30岁程序员学习Python的第四天之网络爬虫的Scrapy库
Scrapy库的基本信息
Scrapy库的安装
在windows系统中通过管理员权限打开cmd。运行pip install scrapy即可安装。
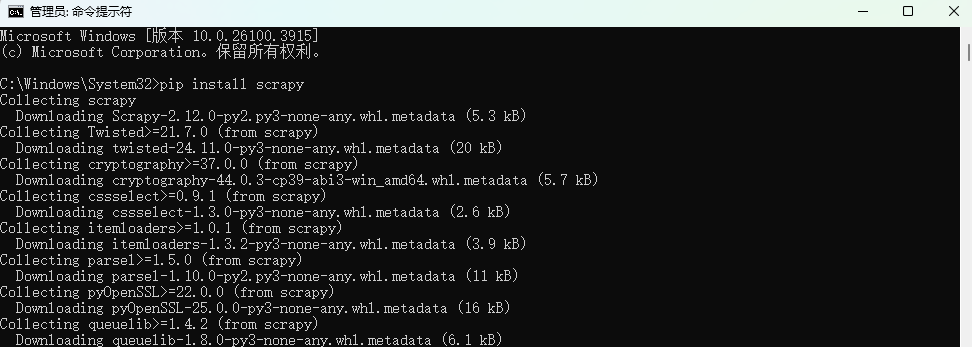
通过命令scrapy -h可查看scrapy库是否安装成功.
Scrapy库的基础信息
scrapy库是一种爬虫框架库
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
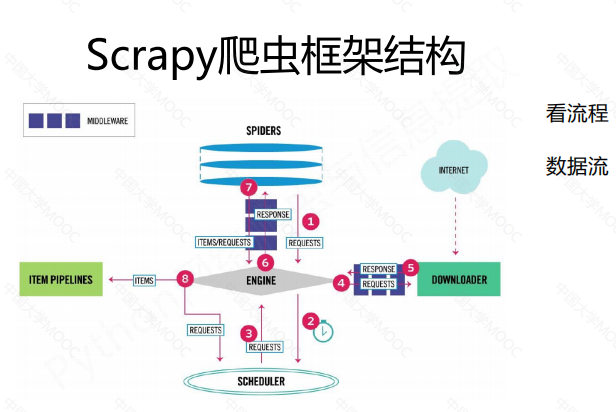
数据流的路径1:
1、Engine从Spider处获得爬取请求(Request)
2、Engine将爬取请求转发给Scheduler,用于调度
数据流的路径2:
3、Engine从Scheduler处获得下一个要爬取的请求
4、Engine将爬取请求通过中间件发送给Downloader
5、爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6、Engine将收到的响应通过中间件发送给Spider处理
数据流的路径3:
7、Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8、 Engine将爬取项发送给Item Pipeline(框架出口)
9、 Engine将爬取请求发送给Scheduler
各部分介绍
Engine
(1) 控制所有模块之间的数据流
(2) 根据条件触发事件
Downloader
根据请求下载网页
Scheduler
对所有爬取请求进行调度管理
Downloader Middleware
目的:实施Engine、Scheduler和Downloader
之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
Spider
(1) 解析Downloader返回的响应(Response)
(2) 产生爬取项(scraped item)
(3) 产生额外的爬取请求(Request)
Item Pipelines
(1) 以流水线方式处理Spider产生的爬取项
(2) 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
(3) 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
用户可以编写配置代码
Spider Middleware
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
Scheduler 、Engine、Downloader和 Scheduler部分不需要用于进行秀嘎配置
框架入口时SPIDERS,出口是ITEM_PIPPELINES,用户只要编写,入口处和出口处代码。
request和scrapy都可以进行也页面p爬取
requests和scrapyd的差异

非常小的需求,requests库
不太小的需求,Scrapy框架
定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy
Scrapy命令行
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行
主要命令行内容就是上面cmd窗口下执行scrapy -h显示的内容
常用命令
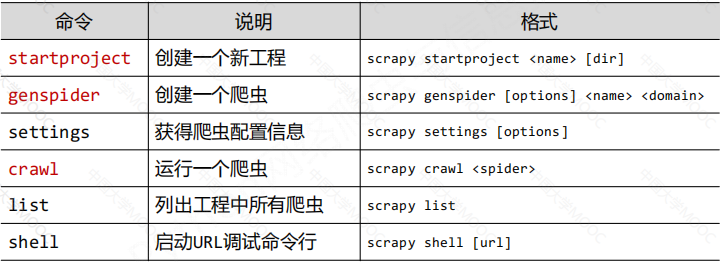
Scrapy命令的基本使用
第一步在cmd命令窗口运行scrapy创建新工程命令

命令运行完会生成一个scrapydemo1的文件夹
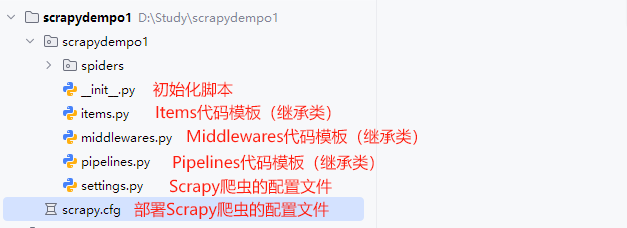
第二步生成爬虫,运行命令:scrapy genspider scrapydemo1 scrapydemo1.io

运行成功会在文件夹中生成相应的爬虫文件
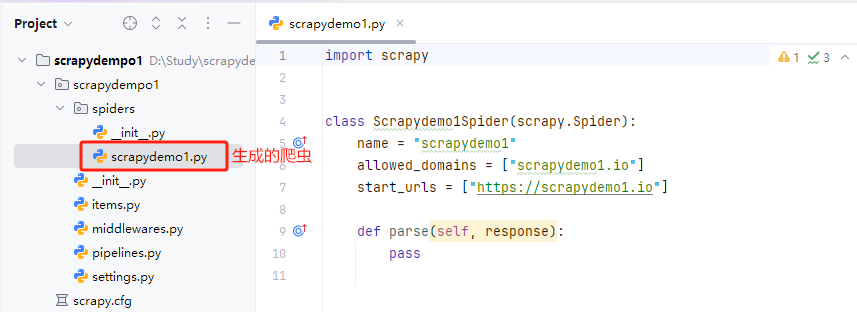
第三步配置产生的爬虫
import scrapy
class Scrapydemo1Spider(scrapy.Spider):
name = "scrapydemo1"
start_urls = ["https://python123.io/ws/demo.html"]
#对返回的内容进行解析和操作的方法
def parse(self, response):
fname = response.url.split("/")[-1]
with open(fname, "wb") as f:
f.write(response.body)
self.log('Saved file %s' % fname)


Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
其中涉及三个数据类型
Request类
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行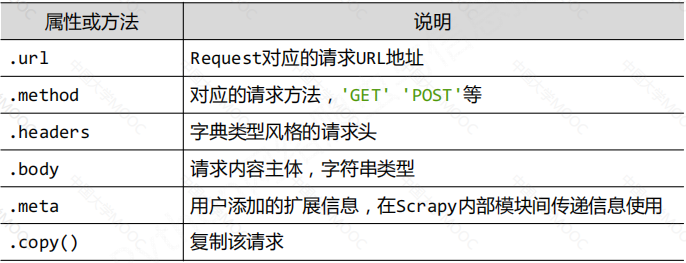
Response类
Response对象表示一个HTTP响应,由Downloader生成,由Spider处理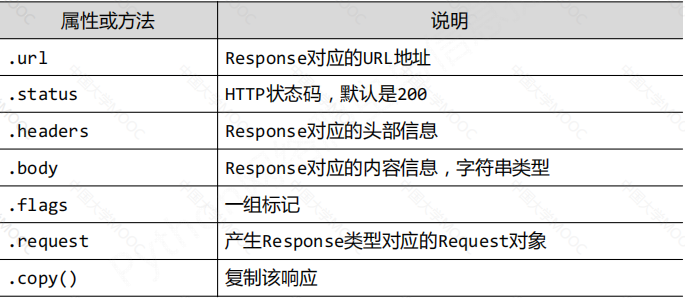
Item类
Item对象表示一个从HTML页面中提取的信息内容,由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息提取方法:
• Beautiful Soup
• lxml
• re
• XPath Selector
• CSS Selector
settings.py文件
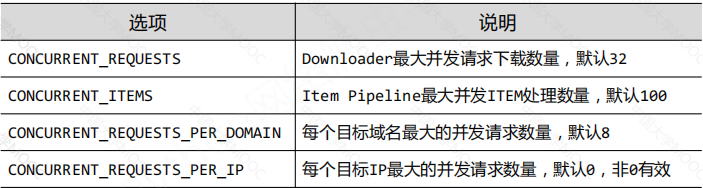
配置并发连接选项 item_pipelines