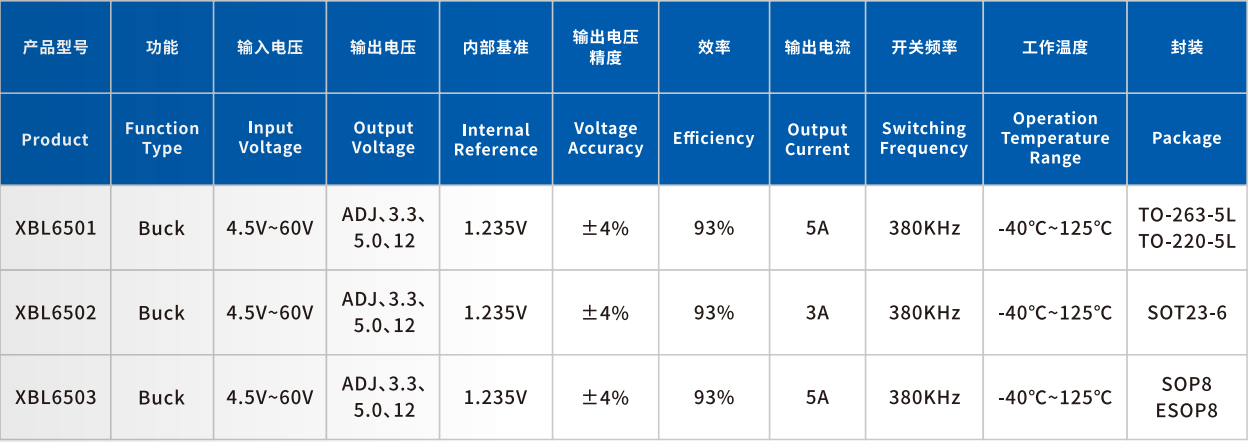
位置编码理论与应用
1. 位置编码如何解决置换不变性及其数学表现
在Transformer模型中,自注意力机制(Self-Attention)具有置换不变性(permutation invariance),这意味着对输入序列的词元(token)进行任意重排,输出的内容本质上保持不变(或仅是行的重排),导致模型无法感知词元的顺序。为了解决这一问题,**位置编码(Positional Encoding)**通过将位置信息融入输入序列,打破这种不变性,使模型能够区分词元的相对或绝对位置。
1.1 置换不变性的数学表现
置换不变性是自注意力机制无法捕捉位置信息的核心原因。让我们从数学角度分析:
-
自注意力机制的计算:
- 输入序列为 X = [ x 1 , x 2 , … , x n ] X = [x_1, x_2, \dots, x_n] X=[x1,x2,…,xn],其中 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd 是第 i i i 个词元的嵌入向量。
- 通过线性变换生成查询(Query)、键(Key)和值(Value): Q = X W Q , K = X W K , V = X W V Q = X W_Q, \quad K = X W_K, \quad V = X W_V Q=XWQ,K=XWK,V=XWV 其中 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 是可学习的权重矩阵。
- 注意力权重为: A = softmax ( Q K T d k ) A = \text{softmax}\left( \frac{Q K^T}{\sqrt{d_k}} \right) A=softmax(dkQKT) 输出为: Attention ( Q , K , V ) = A V \text{Attention}(Q, K, V) = A V Attention(Q,K,V)=AV
-
置换操作的影响:
- 假设对输入 X X X 应用置换矩阵 P P P(一个重排行的矩阵),置换后的输入为 X ′ = P X X' = P X X′=PX。
- 置换后的查询、键和值变为: Q ′ = P Q , K ′ = P K , V ′ = P V Q' = P Q, \quad K' = P K, \quad V' = P V Q′=PQ,K′=PK,V′=PV
- 注意力权重变为: A ′ = softmax ( Q ′ ( K ′ ) T d k ) = softmax ( P Q K T P T d k ) = P A P T A' = \text{softmax}\left( \frac{Q' (K')^T}{\sqrt{d_k}} \right) = \text{softmax}\left( \frac{P Q K^T P^T}{\sqrt{d_k}} \right) = P A P^T A′=softmax(dkQ′(K′)T)=softmax(dkPQKTPT)=PAPT
- 输出为: Attention ( Q ′ , K ′ , V ′ ) = A ′ V ′ = P A P T P V = P A V \text{Attention}(Q', K', V') = A' V' = P A P^T P V = P A V Attention(Q′,K′,V′)=A′V′=PAPTPV=PAV
- 结果表明,置换后的输出 P A V P A V PAV 是原始输出 A V A V AV 的行重排,内容本质不变(即集合意义上等价)。这意味着自注意力机制无法区分 X X X 和 X ′ X' X′ 的顺序,仅依赖词元的内容。
1.2 位置编码如何解决置换不变性
位置编码通过将位置信息融入输入序列,打破置换不变性,使模型能够感知词元的位置。常见的实现方式有两种:绝对位置编码和相对位置编码。
1.2.1 绝对位置编码
- 原理:
- 为每个位置 m m m 分配一个独特的位置编码向量 p m p_m pm,将其加到对应的词元嵌入 x m x_m xm 上: x m ′ = x m + p m x_m' = x_m + p_m xm′=xm+pm 输入序列变为: X new = [ x 1 + p 1 , x 2 + p 2 , … , x n + p n ] X_{\text{new}} = [x_1 + p_1, x_2 + p_2, \dots, x_n + p_n] Xnew=[x1+p1,x2+p2,…,xn+pn]
- 数学表现:
- 若对 X new X_{\text{new}} Xnew 应用置换矩阵 P P P,置换后的输入为: X new ′ = P X new = P ( X + P pos ) X_{\text{new}}' = P X_{\text{new}} = P (X + P_{\text{pos}}) Xnew′=PXnew=P(X+Ppos) 其中 P pos = [ p 1 , p 2 , … , p n ] P_{\text{pos}} = [p_1, p_2, \dots, p_n] Ppos=[p1,p2,…,pn]。
- 因为 p m p_m pm 与位置绑定,置换后位置编码也会重排(如 P P pos P P_{\text{pos}} PPpos),导致 X new ′ ≠ X new X_{\text{new}}' \neq X_{\text{new}} Xnew′=Xnew。这使得注意力计算的结果不再仅仅是行的重排,模型能够感知位置差异。
- 例子:
- 三角函数位置编码(原Transformer): P E ( pos , 2 i ) = sin ( pos 1000 0 2 i / d ) , P E ( pos , 2 i + 1 ) = cos ( pos 1000 0 2 i / d ) PE(\text{pos}, 2i) = \sin\left(\frac{\text{pos}}{10000^{2i / d}}\right), \quad PE(\text{pos}, 2i+1) = \cos\left(\frac{\text{pos}}{10000^{2i / d}}\right) PE(pos,2i)=sin(100002i/dpos),PE(pos,2i+1)=cos(100002i/dpos) 不同位置的编码向量具有独特的频率模式。
- 效果:
- 通过为每个词元添加位置标识,打破了置换不变性,模型可以区分不同位置的词元。
1.2.2 相对位置编码
- 原理:
- 直接在注意力机制中引入词元间的相对位置信息,通常通过修改注意力权重的计算方式。例如,在注意力分数中加入与相对位置 i − j i - j i−j 相关的偏置项。
- 数学表现:
- 修改注意力分数计算: a i j = q i T k j + q i T R i − j a_{ij} = q_i^T k_j + q_i^T R_{i-j} aij=qiTkj+qiTRi−j 其中 R i − j R_{i-j} Ri−j 是相对位置 i − j i - j i−j 的编码向量。
- 置换输入后,相对位置 i − j i - j i−j 会随之改变,导致注意力权重 A A A 的计算结果不同,输出不再是简单重排。
- 例子:
- Transformer-XL: a i j = q i T k j + q i T R i − j + u T k j + v T R i − j a_{ij} = q_i^T k_j + q_i^T R_{i-j} + u^T k_j + v^T R_{i-j} aij=qiTkj+qiTRi−j+uTkj+vTRi−j R i − j R_{i-j} Ri−j 使用正弦余弦函数生成,依赖相对距离。
- 效果:
- 相对位置编码直接捕捉词元间的相对距离或顺序,使模型对位置变化敏感。
1.3 数学分析:Taylor展开的视角
在Transformer模型中,位置编码(Positional Encoding)是解决自注意力机制无法捕捉词元顺序的关键机制。通过将模型输出函数 f ( X ) f(X) f(X) 在加入位置编码后的输入 X + P pos X+P_{\text{pos}} X+Ppos 处进行Taylor展开,我们可以从数学视角深入理解位置编码如何引入绝对位置信息和相对位置信息。
f ~ ( X + P pos ) ≈ f ( X ) + p m T ∂ f ∂ x m + p n T ∂ f ∂ x n + p m T ∂ 2 f ∂ x m 2 p m + p n T ∂ 2 f ∂ x n 2 p n + p m T ∂ 2 f ∂ x m ∂ x n p n \tilde{f}(X + P_{\text{pos}}) \approx f(X) + p_m^T \frac{\partial f}{\partial x_m} + p_n^T \frac{\partial f}{\partial x_n} + p_m^T \frac{\partial^2 f}{\partial x_m^2} p_m + p_n^T \frac{\partial^2 f}{\partial x_n^2} p_n + p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n f~(X+Ppos)≈f(X)+pmT∂xm∂f+pnT∂xn∂f+pmT∂xm2∂2fpm+pnT∂xn2∂2fpn+pmT∂xm∂xn∂2fpn
其中:
-
X X X 是输入序列的词元嵌入矩阵, x m x_m xm 和 x n x_n xn 是位置 m m m 和 n n n 的词元嵌入向量。
-
P pos P_{\text{pos}} Ppos 是位置编码矩阵, p m p_m pm 和 p n p_n pn 是位置 m m m 和 n n n 的位置编码向量。
-
f ( X ) f(X) f(X) 是模型输出函数, f ~ ( X + P pos ) \tilde{f}(X + P_{\text{pos}}) f~(X+Ppos) 是加入位置编码后的输出。
展开式中的项可以分为两类:绝对位置信息(前四项)和相对位置信息(最后一项)。下面,我们将更深入地分析这些项的含义,并通过具体例子阐释其作用。
1.3.1 绝对位置信息
绝对位置信息由以下四项表示:
-
p m T ∂ f ∂ x m p_m^T \frac{\partial f}{\partial x_m} pmT∂xm∂f 和 p n T ∂ f ∂ x n p_n^T \frac{\partial f}{\partial x_n} pnT∂xn∂f(一阶项)
-
p m T ∂ 2 f ∂ x m 2 p m p_m^T \frac{\partial^2 f}{\partial x_m^2} p_m pmT∂xm2∂2fpm 和 p n T ∂ 2 f ∂ x n 2 p n p_n^T \frac{\partial^2 f}{\partial x_n^2} p_n pnT∂xn2∂2fpn(二阶单位置项)
数学含义
-
一阶项:
-
∂ f ∂ x m \frac{\partial f}{\partial x_m} ∂xm∂f 是模型输出 f f f 对位置 m m m 的词元嵌入 x m x_m xm 的梯度,表示输出对该词元的线性敏感度。
-
p m T ∂ f ∂ x m p_m^T \frac{\partial f}{\partial x_m} pmT∂xm∂f 是位置编码向量 p m p_m pm 与梯度的点积,反映了位置 m m m 的编码对输出的直接调整。
-
这类似于为每个位置的词元添加一个独立的"位置偏移",使模型感知到"这个词元在位置 m m m"。
-
-
二阶单位置项:
-
∂ 2 f ∂ x m 2 \frac{\partial^2 f}{\partial x_m^2} ∂xm2∂2f 是模型输出的二阶导数,表示输出对 x m x_m xm 的非线性影响(曲率)。
-
p m T ∂ 2 f ∂ x m 2 p m p_m^T \frac{\partial^2 f}{\partial x_m^2} p_m pmT∂xm2∂2fpm 是位置编码 p m p_m pm 通过二阶导数对输出的调整,增强了对单一位置的建模。
-
这可以看作是对位置 m m m 的"深度调整",进一步强调其绝对位置特性。
-
特点
-
这些项仅依赖单一位置的编码( p m p_m pm 或 p n p_n pn),不涉及其他位置的交互,因此反映了绝对位置信息。
-
它们为每个词元提供了一个独立的位置标识,使模型能够区分不同位置的词元。
例子
-
场景:考虑一个简单的语言模型,输入序列为"猫追狗"(位置 m = 1 , n = 2 , k = 3 m=1, n=2, k=3 m=1,n=2,k=3),词嵌入分别为 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3,位置编码为 p 1 , p 2 , p 3 p_1, p_2, p_3 p1,p2,p3(如三角函数编码)。
-
绝对位置作用:
-
p 1 T ∂ f ∂ x 1 p_1^T \frac{\partial f}{\partial x_1} p1T∂x1∂f 调整"猫"(位置1)的输出贡献,可能使模型更关注句首词。
-
p 2 T ∂ 2 f ∂ x 2 2 p 2 p_2^T \frac{\partial^2 f}{\partial x_2^2} p_2 p2T∂x22∂2fp2 增强"追"(位置2)的非线性影响,强调动词的独立作用。
-
-
实际效果:模型通过这些项区分"猫"在位置1和"狗"在位置3,即使内容相同,也能感知顺序差异。
与绝对位置编码的关系
- 绝对位置编码(如三角函数编码或可训练编码)主要通过这些单位置项起作用。它们为每个位置赋予独特标识(如 p m p_m pm),使模型在输入层感知绝对位置。
1.3.2 相对位置信息
相对位置信息由最后一项表示:
- p m T ∂ 2 f ∂ x m ∂ x n p n p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n pmT∂xm∂xn∂2fpn(二阶交互项)
数学含义
-
∂ 2 f ∂ x m ∂ x n \frac{\partial^2 f}{\partial x_m \partial x_n} ∂xm∂xn∂2f 是模型输出对位置 m m m 和 n n n 的词元嵌入 x m x_m xm 和 x n x_n xn 的混合二阶导数,表示两位置之间的相互影响。
-
p m T ∂ 2 f ∂ x m ∂ x n p n p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n pmT∂xm∂xn∂2fpn 是位置编码 p m p_m pm 和 p n p_n pn 与混合导数的交互,反映了位置 m m m 和 n n n 的联合效应。
-
这项捕捉了相对位置信息,因为它依赖于 p m p_m pm 和 p n p_n pn 之间的关系,通常与两位置的相对距离或顺序相关。
特点
-
与绝对位置项不同,这一项涉及两个位置的交互,体现了位置之间的相对关系。
-
在自注意力机制中,这对应于词元对(如 m m m 和 n n n)的注意力权重如何受相对位置影响。
例子
-
场景:继续使用"猫追狗",假设 m = 1 m=1 m=1(“猫”), n = 2 n=2 n=2(“追”)。
-
相对位置作用:
-
p 1 T ∂ 2 f ∂ x 1 ∂ x 2 p 2 p_1^T \frac{\partial^2 f}{\partial x_1 \partial x_2} p_2 p1T∂x1∂x2∂2fp2 表示"猫"和"追"之间的交互效应。
-
在自注意力中,这可能影响注意力权重 a 12 = softmax ( q 1 T k 2 d k ) a_{12} = \text{softmax}\left( \frac{q_1^T k_2}{\sqrt{d_k}} \right) a12=softmax(dkq1Tk2),使模型更关注主语和动词的邻近关系。
-
-
实际效果:
- 如果序列变为"狗追猫",位置 m = 1 m=1 m=1(“狗”)和 n = 2 n=2 n=2(“追”)的相对关系不变,但具体编码 p m p_m pm 和 p n p_n pn 的值不同,交互项随之调整,反映新的顺序。
与相对位置编码的关系
-
相对位置编码(如Transformer-XL、RoPE)直接通过这种交互项建模位置关系。例如:
-
在注意力分数中加入相对位置偏置 R m − n R_{m-n} Rm−n,使 a m n a_{mn} amn 依赖 m m m 和 n n n 的距离。
-
这与 p m T ∂ 2 f ∂ x m ∂ x n p n p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n pmT∂xm∂xn∂2fpn 的形式一致,明确捕捉相对位置效应。
-
1.3.3 更深入的解释
绝对位置信息的作用机制
-
独立性:单位置项(如 p m T ∂ f ∂ x m p_m^T \frac{\partial f}{\partial x_m} pmT∂xm∂f)为每个词元提供独立调整,使模型感知"这是第 m m m 个位置"。
-
Transformer中的体现:
-
输入变为 x m + p m x_m + p_m xm+pm,自注意力计算 q m = ( x m + p m ) W Q q_m = (x_m + p_m) W_Q qm=(xm+pm)WQ,键和值类似。
-
注意力分数 q m T k n q_m^T k_n qmTkn 包含 p m T W Q W K T x n p_m^T W_Q W_K^T x_n pmTWQWKTxn,独立调整每个位置的贡献。
-
-
局限:绝对位置编码需通过模型学习间接推断相对关系,效率较低。
相对位置信息的作用机制
-
交互性:交互项(如 p m T ∂ 2 f ∂ x m ∂ x n p n p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n pmT∂xm∂xn∂2fpn)直接建模位置 m m m 和 n n n 的关系。
-
Transformer中的体现:
-
在自注意力中, q m T k n = ( x m + p m ) T W Q W K T ( x n + p n ) q_m^T k_n = (x_m + p_m)^T W_Q W_K^T (x_n + p_n) qmTkn=(xm+pm)TWQWKT(xn+pn),展开后包含 p m T W Q W K T p n p_m^T W_Q W_K^T p_n pmTWQWKTpn。
-
这一项依赖 p m p_m pm 和 p n p_n pn 的交互,与相对距离相关,直接影响 a m n a_{mn} amn。
-
-
优势:相对位置编码更自然地捕捉语言中的相对顺序,如动词和宾语的距离。
结合实例
-
绝对位置编码:
-
三角函数编码为位置1(“猫”)生成 p 1 = [ sin ( 1 / 1000 0 2 i / d ) , cos ( 1 / 1000 0 2 i / d ) ] p_1 = [\sin(1/10000^{2i/d}), \cos(1/10000^{2i/d})] p1=[sin(1/100002i/d),cos(1/100002i/d)],独立标识其位置。
-
模型通过 p 1 T ∂ f ∂ x 1 p_1^T \frac{\partial f}{\partial x_1} p1T∂x1∂f 调整"猫"的权重。
-
-
相对位置编码:
-
Transformer-XL中, p 1 T W Q W K T p 2 p_1^T W_Q W_K^T p_2 p1TWQWKTp2 表示"猫"和"追"的相对位置效应,调整注意力权重。
-
若距离为1(如邻近),交互项增强关联;若距离变大,效应减弱。
-
1.3.4 总结与意义
-
绝对位置信息:
-
通过单位置项(如 p m T ∂ f ∂ x m p_m^T \frac{\partial f}{\partial x_m} pmT∂xm∂f)为每个词元提供独立标识。
-
对应绝对位置编码(如三角函数编码),在输入层打破置换不变性。
-
示例:区分"猫"在位置1和"狗"在位置3。
-
-
相对位置信息:
-
通过交互项(如 p m T ∂ 2 f ∂ x m ∂ x n p n p_m^T \frac{\partial^2 f}{\partial x_m \partial x_n} p_n pmT∂xm∂xn∂2fpn)捕捉位置间关系。
-
对应相对位置编码(如RoPE),直接调整注意力权重。
-
示例:增强"猫"和"追"的邻近关系。
-
-
综合效果:
- 绝对位置编码奠定基础,相对位置编码优化关系建模,二者共同使Transformer感知顺序,适应复杂语言任务。
1.4 所有位置编码都是为了解决置换不变性吗?
位置编码的主要目的是解决置换不变性,但并非其唯一作用。不同的位置编码方法在实现这一目标的同时,还可能带来其他效果或改变模型行为:
-
是的,解决置换不变性是核心目标:
- 无论是绝对位置编码还是相对位置编码,其根本目的是让模型感知词元顺序,打破自注意力的对称性。
- 例如,三角函数编码、可训练编码、RoPE等都旨在引入位置依赖性。
-
除此之外的额外作用:
- 外推性(Extrapolation):
- 定义:外推性是指模型在处理比训练时见过的序列更长的输入时,依然能够保持良好性能的能力。也就是说,模型能够"外推"到训练数据分布之外的序列长度。
- 某些位置编码(如三角函数编码、相对位置编码)具有良好的外推性,能处理比训练时更长的序列。可训练位置编码则受限于预定义长度。
- 计算效率:
- 绝对位置编码(如可训练编码)增加存储需求,相对位置编码(如RoPE)可能增加注意力计算的开销。
- 任务适应性:
- 相对位置编码更适合自然语言处理任务,因为语言中相对顺序通常比绝对位置更重要(如句法关系)。
- 模型表达能力:
- 相对位置编码(如Transformer-XL)增强了对长距离依赖的捕捉能力;RoPE结合绝对和相对位置优势,提升线性注意力的性能。
- 创新性设计:
- 一些新型位置编码(如递归位置编码FLOATER)不仅解决顺序问题,还通过动态系统建模增强长序列处理能力。
- 外推性(Extrapolation):
1.5 总结
- 如何解决置换不变性:
- 位置编码通过引入位置信息打破自注意力的对称性。绝对位置编码为每个词元添加独特标识,相对位置编码直接建模词元间关系。
- 数学表现:
- 置换不变性体现为 Attention ( P X ) = P ⋅ Attention ( X ) \text{Attention}(P X) = P \cdot \text{Attention}(X) Attention(PX)=P⋅Attention(X)。位置编码使输入或注意力计算依赖位置,置换后结果不再等价。
- Taylor展开显示其包含绝对位置项和相对位置项。
- 是否只为置换不变性:
- 核心目标是解决置换不变性,但也带来外推性、效率、适应性等额外改变。
2. 注意力机制的查询与位置向量:理解它们的关系与作用过程
2.1 基础概念回顾
2.1.1 注意力机制的核心组件
注意力机制基于三种向量:查询(Query)向量、键(Key)向量和值(Value)向量。这些向量通过以下方式生成:
- 输入嵌入:每个词元首先被转换为嵌入向量 x i x_i xi
- 线性变换:通过权重矩阵将嵌入向量投影为查询、键和值
- 查询向量: q i = x i W Q q_i = x_i W_Q qi=xiWQ
- 键向量: k i = x i W K k_i = x_i W_K ki=xiWK
- 值向量: v i = x i W V v_i = x_i W_V vi=xiWV
2.1.2 位置编码的角色
位置编码为每个位置生成一个向量表示,使模型能够理解序列中词元的顺序。基本形式是:
- 对于位置 p p p,生成位置编码向量 P E ( p ) PE(p) PE(p)
- 将位置编码加到输入嵌入: x i + P E ( i ) x_i + PE(i) xi+PE(i)
2.2 位置向量与查询向量的关系
现在,让我解释位置向量如何影响查询向量,以及整个注意力计算过程。这里我将采用旋转位置编码(RoPE)作为例子,因为它最直接地展示了位置信息与查询/键向量的交互。
2.2.1 标准注意力机制中的作用过程
在标准的Transformer中(使用加性位置编码,如正弦位置编码),过程如下:
-
位置信息融入:
- 将位置编码加到输入嵌入: x ~ i = x i + P E ( i ) \tilde{x}_i = x_i + PE(i) x~i=xi+PE(i)
- 生成查询向量: q i = x ~ i W Q = ( x i + P E ( i ) ) W Q q_i = \tilde{x}_i W_Q = (x_i + PE(i)) W_Q qi=x~iWQ=(xi+PE(i))WQ
- 生成键向量: k j = x ~ j W K = ( x j + P E ( j ) ) W K k_j = \tilde{x}_j W_K = (x_j + PE(j)) W_K kj=x~jWK=(xj+PE(j))WK
-
注意力计算:
- 计算注意力分数: a i j = q i ⋅ k j d k a_{ij} = \frac{q_i \cdot k_j}{\sqrt{d_k}} aij=dkqi⋅kj
- 应用softmax归一化: α i j = softmax ( a i j ) \alpha_{ij} = \text{softmax}(a_{ij}) αij=softmax(aij)
- 加权求和值向量: o i = ∑ j α i j v j o_i = \sum_j \alpha_{ij} v_j oi=∑jαijvj
在这个过程中,位置信息间接地影响了查询和键向量,从而影响注意力分数的计算。
2.2.2 RoPE中的作用过程
在旋转位置编码中,位置信息与查询和键向量的交互更加直接和明确:
-
位置旋转应用:
- 生成基础查询向量: q i = x i W Q q_i = x_i W_Q qi=xiWQ
- 应用位置旋转: q ^ i = R θ , i q i \hat{q}_i = R_{\theta, i} q_i q^i=Rθ,iqi
- 同样地,对键向量: k ^ j = R θ , j k j \hat{k}_j = R_{\theta, j} k_j k^j=Rθ,jkj
其中 R θ , p R_{\theta, p} Rθ,p 是基于位置 p p p 的旋转矩阵。
-
注意力计算:
- 计算旋转后的注意力分数: a i j = q ^ i ⋅ k ^ j = q i ⋅ R θ , i − j k j a_{ij} = \hat{q}_i \cdot \hat{k}_j = q_i \cdot R_{\theta, i-j} k_j aij=q^i⋅k^j=qi⋅Rθ,i−jkj
- 应用softmax归一化: α i j = softmax ( a i j ) \alpha_{ij} = \text{softmax}(a_{ij}) αij=softmax(aij)
- 加权求和值向量: o i = ∑ j α i j v j o_i = \sum_j \alpha_{ij} v_j oi=∑jαijvj
注意关键的数学性质: q ^ i ⋅ k ^ j = q i ⋅ R θ , i − j k j \hat{q}_i \cdot \hat{k}_j = q_i \cdot R_{\theta, i-j} k_j q^i⋅k^j=qi⋅Rθ,i−jkj。这表明旋转后的点积直接编码了相对位置 i − j i-j i−j,使模型能够明确感知词元间的相对位置关系。
2.3 详细的作用过程示例
让我通过一个具体例子来说明位置向量和查询向量如何协同工作。假设我们处理一个简单的句子:“人工智能正在快速发展”。
2.3.1 步骤1: 输入处理与位置融合
以RoPE为例,处理流程如下:
-
词元嵌入:每个词元转换为嵌入向量
- “人工” → x 0 x_0 x0
- “智能” → x 1 x_1 x1
- “正在” → x 2 x_2 x2
- “快速” → x 3 x_3 x3
- “发展” → x 4 x_4 x4
-
生成查询和键向量:
- q 0 = x 0 W Q q_0 = x_0 W_Q q0=x0WQ, k 0 = x 0 W K k_0 = x_0 W_K k0=x0WK (位置0)
- q 1 = x 1 W Q q_1 = x_1 W_Q q1=x1WQ, k 1 = x 1 W K k_1 = x_1 W_K k1=x1WK (位置1)
- … 以此类推
-
应用位置旋转:
- q ^ 0 = R θ , 0 q 0 \hat{q}_0 = R_{\theta, 0} q_0 q^0=Rθ,0q0, k ^ 0 = R θ , 0 k 0 \hat{k}_0 = R_{\theta, 0} k_0 k^0=Rθ,0k0
- q ^ 1 = R θ , 1 q 1 \hat{q}_1 = R_{\theta, 1} q_1 q^1=Rθ,1q1, k ^ 1 = R θ , 1 k 1 \hat{k}_1 = R_{\theta, 1} k_1 k^1=Rθ,1k1
- … 以此类推
在这个过程中,每个查询和键向量都通过位置特定的旋转变换,将位置信息编入向量表示中。
2.3.2 步骤2: 注意力计算
考虑位置2的词元"正在"如何与其他词元交互:
-
计算注意力分数:对于每个位置 j j j,计算 a 2 j = q ^ 2 ⋅ k ^ j a_{2j} = \hat{q}_2 \cdot \hat{k}_j a2j=q^2⋅k^j
- 与"人工"的注意力: a 20 = q ^ 2 ⋅ k ^ 0 = q 2 ⋅ R θ , 2 − 0 k 0 = q 2 ⋅ R θ , 2 k 0 a_{20} = \hat{q}_2 \cdot \hat{k}_0 = q_2 \cdot R_{\theta, 2-0} k_0 = q_2 \cdot R_{\theta, 2} k_0 a20=q^2⋅k^0=q2⋅Rθ,2−0k0=q2⋅Rθ,2k0
- 与"智能"的注意力: a 21 = q ^ 2 ⋅ k ^ 1 = q 2 ⋅ R θ , 2 − 1 k 1 = q 2 ⋅ R θ , 1 k 1 a_{21} = \hat{q}_2 \cdot \hat{k}_1 = q_2 \cdot R_{\theta, 2-1} k_1 = q_2 \cdot R_{\theta, 1} k_1 a21=q^2⋅k^1=q2⋅Rθ,2−1k1=q2⋅Rθ,1k1
- 与自身的注意力: a 22 = q ^ 2 ⋅ k ^ 2 = q 2 ⋅ R θ , 2 − 2 k 2 = q 2 ⋅ R θ , 0 k 2 = q 2 ⋅ k 2 a_{22} = \hat{q}_2 \cdot \hat{k}_2 = q_2 \cdot R_{\theta, 2-2} k_2 = q_2 \cdot R_{\theta, 0} k_2 = q_2 \cdot k_2 a22=q^2⋅k^2=q2⋅Rθ,2−2k2=q2⋅Rθ,0k2=q2⋅k2
- 与"快速"的注意力: a 23 = q ^ 2 ⋅ k ^ 3 = q 2 ⋅ R θ , 2 − 3 k 3 = q 2 ⋅ R θ , − 1 k 3 a_{23} = \hat{q}_2 \cdot \hat{k}_3 = q_2 \cdot R_{\theta, 2-3} k_3 = q_2 \cdot R_{\theta, -1} k_3 a23=q^2⋅k^3=q2⋅Rθ,2−3k3=q2⋅Rθ,−1k3
- 与"发展"的注意力: a 24 = q ^ 2 ⋅ k ^ 4 = q 2 ⋅ R θ , 2 − 4 k 4 = q 2 ⋅ R θ , − 2 k 4 a_{24} = \hat{q}_2 \cdot \hat{k}_4 = q_2 \cdot R_{\theta, 2-4} k_4 = q_2 \cdot R_{\theta, -2} k_4 a24=q^2⋅k^4=q2⋅Rθ,2−4k4=q2⋅Rθ,−2k4
-
应用softmax: α 2 j = softmax ( a 2 j ) \alpha_{2j} = \text{softmax}(a_{2j}) α2j=softmax(a2j)
这将注意力分数归一化为概率分布,表示"正在"对每个位置的关注程度。
-
加权聚合值向量: o 2 = ∑ j α 2 j v j o_2 = \sum_j \alpha_{2j} v_j o2=∑jα2jvj
这一步合成了与"正在"相关联的信息,同时考虑了位置关系。
2.3.3 关键观察
在上面的例子中,我们可以观察到几个重要特点:
-
相对位置的直接编码:注意力分数 a 2 j a_{2j} a2j 直接依赖于相对位置 2 − j 2-j 2−j,通过 R θ , 2 − j R_{\theta, 2-j} Rθ,2−j 编码。
-
自注意力的特殊性:当 i = j i=j i=j 时(词元与自身的注意力),旋转矩阵变为单位矩阵 R θ , 0 R_{\theta, 0} Rθ,0,使得 a i i = q i ⋅ k i a_{ii} = q_i \cdot k_i aii=qi⋅ki,这是标准内积。
-
前后关系的区分:
- 前面的词元(如"人工"和"智能")通过正相对位置 ( + 2 , + 1 ) (+2, +1) (+2,+1) 编码
- 后面的词元(如"快速"和"发展")通过负相对位置 ( − 1 , − 2 ) (-1, -2) (−1,−2) 编码
这使模型能够区分前后文关系。
2.4 位置向量如何影响注意力分布
位置编码对注意力分布的影响是多方面的,这种影响通过以下机制实现:
2.4.1 相对距离敏感性
在RoPE中,旋转矩阵 R θ , i − j R_{\theta, i-j} Rθ,i−j 编码相对距离 i − j i-j i−j,这使得模型能够学习距离敏感的注意力模式:
- 近距离偏好:模型可以学习给予临近词元更高的注意力
- 语法依赖:捕捉如主谓关系等可能跨越多个位置的结构
- 长距离关联:识别远距离的相关信息,如代词与其指代对象
2.4.2 方向感知
RoPE的一个关键特性是它能区分正负相对位置,即前文和后文:
- 当 i > j i > j i>j 时(关注前面的内容),旋转矩阵是 R θ , + ( i − j ) R_{\theta, +(i-j)} Rθ,+(i−j)
- 当 i < j i < j i<j 时(关注后面的内容),旋转矩阵是 R θ , − ( j − i ) R_{\theta, -(j-i)} Rθ,−(j−i)
这使模型能够学习方向敏感的注意力模式,例如在英语中,形容词通常在名词前面,而在汉语中,形容词的位置可能更灵活。
2.4.3 频率差异化
RoPE使用不同频率的旋转,对应于向量的不同维度:
- 高频组件(向量的前几对维度)对小的位置变化敏感,有助于捕捉局部结构
- 低频组件(向量的后几对维度)对大的位置变化敏感,有助于捕捉全局结构
这种多尺度表示使模型能够同时关注局部语法关系和全局文档结构。
2.5 注意力查询和位置向量的共同演化
在训练过程中,注意力机制的查询向量和位置编码不是静态的,而是通过反向传播共同演化:
-
查询投影学习:权重矩阵 W Q W_Q WQ 学习如何从输入嵌入生成有效的查询向量
-
位置解释学习:模型学习如何解释位置编码提供的位置信息
-
位置敏感的内容识别:模型逐渐发展出位置感知的表示,使相同词在不同位置可以有不同的解释
这种共同演化使模型能够形成复杂的注意力模式,例如:
- 在句子开头关注主语
- 在动词后关注宾语
- 在代词处回溯寻找指代对象
2.6 实际应用中的表现
在实际应用中,位置编码与注意力查询的交互表现出丰富的模式:
2.6.1 例子:情感分析任务
考虑句子:“这部电影很无聊,但演员表演精彩”。
在没有位置编码的情况下,模型可能无法区分"无聊"和"精彩"分别修饰什么,导致情感判断混淆。
有了位置编码,注意力查询能够正确关联:
- “无聊"与"电影”
- “精彩"与"演员表演”
- "但"作为转折关系的信号
这种正确的关联是通过位置编码与查询向量的交互实现的。
2.6.2 例子:翻译任务
在翻译英语到中文时,位置编码帮助模型处理两种语言不同的语法结构:
英语:“The red car is parked outside the building.” 中文:“红色的汽车停在建筑物外面。”
位置编码使模型能够学习:
- 英语中形容词在名词前(“red car”)
- 英语中使用被动语态的位置结构
- 中文中表达位置关系的不同方式
这种跨语言的结构映射依赖于位置编码与注意力机制的紧密协作。
参考
更详细的分类和介绍
- 苏神科学空间
- https://0809zheng.github.io/2022/07/01/posencode.html
- Rope解析