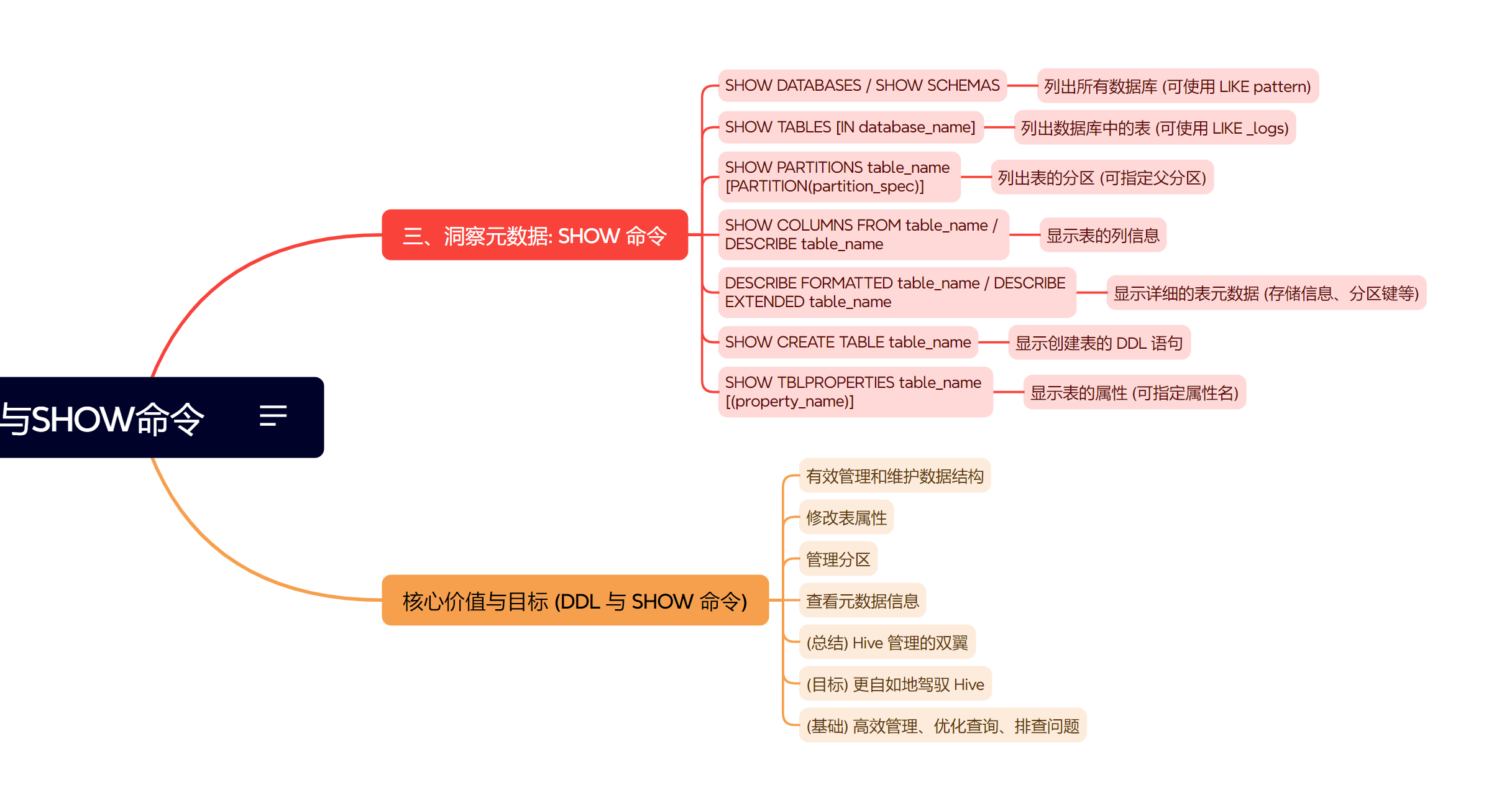
大模型核心运行机制目录
- 一、核心架构:Transformer的演进与改进
- 1.1 核心组件包括:
- 1.1.1 自注意力机制(Self-Attention)
- 1.1.2 多头注意力(Multi-Head Attention)
- 1.1.3 位置编码(Positional Encoding)
- 1.1.4 前馈网络(FFN)与残差结构
- 1.2 模型架构改进方向
- 稀疏化(如DeepSeek):
- 混合专家模型(MoE)(如GPT-4、DeepSeek-MoE):
- 多模态扩展(如GPT-4 Vision):
- 二、训练流程:三阶段协同优化
- 2.1. 预训练(Pre-training)
- 2.2. 微调(Fine-tuning)
- 2.3. 对齐优化(Alignment)
- 三、推理机制:生成与控制的平衡
- 3.1. 自回归生成
- 3.2. 上下文管理
- 3.3. 安全与可控性
- 四、优化与扩展:效率与性能的权衡
- 4.1. 训练优化
- 4.2. 推理加速
- 4.3. 扩展性提升
- 五、核心挑战与解决方案
- 5.1. 计算成本与能效
- 5.2. 长尾知识与事实性
- 5.3. 偏见与安全性
- 5.4. 多模态与泛化性
大模型(如GPT-4、DeepSeek、ChatGPT)的核心运行机制主要是基于深度学习,尤其是Transformer架构。通过大规模数据训练、高效计算优化、自注意力机制和任务对齐技术实现对复杂任务的理解与生成。
一、核心架构:Transformer的演进与改进
大模型的基础是transformer架构
1.1 核心组件包括:
1.1.1 自注意力机制(Self-Attention)
通过计算输入序列中每个词与其他词的相关性权重,捕捉长距离依赖关系。

其中,Q(查询)、K(键)、V(值)为输入向量的线性变换,
d
k
d_k
dk为维度缩放因子。
1.1.2 多头注意力(Multi-Head Attention)
并行多组注意力头,捕捉不同子空间的语义信息,增强模型表达能力。
1.1.3 位置编码(Positional Encoding)
引入序列位置信息,常用方法包括:
绝对位置编码(如Sinusoidal编码)。
相对位置编码(如旋转位置编码RoPE),支持动态扩展上下文长度。
1.1.4 前馈网络(FFN)与残差结构
每层后接非线性全连接层,并通过残差连接和层归一化(LayerNorm)缓解梯度消失。
模型通过预训练在大规模数据上学习语言规律,再通过微调适应特定任务。训练过程中,使用反向传播和优化算法(如Adam)调整数百万甚至数十亿的参数。
依赖GPU/TPU等高性能硬件和分布式训练加速计算。输入文本经过分词与嵌入转换为向量表示,模型通过推理生成输出,并采用生成策略(如束搜索)确保输出质量。整个过程依赖大规模数据和计算资源,实现复杂的语言理解和生成能力。核心架构图如下:
1.2 模型架构改进方向
稀疏化(如DeepSeek):
动态稀疏注意力(局部窗口注意力、激活部分神经元)降低计算复杂度(从O( n 2 n^2 n2)降至O(n l o g n log^n logn))。
混合专家模型(MoE)(如GPT-4、DeepSeek-MoE):
每个输入Token通过路由机制激活少量专家网络,提升模型容量(万亿参数)而计算成本可控。
多模态扩展(如GPT-4 Vision):
跨模态编码器融合文本、图像等输入,支持图文混合任务。
核心模型树如下:
-
Encoder Only: 对应粉色分支,即BERT派,典型模型: BERT
- 自编码模型(Autoencoder Model):通过重建句子来进行预训练,通常用于理解任务,如文本分类和阅读理解。
- 模型像一个善于分析故事的专家,输入一段文本,能拆解的头头是道,本质上是把高维数据压缩到低维空间。
-
Decoder Only: 对应蓝色分支,GPT派, 典型模型: GPT4,LLaMA,DeepSeek,QWen
- 自回归模型(Autoregressive Model):通过预测序列中的下一个词来进行预训练,通常用于文本生成任务。
- 模型像一个会讲故事的专家,给点提示,就能流畅的接着自说自话。
-
Encoder-Decoder: 对应绿色分支,T5派, 典型模型: T5, ChatGLM
- 序列到序列模型(Sequence to Sequence Model):结合了编码器和解码器,通常用于机器翻译和文本摘要等任务。
- 模型像一个“完型填空专家”,是因为它特别擅长处理这种类型的任务。通过将各种NLP任务统一转换为填空问题,T5派能够利用其强大的语言理解和生成能力来预测缺失的文本。这种方法简化了不同任务之间的差异,使得同一个模型可以灵活地应用于多种不同的NLP任务,并且通常能够在多个任务上取得很好的性能。
二、训练流程:三阶段协同优化
大模型的训练分为预训练-微调-对齐三阶段,从通用表征学习到任务适配与价值观对齐。
2.1. 预训练(Pre-training)
目标:从海量无标注数据中学习通用语言模式。
数据:
规模达TB级,涵盖网页、书籍、代码等多源数据,经去重、质量过滤(如毒性内容剔除)。
多语言混合(如PaLM支持100+语言),但以英语为主。
任务:
自回归建模(如GPT系列):预测下一个词,损失函数为交叉熵。
掩码语言建模(如BERT):预测被遮蔽的词,学习双向上下文。
2.2. 微调(Fine-tuning)
目标:适配下游任务(如对话、翻译)。
策略:
全参数微调:调整所有模型参数,需大量标注数据。
参数高效微调:如LoRA(低秩适配)、Adapter(插入小型网络),仅优化部分参数。
指令微调(如ChatGPT):使用人工标注的指令-回答对,增强指令跟随能力。
2.3. 对齐优化(Alignment)
人类反馈强化学习(RLHF)(如ChatGPT):
奖励模型训练:人工标注回答质量排序,训练奖励模型(Reward Model)。
强化学习优化:使用PPO算法,以奖励模型引导策略模型(Policy Model)生成更符合人类偏好的回答。
直接偏好优化(DPO):
替代RLHF,通过显式偏好数据直接优化模型,降低计算复杂度。
三、推理机制:生成与控制的平衡
3.1. 自回归生成
过程:逐个生成Token,将已生成序列作为输入预测下一Token。
解码策略:
贪婪搜索:选择概率最高词,简单但易陷入重复。
束搜索(Beam Search):保留多个候选序列,平衡质量与多样性。
采样策略:温度调节(Temperature):控制采样随机性(低温度趋确定,高温度趋多样)。
Top-p(核采样):仅从累积概率超过阈值p的词中采样。
重复惩罚:抑制重复生成(如通过repetition_penalty参数)。
3.2. 上下文管理
有限上下文窗口:如GPT-4支持128K tokens,通过位置编码扩展(如RoPE线性插值)突破长度限制。
长文本处理:
分块处理(Chunking)与层次化注意力,分段计算后融合。
KV-Cache缓存:缓存历史Token的Key-Value向量,避免重复计算。
3.3. 安全与可控性
安全层(Safety Layer):
输出前过滤有害内容(如暴力、偏见),调用外部审核API(如OpenAI Moderation)。
系统提示控制:
通过system prompt动态调整模型行为(如“你是一个医生”)。
实时检索增强(RAG):
结合外部知识库(如维基百科)补全长尾知识,提升事实准确性。
四、优化与扩展:效率与性能的权衡
4.1. 训练优化
分布式训练:
数据并行:多卡处理不同数据批次。
模型并行:拆分模型至不同设备(如Megatron-LM的张量并行)。
混合并行:结合数据与模型并行(如DeepSpeed的3D并行)。
显存优化:
梯度检查点:牺牲计算时间换显存,重计算中间激活。
混合精度训练:FP16/FP8降低显存占用,结合Loss Scaling保持数值稳定。
4.2. 推理加速
模型量化:
将FP32权重压缩至INT8/INT4,量化感知训练(QAT)减少精度损失。
动态批处理:
合并不同长度请求,最大化GPU利用率(如NVIDIA Triton)。
硬件适配:
针对边缘设备(手机、IoT)部署,支持自适应量化与剪枝。
4.3. 扩展性提升
参数规模:
从亿级(BERT)到万亿级(GPT-4),遵循缩放定律(Scaling Laws)提升性能。
上下文长度:
通过位置编码改进(如NTK-aware RoPE)、分块注意力支持百万Token级输入。
五、核心挑战与解决方案
5.1. 计算成本与能效
挑战:训练万亿模型需数千张GPU,成本超千万美元,推理能耗高。
解决方案:
MoE架构稀疏化计算,量化与蒸馏降低推理成本。
绿色计算:使用可再生能源,优化数据中心能效。
5.2. 长尾知识与事实性
挑战:模型对低频知识覆盖不足,可能生成错误事实。
解决方案:
检索增强生成(RAG):实时调用外部知识库(如ChatGPT联网插件)。
合成数据增强:利用规则或小模型生成高质量训练样本。
5.3. 偏见与安全性
挑战:训练数据隐含社会偏见,可能生成有害内容。
解决方案:
RLHF与DPO对齐人类价值观。
红队测试(Red Teaming)主动探测漏洞,部署多级内容过滤。
5.4. 多模态与泛化性
挑战:跨模态任务(如图文生成)需统一表征空间。
解决方案:
跨模态编码器(如CLIP)对齐图文特征。
渐进式多模态预训练(如PaLI-X)。
六、可能得发展方向(猜测)
稀疏化与模块化:更高效动态计算路径(如Switch Transformer)。
终身学习:持续学习新知识避免灾难性遗忘。
可解释性:通过注意力可视化、概念神经元分析提升透明度。
边缘计算:轻量化模型(如TinyLLaMA)适配移动端部署。
总结
大模型的核心运行机制以Transformer架构为基础,通过大规模预训练学习通用表征,结合微调与对齐技术适配任务与价值观,最终依赖高效工程优化实现低成本推理。其优势在于强大的泛化能力,但需持续攻克成本、安全与知识更新等挑战。聚焦效率提升、多模态融合及伦理对齐,推动技术从“规模竞赛”向“实用落地”演进。