BERT
什么是BERT?
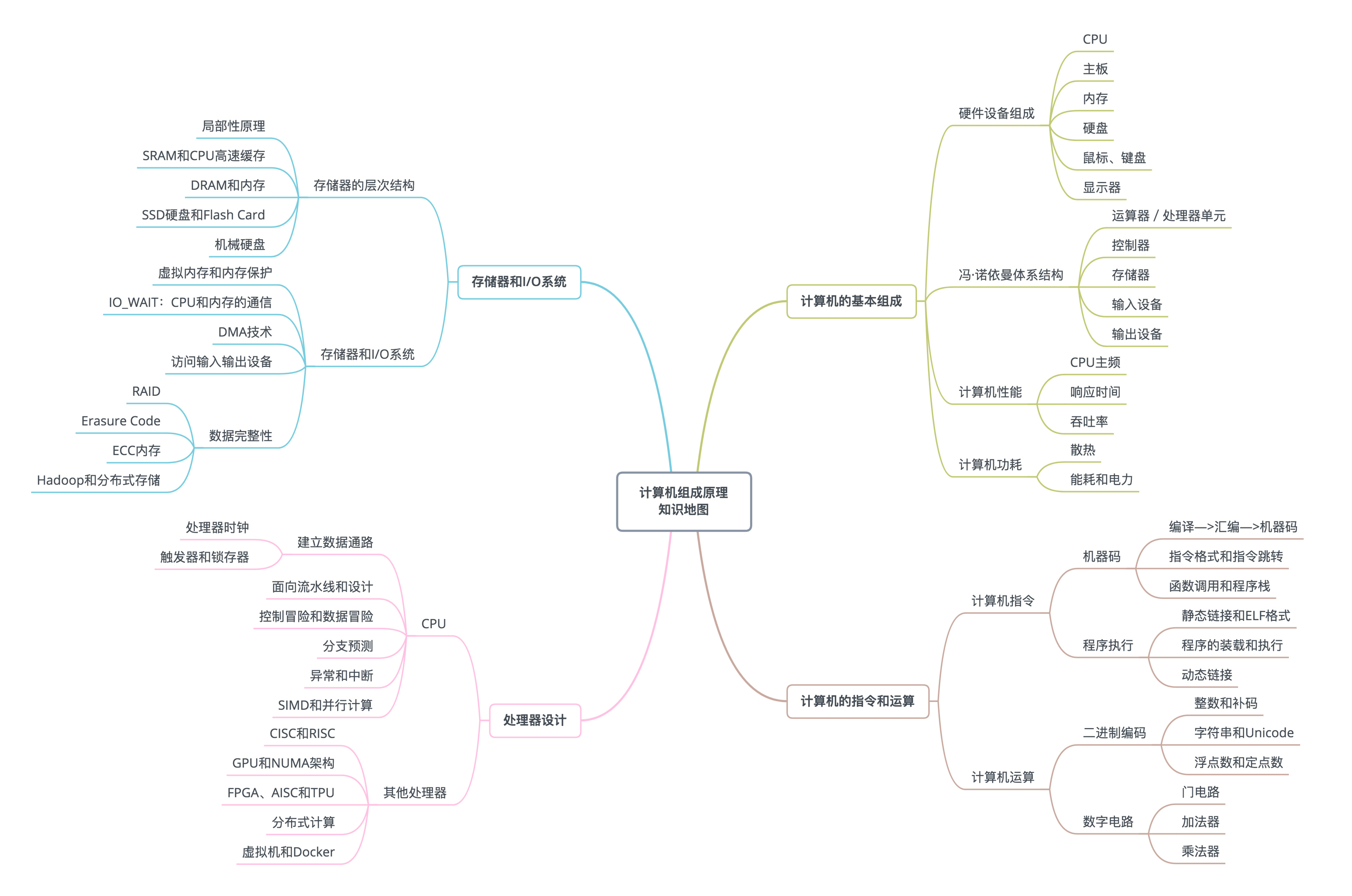
BERT,全称Bidirectional Encoder Representations from Transformers,BERT是基于Transformer的Encoder(编码器)结构得来的,因此核心与Transformer一致,都是注意力机制。这种机制使得模型能够捕捉到句子中词语之间远距离的依赖关系,这是传统RNN/LSTM难以高效实现的能力。
BERT中的B —— Bidirectional
在自然语言中,一个词语的真正含义往往不是孤立存在的,它深深植根于其所处的上下文。更重要的是,这个上下文不仅包括它左边的词(前文),还包括它右边的词(后文)。
传统的语言模型,在BERT之前,要么是单向的(例如GPT-1,它只能自左向右地预测下一个词),要么是浅层双向的(例如ELMo,它通过训练两个独立的单向LSTM——一个从左到右,一个从右到左——然后将它们的表示拼接起来)。这两种方式都存在局限性:
- 单向模型: 当模型在处理一个词时,它无法“看到”这个词之后的信息。这意味着,如果一个词的真实含义需要依赖它后面的词语来 disambiguate(消除歧义),单向模型就会束手无策。这就像你看书,却被要求只能看到当前页的左边部分,无法预知右边即将出现的内容。
eg:
1.“他把钱存进了bank的账户里。”
2. “这条小船停靠在河边的bank。”
在这两个句子中,“bank”这个词是多义词,它既可以指“金融机构”(bank),也可以指“河流的岸边”(river bank)。如果模型只能从左到右看,那么对于第一句,到bank前,模型看到的是:“他把钱存进了...”,基于这些信息,模型可能会猜测“bank”指的是一个金融机构。这似乎是正确的。但对于第二句,到bank前,模型看到的是:“这条小船停靠在河边的...”,仅仅依靠“河边”这个词,模型可能会倾向于猜测“bank”指的是河岸,这在这个语境下也是正确的。但会存在一个问题,你基于bank的理解都只是基于上文,对于第一个句子,“他把钱存进了...”,你下一个词也可以是"保险柜","储钱罐"等等,为什么一定是“银行”呢,因此如果,你如果知道右边的信息“账户”这个下文,你就可以更加明确这里预测的更可能是"bank",而不是“保险柜”等。对于第二个句子,你又怎么知道这里指的是"河岸"而不是"银行"呢?,万一句子想要表达的意思是"船夫将船停靠在河边的bank,并进去取钱",在缺乏下文"取钱"这个含义下,你这时候还能说"bank"是表达岸边的意思吗?因此,基于单向模型的文本编码无法有效照顾到上下文,它对于信息的获取都是基于局部已有信息,具有狭隘性。
- 浅层双向模型: 拼接式的双向虽然看似考虑了两边,但通常是两个独立的单向模型分别编码,然后简单合并。它们在深度上,并没有真正实现左右上下文的深度交互和融合,导致对复杂语境的理解能力不足。如ELMo,其工作原理为:1.分别训练一个从左到右 (L-R) 的LSTM:它处理输入序列并学习每个词基于其左侧上下文的表示。一个从右到左 (R-L) 的LSTM:它处理反向的输入序列(或者说,它学习每个词基于其右侧上下文的表示)。2.对于序列中的每个词,ELMo会将这两个独立的LSTM生成的隐藏状态(向量表示)进行拼接 (concatenation) 或者加权平均,从而得到该词的最终表示。
这就像是分别安排两个人读同一文本段落,让其中一个从左到右读,另外一个从右到左读,然后将两个人的内容进行交换从而获得对于这一文本段落的理解。但这种方式不如一个人直接从左到右和从右到左分别读一遍,这样跟两个人以不同方式读相比,歧义会少。而BERT就是基于这个思想出发来进行设计。
eg:
"他计划周五去bank开户,尽管那时河边bank可能已经关门。"
针对第一个bank,从左到右的LSTM在处理第一个“bank”时: 它能看到“他计划周五去”。基于这些信息,它可能会给出一个通用的表示,因为它完全不知道后面有“开户”这个强烈的提示词。从右到左的LSTM在处理第一个“bank”时, 它能看到“开户,尽管那时...”。这个模型能捕捉到“开户”与“银行”的关联,从而给出指向“金融机构”的表示。最终表示: 这两个独立计算出来的表示(一个只看到左边,一个只看到右边)被拼接起来。
浅层双向的局限性体现在,从左到右的LSTM在处理到“bank”时,它无法在其内部计算过程中,根据“开户”这个后续信息来实时调整和精炼它对“bank”的理解。它只能依赖它当时已知的左侧上下文。虽然最终会拼接右侧信息,但这种融合是事后的,而非过程中的深度交互。如果从左向右针对该词给出的通用表示与bank歧义比较大,从右向左针对该词给的表示可以表示“金融机构”,但你能确保这两个拼接起来,针对该词最终的表示可以表示为“金融机构”吗?
BERT所追求的“双向性”,是深层次的、同时利用左右上下文的理解。 这意味着,在模型理解和表示一个词语时,它能够同时“看到”这个词语在句子中的所有前文和所有后文,从而获取一个真正完整的语境信息。
BERT的预训练
BERT在海量无标签文本数据上进行无监督(unsupervised learning)预训练来学习语言的通用表示。这个过程类似于人类通过大量阅读来积累语感和知识。BERT的预训练主要依赖于两个创新任务:
-
掩码语言模型 (Masked Language Model, MLM)
MASK IS ALL YOU NEED,这是BERT实现深度双向性的基石。
- 操作方式: 在输入文本中,BERT会随机选择15%的词语进行“遮蔽”(即替换成一个特殊的
[MASK]标记)。 - 训练目标: 模型的任务就是预测这些被遮蔽(MASK)的词语是什么。
- 巧妙之处: 为了防止模型简单地“记住”被遮蔽的位置(记答案),这15%的词语有以下处理方式:
- 80%的概率:被替换为
[MASK]标记。(基于上下文预测该MASK对应的词语——填空题) - 10%的概率:被替换为词汇表中的任意一个其他随机词语。这强迫模型不仅要预测被遮蔽的词,还要分辨出替换的词是否合理,增加了学习的难度和深度。(基于上下文来判断该MASK的词语使用是否正确——判断题)
- 10%的概率:保持不变。这进一步迫使模型不仅仅依赖
[MASK]标记来识别被预测的词,而是从完整的上下文信息中进行推断。(举一反三,而不是只会做题)。在这10%的情况下,模型需要预测的那个词并没有被替换成[MASK]。它依然以其原始形式存在于句子中。但模型的目标仍然是预测它!这意味着模型不能仅仅依赖[MASK]标记来知道“这里需要预测”。它必须通过分析整个句子中所有其他词语的完整上下文来推断出这个词本来应该是什么,即使这个词就在那里,也好像它被“隐藏”了一样。
补充:设想一下,如果BERT总是把要预测的词替换成特殊的 [MASK] 标记(比如100%的概率),那么模型很快就会学会一个简单的规则:只要看到 [MASK],我就要预测一个词。这样做会带来一个问题:过度依赖 [MASK] 标记: 模型可能会过于依赖 [MASK] 这个显式信号来知道“这里需要预测一个词”。它可能不会真正深入地学习如何仅凭周围的完整上下文信息来推断一个词。换句话说,它可能在某种程度上“偷懒”,而不是真正理解语言的深层模式。
下一句预测 (Next Sentence Prediction, NSP)
BERT的另一个预训练任务是理解句子之间的关系。
BERT的输入可以是输入两个句子 ( [CLS], 句子1, [SEP], 句子2, [SEP] ) , [SEP]的token标记用于分割句子。
- 操作方式: 模型会输入两个句子(Segment A 和 Segment B)。
- 训练目标: 预测 Segment B 是否真的是 Segment A 的下一句。
- 数据构造: 在训练数据中,50%的样本是真实的下一句对,另外50%是随机从语料库中抽取的句子对。
NSP任务让BERT学会了理解文本的连贯性和篇章结构,这对于问答、文本蕴含、自然语言推理等需要判断句子间逻辑关系的任务非常重要。
BERT的输入表示
它通过特殊的方式对输入进行编码:
- 分词(Tokenization): 通常使用WordPiece分词器,将词语拆分为更小的子词单元。token 不恒为 word,这一点需清楚,对于短单词,才可能 token == word。
- 特殊标记:
[CLS](Classification) 标记:每个输入序列的开头都会加上这个特殊标记。它对应的最终隐藏状态(向量)被用作整个序列的聚合表示,常用于分类任务。[SEP](Separator) 标记:用于分隔两个句子(如A和B),并在单个句子输入的末尾。
- 词元嵌入(Token Embeddings):最基础的嵌入,代表了文本序列中的每个词元(token)本身的语义信息。
- 段落嵌入(Segment Embeddings): 用于区分序列中的不同句子(例如,A句的所有token都有一个
A的段落嵌入,B句有B的段落嵌入),帮助模型理解句子边界。基于SEP标记来确定Segment Embeddings的值,如只有一个[SEP]标记的话,[SEP]标记前的Segment Embeddings的值为0,如果有两个[SEP],那么第二个[SEP]和第一个[SEP]之间的句子的Segment Embeddings的值为1。类似于数组的下标索引,现在数组中每个元素的值变成了一个句子而已。 - 位置嵌入(Position Embeddings): 由于Transformer的自注意力机制是并行处理的,不包含序列顺序信息,因此需要位置嵌入来告知模型每个词在序列中的位置。如:如果没有额外的信息,模型无法区分“猫追狗”和“狗追猫”这样的序列。原版的Transformer是使用固定、周期性的正弦/余弦函数生成位置编码不同,BERT采用的是可学习的(Learned)位置嵌入。BERT在预训练过程中,会为每个可能的序列位置学习一个唯一的、随机初始化的向量。这些位置嵌入向量像词元嵌入一样,被存储在一个查找表(lookup table)中,模型在训练过程中会根据任务和数据特点来优化这些向量。即词与词之间的先后顺序是模型在大量数据预训练过程中自己学习到了,并存储为一个tabel,你后续获得对应token的时候,将其放到table中进行查找就能知道这个token应该是在句子的哪些位置。
这三类嵌入(Token Embeddings + Position Embeddings + Position Embeddings)相加,形成了BERT模型的最终输入Embedding,随后就是Encoding部分。
RoBERTa
RoBERTa全称Robustly Optimized BERT Pretraining Approach,其是基于BERT的优化,模型架构仍然是Transformer, 只是对BERT的预训练方法进行了系统性优化,以提高模型的性能和鲁棒性。
与BERT相比,主要区别在于:
- 更大的数据量、更长的训练时间、更大的批次大小。RoBERTa使用了160GB的训练数据,远超BERT所使用的16GB的训练数据。数据量的大小所带来的模型性能提升。
- 移除下一句预测任务(NSP),专注于单个句子中MLM任务的分析。RoBERTa 团队经实验发现,NSP 任务收益有限,甚至干扰模型对句内语义捕捉。RoBERTa 果断移除 NSP,仅靠 MLM 任务预训练。实践表明,精简任务结构后,模型聚焦句内信息,语义表征更精准。
- 采用动态掩码。在BERT中, 采用的是静态掩码(Static Masking)。在数据预处理阶段,会预先对训练数据进行一次词语遮蔽,并生成固定好的掩码模式。这意味着在整个多轮(epochs)训练中,同一个句子总是以相同的掩码模式出现。RoBERTa 采用动态掩码(Dynamic Masking)。在每个训练批次(batch)送入模型之前,都会动态地生成新的掩码模式。这意味着同一个句子在不同的训练步中,可能会有不同的词语被遮蔽。
eg:
对于句子:"我 喜欢 学习 自然语言处理。"
对于BERT(静态掩码):
- 在整个训练过程中(比如训练了10个epoch),这个句子可能总是被遮蔽成: "我 喜欢
[MASK]自然语言处理。" (模型预测 "学习")
对于RoBERTa(动态掩码):
- Epoch 1: "我 喜欢
[MASK]自然语言处理。" - Epoch 2: "我 喜欢 学习
[MASK]语言处理。" - Epoch 3: "我
[MASK]学习 自然语言处理。" - ...每次训练,模型都需要重新从不同角度理解上下文来预测被遮蔽的词。
BERTweet
BERTweet,顾名思义,其实基于Tweet数据+BERT结构预训练所得出的模型。与BERT和RoBERTa相比,可以用一句话进行表述,BERTweet是基于RoBERTa的预训练范式,但在数据、分词和预处理上进行了Twitter领域特有的适配,即RoBERTa预训练范式 + 针对推文的数据预训练。
BERTweet充分体现了领域适应性,通过在Twitter数据上的大规模预训练,并结合专门的分词和预处理策略,使其能够更精准地捕捉推文的语言特征,从而在情感分析、情绪识别、话题分类等Twitter相关的NLP任务上,显著超越了未经领域适配的BERT和RoBERTa模型。
LLama
LLama,全称 Large Language Model Meta AI,在西班牙语中意为“羊驼”,因此LLama又被称之为羊驼。
LLama的初衷是认为最佳性能不是通过堆模型参数量实现的,而是通过在更多数据上训练的较小模型实现的。
补充说明:一般而言,模型越大,效果越好。然而有文献指出,当给定计算量的预算之后,最好的performance,并不是最大的模型,而是在一个小模型上用更多的数据进行训练。针对给定的计算量预算,scaling laws可以计算如何选择数据量的大小和模型的大小。然而这忽略了inference的预算,而这一点在模型推理时非常关键。当给定一个模型performance目标之后,最好的模型不是训练最快的模型,而是推理最快的模型。尽管在这种情况下,训练一个更大的模型成本会更低。
文献中推荐,训练一个 10B 的模型,需要 200B 的 tokens,而本文的实验发现,一个7B的模型,经过 1T tokens 训练之后,performance 仍然在增加。本文的目标在于,通过在超大规模的数据上训练,给出一系列可能最好 performance 的 LLM。
LLama是一个大规模的生成式语言模型,其模型结构与GPT等生成模型类似,也是基于Transformer-decoder-only的架构进行部分模块的优化。
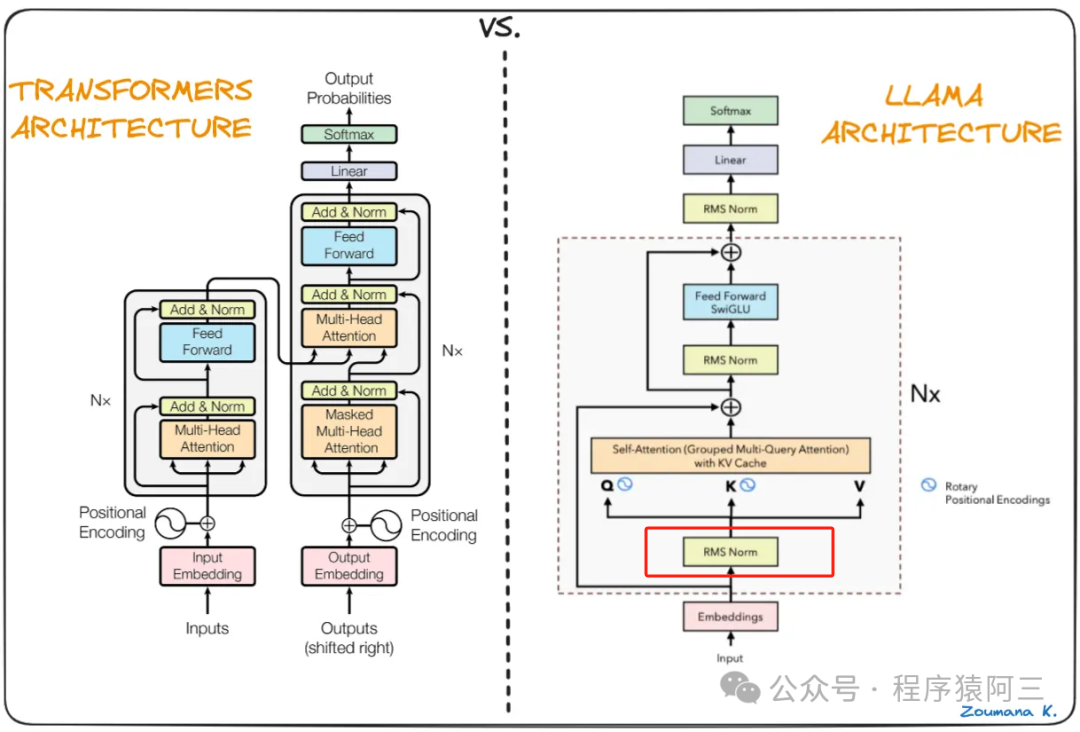
有以下三个改进:
- 使用了GPT3的预标准化。为了提高训练稳定性,对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。使用由RMSNorm 归一化函数。
-
用 SwiGLU 激活函数替换 ReLU 非线性,以提高性能。使用
的维度替代PaLM中的
-
类似GPTNeo,删除了绝对位置嵌入,而是添加了旋转位置嵌入(RoPE)。
针对第一点,在进行注意力机制的计算前,即在进入Transformer子层前对Embedding进行了归一化。并且归一化函数从LayerNorm改为使用RMSNorm。
RMSNorm是LayerNorm的变体,LayerNorm是通过调整当前层输入的均值和方差来解决内部协变量偏移问题,防止梯度消失或爆炸,并使训练对学习率和初始化更加鲁棒。RMSNorm,全称 Root Mean Square Layer Normalization (均方根层归一化),与LayerNorm相比,RMSNorm移除了均值计算,只关注通过均方根(RMS)进行重新缩放。
RMS的公式为
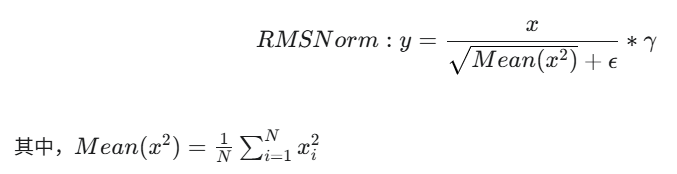
是输入向量,
是输入向量中的第
个元素。
输入向量的维度(即特征的数量)。
表示输入向量的均方差
代表可学习的缩放(gain)参数
是一个很小的参数,一般设为10^-5,主要作用是为了计算稳定。
RMSNorm与LayerNorm相比,没了偏置项和移除了均值。
针对第二点,