本文主要介绍下面三种技巧:
- 使用
__restrict__让编译器放心地优化指针访存 - 想办法让同一个 Warp 中的线程的访存 Pattern 尽可能连续,以利用 Memory coalescing
- 使用 Shared memory
0. 弄清Kernael函数是Compute-bound 还是 Memory-bound
先摆出一个知识点,一般来说,Compute-bound 的 Kernel 不太常见,常见的 Compute-bound 的 Kernel 可能只有矩阵乘法与卷积核比较大的卷积,大多数都是Memory-bound,所以下面我们主要关注如何优化访存。
在经典的冯诺依曼架构下,ALU (Arithmetic Logic Unit,计算逻辑单元,可以简单理解为加法器、乘法器等) 要从内存中取操作数,进行对应的计算(如乘法),并写回内存。所以,计算速度会受到两个因素的限制:ALU 进行计算的速度,与内存的存取速度。如果一个程序的运行速度瓶颈在于前者,那么称其为 Compute-bound 的;如果瓶颈在于后者,那么称其为 Memory-bound 的。
由于 CPU 中运算单元较少,且 CPU 具有多级缓存,所以空间连续性、时间连续性较好的程序在 CPU 上一般是 Compute-bound 的。而 GPU 则恰恰相反:GPU 的核心的规模一般很大,比如 RTX 4090 可以在一秒内做 82.58T 次 float16 运算(暂不考虑 Tensor core),但其内存带宽只有 1TB/s,每秒只能传输 0.5T 个 float16。这便导致 GPU 上的操作更可能会受到内存带宽的限制,成为 Memory-bound。
如何估测一个 CUDA Kernel 是 Compute-bound 还是 Memory-bound 呢?我们可以计算它的 “算存比”,也即,
算存比 = 计算次数/访存次数
并将其与 GPU 的 每秒能做的运算次数/每秒能做的访存次数做比较。
例子:
__global__ void pointwise_add_kernel(int* C, const int* A, const int* B, int n) {
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x)
C[i] = A[i] + B[i];
}对于上面的 pointwise_add_kernel,其需要访问 3N 次内存(读取A[i]、读取B[i]、写入C[i]),同时做 N次加法,所以其存算比为 N/3N=1/3
对于RTX 4090 可以在一秒内做 82.58T 次 float16 运算(暂不考虑 Tensor core),但其内存带宽只有 1TB/s,每秒只能传输 0.5T 个 float16。起存算比为 82.58/0.5=165.16
因此这个 pointwise_add_kernel为 Memory-bound。
1. __restrict__
restrict关键字用于修饰指针。通过加上restrict关键字,编程者可提示编译器:在该指针的生命周期内,其指向的对象不会被别的指针所引用。
大家还记得什么是 Pointer aliasing 嘛?简单来说,下面两段代码并不是等价的:
void f1(int* x, int* y) {
*x += *y;
*x += *y;
}
void f2(int* x, int* y) {
*x += 2*(*y);
}
这是因为,x 和 y 两个指针可能指向相同的内存。考虑 f(x, x),第一段代码将把 *x 变为 4(*x),而第二段代码则会把 *x 变为 3(*x)。
Pointer aliasing 可能会抑制编译器做出某些优化。比如在上面的代码中,f1() 需要 5 次访存而 f2() 仅需三次,后者更优。但由于编译器并不能假设 x 和 y ,它不敢做这个优化。
所以,我们需要 “显式地” 告诉编译器,两个指针不会指向相同的内存地址(准确来说,应该是 “改变一个指针指向的地址的数据,不会影响到通过其他指针读取的数据”),从而让编译器“放心地” 做出优化。nvcc 支持一个关键字,叫做 __restrict__,加上它,编译器就可以放心地把指针指向的值存在寄存器里,而不是一次又一次地访存,进而提高了性能。
我们可以对比一下示例代码中的 gemm_gpu_mult_block_no_restrict.cu 与 gemm_gpu_mult_block.cu 的性能。在 4090 上,前者平均耗时 40420.75,后者平均耗时 3988.38。可以看出,性能提升幅度不容小觑。
为了验证性能下降确实是由于没有了 __restrict__ 关键字后的额外访存带来的,我们可以对比 gemm_gpu_mult_block.cu 与 gemm_gpu_mult_block_no_restrict_reg.cu 的性能。后者虽然没有使用 __restrict__ 关键字,但它把中间的累加结果存在了变量中,而不是每一次都写回 C 数组。在 4090 上,二者的性能非常相似。这说明,在缺少 __restrict__ 关键字的时候,代码需要进行许多不必要的访存,进而拖慢了速度。
2. Memory Coalescing内存合并
Memory Coalescing主要目的就是:充分利用内存带宽。
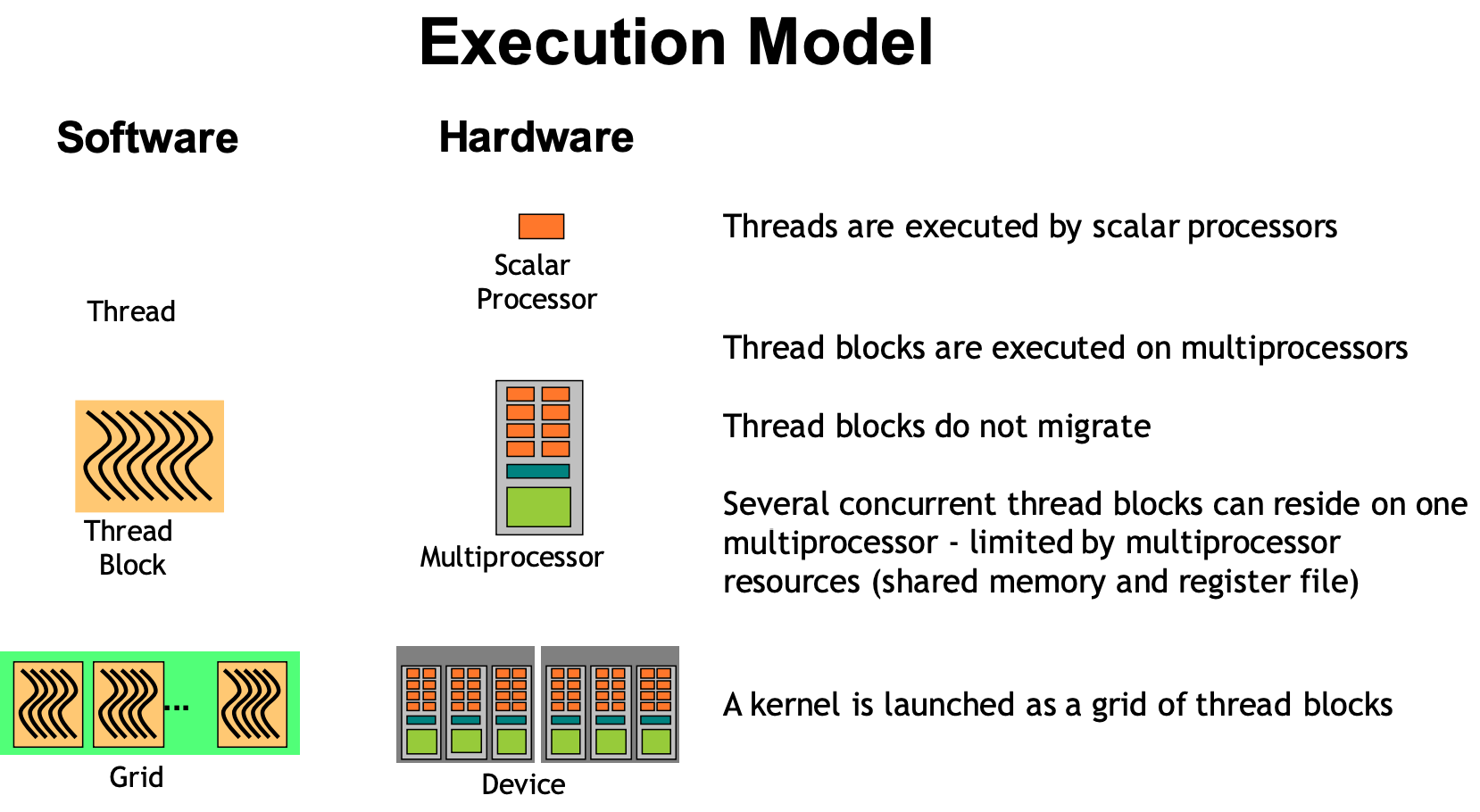
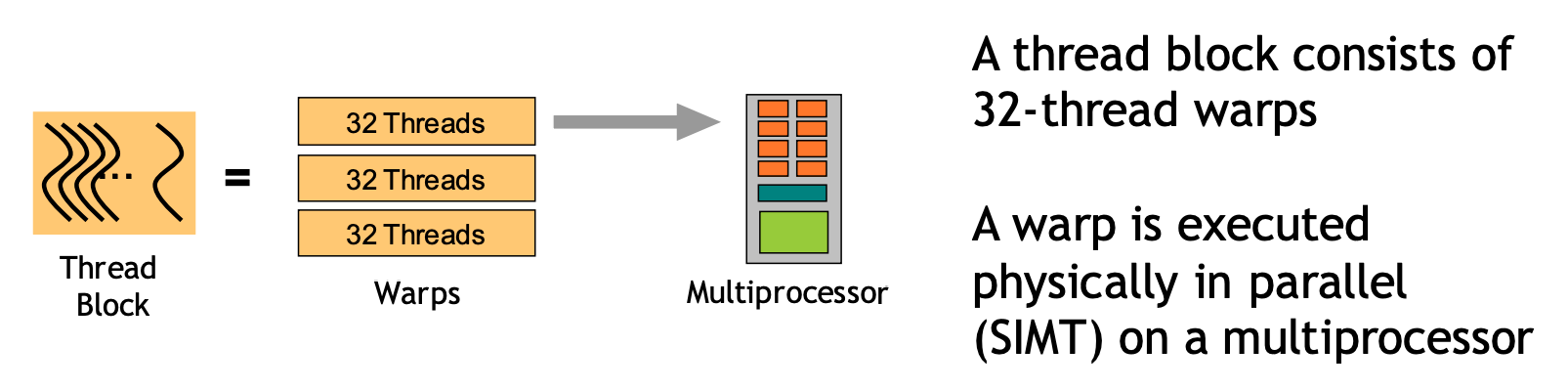
我们先来了解GPU的调度方式。Grid 里包含若干 Thread block,每个 Thread block 则又包含若干 Thread,那么这些 Thread 是如何被调度的呢?它们被按编号分成了若干组,每一组中有 32 个 Thread(即,线程 0 ~ 31 为第一组,32 ~ 63 为第二组,依次类推),这样的 “组” 便被叫做 Warp。
GPU 的调度是以 Warp 作为基本单位的。每个时钟周期内,同一个 Warp 中的所有线程都会执行相同的指令。
(注意,thread, block, grid是软件概念,warp是硬件概念,如以下示意图所示)
(1)Transaction 的基本要求
-
长度为 32 个 Byte:在 GPU 的内存访问中,每个事务(Transaction)的大小被固定为 32 字节。这是硬件设计上的一种规定,用于优化内存访问的效率。
-
开始地址是 32 的倍数:事务(Transaction)的起始地址必须是 32 字节对齐的。也就是说,如果事务的起始地址是 A,那么 Amod32=0。这种对齐要求可以简化硬件设计,并提高内存访问的效率。
(2)Warp 中线程的内存访问模式
-
Warp:在 GPU 中,线程(Thread)是以 Warp 为单位进行调度的。一个 Warp 通常包含多个线程(例如 32 个线程)。
-
线程的内存访问范围:
-
如果一个 Warp 中的第 i 个线程要访问地址范围为 4i∼4i+3 的内存,这意味着每个线程访问 4 字节的数据。
-
由于每个事务(Transaction)的大小是 32 字节,而每个线程访问 4 字节,因此一个 Warp 中的 32 个线程总共需要 4 个事务来完成所有线程的内存访问。因为 32×4 字节 = 128 字节,而 128 字节正好可以分成 4 个 32 字节的事务。
-
然而,内存带宽是有上限的,且每一个 Transaction 的大小都是 32 Byte,这注定了每一秒 GPU 核心可以发起的 Transaction 数量是有上限的。
接下来请阅读 CUDA Best Practices,了解 Memory coalescing 在一个具体的例子中的优化效果。
总之,我们需要尽量保证同一个 Warp 中每一个 Thread 的访存是 coalesced 的,以充分利用内存带宽。
3. Shared Memory
Share memory 既可以用来在同一个 Thread block 的不同 Thread 之间共享数据(最常见的用法是 Reduction),也可以用来优化访存性能。我们现在主要关注后者。
在学习 Shared memory 之前,我们需要先了解一下 CUDA 的内存模型:
CUDA 中大致有这几种内存:
- Global Memory:俗称显存,位于 GPU 核心外部,很大(比如 A100 有 80GB),但是带宽很有限
- L2 Cache:位于 GPU 核心内部,是显存的缓存,程序不能直接使用
- Register:寄存器,位于 GPU 核心内部,Thread 可以直接调用
- Shared memory:位于 GPU 核心内部,每个 Thread block 中的所有 Thread 共用同一块 Shared memory(因此,Shared memory 可以用来在同一个 Thread block 的不同 Thread 之间共享数据),并且带宽极高(因此,Shared memory 可以用来优化性能)。
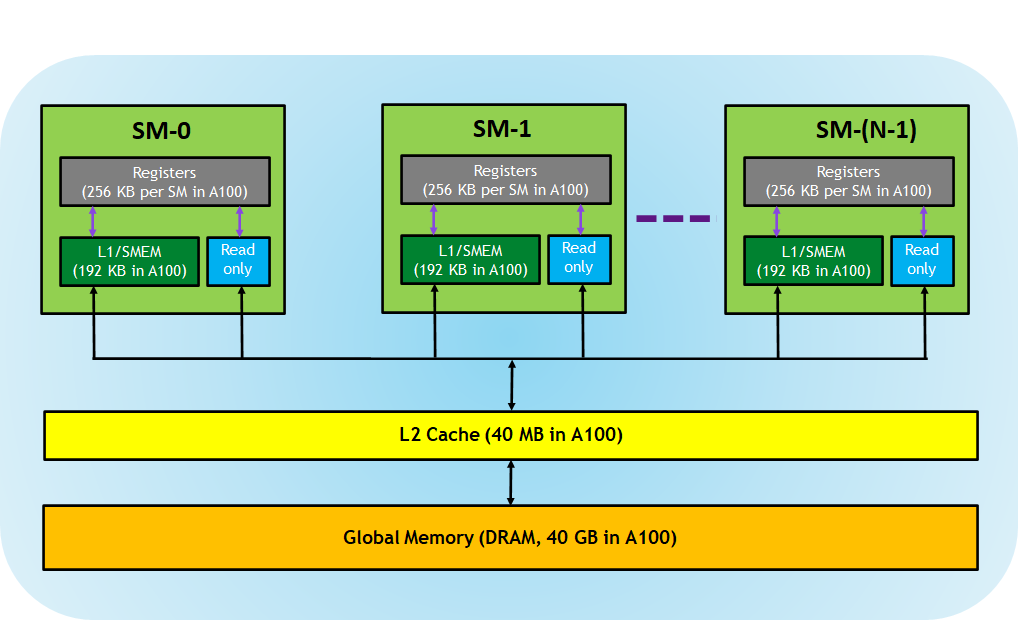
我们还是以矩阵乘法为例。在上面的 gemm_gpu_mult_block.cu 中,为了计算大小分别为 n×k 与 k×m的两个矩阵乘法,我们一共访问了大约 2nmk次内存。这十分不合算,因为三个矩阵加起来也就只有 nk+km+nm个元素。
Tiling
我们尝试使用 Shared memory 来优化矩阵乘法。具体的,我们使用一种叫做 Tiling 的技术。
Tiling 是一种将矩阵划分为小块(Tile)的技术,每个线程块处理一个 Tile。通过这种方式,可以将矩阵的子块加载到 Shared Memory 中,减少全局内存的访问次数,并提高内存访问的局部性。
接下来请阅读这篇文章Tiled Matrix Multiplication(里面有可视化图片)。
在阅读上面那篇文章之后,请阅读示例代码中的 gemm_gpu_tiling.cu,看看我如何实现 Tiling 版本的矩阵乘法。在 4090 上,gemm_gpu_mult_block 耗时 3988.38 us,gemm_gpu_tiling 耗时 311.38 us,性能提升约 10 倍。
#include "gemm_gpu_tiling.h"
#include <cassert>
#include <cuda_runtime_api.h>
constexpr int TILE_SIZE = 32;
// gemm_gpu_tiling - GEMM on GPU, using tiling & shared memory to optimize
// global memory accesses
__global__
void gemm_gpu_tiling_kernel(
int* __restrict__ C, // [n, m], on gpu
const int* __restrict__ A, // [n, k], on gpu
const int* __restrict__ B, // [k, m], on gpu
const int n,
const int m,
const int k
) {
// We copy the tile from a/b into shared memory, and then do the calculation
__shared__ int a_tile[TILE_SIZE][TILE_SIZE];
__shared__ int b_tile[TILE_SIZE][TILE_SIZE];
int my_c_result = 0;
for (int tile_index = 0; tile_index < k/TILE_SIZE; ++tile_index) {
// Step 1. Load the tile from a/b into a/b_tile
a_tile[threadIdx.y][threadIdx.x] = A[(blockIdx.x*TILE_SIZE + threadIdx.y)*k + (tile_index*TILE_SIZE + threadIdx.x)];
b_tile[threadIdx.y][threadIdx.x] = B[(tile_index*TILE_SIZE + threadIdx.y)*m + (blockIdx.y*TILE_SIZE + threadIdx.x)];
__syncthreads();
// Step 2. Calculate the contribution to my_c_result
for (int i = 0; i < TILE_SIZE; ++i) {
my_c_result += a_tile[threadIdx.y][i] * b_tile[i][threadIdx.x];
}
__syncthreads();
}
// Step 3. Store my_c_result
C[(blockIdx.x*TILE_SIZE + threadIdx.y)*m + (blockIdx.y*TILE_SIZE + threadIdx.x)] = my_c_result;
}
void gemm_gpu_tiling(
int* __restrict__ C, // [n, m], on gpu
const int* __restrict__ A, // [n, k], on gpu
const int* __restrict__ B, // [k, m], on gpu
const int n,
const int m,
const int k
) {
assert (n % TILE_SIZE == 0);
assert (m % TILE_SIZE == 0);
assert (k % TILE_SIZE == 0);
dim3 grid_dim = dim3(n / TILE_SIZE, m / TILE_SIZE);
dim3 block_dim = dim3(TILE_SIZE, TILE_SIZE);
gemm_gpu_tiling_kernel<<<grid_dim, block_dim>>>(C, A, B, n, m, k);
}
参考资料:
主要参考:CUDA 编程入门 - HPC Wiki
https://github.com/interestingLSY/CUDA-From-Correctness-To-Performance-Code
https://zhuanlan.zhihu.com/p/349726808
https://hackmd.io/@yaohsiaopid/ryHNKkxTr