📦 一、整体功能定位
这是一个用于从原始视频自动生成短视频解说内容的自动化工具,包含:
-
视频抽帧(可基于画面变化提取关键帧)
-
多模态图像识别(每帧图片理解)
-
文案生成(大模型生成口语化解说)
-
TTS语音合成(将文案变为解说音频)
-
视频合成(图片 + 音频 or 原视频音频)
-
日志记录 + 文案保存
适合用于内容创作、短视频自动剪辑辅助、图文转视频等场景。
🧱 二、代码架构总览
project/
├── main.py # 主流程逻辑入口
├── config.ini # 配置文件(模型URL、key等)
├── doubaoTTS.py # 语音合成模块(豆包接口)
├── output/ # 输出目录(帧图、文案、音频、视频)
│ ├── frames/
│ ├── narration.mp3
│ ├── frame_descriptions.txt
│ ├── narration_script.txt
│ └── final_output_with_original_audio.mp4
⚙️ 三、主要模块说明
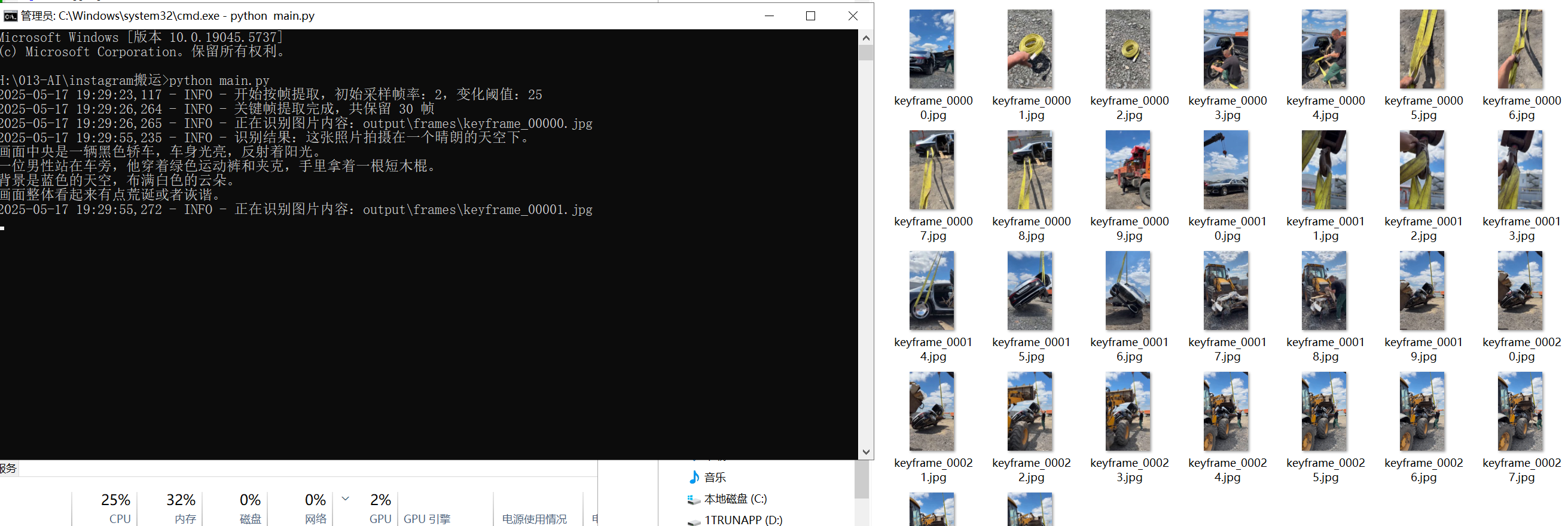
1. extract_keyframes_by_diff() – 拆帧模块(图像变化判断)
-
从视频中按设定帧率提取帧
-
对比相邻帧内容,过滤重复或近似帧
-
降低识图调用频率,提高信息效率
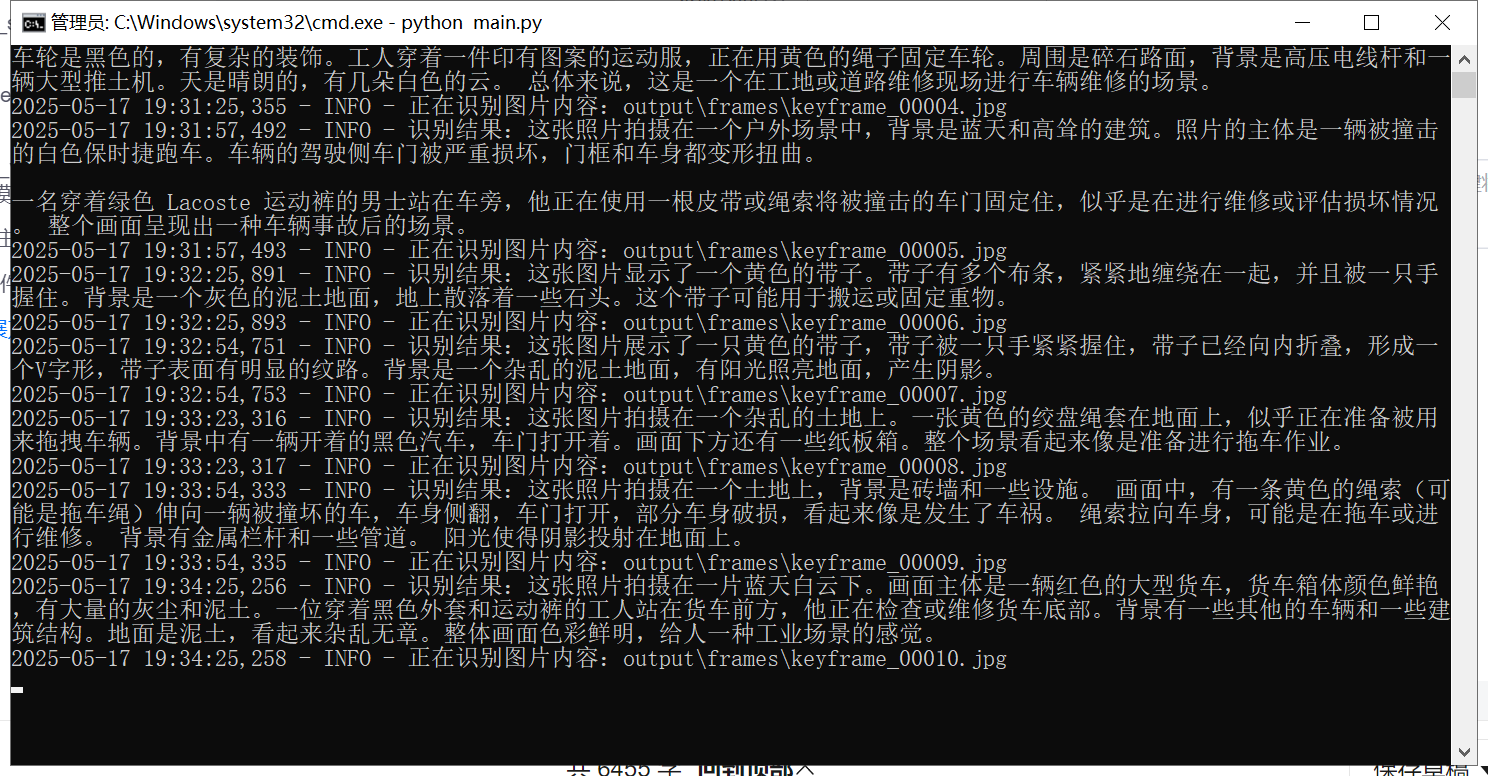
2. describe_image() – 图像识别模块
-
使用
OLLAMA的多模态模型(如gemma3:4b) -
将每帧图像转 base64,提交模型识别
-
输出自然语言描述(中文)
3. generate_script() – 文案生成模块
-
使用
OpenRouter接口,调用如deepseek模型 -
以所有帧描述为输入,生成整体解说词
-
提示词优化为:短视频风格 + 口语化 + 幽默
4. synthesize_audio() – 音频合成模块
-
调用
doubaoTTS实现 TTS 中文语音合成 -
输出
.mp3格式音频文件
5. compose_video_with_audio() – 视频合成模块
-
将图像序列按顺序合成为视频
-
配上:
-
合成解说音频,或
-
原视频音频(当前采用)
-
6. main() – 主流程协调函数
执行顺序如下:
原始视频
↓
图像抽帧(基于变化)
↓
每帧图像识别 → 收集所有描述
↓
文案生成(整体解说)
↓
保存描述 + 文案
↓
语音合成
↓
合成视频( 原视频+音频)
🛠 四、配置文件说明(config.ini)
[ollama]
url = http://localhost:11434/api/generate
model = gemma3:4b
[openrouter]
url = https://openrouter.ai/api/v1/chat/completions
api_key = sk-xxx
model = deepseek-chat
🔁 五、可扩展方向建议
| 功能 | 实现思路 |
|---|---|
| 加字幕 | 用 MoviePy 在视频帧上叠加文案 |
| 多语言支持 | 替换 TTS 模型或调用多语种 GPT 模型 |
| 语音识别 | 加入 whisper 抽取原视频语音作为额外提示输入 |
| 图像字幕识别 | 加 OCR 模块识别画面内字幕,辅助理解 |
| 批量处理视频 | 使用 CLI 参数或脚本批量遍历目录 |
| Web 界面化 | 用 Gradio / Streamlit 构建可视化上传和预览界面 |
直接上代码:
import os
import requests
import json
import base64
import logging
from PIL import Image
from moviepy.editor import VideoFileClip, ImageSequenceClip, AudioFileClip
import doubaoTTS
import configparser
from PIL import Image, ImageChops
import numpy as np
# 设置日志
logging.basicConfig(level=logging.INFO, format='[%(levelname)s] %(message)s')
# 从 config.ini 加载配置
config = configparser.ConfigParser()
config.read("config.ini", encoding="utf-8")
OLLAMA_URL = config.get("ollama", "url")
OLLAMA_MODEL = config.get("ollama", "model")
OPENROUTER_URL = config.get("openrouter", "url")
OPENROUTER_API_KEY = config.get("openrouter", "api_key")
OPENROUTER_MODEL = config.get("openrouter", "model")
# 拆帧函数
def extract_keyframes_by_diff(video_path, output_dir, diff_threshold=30, fps=2, max_frames=None):
"""
从视频中提取关键帧(基于图像变化)
参数:
video_path: 视频文件路径
output_dir: 输出帧目录
diff_threshold: 像素差阈值,越小越敏感
fps: 初始扫描帧率(例如2即每秒取2帧,再做变化判断)
max_frames: 最大输出帧数,默认不限制
"""
os.makedirs(output_dir, exist_ok=True)
clip = VideoFileClip(video_path)
last_frame = None
count = 0
logging.info(f"开始按帧提取,初始采样帧率:{fps},变化阈值:{diff_threshold}")
for i, frame in enumerate(clip.iter_frames(fps=fps)):
if max_frames and count >= max_frames:
break
img = Image.fromarray(frame)
if last_frame:
# 灰度差异
diff = ImageChops.difference(img.convert('L'), last_frame.convert('L'))
diff_score = np.mean(np.array(diff))
if diff_score < diff_threshold:
continue # 差异太小,跳过当前帧
# 保存关键帧
frame_path = os.path.join(output_dir, f"keyframe_{count:05d}.jpg")
img.save(frame_path)
last_frame = img
count += 1
logging.info(f"关键帧提取完成,共保留 {count} 帧")
return sorted([os.path.join(output_dir, f) for f in os.listdir(output_dir) if f.endswith(".jpg")])
# 用 gemma3:4b 多模态识图
def describe_image(img_path):
logging.info(f"正在识别图片内容:{img_path}")
with open(img_path, "rb") as f:
image_bytes = f.read()
image_b64 = base64.b64encode(image_bytes).decode("utf-8")
#logging.info(image_b64)
payload = {
"model": OLLAMA_MODEL,
"messages": [
{
"role": "user",
"content": "请用中文描述这张图片的内容,不要输出markdown格式",
"images": [image_b64]
}
],
"stream": False
}
response = requests.post(OLLAMA_URL, json=payload)
#logging.info(response.json())
result = response.json().get('message', {}).get('content', '').strip()
logging.info(f"识别结果:{result}")
return result
# 用 deepseek 生成中文文案(带完整验证与日志)
def generate_script(prompt):
logging.info("正在生成视频文案")
try:
response = requests.post(
OPENROUTER_URL,
headers={
"Authorization": f"Bearer {OPENROUTER_API_KEY}",
"Content-Type": "application/json"
},
json={
"model": OPENROUTER_MODEL,
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
)
response.raise_for_status()
data = response.json()
if "choices" in data and data["choices"]:
result = data["choices"][0]["message"]["content"]
logging.info(f"记录生成的文案内容:{result}")
return result
logging.error("API 响应中没有 choices 字段: %s", data)
return "生成失败,API 响应格式异常。"
except requests.RequestException as e:
logging.error("API 请求失败: %s", e)
return "生成失败,请检查网络或服务状态。"
# 合成音频
def synthesize_audio(text, output_path):
logging.info("正在合成解说音频")
doubaoTTS.tts_doubao(text, output_path)
logging.info(f"音频保存到:{output_path}")
# 合成视频
def compose_video_with_audio(frame_dir, audio_path, output_path, fps=1):
logging.info("正在合成最终视频")
frame_paths = sorted([os.path.join(frame_dir, f) for f in os.listdir(frame_dir) if f.endswith(".jpg")])
clip = ImageSequenceClip(frame_paths, fps=fps)
audio = AudioFileClip(audio_path)
video = clip.set_audio(audio)
video.write_videofile(output_path, codec='libx264', audio_codec='aac')
logging.info(f"视频生成成功:{output_path}")
def main(video_path, work_dir, fps=1):
frame_dir = os.path.join(work_dir, "frames")
os.makedirs(frame_dir, exist_ok=True)
# 1. 拆帧
frame_dir = os.path.join(work_dir, "frames")
extract_keyframes_by_diff(video_path, frame_dir, diff_threshold=25, fps=2, max_frames=30)
# 2. 多帧识图 + 容错处理
descriptions = []
frame_files = sorted([f for f in os.listdir(frame_dir) if f.lower().endswith(".jpg")])
for i, frame_file in enumerate(frame_files):
frame_path = os.path.join(frame_dir, frame_file)
try:
description = describe_image(frame_path)
if description:
descriptions.append(f"第{i+1}帧:{description}")
else:
logging.warning(f"帧 {frame_file} 描述为空,已跳过")
except Exception as e:
logging.error(f"处理帧 {frame_file} 时发生错误:{e}")
continue
if not descriptions:
logging.error("没有任何帧成功识别,流程中止")
return
# 3. 保存描述到文案文件
full_description = "\n".join(descriptions)
description_txt_path = os.path.join(work_dir, "frame_descriptions.txt")
with open(description_txt_path, "w", encoding="utf-8") as f:
f.write(full_description)
logging.info(f"帧内容描述已保存到:{description_txt_path}")
# 4. 文案生成
prompt = (
"你是一个擅长写短视频解说词的创作者,现在请根据以下每一帧画面内容,"
"用轻松幽默的语气,生成一段通俗易懂、符合短视频风格的中文解说,"
"要求内容简洁、节奏明快、具有代入感,可以适当加入网络流行语或比喻,"
"但不要生硬搞笑,也不要重复描述画面,请让内容听起来像是一个博主在视频里自然说话:\n"
f"{full_description}"
)
script = generate_script(prompt)
# 5. 保存文案内容
script_txt_path = os.path.join(work_dir, "narration_script.txt")
with open(script_txt_path, "w", encoding="utf-8") as f:
f.write(script)
logging.info(f"生成的文案已保存到:{script_txt_path}")
# 6. 合成解说音频
audio_path = os.path.join(work_dir, "narration.mp3")
synthesize_audio(script, audio_path)
# 7. 合成视频(使用原视频音频)
logging.info("正在加载原视频音频")
original_clip = VideoFileClip(video_path)
original_audio = original_clip.audio
frame_paths = sorted([os.path.join(frame_dir, f) for f in os.listdir(frame_dir) if f.lower().endswith(".jpg")])
image_clip = ImageSequenceClip(frame_paths, fps=fps).set_audio(original_audio)
output_video_path = os.path.join(work_dir, "final_output_with_original_audio.mp4")
image_clip.write_videofile(output_video_path, codec='libx264', audio_codec='aac')
logging.info(f"视频已成功生成:{output_video_path}")
# 示例调用
main("2025-05-11_15-12-01_UTC.mp4", "output", fps=1) # 请取消注释后运行