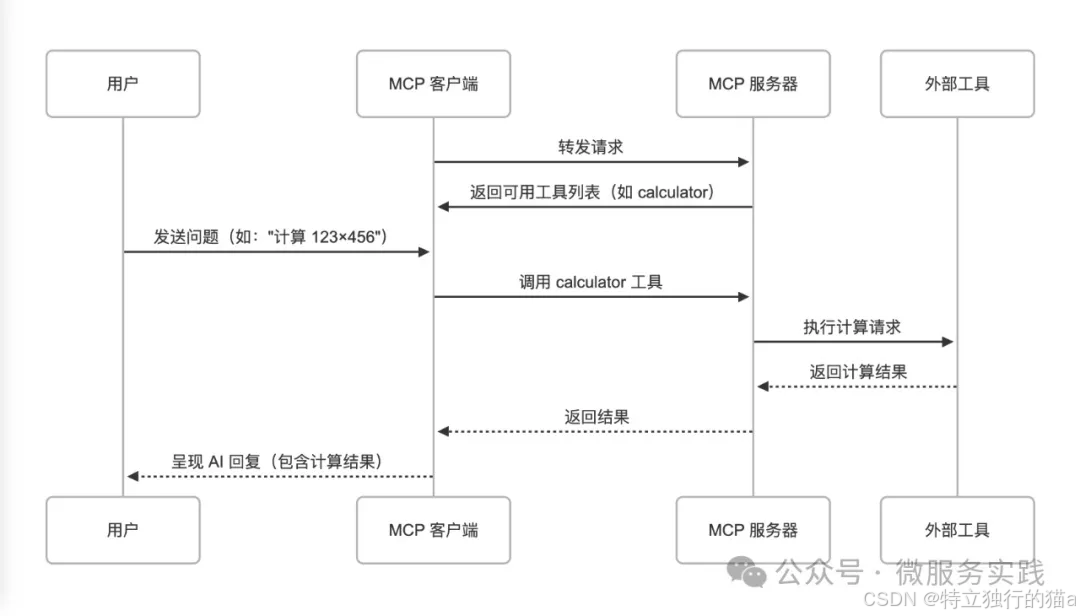
复习日:
1.标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)StandardScaler() :这部分代码调用了 StandardScaler 类的构造函数。在Python中,当你在类名后面加上括号时,就相当于调用了这个类的构造函数,构造函数会创建并初始化一个新的对象。
scaler = ... :这部分代码把调用构造函数后创建的新对象赋值给变量 scaler 。之后,你就可以使用 scaler 这个变量来访问 StandardScaler 类定义的属性和方法。
2.k_range = range(2, 11) # 测试 k 从 2 到 10:为什么不是2到11呢?
Python 里 range() 函数的特性是左闭右开区间,也就是说,它会包含起始值,但不包含结束值。
3.plt.subplot(2, 2, 2)
用 matplotlib.pyplot 模块的 subplot() 函数来创建一个子图。 subplot() 函数的参数解释如下:
- 第一个参数 2 :表示将图形窗口在垂直方向上划分为 2 行。
- 第二个参数 2 :表示将图形窗口在水平方向上划分为 2 列。
- 第三个参数 2 :表示当前要创建和操作的子图编号,编号从左到右、从上到下依次递增。在这个例子中, 2 表示选择第二个子图(即第一行的第二个位置)。
4.奇异值分解(SVD)
输入为矩阵A,尺寸为m*n,可以不是方阵,经过SVD后得到三个矩阵、
和
:
左奇异向量矩阵: 是一个
的正交矩阵,列向量是矩阵
的特征向量。
- 作用:表示原始矩阵 在行空间(样本空间)中的主方向或基向量。简单来说,$U$ 的列向量描述了数据在行维度上的“模式”或“结构”。
- 应用:在降维中, 的前几列可以用来投影数据到低维空间,保留主要信息(如在图像处理中提取主要特征)。
奇异值矩阵:
- 是一个 的对角矩阵,对角线上的值是奇异值(singular values),按降序排列,非负。
- 作用:奇异值表示原始矩阵 在每个主方向上的“重要性”或“能量”。较大的奇异值对应更重要的特征,较小的奇异值对应噪声或次要信息。
- 应用:通过选择前个较大的奇异值,可以实现降维,丢弃不重要的信息(如数据压缩、去噪)。
右奇异向量矩阵的转置:
- 是 的转置,
是一个
的正交矩阵,列向量是矩阵
的特征向量。
- 作用:表示原始矩阵 在列空间(特征空间)中的主方向或基向量。简单来说,
的列向量描述了数据在列维度上的“模式”或“结构”。
- 应用:类似,
的前几列可以用来投影数据到低维空间,提取主要特征。
简单来说、
和
提供了数据的核心结构信息,帮助我们在保留主要信息的同时简化数据处理。
奇异值分解(SVD)后,原始矩阵被分解为
,这种分解是等价的,意味着通过
、
和
的乘积可以完全重构原始矩阵
,没有任何信息损失。
但在实际应用中,我们通常不需要保留所有的奇异值和对应的向量,而是可以通过筛选规则选择排序靠前的奇异值及其对应的向量来实现降维或数据压缩。以下是这个过程的核心思想:
1. 奇异值的排序:
- 在 矩阵中,奇异值(对角线上的值)是按降序排列的。靠前的奇异值通常较大,代表了数据中最重要的信息或主要变化方向;靠后的奇异值较小,代表次要信息或噪声。
- 奇异值的大小反映了对应向量对原始矩阵 的贡献程度。
2. 筛选规则:
- 我们可以根据需求选择保留前个奇异值(
是一个小于原始矩阵秩的数),并丢弃剩余的较小奇异值。
- 常见的筛选规则包括:
- 固定数量:直接选择前 个奇异值(例如,前 10 个)。
- 累计方差贡献率:计算奇异值的平方(代表方差),选择累计方差贡献率达到某个阈值(如 95%)的前 个奇异值。
- 奇异值下降幅度:观察奇异值下降的“拐点”,在下降明显变缓的地方截断。
3. 降维与近似:
- 保留前 个奇异值后,我们只取
矩阵的前
列(记为
,尺寸为
)、
矩阵的前
个奇异值(记为
,尺寸为
)、以及 $V^T$ 矩阵的前
行(记为
,尺寸为
)。
- 近似矩阵为 ,这个矩阵是原始矩阵
的低秩近似,保留了主要信息,丢弃了次要信息或噪声。
- 这种方法在降维(如主成分分析 PCA)、图像压缩、推荐系统等领域非常常用。
4. 对应的向量:
- $U$ 的列向量和 $V$ 的列向量分别对应左右奇异向量。保留前 个奇异值时,
的列向量代表数据在行空间中的主要方向,
的列向量代表数据在列空间中的主要方向。
- 这些向量与奇异值一起,构成了数据的主要“模式”或“结构”。
总结:SVD 分解后原始矩阵是等价的,但通过筛选排序靠前的奇异值和对应的向量,我们可以实现降维,保留数据的主要信息,同时减少计算量和噪声影响。这种方法是许多降维算法(如 PCA)和数据处理技术的基础。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 设置随机种子以便结果可重复
np.random.seed(42)
# 模拟数据:1000 个样本,50 个特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 随机生成特征数据
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模拟二分类标签
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")
# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")
# 选择保留的奇异值数量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形状为 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")
# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")
# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")
# 训练模型(以逻辑回归为例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)
# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")
# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")实际操作过程中的注意事项:
#1. 标准化数据:在进行 SVD 之前,通常需要对数据进行标准化(均值为 0,方差为 1),以避免某些特征的量纲差异对降维结果的影响。可以使用 `sklearn.preprocessing.StandardScaler`。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 注意:`scaler` 必须在训练集上 `fit`,然后对测试集只用 `transform`,以避免数据泄漏。
#2. 选择合适的 k:可以通过累计方差贡献率(explained variance ratio)选择 k,通常选择解释 90%-95% 方差的 k值。代码中可以计算:
explained_variance_ratio = np.cumsum(sigma_train**2) / np.sum(sigma_train**2)
print(f"前 {k} 个奇异值的累计方差贡献率: {explained_variance_ratio[k-1]}")
#3. 使用 sklearn 的 TruncatedSVD:`sklearn` 提供了 `TruncatedSVD` 类,专门用于高效降维,尤其适合大规模数据。它直接计算前 k个奇异值和向量,避免完整 SVD 的计算开销。
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=k, random_state=42)
X_train_reduced = svd.fit_transform(X_train)
X_test_reduced = svd.transform(X_test)
print(f"累计方差贡献率: {sum(svd.explained_variance_ratio_)}")@浙大疏锦行




![[MySQL数据库] SQL优化](https://i-blog.csdnimg.cn/direct/65f10f1a025e42d39188a7bcc2d4bec5.png)