文章目录
- 背景与动机
- 31.1 信号量:定义 (Semaphores: A Definition)
- 31.2 二元信号量 (用作锁) (Binary Semaphores - Locks)
- 31.3 用于排序的信号量 (Semaphores For Ordering)
- 31.4 生产者/消费者问题 (The Producer/Consumer (Bounded Buffer) Problem)
- 31.5 读写锁 (Reader-Writer Locks)
- 31.6 哲学家就餐问题 (The Dining Philosophers)
- 31.7 线程节流 (Thread Throttling)
- 31.8 如何实现信号量 (How To Implement Semaphores)
- 31.9 总结
- 31.10 经典同步问题的现代解决方案与演进
背景与动机
我们已经知道,解决并发问题需要锁 (locks) 和条件变量 (condition variables)。Edsger Dijkstra 是最早认识到这一点的人之一,他引入了一种称为信号量 (semaphore) 的同步原语。Dijkstra 和他的同事发明信号量,旨在将其作为一种通用的同步工具,既可以实现锁的功能,也可以实现条件变量的功能。
核心问题 (THE CRUX): 如何使用信号量?
- 信号量能否替代锁和条件变量?
- 信号量的定义是什么?什么是二元信号量?
- 用锁和条件变量构建信号量是否直接?
- 用信号量构建锁和条件变量是否直接?
31.1 信号量:定义 (Semaphores: A Definition)
信号量是一个具有整数值的对象,可以通过两个基本操作来控制:
sem_wait()(或 P()):- 尝试减少信号量的值。
- 如果信号量的值在减少后变为负数,则调用线程将被阻塞 (block) 并进入休眠状态,直到其他线程通过
sem_post()增加信号量的值使其不再为负。 - 如果信号量的值在减少后大于等于零,则线程继续执行。
sem_post()(或 V()):- 增加信号量的值。
- 如果增加后,有其他线程因为等待该信号量而阻塞,则系统会唤醒其中一个(或多个,取决于实现)等待的线程。
初始化 (Initialization):
- 在使用信号量之前,必须将其初始化为一个特定的整数值。这个初始值决定了信号量的行为。
- POSIX 标准中的初始化函数是
sem_init(sem_t *sem, int pshared, unsigned int value):sem: 指向要初始化的信号量对象的指针。pshared:- 如果为
0,表示信号量在同一进程的线程间共享 (本章主要关注这种情况)。 - 如果非
0,表示信号量在进程间共享 (需要不同的设置和考虑)。
- 如果为
value: 信号量的初始值。
代码示例:初始化一个信号量 (Figure 31.1)
#include <semaphore.h>
sem_t s; // 声明一个信号量变量
// 初始化信号量 s,线程间共享,初始值为 1
sem_init(&s, 0, 1);
sem_wait() 和 sem_post() 的行为定义 (概念性 - Figure 31.2):
// 概念性定义,非实际 POSIX 实现细节
int sem_wait(sem_t *s) {
// 原子地执行以下操作:
decrement the value of semaphore s by one;
if (value of semaphore s is negative) {
wait (i.e., block the calling thread);
}
return 0; // or some status
}
int sem_post(sem_t *s) {
// 原子地执行以下操作:
increment the value of semaphore s by one;
if (there are one or more threads waiting on s) {
wake one of them up;
}
return 0; // or some status
}
关键特性:
- 原子性:
sem_wait()和sem_post()的操作(检查值、修改值、决定是否休眠/唤醒)必须是原子执行的。 - 等待队列: 多个线程可能同时调用
sem_wait()并在信号量的值为负时阻塞,形成一个等待队列。 sem_post()不等待:sem_post()只是简单地增加信号量的值,并尝试唤醒等待者(如果有的话);它本身不会因为某个条件不满足而等待。- 信号量值的意义 (Dijkstra 的定义中): 当信号量的值为负时,其绝对值等于正在等待该信号量的线程数量。不过,POSIX 标准的信号量实现通常不允许用户直接观察到负值(当值为0时调用
wait会阻塞,值始终保持非负)。本章后续实现的 “Zemaphore” 也遵循了值不为负的模式。
历史渊源 (P 和 V 操作的名称):
sem_wait()最初由 Dijkstra 称为P()。sem_post()最初由 Dijkstra 称为V()。- 这些名称来源于荷兰语:
P(): 最初可能来自 “passering” (通过) 或后来 Dijkstra 解释为 “prolaag” (probeer te verlagen 的缩写,意为“尝试减少”)。V(): 最初可能来自 “vrijgave” (释放) 或后来解释为 “verhoog” (增加)。
- 有时也被称为
down()和up()操作。
31.2 二元信号量 (用作锁) (Binary Semaphores - Locks)
信号量最直接的应用之一是作为互斥锁 (mutex lock)。这种只取0或1值的信号量通常被称为二元信号量 (binary semaphore)。
实现锁的思路 (Figure 31.3):
- 初始化: 将信号量
m的初始值设为 1。这表示锁最初是可用的(有一个“资源”可以被获取)。 - 获取锁 (Lock): 在进入临界区之前调用
sem_wait(&m)。 - 释放锁 (Unlock): 在退出临界区之后调用
sem_post(&m)。
sem_t m;
// 初始化为 X,对于锁,X 应该是什么?
// 答案:X 应该是 1
sem_init(&m, 0, 1);
// ... 线程代码 ...
sem_wait(&m); // 获取锁
// --- 临界区开始 ---
// ... 访问共享资源 ...
// --- 临界区结束 ---
sem_post(&m); // 释放锁
// ...
工作原理分析:
-
单个线程获取锁 (Figure 31.4 Trace):
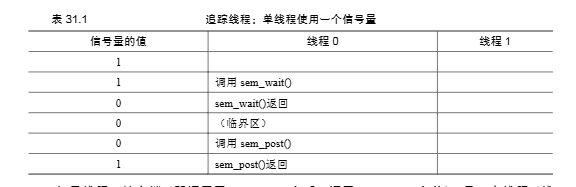
- 信号量
m初始值为 1。 - 线程0 调用
sem_wait(&m):- 信号量值减1,变为 0。
- 由于值 (0) 不为负,线程0继续执行,进入临界区。
- 线程0 在临界区内执行。
- 线程0 调用
sem_post(&m):- 信号量值加1,恢复为 1。
- 没有线程在等待,
sem_post返回。
- 信号量
-
两个线程竞争锁 (Figure 31.5 Trace):
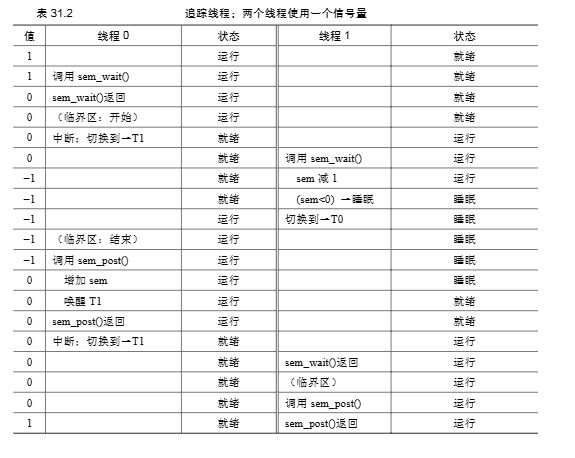
- 信号量
m初始值为 1。 - 线程0 调用
sem_wait(&m),信号量变为 0,线程0进入临界区。 - 线程1 尝试获取锁,调用
sem_wait(&m):- 信号量值减1,变为 -1 (或在POSIX实现中,值变为0,线程1阻塞)。
- 线程1 被阻塞,进入休眠状态,等待信号量
m。
- 线程0 执行完毕临界区,调用
sem_post(&m):- 信号量值加1,变为 0 (或在POSIX实现中,值变为1)。
- 由于有线程 (线程1) 在等待,系统唤醒线程1。
- 线程1 被唤醒,从
sem_wait()返回(此时它已“获得”锁,信号量值再次变为0),进入临界区。 - 线程1 执行完毕临界区,调用
sem_post(&m),信号量恢复为 1。
- 信号量
关键:初始值为1 确保了只有一个线程可以成功执行 sem_wait() 并通过(使信号量变为0),后续线程调用 sem_wait() 会导致信号量值变为负(或阻塞在值为0时),直到持有锁的线程调用 sem_post()。
31.3 用于排序的信号量 (Semaphores For Ordering)
信号量也可以用来强制并发程序中事件的执行顺序,类似于条件变量的功能。
例子:父线程等待子线程完成 (Figure 31.6)
- 目标: 父线程创建一个子线程,然后等待子线程执行完毕后再继续。
- 输出期望:
parent: begin child parent: end - 实现思路:
- 初始化: 将信号量
s的初始值设为 0。这表示最初没有“完成信号”这个资源可用,父线程如果尝试等待,将会阻塞。 - 子线程: 在其工作完成后,调用
sem_post(&s),发出一个“完成信号”(增加信号量的值)。 - 父线程: 在创建子线程后,调用
sem_wait(&s)来等待这个“完成信号”。
- 初始化: 将信号量
sem_t s;
// 初始化为 X,对于等待子线程完成,X 应该是什么?
// 答案:X 应该是 0
sem_init(&s, 0, 0);
void *child(void *arg) {
printf("child\n");
sem_post(&s); // 子线程完成,发出信号
return NULL;
}
int main(int argc, char *argv[]) {
printf("parent: begin\n");
pthread_t c_thread;
pthread_create(&c_thread, NULL, child, NULL);
sem_wait(&s); // 父线程等待子线程的信号
printf("parent: end\n");
return 0;
}
工作原理分析 (两种情况):
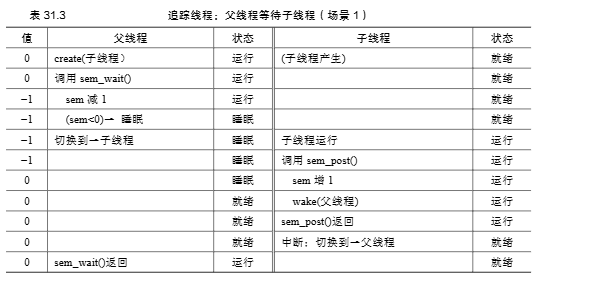
-
父线程先调用
sem_wait()(子线程尚未运行或未完成 - Figure 31.7 Trace, Case 1):- 信号量
s初始值为 0。 - 父线程调用
sem_wait(&s):- 信号量值减1,变为 -1 (或在POSIX中,值为0,父线程阻塞)。
- 父线程阻塞,等待信号。
- 子线程运行,打印 “child”。
- 子线程调用
sem_post(&s):- 信号量值加1,变为 0 (或在POSIX中,值变为1)。
- 由于有线程 (父线程) 在等待,系统唤醒父线程。
- 父线程被唤醒,从
sem_wait()返回,继续执行。
- 信号量
-
子线程先运行并调用
sem_post()(父线程尚未调用sem_wait()- Figure 31.8 Trace, Case 2):
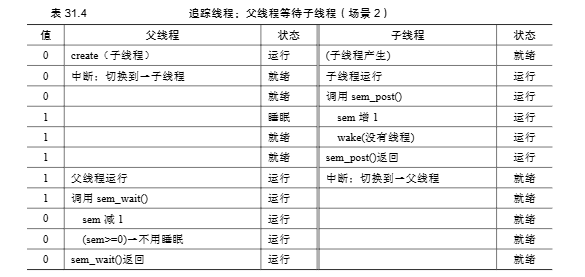
- 信号量
s初始值为 0。 - 子线程运行,打印 “child”。
- 子线程调用
sem_post(&s):- 信号量值加1,变为 1。
- 没有线程在等待,
sem_post返回。
- 父线程运行,调用
sem_wait(&s):- 信号量值减1,变为 0。
- 由于值 (0) 不为负,父线程继续执行,不阻塞。
- 信号量
关键:初始值为0 确保了如果父线程先尝试等待,它会阻塞,直到子线程发出完成信号。如果子线程先完成,它会使信号量的值变为1,这样父线程后续的等待操作可以直接通过。
ASIDE: 设置信号量的初始值
- 作为锁: 初始值为 1 (表示有一个资源——锁——立即可用)。
- 用于排序/等待事件: 初始值为 0 (表示最初事件尚未发生,没有资源可用,等待方需要阻塞)。
- 一般规则 (Perry Kivolowitz 的思路): 考虑在初始化后,你愿意立即“交出”多少个资源。对于锁,你愿意让一个线程立即获取它。对于等待子线程完成,开始时子线程还没完成,所以没有“完成”这个资源可以交出。
31.4 生产者/消费者问题 (The Producer/Consumer (Bounded Buffer) Problem)
这个问题在上一章(条件变量)中已经详细描述过。现在我们尝试用信号量来解决。
基本组件:
- 一个有限大小的共享缓冲区。
- 生产者线程:向缓冲区放入数据项。
- 消费者线程:从缓冲区取出数据项。
同步需求:
- 互斥访问缓冲区: 放入和取出操作是临界区。
- 缓冲区满时生产者等待: 直到有空位。
- 缓冲区空时消费者等待: 直到有数据。
首次尝试:仅使用 empty 和 full 信号量 (Figure 31.9, 31.10 - MAX=1 时正确,多生产者/消费者或 MAX > 1 时有问题)
sem_t empty;// 表示缓冲区中空槽位的数量,初始值为MAX(缓冲区大小)。sem_t full;// 表示缓冲区中已填充槽位的数量,初始值为0。put()和get()函数用于实际的缓冲区操作(非同步版本)。
// 缓冲区和指针 (Figure 31.9)
// int buffer[MAX];
// int fill = 0; // 下一个填充位置
// int use = 0; // 下一个使用位置
// void put(int value) { buffer[fill] = value; fill = (fill + 1) % MAX; }
// int get() { int tmp = buffer[use]; use = (use + 1) % MAX; return tmp; }
// 生产者和消费者 (Figure 31.10)
sem_t empty;
sem_t full;
// ... main 中初始化: sem_init(&empty, 0, MAX); sem_init(&full, 0, 0);
void *producer(void *arg) {
for (int i = 0; i < loops; i++) {
sem_wait(&empty); // P1: 等待有空槽位 (减少空槽位计数)
put(i); // P2: 放入数据
sem_post(&full); // P3: 增加已填充槽位计数 (通知消费者)
}
return NULL;
}
void *consumer(void *arg) {
// while (tmp != -1) { // 书中循环条件
for (int i = 0; i < loops_or_forever; i++) { // 简化循环
sem_wait(&full); // C1: 等待有数据 (减少已填充槽位计数)
int tmp = get(); // C2: 取出数据
sem_post(&empty); // C3: 增加空槽位计数 (通知生产者)
printf("%d\n", tmp);
}
return NULL;
}
- MAX=1 时的分析:
empty初始为1,full初始为0。- 消费者先运行: 调用
sem_wait(&full)(值为0),消费者阻塞。 - 生产者运行: 调用
sem_wait(&empty)(值为1),empty变为0,生产者继续。put()数据。调用sem_post(&full),full变为0 (因为之前是-1或阻塞在0),唤醒消费者。 - 生产者继续运行: 再次到
sem_wait(&empty)(值为0),生产者阻塞。 - 消费者运行: 从
sem_wait(&full)返回。get()数据。调用sem_post(&empty),empty变为0,唤醒生产者。 - 行为符合预期。
- MAX > 1 且有多个生产者/消费者时的问题:
- 竞争条件在
put()和get()内部: 如果两个生产者同时通过sem_wait(&empty),它们可能会尝试写入缓冲区的同一个槽位(例如,都使用当前的fill指针),导致数据覆盖。同样的问题也存在于多个消费者并发调用get()。 - 原因:
put()和get()操作(修改缓冲区内容和更新fill/use指针)本身不是原子的,它们是临界区,需要互斥保护。
- 竞争条件在
解决方案:增加互斥锁 (Figure 31.11 - 错误的加锁方式导致死锁)
- 尝试在生产者和消费者的整个操作序列外层添加一个二元信号量
mutex(初始值为1) 作为锁。
// Figure 31.11: Adding Mutual Exclusion (Incorrectly)
// sem_t mutex; // 初始化为 1
// sem_t empty; // 初始化为 MAX
// sem_t full; // 初始化为 0
void *producer(void *arg) {
for (int i = 0; i < loops; i++) {
sem_wait(&mutex); // PO (NEW): 获取互斥锁
sem_wait(&empty); // P1
put(i); // P2
sem_post(&full); // P3
sem_post(&mutex); // P4 (NEW): 释放互斥锁
}
return NULL;
}
void *consumer(void *arg) {
for (...) {
sem_wait(&mutex); // CO (NEW): 获取互斥锁
sem_wait(&full); // C1
int tmp = get(); // C2
sem_post(&empty); // C3
sem_post(&mutex); // C4 (NEW): 释放互斥锁
printf("%d\n", tmp);
}
return NULL;
}
- 死锁 (Deadlock) 问题:
- 消费者先运行。
- 消费者获取
mutex(Line C0)。 - 消费者调用
sem_wait(&full)(Line C1)。由于缓冲区为空 (full初始为0),消费者阻塞,但它仍然持有mutex锁! - 生产者运行。
- 生产者尝试获取
mutex(Line P0)。由于mutex已被消费者持有,生产者阻塞。
- 结果: 消费者持有
mutex并等待full信号(需要生产者发出)。生产者需要mutex才能发出full信号。两者互相等待,形成死锁。
最终的、正确的解决方案 (Figure 31.12 - 正确的加锁方式)

- 关键在于缩小互斥锁的保护范围,只保护真正需要互斥的临界区,即对共享缓冲区(
buffer,fill,use指针)的实际访问和修改。 - 将
sem_wait(&mutex)和sem_post(&mutex)移到put()和get()操作的内部,或者紧紧包围put()和get()调用。书中示例选择后者。
// Figure 31.12: Adding Mutual Exclusion (Correctly)
// sem_t mutex; // 初始化为 1
// sem_t empty; // 初始化为 MAX
// sem_t full; // 初始化为 0
void *producer(void *arg) {
for (int i = 0; i < loops; i++) {
sem_wait(&empty); // P1: 等待空位
sem_wait(&mutex); // P1.5 (lock): 获取互斥锁,保护 put()
put(i); // P2: 临界区
sem_post(&mutex); // P2.5 (unlock): 释放互斥锁
sem_post(&full); // P3: 通知有数据
}
return NULL;
}
void *consumer(void *arg) {
for (...) {
sem_wait(&full); // C1: 等待数据
sem_wait(&mutex); // C1.5 (lock): 获取互斥锁,保护 get()
int tmp = get(); // C2: 临界区
sem_post(&mutex); // C2.5 (unlock): 释放互斥锁
sem_post(&empty); // C3: 通知有空位
printf("%d\n", tmp);
}
return NULL;
}
- 工作原理:
- 生产者首先等待
empty信号量,确保有空位。这可能使其阻塞,但此时它不持有mutex锁。 - 一旦有空位 (
sem_wait(&empty)返回),生产者才尝试获取mutex锁来执行put()操作。 put()完成后立即释放mutex锁,然后再通过sem_post(&full)通知消费者。- 消费者逻辑类似。
- 生产者首先等待
- 避免死锁: 这种方式避免了之前一个线程持有互斥锁同时又等待另一个信号量(而这个信号量需要另一个等待该互斥锁的线程来发出)的情况。线程在等待
empty或full这种可能导致长时间阻塞的条件时,并不持有mutex。
31.5 读写锁 (Reader-Writer Locks)
读写锁是一种更灵活的锁机制,允许多个“读者 (readers)”并发地访问共享数据结构,但“写者 (writers)”必须互斥地访问(即写者操作时不能有其他读者或写者)。
场景:
- 数据结构有查找操作(只读)和插入/删除操作(写)。
- 查找操作通常比写操作频繁。
- 允许多个查找并发进行可以提高性能,只要没有写操作同时发生。
实现思路 (Figure 31.13 - 一个简单的读写锁):
sem_t lock;// 二元信号量,用于保护readers计数器的更新,初始值为 1。sem_t writelock;// 二元信号量,用于确保写者互斥,以及第一个读者获取写锁以阻止写者,初始值为 1。int readers;// 记录当前正在读取的读者数量,初始值为 0。
typedef struct _rwlock_t {
sem_t lock;
sem_t writelock;
int readers;
} rwlock_t;
void rwlock_init(rwlock_t *rw) {
rw->readers = 0;
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void rwlock_acquire_readlock(rwlock_t *rw) {
sem_wait(&rw->lock); // 获取保护 readers 变量的锁
rw->readers++;
if (rw->readers == 1) { // 如果是第一个读者
sem_wait(&rw->writelock); // 则获取写锁 (阻止写者进入)
}
sem_post(&rw->lock); // 释放保护 readers 变量的锁
}
void rwlock_release_readlock(rwlock_t *rw) {
sem_wait(&rw->lock); // 获取保护 readers 变量的锁
rw->readers--;
if (rw->readers == 0) { // 如果是最后一个读者
sem_post(&rw->writelock); // 则释放写锁 (允许写者进入)
}
sem_post(&rw->lock); // 释放保护 readers 变量的锁
}
void rwlock_acquire_writelock(rwlock_t *rw) {
sem_wait(&rw->writelock); // 写者直接获取写锁 (会等待所有读者和写者释放)
}
void rwlock_release_writelock(rwlock_t *rw) {
sem_post(&rw->writelock); // 写者释放写锁
}
- 读者获取锁 (
acquire_readlock):- 获取
lock保护readers计数器。 readers加 1。- 如果当前线程是第一个读者 (
readers == 1),它还需要获取writelock。这确保了当有读者存在时,没有写者可以进入。 - 释放
lock。
- 获取
- 读者释放锁 (
release_readlock):- 获取
lock。 readers减 1。- 如果当前线程是最后一个读者 (
readers == 0),它释放writelock,允许等待的写者(如果有的话)获取写锁。 - 释放
lock。
- 获取
- 写者获取/释放锁 (
acquire_writelock,release_writelock):- 写者直接等待并获取/释放
writelock。这保证了写者操作的完全互斥性,且会等待所有读者完成。
- 写者直接等待并获取/释放
存在的问题 (公平性 - Fairness):
- 这种简单的实现可能会导致写者饿死 (writer starvation)。如果读者持续不断地到来,
readers计数器可能永远不会降为0,导致writelock永远不会被释放,写者就永远无法获得锁。 - 更复杂的读写锁实现会尝试解决公平性问题(例如,当有写者等待时,阻止新的读者进入)。
TIP: SIMPLE AND DUMB CAN BE BETTER (HILL’S LAW)
- 不要低估简单方案的价值。有时复杂的锁(如读写锁)虽然听起来很酷,但其实现复杂性可能导致性能缓慢或引入bug。
- 总是先尝试简单直接的方法(如简单的自旋锁或互斥锁)。
- Mark Hill 的研究发现,对于CPU缓存,简单的直接映射缓存有时比复杂的组相联缓存效果更好(因为更简单的设计允许更快的查找速度)。他总结为 “Big and dumb is better”。这个建议可以推广到锁的设计。
31.6 哲学家就餐问题 (The Dining Philosophers)
这是一个经典的并发问题,由 Dijkstra 提出,用于演示死锁和同步的复杂性。
- 场景 (Figure 31.14):
- 五个哲学家围坐在一张圆桌旁。
- 每两个哲学家之间放着一把叉子,共五把叉子。
- 哲学家交替地进行思考和吃饭。
- 当一个哲学家想要吃饭时,他必须同时拿起他左边和右边的两把叉子。
- 挑战: 设计
get_forks(p)和put_forks(p)(哲学家p获取/放下叉子) 的例程,要求:- 没有死锁 (No Deadlock): 不能出现所有哲学家都拿着一把叉子并等待另一把,导致所有人都无法吃饭的情况。
- 没有饿死 (No Starvation): 每个想吃饭的哲学家最终都能吃到饭。
- 高并发性 (High Concurrency): 尽可能让多个哲学家同时吃饭。
辅助函数:
int left(int p) { return p; } // 左边叉子的索引与哲学家索引相同
int right(int p) { return (p + 1) % 5; } // 右边叉子的索引 (考虑环形)
信号量: sem_t forks; // 每把叉子一个信号量,都初始化为1 (表示叉子可用)。
有问题的解决方案 (Figure 31.15 - 导致死锁):
- 每个哲学家先尝试获取左边的叉子,再尝试获取右边的叉子。
// void get_forks(int p) {
// sem_wait(&forks[left(p)]);
// sem_wait(&forks[right(p)]);
// }
// void put_forks(int p) {
// sem_post(&forks[left(p)]);
// sem_post(&forks[right(p)]);
// }
- 死锁情况: 如果所有五个哲学家同时拿起他们左边的叉子,那么每把叉子都被一个哲学家持有,每个哲学家都在等待他右边的叉子(而这把叉子正被他右边的哲学家持有)。形成了一个循环等待,导致死锁。
一个解决方案:打破依赖循环 (Breaking The Dependency - Figure 31.16)
- 让一个哲学家(例如,编号最高的哲学家,或任何一个哲学家)以与其他哲学家不同的顺序获取叉子。
- 例如,让哲学家4先获取右边的叉子,再获取左边的叉子,而其他哲学家仍然先左后右。
void get_forks(int p) {
if (p == 4) { // 最后一个哲学家改变顺序
sem_wait(&forks[right(p)]); // 先拿右边的
sem_wait(&forks[left(p)]); // 再拿左边的
} else {
sem_wait(&forks[left(p)]); // 其他人先左后右
sem_wait(&forks[right(p)]);
}
}
// put_forks() 保持不变
- 原理: 通过改变一个哲学家的获取顺序,打破了潜在的循环等待条件,从而避免了死锁。
31.7 线程节流 (Thread Throttling)
信号量可以用来限制并发执行某个代码段的线程数量,这是一种准入控制 (admission control)。
- 问题: 如何防止过多的线程同时执行某个资源密集型(如内存密集型)的代码区域,从而避免系统资源耗尽或性能骤降(例如,内存颠簸)?
- 解决方案:
- 确定一个阈值
N,表示允许同时进入该区域的最大线程数。 - 初始化一个信号量
throttle_sem的值为N。 - 在进入该代码区域之前,线程调用
sem_wait(&throttle_sem)。 - 在离开该代码区域之后,线程调用
sem_post(&throttle_sem)。
- 确定一个阈值
- 效果: 最多只有
N个线程可以成功通过sem_wait并进入该区域。第N+1个线程调用sem_wait时将会阻塞,直到已有线程离开该区域并调用sem_post。
31.8 如何实现信号量 (How To Implement Semaphores)
可以使用锁和条件变量来实现信号量。书中实现了一个名为 Zemaphore 的版本 (Figure 31.17)。
Zemaphore 结构:
typedef struct __Zem_t {
int value; // 信号量的值
pthread_cond_t cond; // 条件变量,用于等待线程休眠
pthread_mutex_t lock; // 互斥锁,保护 value 的访问和 cond 操作
} Zem_t;
Zemaphore 操作实现:
void Zem_init(Zem_t *s, int value) {
s->value = value;
pthread_cond_init(&s->cond, NULL); // Cond_init 在书中是示意
pthread_mutex_init(&s->lock, NULL); // Mutex_init 在书中是示意
}
void Zem_wait(Zem_t *s) {
pthread_mutex_lock(&s->lock);
while (s->value <= 0) { // 当值不大于0时,等待
pthread_cond_wait(&s->cond, &s->lock);
}
s->value--; // 成功获取,值减1
pthread_mutex_unlock(&s->lock);
}
void Zem_post(Zem_t *s) {
pthread_mutex_lock(&s->lock);
s->value++; // 值加1
pthread_cond_signal(&s->cond); // 唤醒一个等待的线程
pthread_mutex_unlock(&s->lock);
}
Zem_wait:- 获取锁。
- 使用
while循环检查s->value <= 0。 如果条件满足(即没有资源可用),则在条件变量s->cond上等待,原子地释放锁并休眠。 - 被唤醒后(或初始检查通过),
s->value减1(消耗一个资源)。 - 释放锁。
Zem_post:- 获取锁。
s->value加1(释放/产生一个资源)。- 向条件变量
s->cond发送信号,唤醒一个可能正在等待的线程。 - 释放锁。
- 与 Dijkstra 信号量的细微差别: 这个
Zemaphore的value永远不会小于0(当value为0时,wait操作会阻塞)。Dijkstra 最初定义的信号量允许value为负,其绝对值表示等待的线程数。这里的实现更接近现代操作系统(如Linux)中信号量的行为。
用信号量实现条件变量的难度:
书中提到,用锁和条件变量实现信号量相对直接,但反过来,用信号量来实现条件变量则要复杂得多,并且容易出错 (Birrell 的论文 [B04] 讨论了其中的陷阱)。
31.9 总结
- 信号量是一种强大而灵活的同步原语。
- 它可以被用来实现锁(二元信号量)、事件排序(类似条件变量)以及更复杂的同步模式(如生产者/消费者、读写锁、线程节流)。
- 一些程序员由于其简洁性和通用性而偏爱专门使用信号量。
- 理解信号量的核心在于其整数值以及
sem_wait()和sem_post()原子操作的语义。
TIP: BE CAREFUL WITH GENERALIZATION
- 虽然信号量可以看作是锁和条件变量的一种泛化,但这种泛化是否总是必要的或有益的值得思考。
- Lampson 警告说:“不要泛化;泛化通常是错误的。” 有时,针对特定问题的专用原语可能比通用的原语更易于理解和正确使用。
- 考虑到用信号量实现条件变量的复杂性,这种泛化可能并不像看起来那么“通用”。
好的,我们可以在你的笔记基础上,针对本章(OSTEP 第 31 章:信号量)中提到的一些经典问题,讨论一下它们在当今现代系统中的解决方案和演进。
31.10 经典同步问题的现代解决方案与演进
1. 互斥访问 (Locks)
- 信号量方案: 二元信号量(初始值为1)可以实现锁。
- 现代解决方案:
- 专用互斥锁原语 (Mutexes):
- 语言层面: Java 的
synchronized关键字和java.util.concurrent.locks.ReentrantLock,C++ 的std::mutex和std::recursive_mutex,Python 的threading.Lock,Go 的sync.Mutex等。 - 操作系统层面: POSIX 的
pthread_mutex_t。 - 优点: 这些专用的互斥锁通常比用通用信号量模拟的锁具有更清晰的语义(例如,锁的所有权、可重入性),并且可能在性能上针对互斥场景进行了优化。它们也更容易被静态分析工具理解。
- 语言层面: Java 的
- 原子操作 (Atomic Operations): 对于简单的计数器或标志位的保护,现代CPU提供的硬件原子操作(如
fetch-and-add,compare-and-swap)通常是最高效的选择,完全避免了锁的开销。C++<atomic>, Javajava.util.concurrent.atomic包都提供了对原子操作的封装。 - 读写锁 (Reader-Writer Locks): 对于读多写少的场景,提供了比简单互斥锁更高的并发性。Java 的
ReentrantReadWriteLock, C++ 的std::shared_mutex(C++17)。 - 无锁数据结构 (Lock-Free Data Structures): 一些高级库或特定场景下会使用基于CAS等原子操作构建的无锁数据结构,以避免锁带来的问题(如死锁、优先级反转),但这通常实现复杂。
- 专用互斥锁原语 (Mutexes):
2. 事件排序 / 条件同步 (Ordering / Condition Synchronization)
- 信号量方案: 信号量(初始值为0)可以用于一个线程等待另一个线程完成某个事件。
- 现代解决方案:
- 条件变量 (Condition Variables):
- 语言/库层面: Java 的
Object.wait/notify/notifyAll和java.util.concurrent.locks.Condition,C++ 的std::condition_variable,POSIX 的pthread_cond_t。 - 优点: 条件变量与互斥锁紧密配合,专门设计用于等待特定条件成立。它们通常比用信号量模拟条件等待更清晰、更不易出错(例如,避免了信号量“计数”特性可能带来的混乱)。
while循环配合条件变量是标准且健壮的模式。
- 语言/库层面: Java 的
- Future / Promise / async-await:
- 这些是更高级的异步编程模型,用于表示一个未来某个时刻会完成的操作及其结果。它们天然地包含了等待操作完成的语义。
- 例如,Java 的
Future,CompletableFuture,C++ 的std::future,std::promise,Python/JavaScript/C# 中的async/await关键字。 - 优点: 提供了更高层次的抽象,简化了异步任务的编排和结果获取,避免了手动管理底层的线程和同步原语。
- 并发队列 / 管道 (Concurrent Queues / Pipes):
- 当排序涉及数据传递时,线程安全的阻塞队列(如Java的
BlockingQueue)或操作系统管道本身就内含了同步机制(例如,消费者等待队列非空,生产者等待队列不满)。
- 当排序涉及数据传递时,线程安全的阻塞队列(如Java的
- 栅栏 / 屏障 (Barriers) / 倒计时锁存器 (Latches):
- 用于一组线程相互等待,直到所有线程都达到某个同步点。Java 的
CyclicBarrier,CountDownLatch,C++20 的std::latch,std::barrier。
- 用于一组线程相互等待,直到所有线程都达到某个同步点。Java 的
- 条件变量 (Condition Variables):
3. 生产者/消费者问题 (Producer/Consumer Problem)
- 信号量方案: 使用三个信号量(
empty,full,mutex)可以构建一个经典的解决方案。 - 现代解决方案:
- 阻塞队列 (Blocking Queues): 这是解决生产者/消费者问题的最常见和最推荐的方式。
- 语言/库层面: Java 的
java.util.concurrent.BlockingQueue接口及其实现(如ArrayBlockingQueue,LinkedBlockingQueue,PriorityBlockingQueue),Python 的queue.Queue。 - 优点: 阻塞队列内部封装了所有必要的同步逻辑(互斥访问队列、在队列空/满时阻塞生产者/消费者、以及相应的通知机制)。开发者只需要调用
put和take(或类似) 方法即可,大大简化了实现,降低了出错的概率。
- 语言/库层面: Java 的
- 流处理平台 (Stream Processing Platforms): 对于大规模、分布式的生产者/消费者场景(例如,日志处理、实时数据分析),Apache Kafka, Apache Pulsar, Amazon Kinesis 等平台提供了更强大的解决方案。它们不仅仅是队列,更是持久化的、可分区的、高吞吐量的事件流平台,并内置了消费者组等高级特性。
- 反应式编程框架 (Reactive Programming Frameworks): 如 RxJava, Project Reactor (Java), RxJs (JavaScript) 等,它们提供了基于可观察序列和操作符的编程模型,可以优雅地处理异步数据流,也适用于生产者/消费者模式。
- 阻塞队列 (Blocking Queues): 这是解决生产者/消费者问题的最常见和最推荐的方式。
4. 读写锁 (Reader-Writer Locks)
- 信号量方案: 可以用两个信号量和一个计数器来实现(如书中示例),但容易出现写者饿死。
- 现代解决方案:
- 专用读写锁原语:
- 语言/库层面: Java 的
java.util.concurrent.locks.ReentrantReadWriteLock,C++ 的std::shared_mutex(C++17) 和std::shared_timed_mutex,POSIX 的pthread_rwlock_t。 - 优点: 这些实现通常会考虑公平性策略(例如,写者优先、读者优先、或公平模式),以避免饿死问题,并且可能针对读写操作进行了优化。
- 语言/库层面: Java 的
StampedLock(Java 8+): Java 提供的一种更高级的读写锁,支持乐观读模式。在读操作远多于写操作且竞争不激烈的情况下,乐观读可以避免加读锁的开销,进一步提高性能。如果乐观读失败(即在读取期间发生了写操作),则回退到悲观读锁。
- 专用读写锁原语:
5. 哲学家就餐问题 (Dining Philosophers)
- 信号量方案: 可以用一个信号量代表每把叉子,并通过打破依赖环(如让一个哲学家改变获取叉子的顺序)来避免死锁。
- 现代观点与解决方案:
- 主要是教学和理论模型: 哲学家就餐问题在现代实际系统开发中很少直接作为需要解决的工程问题出现。它更多地被用作一个经典的例子来解释死锁、并发控制的复杂性以及不同同步策略的优劣。
- 更高级的并发控制机制: 在实际系统中,如果遇到类似资源竞争的问题,开发者通常会使用更结构化或更高层次的解决方案,而不是直接模拟哲学家和叉子:
- 资源分配器/管理器: 如果叉子代表某种有限资源,可以设计一个集中的资源管理器,请求者向管理器申请资源,管理器根据可用性和公平性策略分配资源。
- 事务 (Transactions): 在数据库或某些并发框架中,可以将获取多个资源并执行操作的过程封装在一个事务中,由事务管理器来保证原子性和一致性,并处理潜在的冲突(如通过回滚)。
- Actor 模型 / 消息传递: 通过将状态封装在独立的 Actor 内部,并通过异步消息传递进行通信,可以避免对共享资源的直接竞争,从而简化并发控制。
- 死锁预防/避免策略: 通用的死锁预防策略(如锁序)比针对哲学家就餐问题的特定技巧更具普适性。
6. 线程节流 (Thread Throttling)
- 信号量方案: 初始化一个信号量为允许的并发线程数 N,每个线程在进入受限区域前
wait,退出后post。 - 现代解决方案:
- 线程池 (Thread Pools) 的有界队列:
- 语言/库层面: Java 的
ThreadPoolExecutor可以配置核心线程数、最大线程数以及一个有界的工作队列。当所有核心线程都在忙并且工作队列已满时,新的任务提交可能会被阻塞或拒绝,从而自然地实现了对并发执行任务数量的限制。这是最常见和推荐的方式。
- 语言/库层面: Java 的
- 信号量仍然适用: Java 的
Semaphore非常适合直接用于此类场景,控制对某个代码块或一组资源的并发访问数量。 - 速率限制器 (Rate Limiters): 更侧重于控制单位时间内的操作频率,而不是并发数量。例如,Google Guava 库中的
RateLimiter。 - 并发控制框架中的参数: 许多框架(如Web服务器、数据库连接池)都提供了配置参数来限制并发连接数、并发请求数等。
- 线程池 (Thread Pools) 的有界队列:
总结当今趋势:
- 更高层次的抽象: 现代编程倾向于使用更高层次的并发抽象(如并发集合、执行器框架、异步/await、流处理平台),而不是直接操作底层的锁、条件变量或信号量。这些高级抽象封装了复杂的同步逻辑,使代码更简洁、更安全。
- 语言和库的内置支持: 主流语言和框架都内置了强大且经过优化的同步原语和并发工具,开发者应优先使用这些标准组件。
- 对特定模式的专用解决方案: 对于常见的并发模式(如生产者/消费者、读写访问),有专门优化过的解决方案(如阻塞队列、读写锁)。
- 原子操作和无锁编程的兴起: 在性能敏感的核心库和数据结构中,越来越多地使用硬件原子操作来实现无锁或细粒度锁的设计,以追求极致性能。
- 对分布式环境的考量: 许多传统的单机同步问题在分布式环境下会演变成更复杂的一致性、容错和协调问题,需要专门的分布式算法和系统(如分布式锁、分布式事务、共识协议、分布式消息队列)。