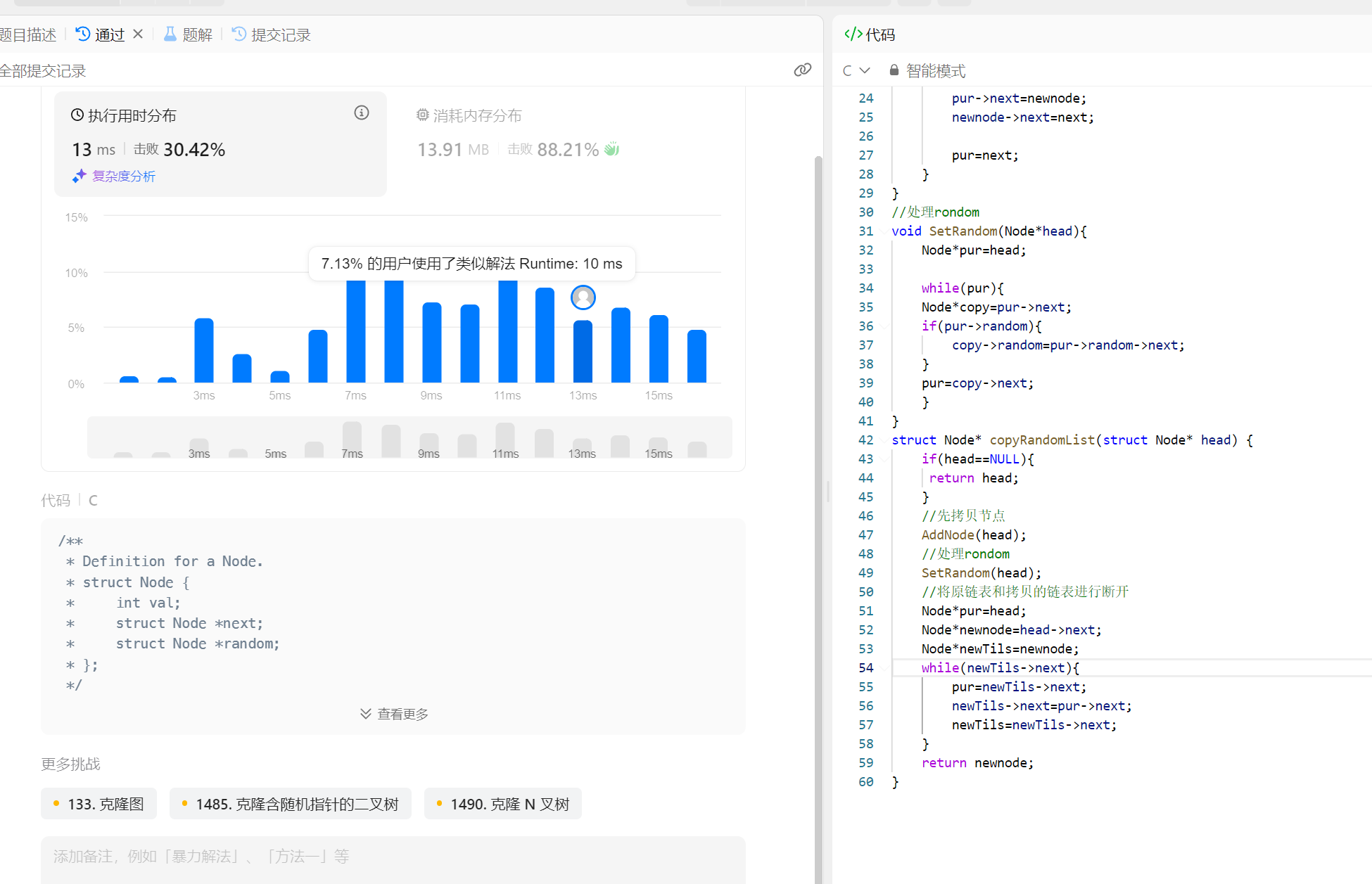
目录
# 动态规划
# 基于动态规划的强化学习方法
# 求解过程:
## 策略评估
## 策略提升
# 价值迭代算法
# 参考
# 动态规划
动态规划的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。动态规划会保存已解决的子问题的答案,在求解目标问题的过程中,需要这些子问题答案时就可以直接利用,避免重复计算。
# 基于动态规划的强化学习方法
分类:
- 策略迭代(policy iteration): 由策略评估(policy evaluation)和策略提升(policy improvement)两部分组成
- 价值迭代(value iteration)
# 求解过程:
贝尔曼最优方程:
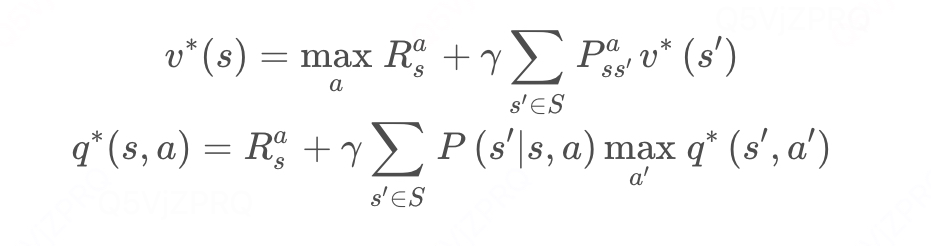
利用动态规划来求解的话,核心是找到最优值函数;
## 策略评估
求解值函数:
状态值函数的计算公式:
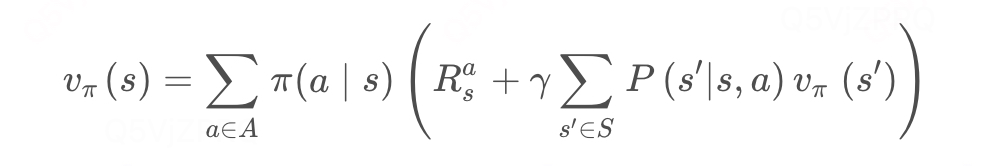
该式中其他变量都是已知量,是一个关于值函数的线性方程组,其未知数的个数为状态的总数,用|S|来表示。
利用动态规划来求解:可以把计算下一个可能状态的价值当成一个子问题,把计算当前状态的价值看作当前问题。在得知子问题的解后,就可以求解当前问题。更一般的,考虑所有的状态,就变成了用上一轮的状态价值函数来计算当前这一轮的状态价值函数。
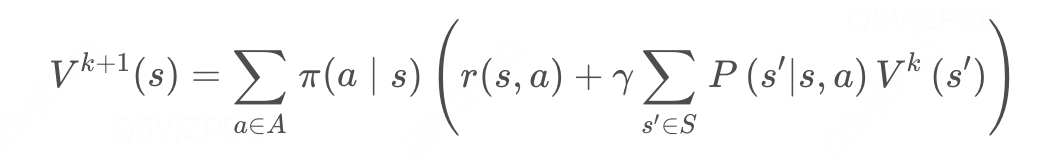
策略评估伪代码:

## 策略提升
使用策略评估计算得到当前策略的状态价值函数之后,我们可以据此来改进该策略。
得到价值函数$V_pi$后,也就是知道了在策略π \piπ下从每一个状态出发最终得到的期望回报。下一步就是要改进策略pi,来获得在状态下更高的期望回报!
策略提升定理(policy improvement theorem):
如果存在Q π ( s , a ) > V π ( s ) Q^{\pi}(s,a)>V^{\pi}(s)Q ,则说明在状态s下采取动作a会比原来的策略π ( a ∣ s ) \pi(a|s)π(a∣s)得到更高的期望回报。于是我们可以直接贪心地在每一个状态选择动作价值最大的动作,也就是:
已知当前策略的值函数时,在每个状态采用贪婪策略对当前策略进行改进即可。
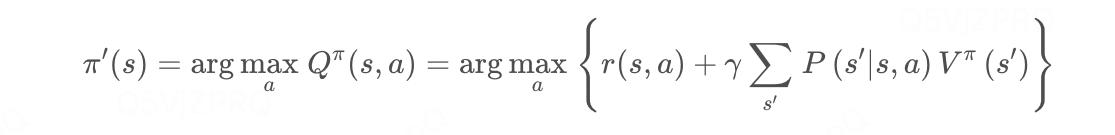
策略迭代算法:
总体来说,策略迭代算法的过程如下:对当前的策略进行策略评估,得到其状态价值函数,然后根据该状态价值函数进行策略提升以得到一个更好的新策略,接着继续评估新策略、提升策略……直至最后收敛到最优策略:
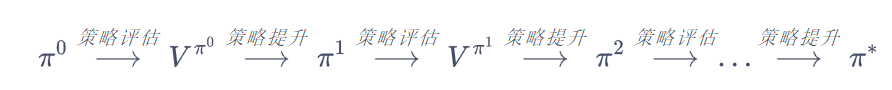

总结:
1. 策略评估:给定策略,通过数值迭代算法不断计算该策略下每个状态的值函数
2. 策略改进:利用该值函数和贪婪策略得到新的策略。
# 价值迭代算法
策略评估中需要价值函数收敛,值函数的收敛往往需要很多次迭代,这需要很大的计算量,尤其是在状态和动作空间比较大的情况下。但是进行策略改进之前一定要等到策略值函数收敛吗?
如果只在策略评估中进行一轮价值更新,然后直接根据更新后的价值进行策略提升,这样是否可以呢?答案是肯定的,这其实就是价值迭代算法,它可以被认为是一种策略评估只进行了一轮更新的策略迭代算法。

# 参考
1.基于动态规划的强化学习方法_动态规划强化学习-CSDN博客
2.深入浅出强化学习


![[工具]B站缓存工具箱 (By 郭逍遥)](https://i-blog.csdnimg.cn/direct/7a45a56137354d7b8b12a5a5f4951568.png#pic_center)