LeetCode 513 找树左下角的值
迭代法——层序遍历
思路:对树进行层序遍历操作,层序遍历完后,输出树最后一层的第一个节点。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def findBottomLeftValue(self, root):
"""
:type root: Optional[TreeNode]
:rtype: int
"""
### Version 1 : 层序遍历,遍历每一层后取出最后一层的第一个元素。
result = []
queue = deque([root])
while queue:
level = []
size = len(queue)
while size:
cur = queue.popleft()
if cur.left:
queue.append(cur.left)
if cur.right:
queue.append(cur.right)
level.append(cur.val)
size -= 1
result.append(level)
return result[-1][0] 递归法
思路:
- 由于是记录底层最左侧节点的值,因此我们需要去获取遍历时的深度,深度最深的时候才去考虑是否是最左侧节点的值。
- 由于是获取最左侧节点的值,因此只要遍历顺序是左先于右,这样的话在深度最深的时候,由于遍历顺序是左先,因此第一个遍历到的节点一定是底层最左侧节点(前中后序遍历中左都是在右之前,因此三种遍历方式都可以,另外本题对于中不需要处理,所以中其实就是无代码)
关键:
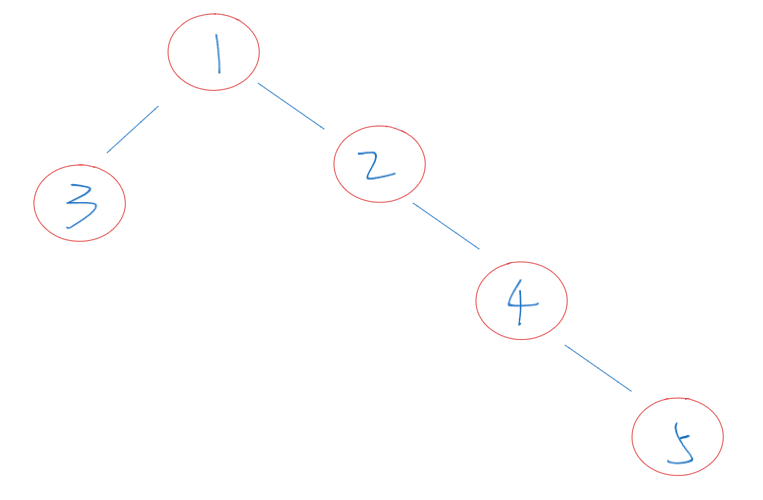
- 遍历后记得回溯,因为你遍历是在遍历下一层的,当你遍历完下一层后,需要回退到上一层中去遍历另外一边。如下图所示:你在遍历完3之后需要回退到1,才能继续去遍历1的右子树。没有回溯的话就会一直卡在左边(因为左边优先遍历)。同理遍历完右边后也需要回退。
- 由于需要在遍历的过程中去比较是否到达深度最深的地方,因此需要通过一个全局变量用于记录已遍历过的最大深度的信息。当遍历到叶子节点时,就需要判断当前是否是最大深度了,如果是则更新最大深度的值,反之。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def findBottomLeftValue(self, root):
"""
:type root: Optional[TreeNode]
:rtype: int
"""
#### 递归法:底层最左边节点的值,其深度一定是最大的。
#### 前中后序遍历都可以,因为都是左遍历在右遍历之前。
self.max_depth = float('-inf') ### 全局变量,存储最大深度
self.result = 0 ### 全局变量,存储底层最左侧节点的值
self.search_DepLeft(root, 1)
return self.result
def search_DepLeft(self, root, depth):
### 递归逻辑:记录当前遍历节点的深度,遍历顺序需要满足左一定在右之前。这样的话,深度最大时,一个遍历到的元素就是底层的最左侧节点。
### 关键:如何对max_depth初始化,且在下一次递归时,max_depth的值是上一层节点的值。这样的话max_depth是一个全局变量,其初始化不应该在递归函数内设置
if not root.left and not root.right: ### 终止条件 —— 到叶子节点
if depth > self.max_depth: ### 到达叶子节点后,需要判断深度是否是最底层
self.max_depth = depth
self.result = root.val ### 由于左遍历在右遍历之前,因此深度最大时遍历到的第一个节点一定是底层的最左侧节点
return
if root.left: ### 有左叶子节点的话
depth += 1 ### 更新遍历左叶子节点时候的深度
self.search_DepLeft(root.left, depth)
depth -= 1 ### 遍历完后,需要回溯,不然的话就会一直停留在左子树。
if root.right:
depth += 1
self.search_DepLeft(root.right, depth)
depth -= 1LeetCode 112 路径总和
思路:(前中后序遍历都可以,这里是前序遍历)
- 定义一个全局变量记录,根节点逐渐向下遍历过程中的和,到达根节点的时候,判断当前路径是否成立。
- 如果不成立的话,需要对子递归函数进行回溯操作。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def hasPathSum(self, root, targetSum):
"""
:type root: Optional[TreeNode]
:type targetSum: int
:rtype: bool
"""
### 根节点到叶子节点的路径, 这个做过。但这道题不需要返回整条path,而是返回path的值之和是否等于targetSum
### 现在是在上述基础上,计算根节点到叶子节点的路径上的值,判断该值是否等于targetSum
self.sum = 0 ## 记录当前遍历的path值的总和
if not root:
return False
result = self.search_Path(root, targetSum)
return result
def search_Path(self, root, targetSum):
self.sum += root.val
# print("path_self.sum, root.val", self.sum, root.val)
if not root.left and not root.right: ###终止条件
if self.sum == targetSum:
return True
if root.left:
if self.search_Path(root.left, targetSum):
return True
# self.search_Path(root.left, targetSum)
self.sum -= root.left.val
if root.right:
if self.search_Path(root.right, targetSum):
return True
# self.search_Path(root.right, targetSum)
self.sum -= root.right.val
return False ### 完全遍历后,没有输出True就输出return错误地方分析:
- 递归思路可以实现逐渐查找并回溯。但下面代码这样编写有问题,即当self.search_Path(root.left, targetSum)搜到叶子节点时,发现路径之和==targetSum时,此时会return True,但这也仅代表这个递归函数返回True,后续没有显式返回子递归的结果,因此最终输出的会是Null。(子递归返回了值,但未传递返回值,从而结果被更上一层的递归也覆盖掉了)
- 为什么要加这个判断,比如你目前的主递归函数是递归根节点的左节点,随后子递归是逐渐往下遍历,那当子递归输出为True时,就已经告诉了目前左子树存在一条路径,使得根节点到左子树的一个叶子节点的值等于targetSum,那你此时就需要就子递归的输出直接return给根节点的左节点函数,那主递归函数在收到True时,此时就明确了左子树存在一条路径之和符合题目要求的情况。
if root.left:
self.search_Path(root.left, targetSum)
self.sum -= root.left.val
if root.right:
self.search_Path(root.right, targetSum)
self.sum -= root.right.valLeetCode 113 路径总和 II
注意:
- 浅拷贝和深拷贝的问题。
- self.result.append(self.path) ### 这里存的是self.path的指针,并没有存储当targetSum的数组元素。这个指针会始终指向这块数组的内存位置,如果存储的是指针的话,最终result的内容只会是该内存块中最后的元素,在这道题中,最后result.append的只会是5,因为在遍历完并回溯完后,最终数组只有根节点元素。
- self.result.append(self.path[:]) ### 这里是深拷贝,即在内存中重新开辟一块空间来copy此时符合条件的路径的数组,result存储的是这个新的数组。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def pathSum(self, root, targetSum):
"""
:type root: Optional[TreeNode]
:type targetSum: int
:rtype: List[List[int]]
"""
self.sum = 0
self.result = []
self.path = []
self.search_Path(root, self.path, targetSum, self.result)
return self.result
def search_Path(self, root, path, targetSum, result):
if not root:
return
self.sum += root.val
self.path.append(root.val)
if not root.left and not root.right:
if self.sum == targetSum:
self.result.append(self.path[:])
# self.result.append(self.path) ### 这里存的是self.path的指针,并没有存储当targetSum的数组元素。这个指针会始终指向这块数组的内存位置,如果存储的是指针的话,最终result的内容只会是该内存块中最后的元素,在这道题中,最后result.append的只会是5,因为在遍历完并回溯完后,最终数组只有根节点元素。
return
else:
return
if root.left:
self.search_Path(root.left, self.path, targetSum, self.result)
self.sum -= root.left.val
path.pop()
if root.right:
self.search_Path(root.right, self.path, targetSum, self.result)
self.sum -= root.right.val
path.pop() LeetCode106 从中序与后序遍历序列构造二叉树
中序遍历:左中右
后序遍历:左右中
根据中序遍历和后序遍历的规则,我可以得出以下特性来构造二叉树:
- 后序遍历的最后一个节点一定是根节点,因此我们可以根据这个根节点,去中序遍历中将左子树和右子树给区分开来。
- 中序遍历和后序遍历起始都是左,在中序遍历中根据根节点将左子树和右子树区分开来后,我们可以根据中序遍历左子树元素的个数,在后序遍历中获得左子树的后序遍历数组,其余的就是右子树的后序遍历数组。
根据上述特性后,我们可以就可以确定了这颗树的根节点、左子树的中序遍历和后序遍历数组、右子树的中序和后序遍历数组。那分别对左右子树的中序和后序数组进行递归操作,又可以根据相同的特性获得唯一左子树和右子树。
如下面例子:
| 9 | 3 | 15 | 20 | 7 |
| 9 | 15 | 7 | 20 | 3 |
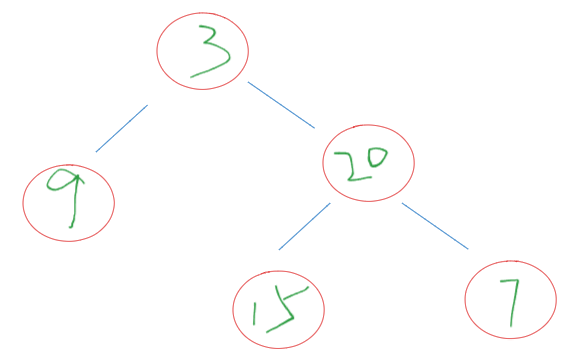
首先,我们可以知道根节点为3。知道根节点为3之后,就可以明确知道在中序遍历数组3左边是左子树,3右边是右子树。根据中序遍历中左子树的元素个数就可以确定在后序遍历中的左子树后序遍历数组,这里是都为9。其余的就是右子树的内容,那对其余的进行分析,可以知道右子树中序遍历数组为 [15, 20, 7],后序遍历数组为[15, 7, 20]。执行相同的操作,就可以确定唯一的右子树。最后整棵树为如下:
代码思路:
- 判断后序数组是否为None,如果是,则证明为空树
- 判断后序数组长度是否为1,如果是,则证明则有根节点
- 如果后序数组大于1,则首先获得这颗树的根节点。
- 根据根节点的值,去中序遍历数组中找到等于该值的元素下标,在这个下标之前的子数组就是左子树的中序遍历数组,之后的就是右子树中序遍历的子数组。
- 根据左子树的中序遍历数组的个数,我们可以从后序遍历数组中获得左子树的后序遍历数组。其余的,除了最后一个节点之外的元素,就是右子树后序遍历的子数组。
- 根据左,右子树的中序遍历和后序遍历子数组,进行递归操作,来唯一确定左右子树。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def buildTree(self, inorder, postorder):
"""
:type inorder: List[int]
:type postorder: List[int]
:rtype: Optional[TreeNode]
"""
if len(postorder) == 0: ## 空树
return None
### 只有根结点的情况,以下也能进行判断
root_val = postorder[-1]
root = TreeNode(val=root_val)
SEP = inorder.index(root_val) ### 获得切割点的index
left_inorder = inorder[:SEP]
right_inorder = inorder[SEP+1:]
#### 区间是左闭右开,数组[A:B] 等于 A到B-1位置的子数组
left_postorder = postorder[0:len(left_inorder)]
right_postorder = postorder[len(left_inorder):len(postorder)-1]
root_left = self.buildTree(left_inorder, left_postorder)
root_right = self.buildTree(right_inorder, right_postorder)
root.left = root_left ### 将构造好的左右子树连接到根节点中
root.right = root_right
return root- 注意再获得左右子树后,要将根节点的左右指针进行赋值。
- 注意区间是左闭右开还是左闭右闭
LeetCode 105 从前序与中序遍历序列构造二叉树
中序遍历:左中右
前序遍历:中左右
根据中序遍历和前序遍历的规则,我可以得出以下特性来构造二叉树:
- 前序遍历的第一个节点一定是根节点,因此我们可以根据这个根节点,去中序遍历中将左子树和右子树给区分开来。
- 中序遍历和前序遍历结尾都是右,在中序遍历中根据根节点将左子树和右子树区分开来后,我们可以根据中序遍历右子树元素的个数,在前序遍历中获得右子树的前序遍历数组,其余的就是左子树的前序遍历数组。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def buildTree(self, preorder, inorder):
"""
:type preorder: List[int]
:type inorder: List[int]
:rtype: Optional[TreeNode]
"""
### preorder: 中左右
### inorder : 左中右
if len(preorder) == 0: ##空树
return None
root_val = preorder[0]
root = TreeNode(val=root_val) ##根节点
SEP = inorder.index(root_val)
left_inorder = inorder[:SEP] ### 区间是左闭右开
left_preorder = preorder[1:len(left_inorder)+1]
right_preorder = preorder[len(left_inorder)+1:]
right_inorder = inorder[SEP+1:]
left_tree = self.buildTree(left_preorder, left_inorder)
right_tree = self.buildTree(right_preorder, right_inorder)
root.left = left_tree
root.right = right_tree
return root 总结
中序遍历 + 前序/后序遍历 可以 确定一个唯一的二叉树。必须有中序遍历的存在。
而前序遍历+后序遍历无法确认。
前序遍历:中左右
后序遍历:左右中
根据前序遍历和后序遍历的特性,我们只能唯一确定根节点,但无法从前序遍历和后序遍历划分出左右。例子如下:
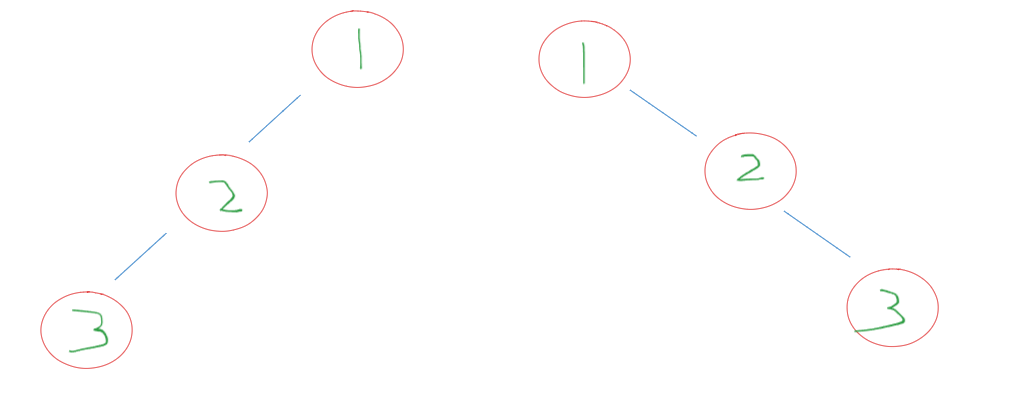
上面这两颗树的前序遍历都为[ 1, 2, 3] ,后序遍历为[3, 2, 1]


![[Git]ssh下用Tortoisegit每次提交都要输密码](https://i-blog.csdnimg.cn/direct/95652aaa3092415b818ff58483e4e7ea.png)