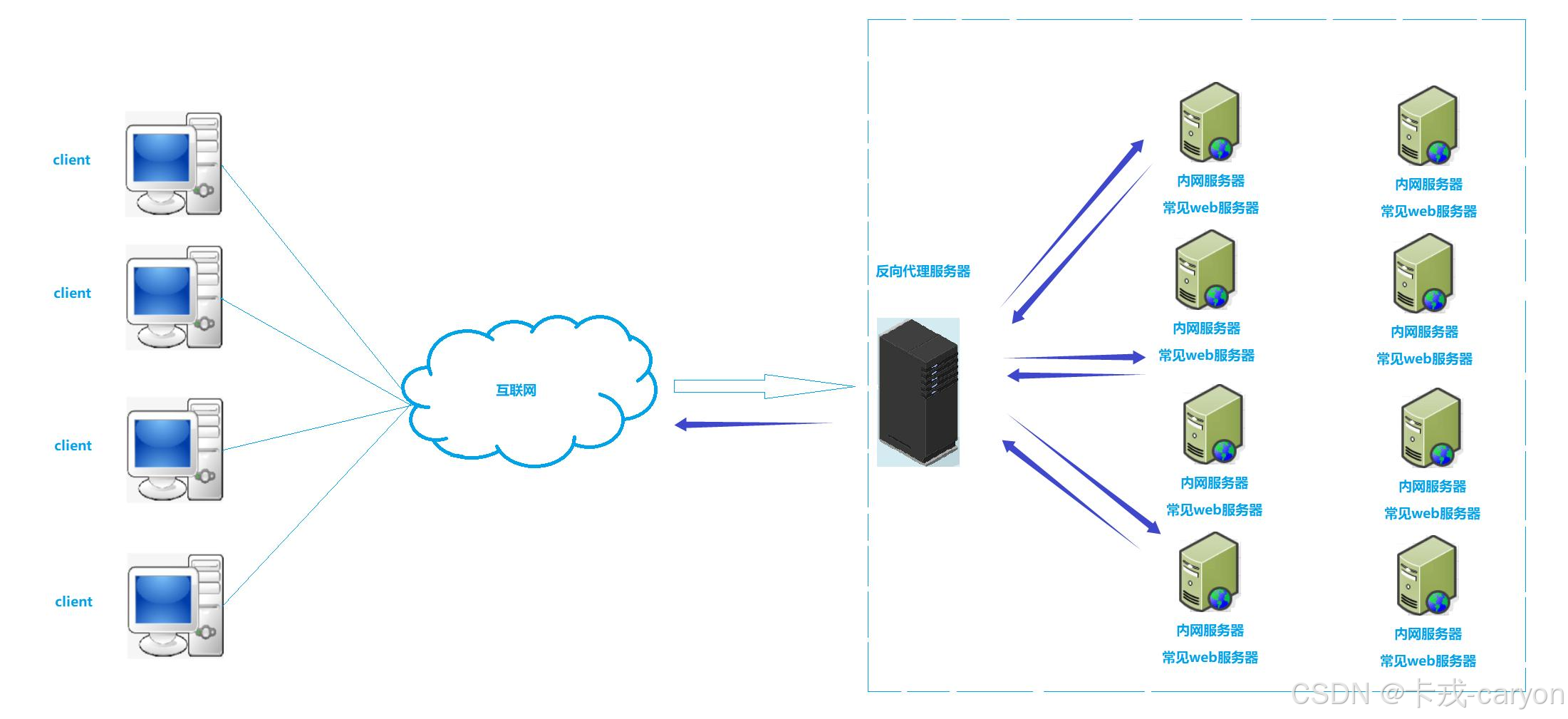
大数据技术全景解析:HDFS、HBase、MapReduce 与 Chukwa
在当今这个信息爆炸的时代,大数据已经成为企业竞争力的重要组成部分。从电商的用户行为分析到金融的风险控制,从医疗健康的数据挖掘到智能制造的实时监控,大数据技术无处不在。然而,面对PB级甚至EB级的数据规模,传统的计算和存储方式已无法胜任。于是,以 Hadoop 生态系统 为代表的大数据技术应运而生。
本文将带你走进大数据的世界,重点介绍其中的四大关键技术:HDFS(分布式文件系统)、HBase(分布式数据库)、MapReduce(分布式计算框架) 和 Chukwa(数据收集与监控工具),帮助你理解它们各自的定位、原理以及如何协同工作,构建一个完整的大数据生态系统。
一、HDFS:海量数据的基石 —— 分布式文件系统
1.1 什么是 HDFS?
HDFS(Hadoop Distributed File System) 是 Hadoop 的核心组件之一,是一个分布式文件系统,专为大规模数据存储设计。它能够将 PB 级别的数据分布在成百上千台服务器上,并提供高吞吐量的访问能力。
1.2 HDFS 的特点
- 高容错性:通过数据副本机制(默认3份),即使部分节点宕机也不会丢失数据。
- 高吞吐量:适合一次写入、多次读取的场景(如日志处理)。
- 适用于大文件:不适合处理大量小文件,但非常适合处理几百MB到GB级别的大文件。
- 廉价硬件支持:可以在普通的商用服务器上运行,降低成本。
1.3 HDFS 架构
HDFS 采用经典的 主从架构(Master/Slave):
- NameNode:主节点,负责管理文件系统的元数据(如目录结构、文件块的位置等)。
- DataNode:从节点,负责实际存储数据块,并定期向 NameNode 汇报状态。
- Secondary NameNode:辅助 NameNode 定期合并元数据日志,防止日志过大。
类比理解:你可以把 HDFS 看作是一个“云盘”,只不过这个云盘是自己搭建的,而且专门用来存放大文件。
二、HBase:实时查询的利器 —— 分布式 NoSQL 数据库
2.1 什么是 HBase?
HBase 是基于 HDFS 构建的分布式、可扩展、面向列的 NoSQL 数据库,它提供了对大数据集的低延迟随机读写访问能力,适用于需要实时查询的场景。
2.2 HBase 的特点
- 强一致性:支持 ACID 特性(在某些模式下)。
- 横向扩展性强:可以轻松扩展到数百个节点。
- 适合稀疏数据:每个行可能有不同的列,节省存储空间。
- 低延迟访问:相比 MapReduce,HBase 支持毫秒级响应。
2.3 HBase 架构
- HMaster:负责管理表和 RegionServer 的分配。
- RegionServer:负责管理一定范围的表数据(Region),并处理客户端请求。
- ZooKeeper:协调服务,用于维护集群状态、选举 Master 等。
类比理解:如果 HDFS 是硬盘,那么 HBase 就像一个“快速查找的数据库索引”,让你能快速查到某个具体记录。
三、MapReduce:离线计算的引擎 —— 分布式批处理框架
3.1 什么是 MapReduce?
MapReduce 是 Hadoop 提供的一种分布式批处理计算框架,由 Google 首创思想,Hadoop 实现。它允许开发者用简单的接口编写复杂的分布式程序,适用于海量数据的离线处理任务。
3.2 MapReduce 的工作流程
MapReduce 的核心思想是“分而治之”:
- Map 阶段:将输入数据切分为多个片段,每个片段独立进行处理,输出中间键值对。
- Shuffle 阶段:系统自动将相同 key 的 value 聚合在一起。
- Reduce 阶段:对聚合后的 key-value 进行最终处理,生成结果。
示例:统计一份巨大的日志文件中各个单词出现的次数。
3.3 MapReduce 的优缺点
-
✅ 优点:
- 易于扩展
- 高容错性(失败任务会重新执行)
- 可以处理非结构化数据
-
❌ 缺点:
- 延迟较高(适合离线处理)
- 不适合实时交互式查询
- 开发调试复杂度高(相较 Spark)
类比理解:MapReduce 就像是一个工厂流水线,把大任务拆解成小任务并发执行,最后汇总结果。
四、Chukwa:数据采集与监控的得力助手
4.1 什么是 Chukwa?
Chukwa 是 Apache Hadoop 项目下的一个子项目,是一个开源的数据收集与监控系统,专门用于从大型分布式系统中采集、存储和分析数据。
4.2 Chukwa 的主要功能
- 日志收集:从各种来源(如 Hadoop 集群、Web 服务器、应用日志)收集数据。
- 数据存储:将收集到的数据写入 HDFS 或其他存储系统。
- 可视化展示:通过内置的 Web UI 提供基本的数据分析和图表展示。
- 报警机制:当检测到异常指标时,可以触发报警通知。
4.3 Chukwa 架构组成
- Agent:部署在每台机器上的数据采集器,负责监听日志变化并发送数据。
- Collector:接收 Agent 发送的数据,并进行初步处理。
- Demux/Mapper:对数据进行分类、清洗、转换。
- HDFS 存储:最终数据落盘到 HDFS 中。
- HICC(Web UI):提供可视化界面,展示监控指标。
类比理解:Chukwa 就像是一个“数据中心的保安系统”,时刻监控着整个集群的状态,一旦有异常就发出警报。
五、四者之间的关系与协作
| 组件 | 角色 | 功能 |
|---|---|---|
| HDFS | 存储层 | 存放原始数据和计算结果 |
| HBase | 查询层 | 提供实时查询与更新能力 |
| MapReduce | 计算层 | 执行批量数据处理任务 |
| Chukwa | 监控层 | 收集日志、监控集群状态 |
这四个组件共同构成了一个完整的 Hadoop 生态系统:
- HDFS 是基础,所有数据都存储在其上;
- HBase 在其之上构建了实时查询能力;
- MapReduce 则负责对这些数据进行深度处理;
- Chukwa 负责整个生态系统的日志采集与监控,保障系统稳定运行。
六、总结:大数据世界的拼图
在大数据的世界里,没有哪个单一的技术能解决所有问题。我们需要根据业务需求选择合适的工具组合:
- 如果你需要存储海量数据,那就使用 HDFS;
- 如果你需要实时查询和更新,那就使用 HBase;
- 如果你需要处理历史数据或批量任务,那就使用 MapReduce;
- 如果你需要监控和分析集群状态,那就使用 Chukwa。
当然,随着技术的发展,像 Spark、Flink、Kafka、Hive 等新兴工具也在不断丰富着大数据生态。但理解 Hadoop 的核心组件仍然是进入大数据领域的第一步。
结语
大数据不是一项技术,而是一整套解决方案。掌握 HDFS、HBase、MapReduce 和 Chukwa,不仅能让你更好地理解大数据的本质,也能为你后续深入学习 Spark、Flink 等现代大数据框架打下坚实的基础。
在这个数据驱动的时代,谁掌握了数据,谁就掌握了未来。希望这篇文章能成为你探索大数据世界的第一步!







![[STM32] 5-1 时钟树(上)](https://i-blog.csdnimg.cn/direct/015d9c0309f14b32a3a7516efcbcc00d.png)