限于用户数据和日志
云取证面临的主要挑战包括:
- 数据定位:数据可能分布在多个地理位置和法律管辖区,增加了获取和法律复杂性
- 法律和隐私问题:不同国家和地区有不同的数据保护法律和取证程序要求
- 多租户环境:客户数据共存于同一物理基础设施,增加了隔离和提取特定数据的难度
- 动态环境:资源可以快速创建和销毁,导致证据易失性增加
- 服务水平协议(SLA)限制:提供商合同可能限制取证调查的能力
- 证据收集标准化:缺乏标准化方法收集云环境证据
- 信任链:依赖第三方提供商维护证据完整性
云取证模型需要考虑这些因素,并开发适应分布式、虚拟化环境的方法和工具。
13.2 云数据获取方法
云数据获取需要根据服务模型和访问级别采取不同策略。主要获取方法包括:
-
客户端获取:从访问云服务的设备获取数据
- 浏览器缓存、历史记录和cookies
- 同步文件和本地副本
- 客户端应用程序数据和日志
- 身份验证令牌和凭据
-
API访问:通过服务提供商的编程接口获取数据
- 使用OAuth和应用密钥进行认证
- 批量下载用户数据和元数据
- 获取审计日志和活动记录
- 示例:使用Google Takeout、Microsoft Graph API或AWS CLI
-
服务提供商协助:通过法律程序获取提供商提供的数据
- 法院命令和搜查令
- 保存请求和法律保全
- 提供商生成的报告和导出
- 加密密钥和访问令牌
-
虚拟机取证:针对IaaS环境
- 虚拟机快照和镜像获取
- 内存转储分析
- 磁盘卷获取和分析
- 示例工具:AWS EBS快照、Azure磁盘快照
-
容器取证:针对容器化环境
- 容器镜像分析
- 运行时状态捕获
- 容器编排平台(如Kubernetes)日志
云数据获取的最佳实践:
- 记录收集过程中的所有步骤
- 使用哈希验证下载的数据
- 保留元数据和访问时间信息
- 考虑时区差异和时间同步问题
- 使用专门设计的云取证工具
13.3 主要云服务取证
不同云服务提供商和平台需要特定的取证方法和技术:
-
AWS取证:
- 关键数据源:CloudTrail(API活动)、VPC Flow Logs(网络流量)、S3访问日志、EC2实例
- 获取方法:AWS CLI、控制台导出、CloudWatch日志、EBS快照
- 取证工具:AWS CLI、Amazon Detective、第三方AWS取证工具
- 注意事项:区域特定存储、IAM权限模型、临时访问令牌
-
Microsoft Azure取证:
- 关键数据源:Azure活动日志、安全中心、存储账户、虚拟机
- 获取方法:Azure门户导出、PowerShell脚本、REST API、磁盘快照
- 取证工具:Azure Security Center、Log Analytics、Microsoft Graph API
- 注意事项:租户架构、Azure AD集成、地理数据驻留
-
Google Cloud取证:
- 关键数据源:Cloud Audit Logs、VPC流日志、Cloud Storage、Compute Engine
- 获取方法:Google Cloud控制台、gcloud CLI、API访问、磁盘快照
- 取证工具:Google Cloud Security Command Center、Cloud Logging
- 注意事项:项目组织结构、IAM角色、服务账号
-
SaaS应用取证:
- Microsoft 365:
- 来源:Exchange Online、SharePoint、Teams、OneDrive
- 工具:Microsoft 365 eDiscovery、Compliance Center、Office 365 Management API
- Google Workspace:
- 来源:Gmail、Drive、Docs、Admin控制台
- 工具:Google Vault、Admin SDK、Google Takeout
- Slack:
- 来源:频道消息、私人消息、文件
- 工具:Slack Discovery API、导出功能、审计日志
- Microsoft 365:
-
社交媒体和通信服务:
- 来源:用户生成内容、时间线、私信、连接数据
- 方法:API访问、法律请求、用户数据导出
- 挑战:速率限制、内容过期策略、加密通信
13.4 云取证分析技术
云取证分析需要针对云环境的独特特性开发特定技术:
-
日志分析:云服务生成大量日志,需要高效处理
- 大规模日志处理技术
- 正则表达式和模式匹配
- 日志关联和时间同步
- 工具:ELK Stack、Splunk、Google BigQuery
-
时间线重建:跨多个服务和组件的活动序列
- 标准化不同来源的时间戳
- 关联用户活动和系统事件
- 可视化复杂的云交互
- 工具:Timesketch、Chronicle、自定义时间线生成脚本
-
容器和虚拟机分析:
- 容器镜像层分析
- 虚拟机磁盘和内存分析
- 应用程序和系统日志检查
- 工具:Docker Scout、Sysdig Inspect、Volatility(虚拟机内存分析)
-
数据关联和可视化:
- 跨服务数据关联
- 用户活动和身份关联
- 网络流量和API调用映射
- 工具:Neo4j、Gephi、D3.js、Grafana
-
自动化分析:
- 云原生取证分析脚本
- 数据转换和标准化管道
- 机器学习异常检测
- 工具:Python脚本、Jupyter Notebooks、Terraform
云取证分析的最佳实践:
- 优先关注易失性数据和短期日志
- 建立虚拟机实例和容器镜像的基线
- 利用云服务提供商的安全分析功能
- 对获取的数据应用本地取证方法
- 考虑数据驻留和法律管辖权问题
十四、物联网与嵌入式设备取证
14.1 物联网取证的范围与挑战
物联网(IoT)取证关注从互联设备(如智能家居设备、可穿戴技术和传感器)获取和分析数据。这个领域因设备多样性、协议差异和资源限制而面临独特挑战。
物联网生态系统通常包括三个主要组件:
- 设备层:物理设备和传感器(如智能音箱、恒温器、健身追踪器)
- 网络层:设备之间以及设备与云之间的通信(Wi-Fi、蓝牙、ZigBee、Z-Wave等)
- 应用层:控制和管理设备的应用程序和云服务
物联网取证面临的主要挑战包括:
- 设备多样性:数千种不同的IoT设备,硬件和软件各不相同
- 专有固件:许多设备使用专有操作系统和固件,难以分析
- 有限存储:许多IoT设备有最小化的本地存储,数据快速覆盖
- 数据加密:设备通信和存储常使用加密,增加分析难度
- 物理访问限制:有些设备可能嵌入在困难或危险的环境中
- 易失性数据:许多IoT设备在断电时丢失所有数据
- 取证工具缺乏:与传统数字取证相比,专用IoT取证工具相对匮乏
- 现场保护:确保物理设备不被篡改或重置的难度
物联网取证要求结合嵌入式系统知识、网络分析和云取证技能,需要创新方法来处理这些独特挑战。
14.2 嵌入式设备数据获取
嵌入式设备数据获取需要多种技术,取决于设备类型、接口和可访问性:
-
物理获取方法:
- JTAG/SWD接口:低级调试接口,允许直接读取存储芯片
- 需要识别设备上的测试点
- 使用专用JTAG适配器连接
- 可以绕过设备安全措施
- 芯片脱机(Chip-Off):物理移除存储芯片并直接读取
- 需要专门的设备和专业知识
- 风险较高,可能破坏数据
- 适用于严重损坏的设备
- 固件提取:从设备存储芯片获取固件
- 通过直接连接闪存芯片
- 使用SPI或I2C协议读取
- 需要正确识别芯片引脚和电压
- JTAG/SWD接口:低级调试接口,允许直接读取存储芯片
-
逻辑获取方法:
- 通过设备接口:USB、串行、网络等
- 使用系统提供的调试接口
- 命令行或管理界面访问
- 可能需要开发者模式或特殊访问
- 固件更新机制:利用更新过程访问数据
- 截获更新过程中的固件包
- 检查更新验证机制
- 备份现有固件进行分析
- 无线捕获:拦截设备无线通信
- 捕获Wi-Fi、蓝牙、ZigBee等流量
- 使用专用射频捕获设备
- 解码专有协议和格式
- 通过设备接口:USB、串行、网络等
-
专用获取工具:
- 嵌入式系统调试器:用于访问系统内存和存储
- 逻辑分析仪:捕获数字信号和通信协议
- 总线分析仪:监控设备内部数据传输
- 固件提取和分析工具:如Binwalk、FirmWalker、Ghidra
嵌入式设备数据获取的最佳实践:
- 记录设备序列号、型号和固件版本
- 保持设备供电以保存易失性数据
- 首先尝试最少侵入性的方法
- 创建存储内容的位对位副本
- 收集相关配套应用和云数据
- 详细记录所有获取步骤和方法
14.3 智能家居设备取证
智能家居设备包含大量潜在证据,从用户活动模式到语音命令和设备状态:
-
智能音箱与虚拟助手:
- 关键数据:语音命令历史、用户查询、设备活动日志、账户信息
- 获取方法:
- 云服务获取(如Amazon Alexa或Google Assistant历史)
- 配套移动应用程序分析
- 设备本地存储提取(如缓存和临时文件)
- 分析重点:使用模式、位置数据、时间线重建、设备互动
-
智能安全系统:
- 关键数据:视频片段、活动检测、用户访问记录、警报历史
- 获取方法:
- NVR/DVR存储分析
- 云存储访问(通过账户或API)
- SD卡和本地缓存提取
- 分析重点:时间戳验证、视频篡改检测、活动模式、系统日志
-
智能家居控制器和集线器:
- 关键数据:设备连接历史、自动化规则、用户互动日志、网络配置
- 获取方法:
- 固件提取和分析
- 数据库和日志文件提取
- 备份文件分析
- 分析重点:设备状态变化、网络活动、时间线、用户交互
-
智能照明和环境控制:
- 关键数据:使用模式、计划活动、状态变化、远程访问
- 获取方法:
- 控制器数据库提取
- 移动应用数据分析
- 云服务日志获取
- 分析重点:在场/不在场指标、常规活动模式、异常触发
-
智能电视和流媒体设备:
- 关键数据:观看历史、搜索记录、应用使用、登录信息
- 获取方法:
- 板载存储分析
- 网络流量捕获
- 账户活动历史
- 分析重点:用户活动、时间线、内容访问、账户关联
智能家居设备取证的关键考虑因素:
- 设备间的互联性和数据共享
- 物理访问与远程访问结合
- 用户账户和多用户环境
- 时间同步和时区差异
- 设备自动更新和远程擦除风险
14.4 可穿戴设备和健康监测器
可穿戴技术如智能手表、健身追踪器和健康监测设备存储多种敏感和取证相关数据:
-
智能手表:
- 关键数据:位置历史、健康指标、通知记录、应用使用、消息
- 获取方法:
- 配对手机分析
- 云账户数据访问
- 设备备份分析
- 通过调试接口直接获取
- 分析重点:活动时间线、位置数据、通信记录、健康状态
-
健身追踪器:
- 关键数据:GPS路线、步数、心率、睡眠模式、活动记录
- 获取方法:
- 移动应用数据库
- 云服务API访问
- 设备同步数据缓存
- 分析重点:活动模式、位置历史、在场证明、健康状态变化
-
医疗监测设备:
- 关键数据:健康指标、活动水平、药物提醒、异常警报
- 获取方法:
- 医疗记录系统访问
- 设备日志提取
- 配套应用分析
- 分析重点:健康状态、活动能力、治疗依从性、异常警报
-
智能眼镜和头戴设备:
- 关键数据:视频/音频记录、应用使用、位置数据、用户互动
- 获取方法:
- 内部存储提取
- 云账户访问
- 配套设备分析
- 分析重点:视觉/音频证据、使用模式、环境信息
可穿戴设备取证的特殊考虑:
- 数据隐私和法律获取授权
- 健康数据特殊保护要求
- 设备与云服务数据同步模式
- 传感器准确性和数据可靠性
- 多传感器数据关联和验证
十五、取证准备与规划
15.1 取证就绪性概念
取证就绪性(Forensic Readiness)是组织预先规划和准备,以便在需要时能够最大化收集可用数字证据的能力,同时最小化取证调查的成本和干扰。
取证就绪性的关键目标包括:
- 最大化组织从数字证据中获取情报的能力
- 最小化取证调查的成本和时间
- 确保收集到的证据具有法律效力和可接受性
- 减轻安全事件的业务影响
- 为网络安全事件和内部调查建立响应能力
取证就绪性计划的关键组成部分:
- 风险评估:了解可能需要取证调查的情境和风险
- 证据识别:确定潜在的证据来源和类型
- 证据收集和保存方法:制定程序和配置系统以捕获证据
- 法律和监管考虑:确保符合相关法律要求
- 人员角色和责任:明确定义谁负责取证活动
- 培训和意识:确保相关人员具备必要的技能
- 工具和资源:识别和部署必要的取证工具
- 测试和演练:定期测试取证就绪能力
取证就绪性框架应与现有的事件响应、业务连续性和安全管理框架集成,形成组织整体安全战略的一部分。
15.2 企业环境的取证准备
企业环境的取证准备需要系统化的方法,考虑技术、法律和组织因素:
-
政策和程序:
- 取证调查政策,明确定义何时、如何开展取证活动
- 证据收集、处理和保存程序
- 事件分类和升级路径
- 记录保留策略和要求
- 隐私考虑和合规要求
-
技术基础设施:
- 日志管理:集中式日志收集、存储和保护
- 配置全面的系统和应用程序日志
- 实施集中式日志服务器或SIEM解决方案
- 确保日志完整性和防篡改措施
- 监控系统:用于检测可疑活动
- 网络监控和流量分析
- 端点检测和响应(EDR)解决方案
- 用户行为分析系统
- 存储考虑:确保足够的存储容量
- 长期日志和监控数据存储
- 取证镜像和证据存储
- 安全备份和归档系统
- 日志管理:集中式日志收集、存储和保护
-
人员准备:
- 定义取证团队角色和责任
- 提供取证工具和技术培训
- 开展取证意识培训
- 建立法律和技术专家网络
- 确定外部专家和服务提供商
-
工具和技术:
- 企业级取证工具和平台
- 远程取证能力
- 数据保存和收集解决方案
- 证据分析和报告工具
- 密码恢复和解密能力
-
供应链和第三方考虑:
- 合同中的取证协议和条款
- 供应商取证协助协议
- 云服务提供商的取证准备
- 跨组织边界的取证协作
-
就绪性测试和演练:
- 定期取证准备评估
- 模拟事件响应演练
- 测试证据收集和保存流程
- 验证工具和技术的有效性
企业取证准备的最佳实践:
- 采用风险基础方法,关注最有价值的资产
- 将取证准备与整体安全计划集成
- 记录所有政策、程序和技术配置
- 定期审查和更新取证能力
- 保持与法律和监管要求的一致
15.3 取证实验室设置与认证
建立专业的取证实验室需要考虑物理设施、设备、流程和认证标准:
-
实验室类型:
- 专用实验室:固定的专用空间,完全受控环境
- 移动实验室:便携式设备,可在现场进行取证活动
- 虚拟实验室:远程访问的基础设施,支持分散式工作
- 混合模型:结合上述方法,根据需求灵活使用
-
物理设施要求:
- 安全访问控制和监控
- 证据存储保险箱和安全区域
- 适当的电源和备用发电
- 网络隔离和保护
- 环境控制(温度、湿度、静电防护)
- 工作站和会议区域
-
技术基础设施:
- 取证工作站(处理高性能和特殊硬件)
- 证据存储服务器和解决方案
- 写保护设备和取证桥接器
- 各种连接器、适配器和专用硬件
- 多种操作系统环境
- 取证软件套件和专用工具
-
标准操作程序(SOPs):
- 证据接收和记录程序
- 证据处理和分析协议
- 证据链维护流程
- 报告生成和案例管理
- 质量保证和验证程序
- 证据返还和处置流程
-
认证与标准合规:
- ISO/IEC 17025:测试和校准实验室通用要求
- ISO/IEC 27037:数字证据识别、收集、获取和保存指南
- ASCLD/LAB:美国犯罪实验室主任/实验室认证委员会
- SWGDE:数字证据科学工作组标准
- 国家特定认证:如英国的Forensic Science Regulator
-
人员资质与培训:
- 专业认证(如GCFA、EnCE、CCE等)
- 持续教育和技能发展
- 专业道德和行为准则
- 专家证人培训
- 角色特定培训和资格
-
文档和质量管理:
- 全面的案例管理系统
- 详细的证据文档和程序记录
- 质量保证和工具验证文档
- 定期审计和合规检查
- 持续改进流程
取证实验室设置的最佳实践:
- 对实验室设计进行风险评估
- 建立清晰的取证流程和程序
- 投资适当的工具和培训
- 实施严格的质量保证措施
- 保持与行业标准和最佳实践的一致
- 准备专家证人作证的需求
15.4 事件响应与数字取证的集成
数字取证和事件响应是密切相关的领域,有效的集成可以显著提高组织的安全防护能力:
-
事件响应与取证的关系:
- 事件响应:注重快速控制和恢复
- 数字取证:注重证据收集和详细分析
- 集成方法:在响应过程中保护和收集证据,同时快速恢复业务
-
集成DFIR(数字取证和事件响应)框架:
- 准备阶段:制定政策、部署工具、培训团队
- 检测与分析:识别事件并进行初步取证分类
- 遏制、根除与恢复:在保护证据的同时执行响应措施
- 后事件活动:详细取证分析和完整调查
- 反馈与改进:根据调查结果改进安全控制和DFIR流程
-
关键整合点:
- 共享工具和平台:
- 统一的事件管理系统
- 集成的分析平台
- 共享证据存储和管理
- 流程集成:
- 证据保存纳入响应流程
- 取证分析支持根因分析
- 协调的文档和报告流程
- 团队协作:
- 明确的角色和责任
- 跨职能技能和理解
- 协调的升级和通知流程
- 共享工具和平台:
-
取证就绪型事件响应:
- 设计响应活动以保护潜在证据
- 创建响应流程的取证记录
- 维护响应行动的详细日志
- 优先保存易失性数据
- 将响应工具配置为保留取证信息
-
实时取证与分类:
- 快速取证分析以指导响应决策
- 初步证据收集以确定事件范围
- 优先级划分和事件分类
- 数据泄露和法规要求评估
- 威胁情报集成和攻击者归因
-
集成工具和自动化:
- 端点检测和响应(EDR)解决方案
- 安全编排自动化和响应(SOAR)平台
- 远程取证功能
- 自动化证据收集脚本
- 集成的分析和报告工具
DFIR集成的最佳实践:
- 开发同时考虑取证和响应需求的流程
- 建立跨职能DFIR团队
- 实施支持两种需求的技术解决方案
- 进行联合培训和演练
- 定期审查和更新集成流程
- 维护明确的通信和升级渠道
十六、法律与道德考虑
16.1 数字取证法律框架
数字取证必须在适用的法律框架内进行,以确保证据的合法性和可接受性。不同国家和管辖区的法律要求可能有显著差异,取证从业人员必须了解这些要求。
数字取证的主要法律考虑包括:
-
搜查和扣押法律:
- 获取电子设备的法律要求
- 搜查令范围和限制
- 紧急情况例外和无令搜查
- 私人对政府搜查的不同规则
-
证据规则:
- 证据相关性和可靠性要求
- 最佳证据规则和数字复制
- 证据链要求
- 证据认证和验证标准
-
隐私法律:
- 数据保护法规(如GDPR、CCPA)
- 员工隐私权与雇主监控
- 通信隐私法律(如美国的ECPA)
- 跨境数据传输限制
-
专业特权:
- 律师-客户特权通信
- 医患保密信息
- 其他受保护的专业关系
- 业务敏感和商业秘密考虑
-
司法管辖权问题:
- 跨境调查挑战
- 国际合作和司法协助
- 云数据的司法管辖权问题
- 域外证据收集法律
-
专家证词规则:
- 专家资格和认证要求
- 科学证据可接受性标准
- 专家意见的限制
- Daubert/Frye等科学证据标准
-
行业特定法规:
- 金融服务法规(如SOX)
- 医疗数据法规(如HIPAA)
- 电信和互联网服务提供商法规
- 关键基础设施要求
取证活动的法律基础可以多种形式存在:
- 法院授权(如搜查令、法院命令)
- 法规授权(特定法律下的权力)
- 同意(用户或组织的明确许可)
- 雇主政策(组织内部调查)
- 合同权利(服务协议条款)
数字取证从业者需要与法律顾问密切合作,确保取证活动符合相关法律要求。
16.2 证据可采性与法庭呈现
数字证据要在法庭上被接受,必须满足多项标准,取证专家需要了解并遵循这些要求:
-
数字证据可采性的关键要素:
- 相关性:证据与案件事实相关
- 可靠性:证据准确、可信赖
- 充分性:证据足以支持其意图的结论
- 真实性:证据是所声称的内容,未被篡改
- 获取合法性:证据通过合法手段获取
-
证据认证要求:
- 确认证据是真实的
- 证明证据与案件相关
- 建立证据的来源和历史
- 证明证据未被更改
- 关联证据与特定个人或设备
-
证据链(Chain of Custody):
- 记录谁、何时、在哪里接触了证据
- 保护证据的物理和逻辑完整性
- 记录任何证据传递或处理
- 维护一致、清晰的记录
- 证明证据的连续监管
-
专家证词准备:
- 清晰解释技术概念
- 避免行业术语和复杂专业词汇
- 准备视觉辅助材料
- 预期反对方质疑和抗辩
- 专注于方法和事实,避免推测
-
报告和文档标准:
- 全面详细的取证报告
- 清晰的分析方法说明
- 工具和程序的完整记录
- 包含工具验证和质量控制
- 所有结论的科学依据
-
科学证据标准:
- Daubert标准:美国许多司法管辖区的要求
- 理论或技术是否可测试
- 是否经过同行评审和发表
- 已知或潜在的错误率
- 存在的标准和控制
- 方法在科学界的接受度
- Frye标准:一些司法管辖区使用
- 技术在相关科学界的一般接受性
- Daubert标准:美国许多司法管辖区的要求
-
证据呈现最佳实践:
- 使用清晰、简洁的语言
- 提供适当的视觉辅助
- 以线性方式呈现技术流程
- 使用类比解释复杂概念
- 强调结论的科学基础
- 承认限制和不确定性
16.3 职业道德与最佳实践
数字取证从业者面临各种道德挑战,需要遵循专业标准和最佳实践:
-
专业道德原则:
- 客观性:保持中立,不偏不倚
- 完整性:诚实、准确地报告发现
- 透明度:清晰记录所有方法和决策
- 保密性:保护敏感信息和隐私
- 能力:在专业知识范围内工作
- 责任:为行动和结论负责
-
取证道德挑战:
- 利益冲突识别和管理
- 维护证据完整性和客观性
- 处理敏感和个人数据
- 报告限制和不确定性
- 在压力下维持专业标准
- 避免证据选择性报告
-
专业道德准则:
- ISFCE道德准则(国际电子取证认证组织)
- IACIS道德准则(国际计算机调查专家协会)
- DFCB道德准则(数字取证认证委员会)
- 特定国家的司法和执法准则
-
保持专业界限:
- 认识并尊重专业能力限制
- 适当时寻求额外专业知识
- 清晰沟通可交付成果和限制
- 避免超出专业能力范围的陈述
- 区分事实发现和专家意见
-
持续专业发展:
- 保持最新的技术知识
- 跟踪行业标准和最佳实践
- 参与专业组织和社区
- 定期更新技能和认证
- 同行学习和合作
-
沟通道德责任:
- 以准确、清晰的方式呈现发现
- 解释分析的限制和不确定性
- 避免误导性陈述或夸张
- 确保所有相关方理解发现的含义
- 维持专业沟通标准
数字取证专业人员应该将道德考虑融入日常实践,始终保持最高的专业标准,不仅遵守法律要求,还要坚持道德原则,维护取证领域的诚信和可信度。
十七、未来趋势与发展
17.1 人工智能与机器学习在取证中的应用
人工智能(AI)和机器学习(ML)技术正在改变数字取证领域,提供自动化分析、模式识别和异常检测能力,帮助处理日益增长的数据量和复杂性。
AI/ML在数字取证中的关键应用领域:
-
大规模数据分析:
- 自动处理和分类海量数据
- 识别相关证据中的模式和关联
- 减少手动数据分类和审查时间
- 处理非结构化数据(如图像、视频、文本)
- 示例工具:Magnet AXIOM AI、OpenText EnCase AI
-
异常检测:
- 识别网络通信中的异常模式
- 检测用户行为偏差
- 识别文件系统异常活动
- 标记可疑的注册表或系统更改
- 示例应用:UEBA系统、AI驱动的EDR平台
-
媒体分析:
- 图像分类和识别
- 视频内容自动分析
- 音频记录转录和分析
- 深度伪造检测
- 示例技术:计算机视觉API、音频分析工具
-
数字取证分类:
- 自动化证据优先级排序
- 分类潜在相关文件
- 识别需要进一步调查的项目
- 减少取证噪音和不相关数据
- 示例方法:监督学习分类器、聚类算法
-
自然语言处理:
- 从文档、消息和通信中提取情报
- 实体识别和关系映射
- 情感分析和意图识别
- 多语言内容分析
- 示例应用:NLP工具包、语义分析引擎
-
预测分析:
- 基于历史案例预测调查方向
- 识别潜在证据位置
- 估计对不同调查策略的时间和资源需求
- 优化取证工作流程
- 示例技术:预测模型、决策支持系统
AI/ML在取证中的挑战:
- 结果可解释性和透明度
- 偏见和公平性问题
- 工具验证和法庭可接受性
- 误报和漏报平衡
- 取证从业者的技能需求变化
尽管面临这些挑战,AI和ML技术正在成为应对不断增长的数字证据复杂性和数量的关键工具,未来将在取证工作流程中扮演越来越重要的角色。
17.2 量子计算与加密挑战
量子计算的发展对数字取证领域带来重大影响,尤其是在密码学和数据安全方面:
-
量子计算对传统加密的威胁:
- Shor算法可能破解RSA和ECC等公钥算法
- 量子计算可能将当前加密保护降低到不安全级别
- 可能需要重新检视历史加密证据
- 数字签名和证据完整性验证面临挑战
-
后量子密码学:
- 抗量子加密算法的发展
- 晶格基础、哈希基础和编码基础方法
- NIST后量子加密标准化努力
- 取证工具需要适应新的加密标准
-
量子取证挑战:
- 分析量子加密通信和存储
- 开发新的取证算法和方法
- 证据提取和分析工具的重大变革
- 法律和监管框架的适应
-
量子计算的取证潜力:
- 加速复杂计算和模式识别
- 提高大规模数据分析能力
- 加快密码破解和数据恢复
- 解决当前技术难以处理的问题
-
取证就绪性准备:
- 教育和人员培训
- 工具和框架的前瞻性发展
- 研究后量子环境中的证据收集方法
- 组织准备和标准制定
量子计算既是挑战也是机遇,取证专业人员需要关注这一领域的发展,同时准备应对颠覆性变革。
17.3 区块链取证
区块链技术的广泛应用创造了新的数字取证领域,需要专门的技术和方法:
-
区块链基础:
- 分布式账本技术的运作原理
- 共识机制和验证过程
- 公链、私链和联盟链的区别
- 智能合约和去中心化应用(DApps)
-
区块链取证挑战:
- 去中心化数据的获取难度
- 匿名和假名技术(如零知识证明)
- 跨链和跨平台调查
- 加密密钥和钱包取证
- 智能合约逆向工程和分析
-
加密货币调查:
- 比特币、以太坊和其他主要加密货币分析
- 交易追踪和可视化
- 地址聚类和身份归属
- 混币服务和隐私币调查
- 交易所数据和KYC信息获取
-
区块链取证方法:
- 区块链数据抓取和索引
- 交易图分析和模式识别
- 钱包取证和密钥恢复
- 智能合约分析和漏洞检测
- 链下数据关联和集成
-
区块链取证工具:
- Chainalysis、CipherTrace等商业平台
- BlockSci、BitcoinExplorer等开源工具
- 区块链分析APIs和数据服务
- 自定义Python分析脚本和库
- 区块链浏览器和可视化工具
-
法律和监管考虑:
- 多司法管辖区调查的复杂性
- 证据可采性和提交标准
- 监管机构协作和信息共享
- 隐私法规与区块链透明度的平衡
区块链取证是一个快速发展的领域,要求专业人员持续学习和适应新技术,同时将传统取证原则应用于这一独特环境。
17.4 新兴设备与技术
数字技术的快速发展不断引入新的取证挑战和机会。以下是一些重要的新兴领域:
-
边缘计算取证:
- 分布式处理环境中的数据采集
- 边缘设备上的易失性数据捕获
- 网关和节点间通信分析
- 集成边缘和云数据创建完整图景
-
增强和虚拟现实取证:
- AR/VR设备数据提取
- 虚拟环境活动和交互分析
- 空间映射和位置数据恢复
- 用户行为和活动重建
-
自动驾驶车辆取证:
- 车载计算机和传感器数据获取
- 通信记录和远程更新分析
- 决策算法和事件重建
- 车辆对车辆(V2V)通信调查
-
5G和高级网络取证:
- 网络切片和虚拟化环境分析
- 大规模物联网设备通信调查
- 超低延迟通信捕获和分析
- 多接入边缘计算(MEC)取证
-
生物识别系统取证:
- 生物识别数据获取和分析
- 模板和原始生物特征数据处理
- 系统验证过程和访问控制分析
- 生物识别欺骗和篡改检测
-
脑机接口和神经技术:
- 神经数据和用户交互分析
- 脑机接口设备提取
- 神经命令和控制信号证据
- 神经反馈和响应模式研究
-
量子互联网和通信:
- 量子密钥分发系统分析
- 量子纠缠通信取证
- 后量子环境中的数据获取
- 量子通信安全措施评估
应对这些新兴技术的关键策略:
- 持续教育和专业发展
- 跨学科协作(工程、计算机科学、法律等)
- 参与标准制定和最佳实践开发
- 与技术创新者和制造商协作
- 前瞻性取证研究和工具开发
数字取证领域必须不断发展以跟上技术创新步伐,这需要取证专业人员保持灵活性和适应性,同时坚持核心取证原则和方法论。
十八、结论与资源
18.1 数字取证的未来发展
数字取证领域正面临前所未有的机遇和挑战,未来发展将由技术进步、法律变化和社会需求共同塑造。取证专业人员需要不断学习和适应才能在这一动态环境中保持有效。
数字取证未来发展的关键趋势:
-
规模和复杂性增长:
- 数据量呈指数级增长,单个调查可能涉及TB或PB级数据
- 设备类型和数量激增,包括IoT、穿戴设备、智能家居等
- 取证工具需要处理大规模数据集和异构数据源
- 云计算和分布式系统增加调查复杂性
-
自动化和智能分析:
- AI/ML技术在初步分析和数据分类中的应用扩大
- 交互式可视化工具简化复杂数据集理解
- 自动异常检测和模式识别减轻分析师负担
- 智能取证平台整合多种工具和技术
-
法律和监管环境变化:
- 隐私法规日益严格(GDPR等)对取证活动产生影响
- 跨国调查和司法管辖权挑战需要新框架
- 证据标准适应新技术环境
- 平衡安全需求与隐私保护
-
专业标准和认证发展:
- 更严格的取证从业人员资格要求
- 工具和方法的标准化和验证增强
- 行业认证与正规教育的结合
- 国际标准和最佳实践的统一
-
融合取证方法:
- 取证学科间界限模糊(如数字、网络、物理、生物取证)
- 端到端调查平台整合多种取证领域
- 物理和数字世界交互点的重要性增加
- 集成调查方法应对混合威胁和攻击
-
反取证技术对抗:
- 加密和隐私技术普及增加取证挑战
- 反取证工具和方法日益复杂
- 内存取证与实时分析重要性增强
- 预期反取证措施的主动取证方法
成功应对未来挑战的关键要素:
- 持续学习和技能发展
- 跨学科知识和协作
- 创新思维和适应能力
- 坚守取证基本原则和道德标准
- 与时俱进的工具和方法
18.2 持续教育与专业发展
数字取证是一个快速发展的领域,需要持续学习和专业发展:
-
正规教育路径:
- 计算机科学、网络安全或取证学位
- 研究生和博士级取证专业
- 专业证书课程和短期培训
- 司法和法律方面的辅助教育
-
专业认证:
- 一般取证认证:
- EnCE (EnCase Certified Examiner)
- GCFA (GIAC Certified Forensic Analyst)
- CFCE (Certified Forensic Computer Examiner)
- CCE (Certified Computer Examiner)
- 专业领域认证:
- CCME (Certified Computer Mobile Examiner)
- CCPA (Certified Cyber-Crime Professional Associate)
- CHFI (Computer Hacking Forensic Investigator)
- CCFE (Certified Computer Forensics Examiner)
- 一般取证认证:
-
持续教育资源:
- 专业组织会议和研讨会
- 线上学习平台和课程
- 厂商特定培训和认证
- 实验室和实践环境
- 学术和行业期刊
-
专业网络和社区:
- 取证社区和论坛参与
- 专业协会成员资格
- 导师和同行关系
- 跨学科网络和合作
-
实践经验提升:
- 挑战性案例和新技术实践
- 模拟环境和CTF活动
- 知识共享和内部培训
- 研究项目和发表
-
职业发展路径:
- 初级取证分析师 → 高级取证专家
- 专注特定领域(如移动、网络、内存取证)
- 向管理、顾问或专家证人方向发展
- 学术和研究职业路径
持续教育的最佳实践:
- 制定个人发展计划,包括短期和长期目标
- 平衡技术、法律和沟通技能发展
- 保持对新兴技术和威胁的警觉
- 定期评估和更新技能组合
- 贡献社区,分享知识和经验
18.3 推荐学习资源
为数字取证专业人员和学习者提供的精选资源:
-
书籍和学术资源:
- 入门书籍:
- “Digital Forensics Basics” by André Årnes
- “Guide to Computer Forensics and Investigations” by Bill Nelson
- “Digital Forensics with Open Source Tools” by Cory Altheide & Harlan Carvey
- 高级参考:
- “File System Forensic Analysis” by Brian Carrier
- “Windows Forensic Analysis” by Harlan Carvey
- “The Art of Memory Forensics” by Michael Hale Ligh
- “Practical Malware Analysis” by Michael Sikorski & Andrew Honig
- 入门书籍:
-
学术期刊和出版物:
- Digital Investigation Journal
- International Journal of Digital Forensics & Incident Response
- Journal of Digital Forensics, Security and Law
- IEEE Security & Privacy
- ForensicFocus.com文章和评论
-
在线训练和学习平台:
- SANS Digital Forensics Courses
- Pluralsight Security Courses
- Cybrary Digital Forensics Training
- Linux Academy & A Cloud Guru
- edX and Coursera Forensics Courses
-
社区和论坛:
- ForensicFocus Forums
- SANS DFIR Forum
- Reddit’s r/computerforensics
- StackExchange Information Security
- GitHub取证社区和项目
-
练习和实验室环境:
- Digital Corpora样本数据集
- CFReDS (Computer Forensic Reference Data Sets)
- DFRWS Forensic Challenges
- CyberDefenders Blue Team Challenges
- Volatility Memory Samples
-
播客和视频资源:
- SANS DFIR Webcasts
- Digital Forensics Stream
- Forensic Lunch
- Brakeing Down Security
- 13Cubed YouTube Channel
-
会议和专业活动:
- SANS DFIR Summit
- DFRWS (Digital Forensic Research Workshop)
- BlackHat and DEF CON Forensics Tracks
- Open Source Digital Forensics Conference
- 区域DFIR社区会议
-
工具文档和教程:
- Sleuth Kit & Autopsy Wiki
- Volatility Documentation
- SANS Cheat Sheets & Posters
- NIST Digital Forensics Publications
- GiHub取证工具文档和示例
这些资源涵盖从基础到高级的各个层面,为取证专业人员提供全面的学习和参考材料。资源选择应基于个人学习目标、当前知识水平和专业发展方向。
18.4 总结与展望
数字取证是一门不断发展的学科,结合了技术、法律和调查技能。作为这一动态领域的专业人员,需要保持核心原则,同时适应不断变化的技术环境。
数字取证的核心价值和持久原则:
- 科学方法和客观性
- 证据完整性和可靠性
- 透明的流程和可重复结果
- 道德实践和专业行为
- 持续学习和技能发展
随着技术的演进,取证专业人员将面临新的挑战和机遇。云计算、物联网、人工智能和量子技术等趋势将改变取证实践的面貌,但基本原则仍将指导调查方法。
成功的数字取证专业人员需要:
- 扎实的技术基础与专业知识
- 跨学科思维和终身学习态度
- 对复杂数据和情境的分析能力
- 清晰的沟通和证词技能
- 严格的道德标准和客观性
通过适当的工具、方法和不断发展的技能,数字取证人员可以应对不断变化的数字环境,为刑事调查、民事诉讼和企业安全提供宝贵的支持。
数字取证的未来将由技术创新、法律发展和社会需求共同塑造,但其核心使命保持不变:以科学和客观的方式揭示数字证据的真相。






![[ctfshow web入门] web122](https://i-blog.csdnimg.cn/direct/b8e1165dd3634767b3037ab66f777443.png)