Systematic identification and expression profiles of the BAHD superfamily acyltransferases in barley (Hordeum vulgare)
系统鉴定与大麦(Hordeum vulgare)中 BAHD 超家族酰基转移酶的表达谱分析

摘要
BAHD 超家族酰基转移酶在植物中催化和调控次级代谢中发挥着重要作用。然而,关于大麦中 BAHD 超家族的研究相对较少。在本研究中,我们从大麦基因组中鉴定出 116 个 HvBAHD 酰基转移酶基因。基于系统发育分析及在模式单子叶植物和双子叶植物中的分类,我们将这些基因分为八个类群:I-a、I-b、II、III-a、III-b、IV、V-a 和 V-b。值得注意的是,包括与植物抗赤霉菌有关的胍丁胺香豆素转移酶(ACT)在内的 IV 类基因,在拟南芥中并不存在。对 HvBAHD 基因顺式调控元件的分析表明,这些基因对 GA₃(赤霉素)处理具有正向响应。通过计算机预测表达分析及 qPCR 实验结果显示,HvBAHD 基因在多个组织和发育阶段中表达,并在苗期高度富集,表明其具有多样的功能。单核苷酸多态性(SNP)扫描分析表明,HvBAHD 编码区的天然变异较少,这些序列在大麦驯化过程中较为保守。我们的研究揭示了 HvBAHD 基因家族的复杂性,并为其后续功能研究提供了基础。
引言
酰基转移酶具有多种功能,在植物基因表达、代谢和信号转导中发挥着重要作用。植物的次级代谢可产生多种重要的代谢产物,如酚类(如类黄酮)、异戊二烯类化合物(如萜类)以及含氮化合物(如生物碱)(图1a)。BAHD 酰基转移酶催化多种植物次级代谢产物的酰化反应。它们是主要存在于植物、藻类和细菌中的一类超家族酶,负责将酰基供体(通常为酰基活化的 CoA 硫酯)上的酰基基团 [RC(O)R'] 转移至受体分子,其产物包括小分子挥发性酯、改性花青素,以及构成性防御化合物和植物抗毒素(phytoalexins)等¹。
BAHD 酰基转移酶的命名来源于该超家族中最早通过生化手段鉴定出的四种酶名称的首字母²。这四种酶分别是:
-
BEAT(苯甲醇 O-乙酰转移酶),从 Clarkia breweri 中克隆,参与挥发性酯类化合物的生成;
-
AHCT(花青素 O-羟基肉桂酰转移酶),从 Gentiana triflora 中克隆,参与花青素的酰化;
-
HCBT(苯甲酰/羟基肉桂酰转移酶),从 Dianthus caryophyllus 中克隆,参与植物抗毒素 anthramide 的生成;
-
DAT(脱乙酰长春胺 4-O-乙酰转移酶),从 Catharanthus roseus 中克隆,参与生物碱长春胺的最后一步合成。
在这些酶中,主要可分为两类:一类主要参与植物挥发性酯类物质的释放;另一类与花青素/类黄酮的合成密切相关。HCBT 和 DAT 家族的成员通常具有两个重要的保守氨基酸基序:
-
HXXXD(组氨酸-H、任意三残基-X、天冬氨酸-D),通常位于酶的中心区域;
-
DFGWG(天冬氨酸-D、苯丙氨酸-F、甘氨酸-G、色氨酸-W、甘氨酸-G),这是一个保守基序,通常位于蛋白质的羧基末端,推测参与 CoA 的结合(图1b)¹。
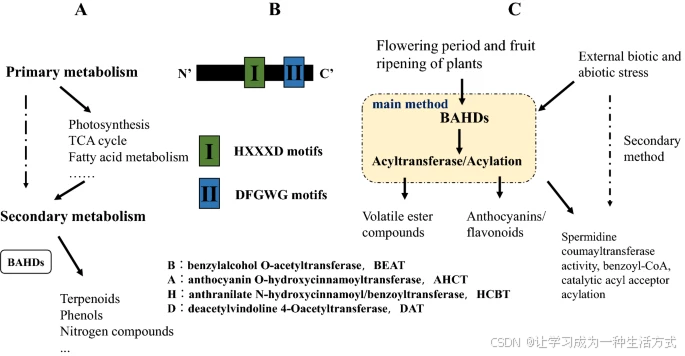
植物中 BAHD 基因的功能角色
(a) BAHD 酰基转移酶在植物次级代谢中发挥重要作用。 (b) BAHD 蛋白的典型结构。 (c) BAHD 的激活过程。
近年来,随着水稻和拟南芥全基因组测序的完成,研究人员已分别在水稻中鉴定出至少 119 个 BAHD 超家族基因,在拟南芥中鉴定出 64 个(包括假基因)³。这极大地促进了对 BAHD 基因功能、催化机制、进化关系,特别是在医学相关性方面的研究。多酚类化合物是饮食中的重要成分,而羟基肉桂酸酯类衍生物(如单木质素羟基肉桂酸酯)被认为具有治疗潜力⁴。例如,从当归 (Angelica sinensis) 中鉴定的 BAHD 酶——阿魏酰辅酶 A:单木质素转移酶(AsFMT),可催化合成阿魏酸芥酯,这种物质具有抗菌、抗氧化和抗阿尔茨海默病的功能⁵,也显示出在抗肿瘤辅助治疗中的潜在逆转作用⁶。紫锥菊中菊苣酸的生成也涉及 BAHD 酰基转移酶,这种代谢产物在抗病毒、抗炎和调节糖脂代谢方面具有重要药用价值⁷。
在真核生物中,蛋白质翻译后的最常见修饰方式之一是酰化或去酰化,而这主要由酰基转移酶的丰度和活性所调控。这类酶在植物的生长发育过程中具有多样化的功能。在拟南芥中,一些已被功能鉴定的 BAHD 成员以羟基肉桂酰辅酶 A(hydroxycinnamoyl-CoA)为底物,例如:
-
羟基肉桂酰辅酶 A:莽草酸/奎宁酸羟基肉桂酰转移酶(HCT),参与木质素的合成⁸;
-
亚精胺羟基肉桂酰转移酶(SHT),在拟南芥花药的绒毡层中合成羟基肉桂酰亚精胺⁹;
-
多胺酰基转移酶,参与拟南芥种子中亚精胺结合物的积累¹⁰;
-
乙酰辅酶 A:(Z)-3-己烯-1-醇乙酰转移酶(CHAT),在拟南芥中生成绿色叶片挥发物 (Z)-3-己烯-1-醋酸酯¹¹;
-
角质层脊缺陷基因(DCR),参与拟南芥花部角质素中最丰富单体的聚合¹²。
此外,还有报道指出亚苯基脂肪酸(suberin)与角质素(cutin)的阿魏酰转移酶,以及蜡质脂肪醇咖啡酰转移酶,能将羟基肉桂酰-CoA 转移到 ω-羟基脂肪酸受体上,这些产物会在细胞外基质中积累¹³¹⁴¹⁵。最近还鉴定出一种新型 BAHD 家族酶 —— 油菜固醇失活酶 2(BIA2),该酶参与油菜素内酯(BR)稳态调控,可能通过酯化方式使生物活性 BR 失活,特别是在黑暗条件下植物的根和下胚轴中作用明显¹⁶。
在水稻中,BAHD 酰基转移酶 OsAT10 作为 p-香豆酰辅酶 A 转移酶,参与葡萄糖醛阿拉伯木聚糖(glucuronoarabinoxylan)的修饰¹⁷;而 缺陷花粉壁基因 2(DPW2) 则在水稻花粉壁的形成中起关键作用,敲除该基因会导致花粉壁结构破坏,最终引发花粉败育(图1c)¹⁸。酰基转移酶还可催化胆固醇的酯化过程,如酰基辅酶 A:胆固醇酰基转移酶(ACAT),可将游离胆固醇转化为胆固醇酯¹⁹。
大麦(Hordeum vulgare)是仅次于玉米、水稻和小麦的世界第四大粮食作物,广泛应用于动物饲料、人类食物以及酿造工业。大麦具有抗逆性强、适应性广、栽培区域广泛等优势。国际大麦基因组测序联盟(IBSC)近期发布了大麦参考基因组的第一个版本²⁰,随着大麦泛基因组测序的推进²¹,大量遗传信息被发掘出来。然而,目前尚未有关于大麦 BAHD 基因家族的全基因组系统研究。开展此类研究将有助于探索 Triticeae(禾谷类)作物中物种间的相似性及潜在的功能特异性。本研究中,我们挖掘了大麦基因组序列资源,并构建了 BAHD 基因家族的隐马尔可夫模型(HMM),据此定义了 BAHD 超基因家族,并分析了其表达特性与预测潜在功能²²²³。
结果
在大麦基因组中鉴定 HvBAHD 基因
本研究使用大麦品种 Morex 的基因组序列来鉴定潜在的 HvBAHD 基因。为此,采用了两种方法:一是利用水稻 (Oryza sativa) 和拟南芥 (Arabidopsis thaliana) 的 BAHD 蛋白序列在本地进行蛋白质 BLAST 搜索;二是通过 Pfam 数据库中的保守 BAHD 超家族功能结构域(Pfam: PF02458)进行隐马尔可夫模型(HMM)搜索。通过去除冗余序列后,共从大麦 (Hordeum vulgare) 中鉴定出 116 个基因,并依次命名为 HvBAHD001 至 HvBAHD116。
几乎所有被筛选出的基因都编码 HXXXD 保守结构域,但 DFGWG 结构域的保守性则存在一定变异。研究还对所有预测的 HvBAHD 蛋白的基本理化性质进行了汇总,包括氨基酸长度、分子量(道尔顿)、等电点(pI)、疏水性预测以及 GC 含量(%)(见补充表 1)。其中约 75% 的 HvBAHD 蛋白长度为 412–499 个氨基酸,与拟南芥和水稻的 BAHD 蛋白相似;63%(73/116)具有亲水性,72% 的等电点小于 7,分子量分布在 40–59 kDa 之间。每个基因在大麦品种 Golden Promise 中的基因编号信息详见补充表 124。
HvBAHD 蛋白的系统进化分析
为了研究 BAHD 家族蛋白的物种间进化关系,本研究利用 MEGA X 软件(Home)构建了包含 295 条 BAHD 蛋白序列(其中 116 条来自大麦,119 条来自水稻,60 条来自拟南芥)的系统进化树,并采用最大似然法(Maximum Likelihood Method)进行树的构建。
HvBAHD 蛋白的分类依据先前关于水稻和拟南芥的研究方法,并结合其与已知同源基因的聚类关系¹³²⁵。结果显示,大麦的 BAHD 蛋白可划分为五个进化支(见图 2 和补充图 S1)。
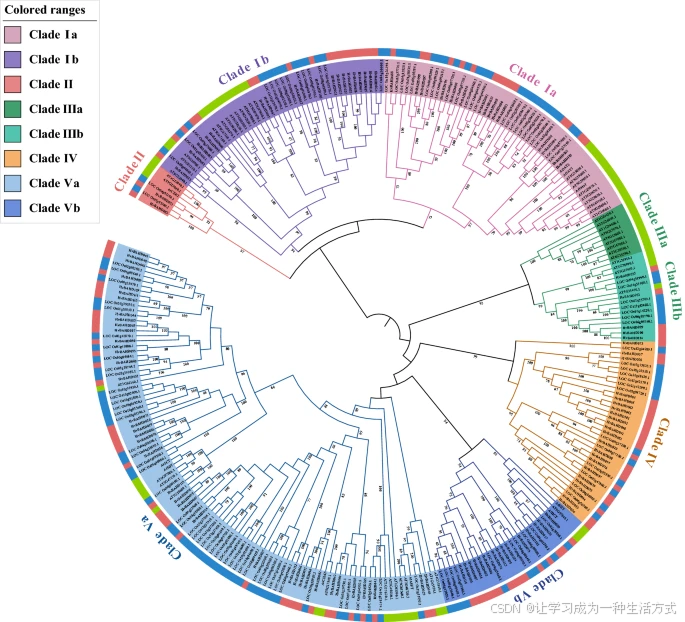
BAHD 蛋白的系统发育分析
采用最大似然法,利用拟南芥、水稻和大麦的 BAHD 蛋白序列构建了系统发育树。这些序列被划分为五个进化支。内环中不同的颜色代表不同的进化支,外环中不同的颜色代表不同的物种(绿色代表拟南芥,红色代表大麦,蓝色代表水稻)。该系统发育树由 MEGA X(Home)和 iTOL 在线工具(iTOL: Interactive Tree Of Life)生成。
进化支 I 包含两个亚支:Ia(包含 15 个 HvBAHD 基因)和 Ib(包含 18 个 HvBAHD 基因)(见图 2);而进化支 II(包含 2 个 HvBAHD 基因)是所有分支中成员最少的一个(见图 2)。进化支 III 也可进一步细分为两个亚支:IIIa(无 HvBAHD 基因)和 IIIb(包含 5 个 HvBAHD 基因)(见图 2)。在大麦中有两个基因 HvBAHD031 和 HvBAHD083 与 Eceriferum2 (CER2) 同源,在与水稻和拟南芥的比对中显示出高度保守性(见图 2)。进化支 IV(包含 22 个 HvBAHD 基因)似乎是本研究所分析的单子叶植物中特有的(见图 2)。
该分支中的一个代表性 BAHD 蛋白是 Agmatine Coumarol Transferase (ACT),据报道该酶可催化水杨酸胺基甲酸(hydroxycinnamate agmatine)的合成,其前体 hydroxycinnamoyl-CoA thioester 可作为一种抗真菌物质 hordatine 的前体。类似的 hydroxycarnitine-agmatine 衍生物也在小麦中被检测到,虽然含量较低。
进化支 IIIa 可能是双子叶植物特有的,因为在水稻和大麦中未检测到相关序列。该支中的 AT4G15400 基因参与三萜类植物激素 brassinosteroid(BR)的合成和修饰,调节 BR 的稳态和植物的光信号响应。尽管 III 类中的大多数成员具有不同的乙酰化醇类受体,其供体大多为 acetyl-CoA。一些 acetyl-CoA 类的 BAHD 酶参与果实中挥发酯的合成(如月季的 RhAAT1),而另一些则参与生物碱的修饰。
进化支 V 拥有最多的 HvBAHD 基因,并可细分为两个亚支:Va(包含 39 个 HvBAHD 基因)和 Vb(包含 15 个 HvBAHD 基因)。在 Va 支中,HvBAHD029 很可能是 AT5G41040(ASFT)、AT5G63560(FACT) 和 AT3G48720(DCF)的同源基因,这些基因参与栓质和角质层的生物合成。此外,HvBAHD115 是 AT2G23510(spermidine diprosyl acyltransferase,SDT)的同源基因,该基因参与种子中二阿魏酰胺精胺及其葡萄糖苷的生成;它还与 AT2G25150(spermidine dicoumarolyl acyltransferase,SCT)同源,该基因主要在根中表达,具有精胺香豆酰 CoA 酰转移酶活性。
Clade Va 中的典型酰基 CoA 蛋白参与挥发酯的形成,与 hydroxycinnamoyl transferase (HCT) 相关,HCT 负责合成绿原酸和单木酚。AtHCT(AT5G48930)位于 Clade V 中,与 HvBAHD011、HvBAHD010 和 HvBAHD082 属于同一类。有研究指出 HCT 在大多数维管植物中参与木质素前体的合成,其多个已知成员(如 hydroxycinnamoyl-CoA shikimate/quinate HCT)都使用 hydroxycinnamoyl-CoA 作为底物。HQT 是与 HCT 密切相关的另一个酶,这两种酶均具有 HHLVD 和 DFGWG 保守结构域。
总体来看,除了 Clade IIIa 外,几乎每个亚支中都存在与功能性 BAHD 基因密切相关的大麦同源基因,这表明其在植物次生代谢中作为酰基转移酶的功能可能在进化过程中得以保留。
BAHD 基因的染色体定位
所有 116 个 HvBAHD 基因均被映射到大麦的染色体上,根据其在染色体上的物理位置命名为 HvBAHD001 至 HvBAHD113,其中 HvBAHD114 至 HvBAHD116 的位置信息未知(见图 3)。进一步的染色体定位分析显示,这些基因在大麦染色体上分布不均。大多数 BAHD 基因集中分布在第 2、7、4 和 1 染色体上(见图 3),并主要位于染色体的末端区域。
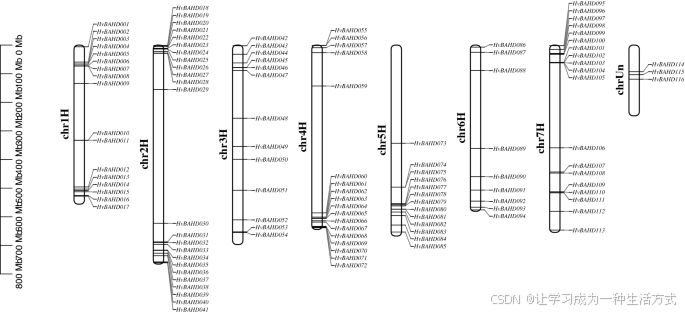
113 个拟定 HvBAHD 基因在大麦七条染色体上的分布情况
113 个 HvBAHD 基因分布于大麦的七个染色体组中,其中有 3 个基因位于未知染色体(chrUn)上。所有大麦染色体根据预测长度按比例绘制。本图由 TBtools v1.082 软件构建(Redirecting)。
HvBAHD 基因启动子中的保守基序和顺式作用元件分析
蛋白质基序的分布可能导致一个基因家族成员之间的功能多样性。因此,我们使用 MEME 工具对 HvBAHD 蛋白预测的全长序列进行了基序分布分析(见图 4;补充表 S2)。共预测得到 10 个基序。大多数 HvBAHD 蛋白都同时含有基序1和基序4。
基于基因结构分析,我们确定基序1(序列为:FTCGGFVIGLRTNHAVADGTGAAQFLNAV)和基序4(序列为:FDVYGNDFGWGRPV)分别对应于保守结构域 HXXXD 和 DFGWG(见补充表 S2)。同一亚家族内的 HvBAHD 成员在保守基序的类型和分布上表现出高度相似性,这与系统发育进化支的分类结果一致。

大麦 BAHD 基因的系统发育关系、基因结构和保守蛋白质基序结构
(a) 基于预测的 HvBAHD 蛋白氨基酸序列构建了最大似然进化树。该系统发育树由 MEGA X(Home)和 iTOL 在线工具(iTOL: Interactive Tree Of Life)生成。
(b) 大麦 BAHD 蛋白的基序组成。不同颜色的框表示不同的基序,通过 MEME 5.0.1(MEME - Submission form)软件分析得到。基序 1 对应 HXXXD 结构域,基序 4 对应 DFGWG 结构域。每个基序的序列信息详见补充表 S2。
(c) 大麦 BAHD 基因的外显子-内含子结构。绿色和黄色方框分别表示未翻译区(UTR)和编码区序列(CDS),黑线代表内含子。基因组结构由 TBtools v1.082 软件构建(Redirecting)。
启动子中的顺式作用元件分析
为了评估 HvBAHD 基因中潜在的顺式调控元件的保守性,我们对所有 116 个基因进行了启动子区(上游 2000 bp 序列)的分析。然而,由于大麦的基因间区序列中存在部分缺失数据,为确保预测结果的可靠性,我们排除了缺失序列的 HvBAHD 基因,仅集中分析 79 个具有完整 2000 bp 上游序列的 HvBAHD 基因。这 79 个基因覆盖了各个进化支的代表性基因,因此结果具有一定的普适性,但不能完全代表整个 HvBAHD 基因家族。
结果显示,一些顺式调控元件(如光响应元件、植物激素响应元件、植物防御相关元件及胁迫响应元件)均与 HvBAHD 家族的潜在功能相关。详细信息见补充表 S3。我们忽略了启动子核心元件 CAAT-BOX(启动子和增强子区中的常见顺式作用元件)和 TATA-BOX(启动子核心元件,位于转录起始点上游约 -30 bp 处),仅展示了其他元件的分布(见补充图 S2)。
在 HvBAHD 基因中,某些元件的分布具有明显的普遍性,包括光响应元件(G-box)、生物和非生物胁迫响应元件(As-1、ARE、STRE、MYB 和 MYC),这些元件在多数 HvBAHD 基因中频繁出现。类似的元件在拟南芥的 BAHD 序列中也有出现,但未提供特定注释信息。这些元件可能反映了 BAHD 基因家族中的重要保守元件。此外,在 HvBAHD 基因中还检测到了一些与赤霉素(GA)相关的反应元件,这些元件可能有助于 HvBAHD 基因的活化。此前的研究表明,大麦中的 ACT 相关基因可能对 GA 功能具有拮抗作用。
HvBAHD 基因的进化分析
系统发育分析可揭示基因复制事件的信息。Ka/Ks 值是评估编码序列进化和确定基因复制后选择压力类型的重要参数。在本研究中,我们通过大麦 BAHD 基因的本地 BLAST 比较,筛选出序列相似性大于 75% 的基因对,以此确定基因复制事件。
根据系统发育分析,共检测到 14 对 HvBAHD 同源基因对(见图 5)。这些推测的串联重复基因对进行了 Ka/Ks 分析,结果包括 Ks(同义替换率)、Ka(非同义替换率) 及 Ka/Ks 比值,具体数据见补充表 S4。
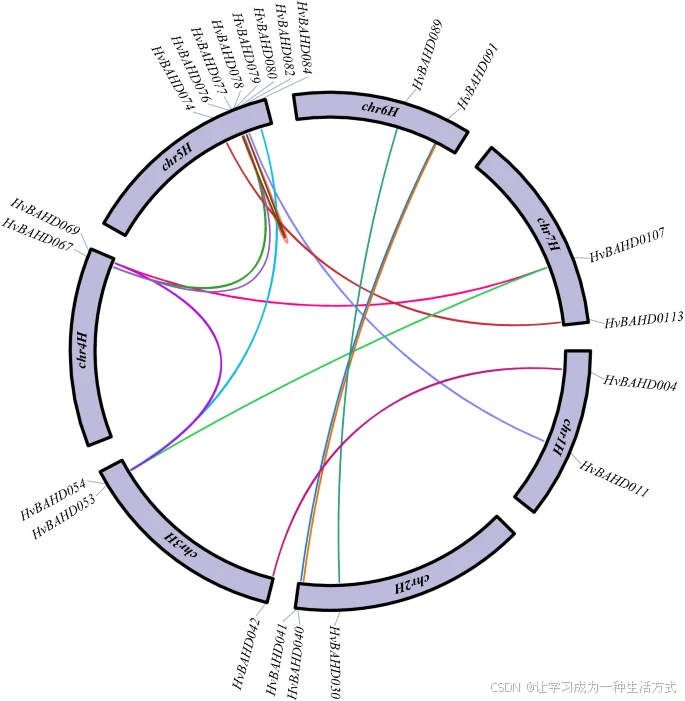
大麦 BAHD 同源基因对及其染色体位置
图中展示了大麦 BAHD 成员的同源基因对及其在染色体上的位置。不同颜色的连线表示两个基因之间存在特定的复制关系。图的外圈显示了相关基因的名称及其在染色体上的分布位置。该图由 TBtools v1.082 构建(Redirecting)。
Ka/Ks 分析与进化意义
非同义突变(Ka)通常受自然选择的影响,而同义突变(Ks)则通常不受选择压力。在进化分析中,了解同义和非同义突变的发生速率具有重要意义。
-
当 Ka/Ks > 1 时,表示基因处于正向选择;
-
当 Ka/Ks = 1 时,表示中性进化;
-
当 Ka/Ks < 1 时,表示存在纯化选择(负选择)效应[35]。
在所筛选出的 14 对重复基因中,有 10 对基因的 Ka/Ks 比值小于 1,这与同义替代(而非非同义替代)所主导的进化模式相符,表明基因复制后为了维持氨基酸序列的稳定性而受到纯化选择的限制。
HvBAHD 基因的 qRT-PCR 表达分析及其对 GA₃ 处理的响应
为分析大麦 BAHD 基因家族的表达模式,从 IPK 网站提取了不同生长阶段、器官和组织的表达数据,并通过分层聚类模型进行分析。热图显示,在 15 个不同发育阶段中,有 111 个 HvBAHD 基因 被检测到有表达(图 6,基于网络 RNA-seq 数据)。
这些 HvBAHD 基因在大麦生长的所有阶段均表现出不同程度的表达。总体上可以观察到:
-
老根中 HvBAHD 基因的表达水平普遍高于幼根;
-
属于系统发育第五类(Clade V)的一些基因(如 HvBAHD030、HvBAHD044、HvBAHD055)在所有阶段的表达量均较高(图 6)。
-
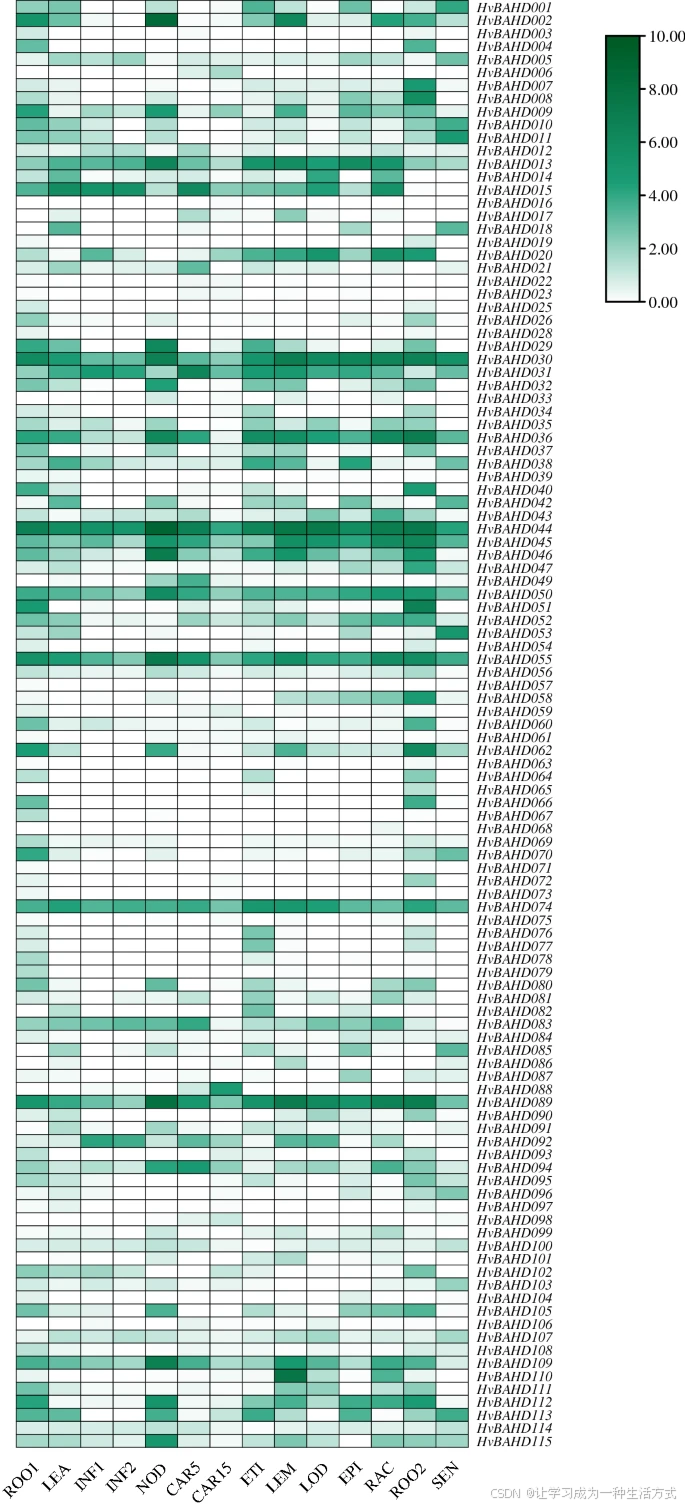
大麦不同组织和器官中部分 BAHD 基因的表达模式
部分 BAHD 基因在大麦不同组织和器官中的表达谱如下图所示。转录水平以从白色到绿色的梯度色标表示。表达数据来自 IPK 网站(Leibniz-Institut für Pflanzengenetik und Kulturpflanzenforschung - Leibniz-Institut (IPK))。标准化后的表达水平通过对数函数转换,并进行了 HvBAHD 基因子集的层次聚类分析。该热图由 TBtools v1.082 绘制(Redirecting)。
各组织的缩写说明如下:
-
ROO1:幼苗根(10 cm 苗期)
-
LEA:幼苗地上部分(10 cm 苗期)
-
INF1:发育早期的花序(5 mm)
-
INF2:发育中的花序(1–1.5 cm)
-
NOD:分蘖期,第三节间(42 天后)
-
CAR5:发育中籽粒(5 天后)
-
CAR15:发育中籽粒(15 天后)
-
ETI:黄化幼苗,黑暗条件(10 天后)
-
LEM:花序中外稃(42 天后)
-
LOD:花序中唇瓣(42 天后)
-
EPI:表皮条带(28 天后)
-
RAC:花序中主轴(35 天后)
-
ROO2:根系(28 天后)
-
SEN:衰老叶片(56 天后)
通过 qRT-PCR 分析 HvBAHD 基因在不同组织中的表达
为进一步了解 HvBAHD 基因在不同组织中的潜在功能,我们对来源于五个系统发育分支的 27 个基因进行了 qRT-PCR 分析。
结果显示:
-
来自 Clade I 的 HvBAHD012、HvBAHD013、HvBAHD015 和 HvBAHD095 在茎部组织中高度表达(图 7);
-
来自 Clade IV 的 HvBAHD034 和 HvBAHD036 在幼苗阶段表达较高(图 7);
-
HvBAHD032、HvBAHD099 和 HvBAHD100 属于 Clade IIIb,该类基因多数参与挥发性物质和生物碱的形成;qRT-PCR 显示这些基因不仅在幼叶中高表达,也在根部有较高表达(图 7);
-
HvBAHD052 与参与羟基肉桂酰转移酶(HCT)合成的基因具有同源性,在幼叶中表达显著(图 7)。
qRT-PCR 分析表明,许多 BAHD 基因在发育中的幼苗组织中有表达,但来自不同系统发育分支的基因在表达上存在明显差异,可能反映了其在不同组织中所承担的不同功能角色。
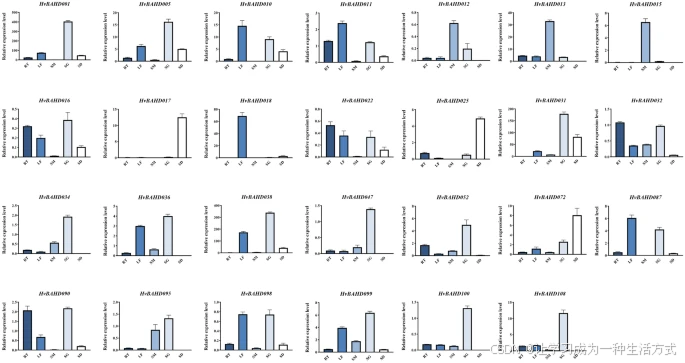
五种大麦组织中 HvBAHD 基因的相对表达水平(qRT-PCR 测定)
HvBAHD 基因在五种不同大麦组织中的相对表达水平通过 qRT-PCR 测定。各组织的缩写如下:
-
RT:根(Root)
-
SM:茎(Stem)
-
LF:叶(Leaf)
-
SG:2 周龄幼苗(2-week-old Seedling)
-
SD:成熟种子(Ripe Seed)
该图由 GraphPad 8 软件绘制(GraphPad中国 | GraphPad Prism 10-分析、绘图并展示你的科研成果!)。
HvBAHD 基因对赤霉素(GA₃)处理的响应分析
通过顺式作用元件(cis-element)分析,我们在部分 BAHD 基因的启动子区域鉴定出了多个GA 响应元件,提示其可能在 GA 信号通路中发挥作用。例如,GARE-motif 和 p-box(皆为赤霉素响应元件)在大麦中与 GA 反应相关,且在 Clade IV 基因中尤为丰富。Clade IV 中的 ACT 基因与赤霉镰刀菌 (Gibberella zeae) 有关联,而该真菌与赤霉素之间存在微妙的关系。
为进一步验证该假设,我们在五叶期的大麦植株中,使用 50 mg/L GA₃ 分别处理 3 天、5 天和 9 天后,检测了部分 HvBAHD 基因的转录响应。qRT-PCR 结果如图 8 所示。
结果表明:
-
处理 第 3 天时,HvBAHD 基因表达变化不显著;
-
但在处理 第 5 天后,基因表达水平显著上调(图 8)。
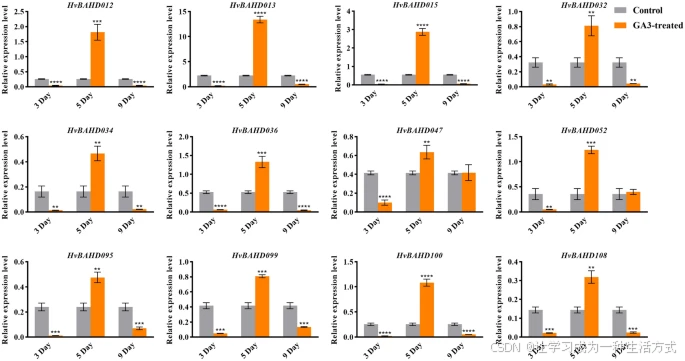
GA₃ 处理后第 3、5、9 天大麦叶片中 HvBAHD 基因的相对表达水平
灰色表示对照组,橙色表示 GA₃ 处理组。统计显著性标记如下: (P < 0.0001,*;P < 0.001,**;P < 0.01,;P < 0.1,*)。
该图由 GraphPad 8 软件绘制(GraphPad中国 | GraphPad Prism 10-分析、绘图并展示你的科研成果!)。
由于 HvBAHD 基因在幼苗期表达水平较高,我们进一步在幼苗上进行了 GA₃ 喷雾处理实验。实验中使用 GA₃ 或清水喷洒幼苗,5 天后采集叶片样本。
qRT-PCR 结果显示,多数检测的 HvBAHD 基因表达水平均显著上调,表明 GA₃ 处理已经影响了植物,并且 HvBAHD 基因对此产生了响应(见图 9)。
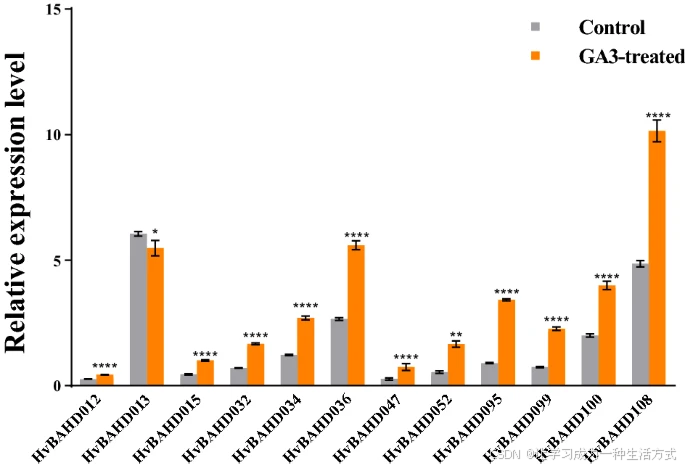
大麦幼苗经 GA₃ 处理 5 天后 HvBAHD 基因的相对表达水平
灰色表示对照组,橙色表示 GA₃ 处理组。 (P < 0.0001,*;P < 0.001,**;P < 0.01,;P < 0.1,*)。
该图由 GraphPad 8 软件绘制(GraphPad中国 | GraphPad Prism 10-分析、绘图并展示你的科研成果!)。
大麦部分 HvBAHD 蛋白的亚细胞定位分析
为了评估大麦中 BAHD 蛋白之间可能存在的差异,我们对部分 HvBAHD 蛋白进行了亚细胞定位分析。 结果表明,HvBAHD041、HvBAHD044、HvBAHD063 和 HvBAHD096 均定位于烟草细胞质中(见图 10)。
HvBAHD041 和 HvBAHD063 属于 Clade IV,该类群似乎是单子叶植物特有的,可能与抗真菌功能相关。因此,Clade IV 中 ACT 基因相关的生物合成途径很可能发生在细胞内部。
HvBAHD096 是 Clade Ia 的代表基因,该类群还包含拟南芥 At5MaT 基因,后者在体内外均可作为花青素 5-葡萄糖苷丙二酰辅酶 A 酰基转移酶发挥功能36。 定位结果表明,来自 At5MaT 类别的酰基转移酶在大麦中极可能在细胞质中合成。
相比之下,HvBAHD074(属于 Clade V 分支)预测主要参与乙酰辅酶 A 的合成,其定位分析显示该蛋白位于细胞核中。
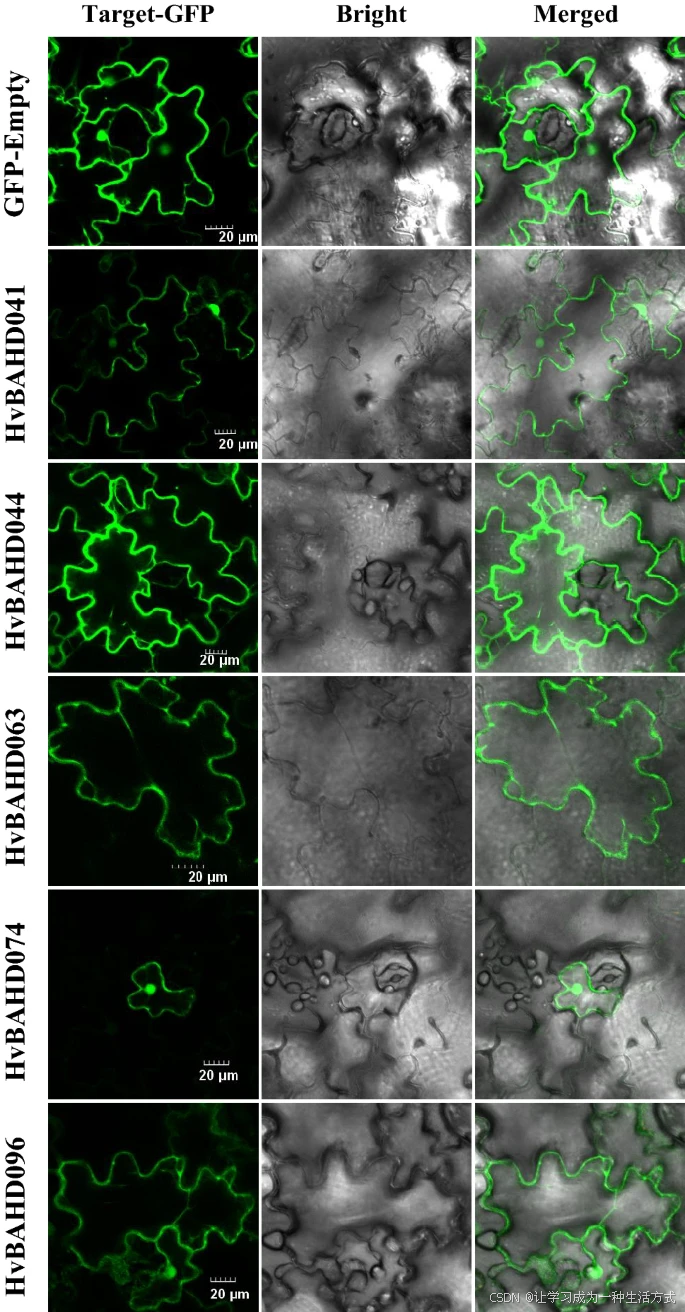
HvBAHD 蛋白在大麦中的亚细胞定位
选取的 HvBAHD-GFP 融合蛋白与空载 GFP(GFP-Empty,作为对照)分别在烟草叶片中瞬时表达,并在共聚焦显微镜下进行成像。比例尺为 20 μm。
大麦的 SNP 数据分析
为探究 HvBAHD 家族在驯化过程中的自然变异,我们利用 IPK Gatersleben 大麦泛基因组数据库进行 SNP 检索,并收集了 93 个 BAHD 基因的信息。在这些基因中,仅有 52%(48/93) 在 SNP 浏览器所采样的品种中检测到 SNPs,47%(44/93) 出现了氨基酸改变(见补充图 S3)。 值得注意的是,Clade IV 类群中含有 SNP 的基因比例非常高,达到 71%(12/17),Clade II 亚类中的两个大麦基因也都表现出 SNP 突变。这表明这些子类成员可能发生了重要的变异,属于在进化上仍较“年轻”的基因,具有较高的变化频率。 此外,在所有 MAF(最小等位基因频率)> 0.05 的 HvBAHD 基因中,仅有 32%(30/93) 受 SNP 影响,这可能由于其自身功能上的限制,也说明大多数基因是保守的,未受到 SNP 位点突变的影响。
讨论
通过对大麦 BAHD 基因家族的检索、分析和整理,我们共鉴定出 116 个 HvBAHD 基因,所有这些基因均具有典型的 HXXXD 特征结构域。该基因总数与水稻和杨树相似,表明 BAHD 家族在植物进化中具有重要作用。
我们利用最大似然法构建了系统发育树,包含 116 个大麦、60 个拟南芥和 119 个水稻的 BAHD 蛋白序列。在系统发育分析中,116 个 HvBAHD 基因被分为五个类群,其分类与水稻和拟南芥相似,但 Clade IV 是禾本科特有的类群(见图 2)。
虽然 HvBAHDs 在序列长度和分子量上差异较大,但其结构域和保守基序(motif)组成高度一致(见补充表 1)。外显子/内含子组成分析显示,HvBAHD 基因的内含子数量从 0 到 5 不等,但多数基因只有一个或无内含子,且除 HvBAHD005 和 HvBAHD037 外,不同类群中的内含子数目都高度保守(见图 4),这与其他植物的研究结果一致1,25,37。
我们发现,大多数 HvBAHD 基因分布于染色体的基因富集区(见图 3),这一特点也与其他大麦基因家族的报道一致38,^39。
基因重复是导致基因组复杂性及基因家族快速扩张和进化的主要机制之一40,^41。 染色体分布数据显示,至少有 14 对 HvBAHD 基因发生了重复事件(见图 5;补充表 S4),其中大部分为片段重复,仅有两对基因(HvBAHD76 与 HvBAHD80;HvBAHD77 与 HvBAHD80)属于串联重复产物。这些片段重复事件与其他物种中 BAHD 家族的研究结果一致37。
大多数 BAHD 家族成员参与不同的生化反应,尽管从低等植物到高等植物在各种酯类合成途径中的 BAHD 酰基转移酶功能存在细微差异。位于 Clade II 的 AT4G24510.1(CER2) 有助于表皮角质层蜡质的形成,从而在物理上抵抗外部病原体的侵袭并控制水分流失42,^43。 CER2 已在拟南芥、玉米和水稻中被鉴定,具有相似的功能,促进蜡质超长链脂肪酸(VLCFA)前体的延伸。 在苔藓植物中尚未发现 CER2 同源物,提示 CER2 可能是维管植物中的一项进化创新44。
我们在系统发育分析中将这些已知序列作为参考成员纳入,有助于推测 HvBAHDs 中存在大量潜在的新型酶,特别是在某些尚无已知功能酶的亚类中(图 2)。 系统发育树显示,Clade IV 是禾本科特有的类群,其中存在许多与 Gibberella zeae(禾谷镰刀菌)相关的应答元件,可能增强植物的抗病能力。 在进化过程中,禾本科形成了一个特殊分支,仍可能存在更多有趣的功能联系(图 2)。Clade IV 中的Agmatine coumaroyltransferase(ACT)是植物中第一个被鉴定的胺类 N-羟基肉桂酰转移酶,负责在大麦中催化抗真菌的羟基肉桂酰阿魏胺类衍生物的生物合成,代表了一类新的 N-羟基肉桂酰转移酶45。 Clade IV 中 HvBAHD 蛋白的数量众多,提示它们可能在抵御真菌侵染中发挥作用,与大麦的进化相关。 未来还需要进一步实验验证该类群在植物激素赤霉素调控中的作用,尤其考虑其与 Gibberella zeae 之间存在某种关联。
顺式调控元件分析为 HvBAHDs 的功能研究提供了重要基础。本研究中我们发现,在 HvBAHD 基因启动子区域预测的顺式元件中,响应生物胁迫和非生物胁迫的元件数量最多,表明这些基因可能参与应对各种不利环境胁迫。
此外,我们还发现与赤霉素响应相关的 GARE-motif 和 p-box(赤霉素响应元件) 在该家族中广泛存在。这与我们的 GA 处理实验结果一致,表明 HvBAHD 基因在处理后几天内对 GA₃ 表现出积极响应。
我们还鉴定出多个 TGACG 和 CGTCA 基序,这些元件主要响应 甲基茉莉酸(MeJA),这与 BAHD 在次生代谢中的作用一致。甲基茉莉酸可提高过氧化物酶、壳聚糖酶和脂氧合酶等防御蛋白的活性46,^47,从而促进生物碱和酚酸类次生代谢物的积累,改变挥发性信号物质的释放,甚至形成防御结构,如腺毛和树脂道。
qRT-PCR 的结果表明,BAHD 不同类群的基因存在表达差异。进一步研究有助于确定哪些成员与 JA(茉莉酸)应答相关,以及这是否与顺式元件的存在直接相关。
分布于 Clade II 和 Clade IV 的大量 SNP 位点表明,与其他类群相比,这两个类群在植物进化过程中可能演化出更为专一的功能(补充图 S3)。 近期的一些研究发现,将 细胞壁 BAHD 酰基转移酶–对羟基肉桂酸单烯醇转移酶(PMTs) 引入拟南芥和杨树中,可促进木质素的类香豆素化,从而提高糖化效率48。这说明 BAHD 酰基转移酶在禾本科与双子叶植物细胞壁的改性中具有重要作用,并具有在饲料及生物能源工程中提升糖化潜力的应用前景49。
目前,已有部分 BAHD 基因家族的生化功能被阐明,显示出它们在多个研究领域中的重要作用。然而,仍有许多 BAHD 基因的功能尚不明确。 本研究为进一步探索 BAHD 基因家族在大麦这一关键小麦族作物中的作用提供了基础,目前大麦的功能基因组学与遗传资源正日益丰富。
结论
本研究在大麦参考品种 Morex 的基因组中共鉴定出 116 个 HvBAHD 基因。系统发育分析表明,这些基因在数量和分类上与水稻和拟南芥相似。通过基因结构、MEME 模式、Ka/Ks 和 SNP 扫描分析发现,大多数 HvBAHD 基因具有较高的保守性。
值得注意的是,Clade IV 基因似乎是单子叶植物特有的,其中包含与植物抗 Gibberella 真菌相关的 ACT 基因。此外,我们分析了 HvBAHD 启动子的顺式调控元件,发现其对 GA₃ 处理有积极响应。基因表达分析表明,多数 HvBAHD 基因在幼苗期表达活跃。
截至目前,尚无大麦 BAHD 家族成员被详细功能解析。本研究为该基因家族的功能研究、转录调控机制和在大麦中的作用奠定了坚实基础。
材料与方法
植物材料与数据来源
本研究使用的二穗春大麦品种 Golden Promise 种子由上海交通大学提供。水稻 OsBAHD 和拟南芥 AtBAHD 的蛋白质序列分别下载自 水稻基因组注释项目(RGAP)(Rice Genome Annotation Project)50 和 拟南芥信息资源中心(TAIR)(TAIR - Arabidopsis)。 大麦的核苷酸和蛋白质序列则来自于植物基因组数据库 Phytozome(Phytozome v13)51。我们利用 HMMER 工具(Biosequence analysis using profile hidden Markov Models | HMMER)对大麦蛋白序列进行检索,筛选出包含 HvBAHD 保守结构域 的候选蛋白(E-value < 10⁻¹⁰)。
序列识别与收集
我们使用 TBtools 提取水稻和拟南芥中的 BAHD 蛋白序列52,并利用 MEGA-X(Home)进行多序列比对53。HMM 构建过程使用 Bio-linux 软件完成54,^55。E-value 小于 10⁻¹⁰ 的序列被选为候选基因,最终共保留 116 个 HvBAHD 基因。 为保证数据的准确性,我们使用 Pfam 数据库(Pfam is now hosted by InterPro)中提供的 BAHD 特征结构域(PF02458)构建 HMM 模型56,^57。
系统发育分析
HvBAHD 蛋白序列使用 ClustalW 工具默认参数进行比对58。然后,利用 MEGA-X 软件以 最大似然(ML)法(替代模型:WAG + G + F) 构建系统发育树,并进行 1000 次自助法(bootstrap)重复59。 系统发育分析共使用了来自:
-
稻(Oryza sativa)的 119 个 BAHD 蛋白序列,
-
拟南芥(Arabidopsis thaliana)的 60 个 BAHD 蛋白序列,
-
大麦(Hordeum vulgare)的 116 个 BAHD 蛋白序列。
构建完成的系统发育树使用 iTOL 工具(iTOL: Interactive Tree Of Life)进行可视化60。
基因结构与保守基序分析
为了分析 HvBAHD 基因的外显子/内含子结构,我们从 Phytozome 上的大麦基因组数据库(Phytozome v13)下载了其 CDS 和蛋白质序列。使用 MEME 工具(MEME - Submission form)识别 HvBAHD 蛋白中的保守基序61,其参数设置如下:
-
最大基序数设为 10;
-
每个基序长度范围为 6–200;
-
总基序上限为 50;
-
其余参数使用默认设置。
使用 TBtools52 对基因结构及保守基序进行可视化分析。 ExPasy 生物信息学在线工具(Compute pI/Mw tool,Expasy - Translate tool)62 被用于预测每个 HvBAHD 蛋白的 等电点(pI) 和 相对分子质量(kDa)。 此外,选取每个 HvBAHD 基因启动子上游 2 Kb 区域,使用 PlantCARE 工具(http://bioinformatics.psb.ugent.be/webtools/plantcare/html/)63 进行顺式调控元件分析。
染色体位置信息与共线性分析
每个基因的预测定位信息来自 BARLEY IPK 网站(Home),随后使用 TBtools 绘制染色体定位图。利用 Bio-linux 平台中的 KaKs_Calculator2.0 程序64,^65 计算 Ka/Ks 值。
大麦 HvBAHD 基因的表达分析
为研究 HvBAHD 基因在不同组织和发育阶段中的特异性表达模式,我们从 IPK 数据库(Galaxy)下载了不同时期的 RNA-seq 数据。基因表达水平以 FPKM(每千个外显子碱基的每百万片段数) 表示,并使用 TBtools 绘制表达热图。
植物生长、组织处理及赤霉素(GA)处理
春大麦品种 Golden Promise 在 安徽农业大学(北纬 31.85°,东经 117.26°)常温(15–25 °C)条件下自然种植。种子在 3 月初发芽,幼苗移栽至花盆中。成熟根、茎、叶、幼苗和穗的组织样本分别采集,用锡纸包裹并迅速投入液氮中保存,所有样本存于 −80 °C 用于 RNA 提取等后续实验。 在 GA₃ 处理实验中,向五叶期植株叶面喷洒 50 mg/L 的 GA₃ 溶液,喷水处理作为对照。具体方法为选择两个生长一致的大麦盆栽样本,其中一个喷洒 GA₃,另一个喷洒相同体积的水,间隔一天喷洒一次,期间统一浇水和施肥。在处理第 3 天、第 5 天和第 9 天分别采集叶片进行 RNA 提取,并通过 qRT-PCR 检测 HvBAHD 基因表达水平,同时记录植株生长变化。此外,还进行了使用 10⁻⁴ M GA 溶液的喷洒处理,对照组喷洒水。所有方法(包括种子的收集)均遵循中国相关的法规与操作规范。
实时定量 PCR(qRT-PCR)分析
使用 Tiangen 公司(北京) 提供的 Trizol 法总 RNA 提取试剂盒从不同大麦组织中提取总 RNA,按照说明书操作。RNA 质量通过 Nanodrop 1000 紫外分光光度计(ThermoFisher Scientific) 检测,并通过 1% 琼脂糖凝胶电泳验证完整性。 一链 cDNA 使用 PrimeScript™ RT 试剂盒(带 gDNA 去除步骤,TaKaRa) 合成,实时荧光定量 PCR 使用 Hieff® qPCR SYBR Green Master Mix(叶森生物,上海) 试剂,在 Roche Light Cycler 96 实时 PCR 系统上进行。反应程序为两步法。 相对表达量使用 2^ΔΔCt 法 计算,显著性分析使用 t 检验66。HvACTIN(HORVU1Hr1G074350.1) 被用作内参基因67。所有用于检测 HvBAHD 基因表达的引物列于补充表 S5中。
HvBAHD 基因的亚细胞定位
为进行瞬时表达,使用引物 HvBAHDs-CDS-F 和 HvBAHDs-CDS-R(序列见补充表 S5)扩增 HvBAHD CDS 全长,并将其克隆入经 Bgl II 和 Spe I 酶切的 pCAMBIA1301-GFP 载体中,构建成表达载体 1301-35Spro:HvBAHDCDS-GFP。构建好的载体转化入 农杆菌 GV3101 菌株,并注入 4 周龄烟草(Nicotiana benthamiana)叶片中。在黑暗条件下培养 72 小时后,将带有荧光蛋白的烟草叶表皮组织用水封片,使用共聚焦显微镜(Leica TCS SP5)观察,以空载体 1301-GFP 作为对照。
启动子顺式调控元件预测
从大麦基因组的 GFF3 文件中提取每个 BAHD 相关基因上游 2000 bp 的序列,进行顺式调控元件分析。使用 PlantCARE 网站(http://bioinformatics.psb.ugent.be/webtools/plantcare/html/)63,^68 进行预测,并通过 RStudio 软件进行可视化分析。
HvBAHD 基因的单核苷酸多态性(SNP)数据分析
在 IPK-SNP 浏览器(IPK Gatersleben - BRIDGE Web Portal)69 中选择大麦核心亚群体 “core50” 作为研究对象,统计 HvBAHD 基因家族中的 SNP 数量。