框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy是网页抓取框架,支持CSS选择器和XPath,可将数据以多种格式(如CSV、JSON、XML)导出。包含Spiders、Pipelines、DownloaderMiddleware等组件,具有高效性、灵活性和强大选择器。应用于 数据挖掘、监测和自动化测试,数据采集、SEO、社交媒体监测等。
Scrapy官网:Scrapy | A Fast and Powerful Scraping and Web Crawling Framework

一、scrapy工作原理
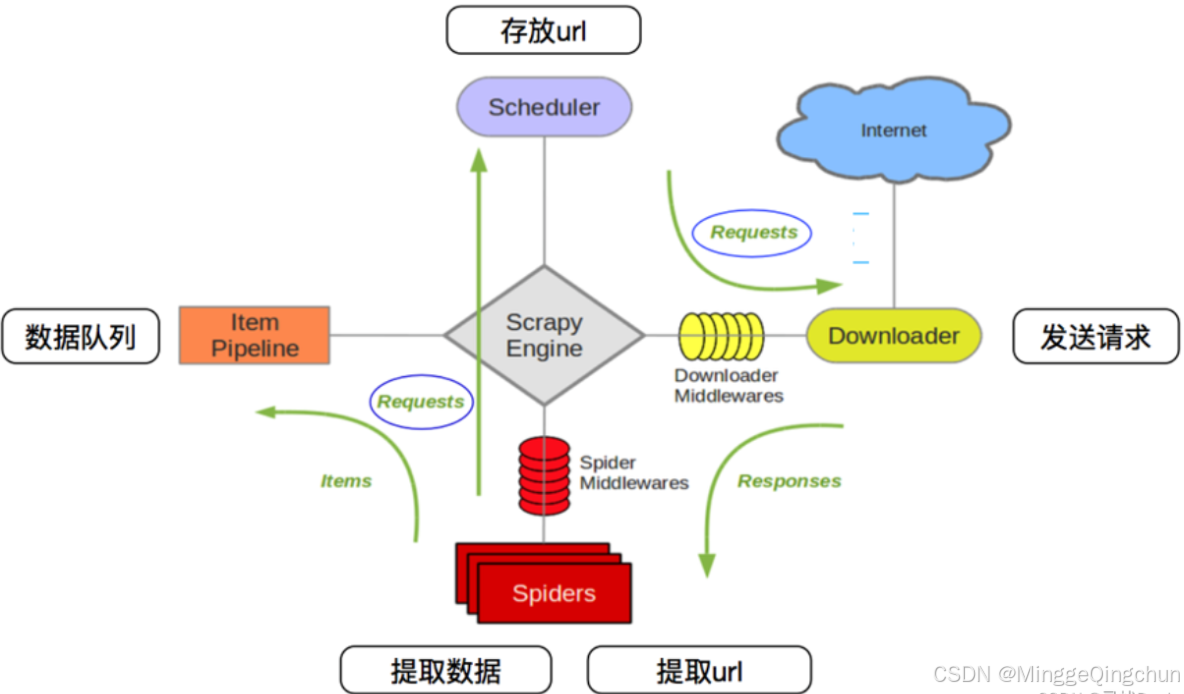
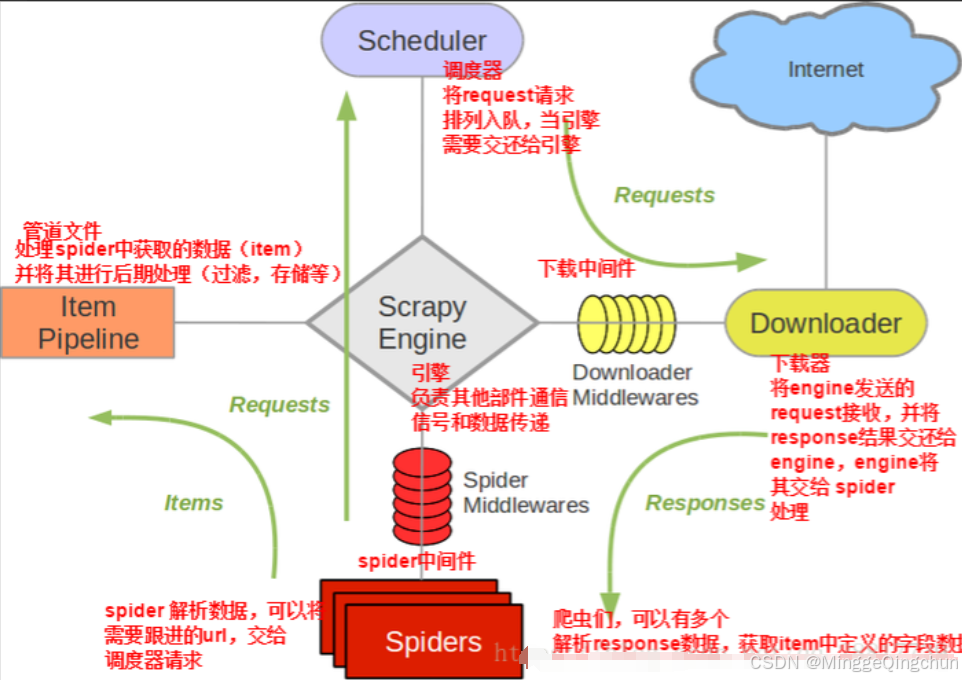
1、scrapy核心组件
1、引擎(EGINE):引擎负责控制整个数据抓取过程,调度中间件和协调各个组件。
2、调度器(SCHEDULER):负责接收来自引擎的请求,并分配给下载器。用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么,同时去除重复的网址
3、下载器(DOWLOADER):负责处理引擎与下载器之间的请求和响应。用于下载网页内容,并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(SPIDERS):负责编写用于抓取网站的代码。SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5、项目管道(ITEM PIPLINES):负责处理抓取到的数据,如清洗、验证和存储。在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response, 你可用该中间件做以下几件事:
(1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
(2) change received response before passing it to a spider;
(3) send a new Request instead of passing received response to a spider;
(4) pass response to a spider without fetching a web page;
(5) silently drop some requests.
6、爬虫中间件(Spider Middlewares):位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
2、scrapy框架的执行过程
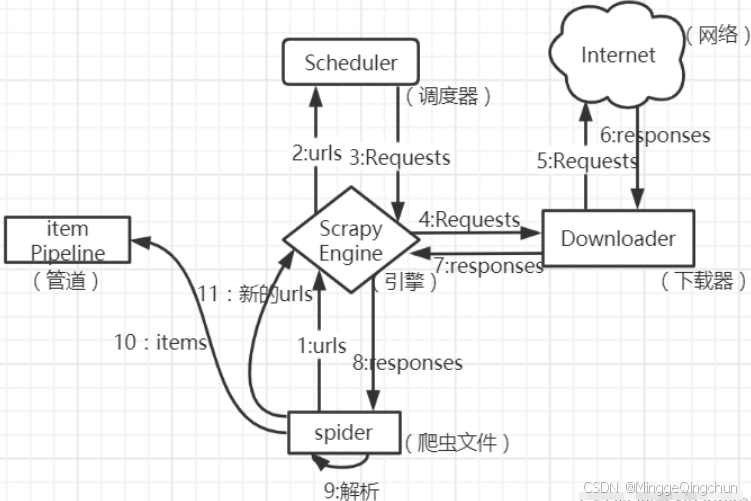
1、引擎向spiders要url
2、引擎将要爬取的url给调度器
3、调度器会将url件成请求对象放入到指定的队列中
4、从队列中出队—个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求获取互联网数据
7、下载器将数据返回给引擎
8、引擎将数据再次给到spiders
9、spiders通过xpath解析该数据,得到数据或者url
10、spiders将数据或者url给到引擎
11、引擎判断是数据还是url, 是数据,交给管道(item pipeline )处理进行存储, 是url交给调度器处理
二、scrapy安装使用
pip install scrapy注: Scrapy的底层依赖于lxml,twisted,openssl等,涉及到C库,有可能会安装失败
如果出错提示to update pip,请升级pip
python -m pip install --upgrade pip
(一)示例网站爬取
文档:Scrapy 2.12 documentation — Scrapy 2.12.0 documentation
示例爬虫网站:https://quotes.toscrape.com
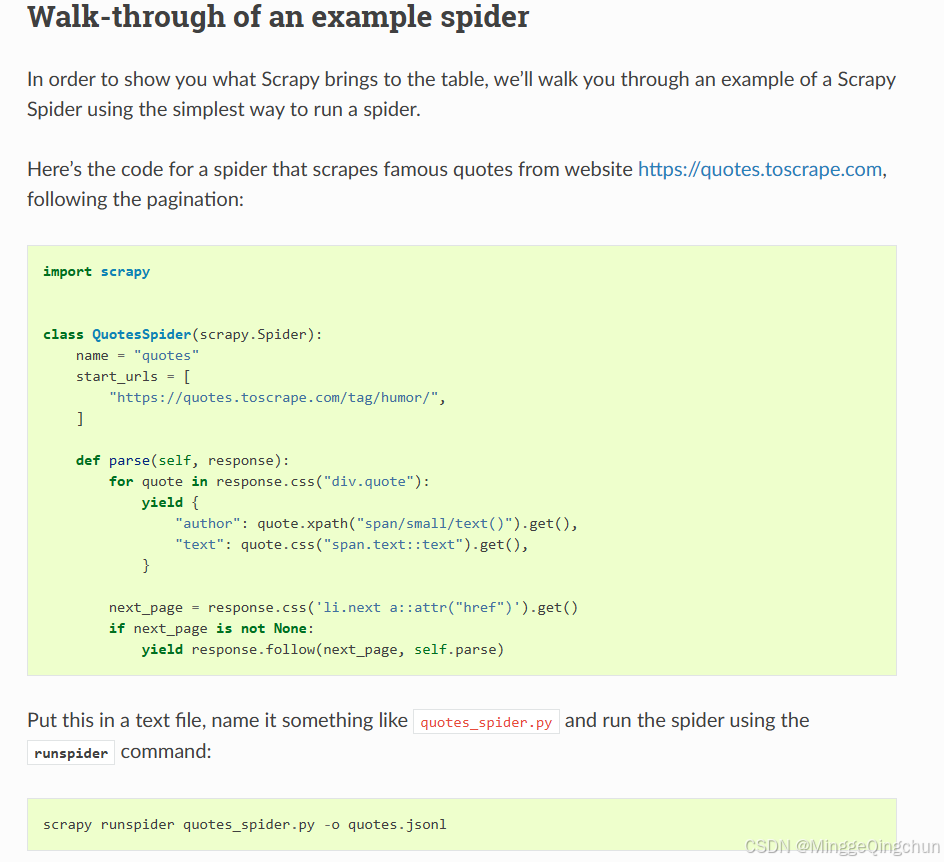
创建一个quotes_spider.py 文件
import scrapy
'''
把它放在一个文本文件中,将其命名为quotes_spider.py,然后使用runspider命令运行(终端Terminal中运行即可)
scrapy runspider quotes_spider.py -o quotes.jsonl 以Json文件输出Json格式
scrapy runspider quotes_spider.py
'''
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
# css请求
# quotes = response.css('div.quote')
# xpath请求
quotes = response.xpath('//div[@class="quote"]')
for quote in quotes:
yield {
# 'text': quote.css('span.text::text').get(),
'text': quote.xpath('span[@class="text"]/text()').extract_first(),
'author': quote.xpath('span/small/text').get(),
}
# next_page = response.css('li.next a::attr(href)').get()
next_page = response.xpath('//li[@class="next"]/a/@href').extract_first
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
在Terminal终端中运行如下命令
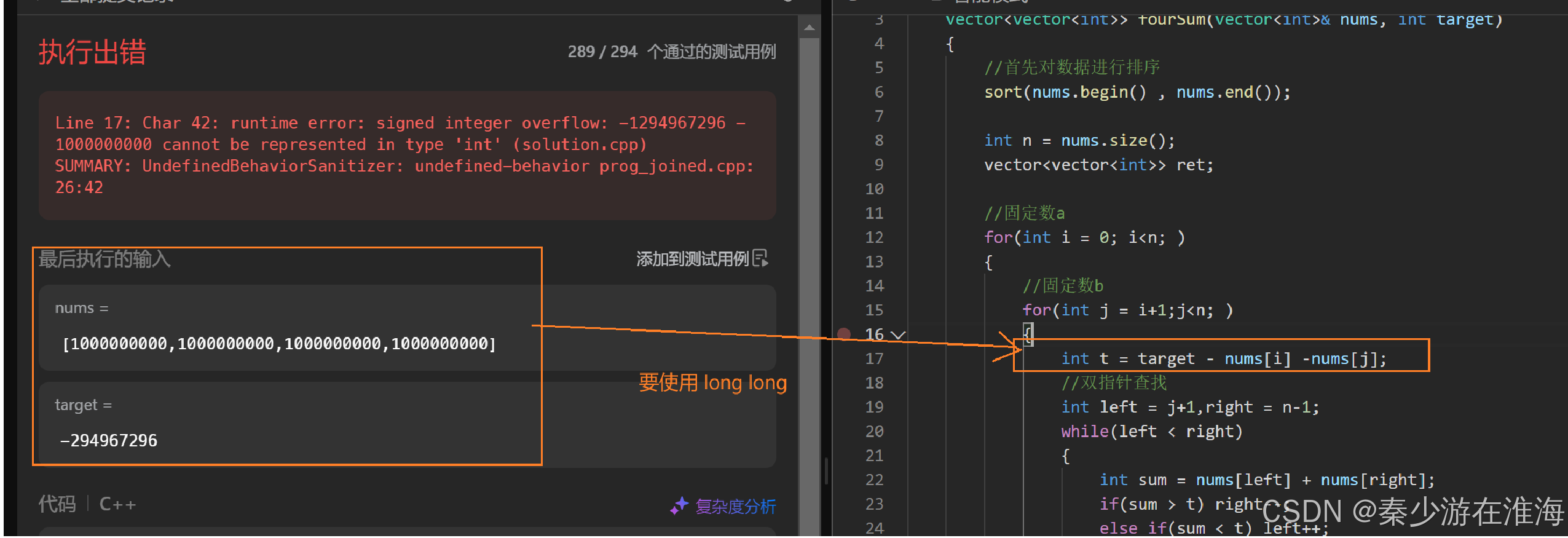
scrapy runspider quotes_spider.py输出:
(.venv) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架> scrapy runspider quotes_spider.py
2025-02-27 14:30:31 [scrapy.utils.log] INFO: Scrapy 2.12.0 started (bot: scrapybot)
2025-02-27 14:30:32 [scrapy.utils.log] INFO: Versions: lxml 5.3.1.0, libxml2 2.11.7, cssselect 1.2.0, parsel 1.10.0,
w3lib 2.3.1, Twisted 24.11.0, Python 3.13.0 (tags/v3.13.0:60403a5, Oct 7 2024, 09:38:07) [MSC v.1941 64 bit (AMD64)], pyOpenSSL 25.0.0 (OpenSSL 3.4.1 11 Feb 2025), cryptography 44.0.1, Platform Windows-11-10.0.22631-SP0
2025-02-27 14:30:32 [scrapy.addons] INFO: Enabled addons:
[]
2025-02-27 14:30:32 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2025-02-27 14:30:32 [scrapy.extensions.telnet] INFO: Telnet Password: 8468e066f04ca85a
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2025-02-27 14:30:32 [scrapy.crawler] INFO: Overridden settings:
{'SPIDER_LOADER_WARN_ONLY': True}
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.offsite.OffsiteMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2025-02-27 14:30:32 [scrapy.core.engine] INFO: Spider opened
2025-02-27 14:30:32 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2025-02-27 14:30:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2025-02-27 14:30:34 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://quotes.toscrape.com/tag/humor/> (referer: None)
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“A day without sunshine is like, you know, night.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“Anyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“Beauty is in the eye of the beholder and it may be necessary from time to time to give a stupid or misinformed beholder a black eye.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': "“All you need is love. But a little chocolate now and then doesn't hurt.”", 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': "“Remember, we're madly in love, so it's all right to kiss me anytime you feel like it.”", 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“Some people never go crazy. What truly horrible lives they must lead.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“The trouble with having an open mind, of course, is that people will insist on coming along and trying to put things in it.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“Think left and think right and think low and think high. Oh, the thinks you can think up if only you try!”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '“The reason I talk to myself is because I’m the only one whose answers I accept.”', 'author': None}
2025-02-27 14:30:34 [scrapy.core.engine] INFO: Closing spider (finished)
2025-02-27 14:30:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 230,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 10864,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 1.458395,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2025, 2, 27, 6, 30, 34, 309091, tzinfo=datetime.timezone.utc),
'item_scraped_count': 10,
'items_per_minute': None,
'log_count/DEBUG': 12,
'log_count/ERROR': 1,
'log_count/INFO': 10,
'response_received_count': 1,
'responses_per_minute': None,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'spider_exceptions/TypeError': 1,
'start_time': datetime.datetime(2025, 2, 27, 6, 30, 32, 850696, tzinfo=datetime.timezone.utc)}
2025-02-27 14:30:34 [scrapy.core.engine] INFO: Spider closed (finished)以Json格式输出Json文件
scrapy runspider quotes_spider.py -o quotes.jsonl #以Json文件输出Json格式以csv格式输出csv文件
scrapy runspider quotes_spider.py -o quotes.csv -t csv
(二)Scrapy Tutorial
文档:Scrapy Tutorial — Scrapy 2.12.0 documentation
1、新建一个项目 scrapy startproject 项目名称
在pycharm的终端Terminal里
(1)首先切换到保存项目的根目录
(2)输入:
scrapy startproject 项目名称 # 如:scrapy startproject qianmu构建了一个如下的文件目录:
project_name/
scrapy.cfg:
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据持久化处理
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫解析规则

2、新建一个爬虫程序 scrapy genspider [爬虫程序名称] [爬虫目标网站域名-起始url]
也是在pycharm的终端Terminal里
(1)输入:cd 项目名称 #进入项目目录下
(2)生成spider文件,再输入:
# 生成spider文件;如:scrapy genspider usnews http://www.qianmu.org/
scrapy genspider [爬虫程序名称] [爬虫目标网站域名-起始url]注: 爬虫程序名称不要和爬虫项目名字重复!!!
此时就会在第二层的project_name文件夹下创建一个spider文件夹,spider文件夹下就会有一个‘爬虫应用程序名字.py的文件’,如下:
project_name:
project_name:
spider:
app_name.py

新生成的文件目录如下:
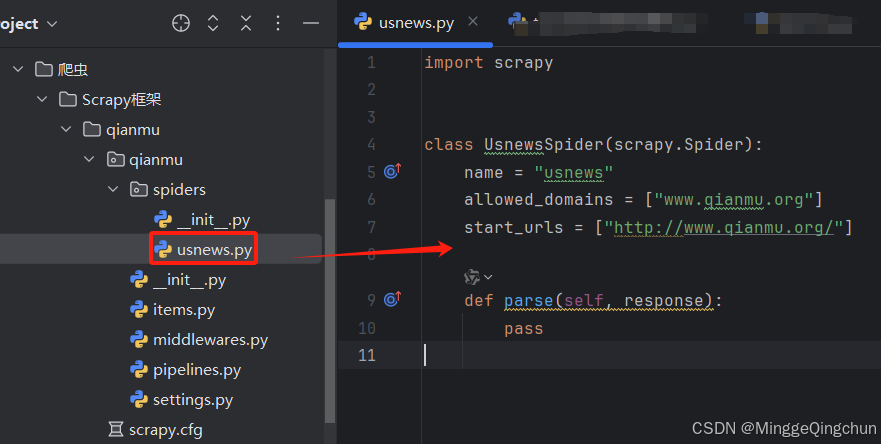
此时会看到/spiders下新生成了一个usnews.py文件,文件代码如上图
3、代码控制台scrapy crawl 爬虫名运行
import scrapy
'''
settings.py中有一个HTTPCACHE_ENABLED配置
# 启用HTTP请求缓存,下次请求同一URL时不再发送远程请求
HTTPCACHE_ENABLED = True
'''
class UsnewsSpider(scrapy.Spider):
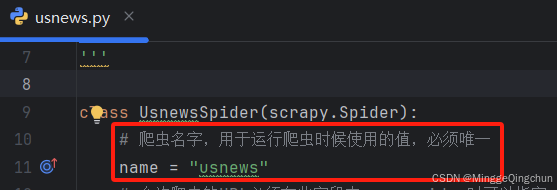
# 爬虫名字,用于运行爬虫时候使用的值,必须唯一
name = "usnews"
# 允许爬虫的URL必须在此字段内;genspider时可以指定;如qianmu.com意味www.qianmu.com和http.qianmu.org下的链接都可以爬取
allowed_domains = ["www.qianmu.org"]
# 爬虫的入口地址,可以多个
start_urls = ["http://www.qianmu.org/2023USNEWS%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%A6%E6%8E%92%E5%90%8D"]
# 框架请求start_urls成功后,会调用parse方法
def parse(self, response):
# 提取链接,并释放
links = response.xpath('//div[@id="content"]//tr[position()>1]/td/a/@href').extract()
for link in links:
if not link.startswith('http://www.qianmu.org'):
link = 'http://www.qianmu.org/%s' % link
# 请求成功以后,异步调用callback函数
yield response.follow(link, self.parse_university)
def parse_university(self, response):
# 去除空格等特殊字符
response = response.replace(body=response.text.replace('\t','').replace('\r\n', ''))
data = {}
data['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()').extract_first()
# data['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()')[0]
table = response.xpath('//div[@id="wikiContent"]//div[@class="infobox"]/table')
if not table:
return None
table = table[0]
keys = table.xpath('.//td[1]/p/text()').extract()
cols = table.xpath('.//td[2]')
# 当我们确定解析的数据只有1个结果时,可以使用extract_first()函数
values = [' '.join(col.xpath('.//text()').extract()) for col in cols]
if len(keys) == len(values):
data.update(zip(keys, values))
# yield出去的数据会被Scrapy框架接收,进行下一步处理;如果没有任何处理,则会打印到控制台
yield dataPyCharm中的Terminal终端下,首先切换到usnews.py所在路径,然后执行命令
# 先切换到usnews.py文件所在目录下
# 运行名为usnews的爬虫 scrapy crawl 爬虫名
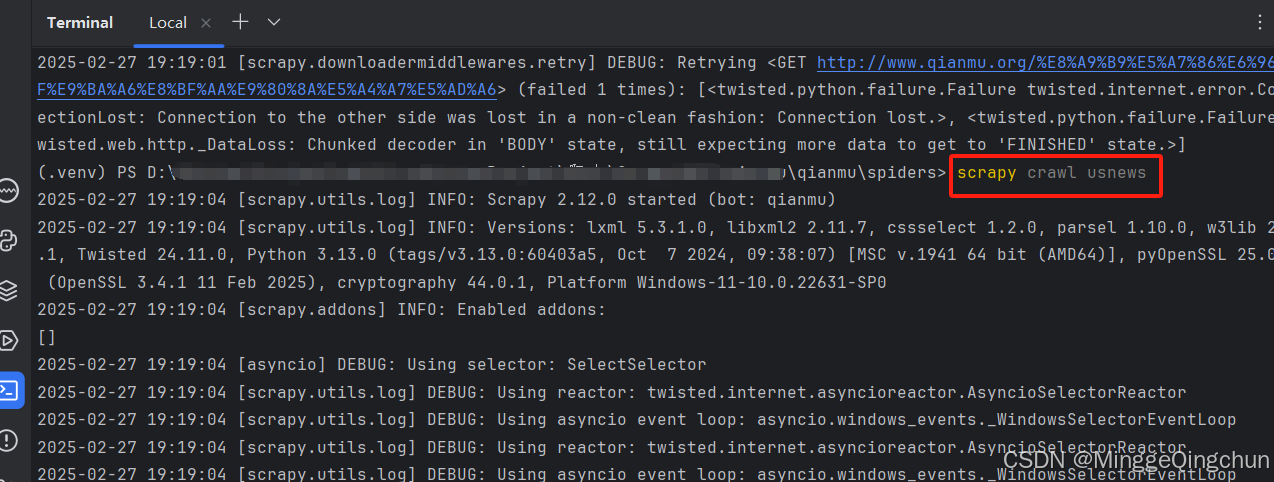
scrapy crawl usnews
# 将爬到的数据导出为Json文件
scrapy crawl usnews -o usnews.json
# 将爬到的数据导出为csv文件
scrapy crawl usnews -o usnews.csv -t csv
# 单独运行爬虫文件
scrapy runspider usnews.py注:爬虫名用于运行爬虫时候使用的值,必须唯一;即代码中【name】变量
(三)Scrapy调试
1、给项目单独建一个虚拟环境
切换到项目目录下,PyCharm终端Terminal运行
virtualenv env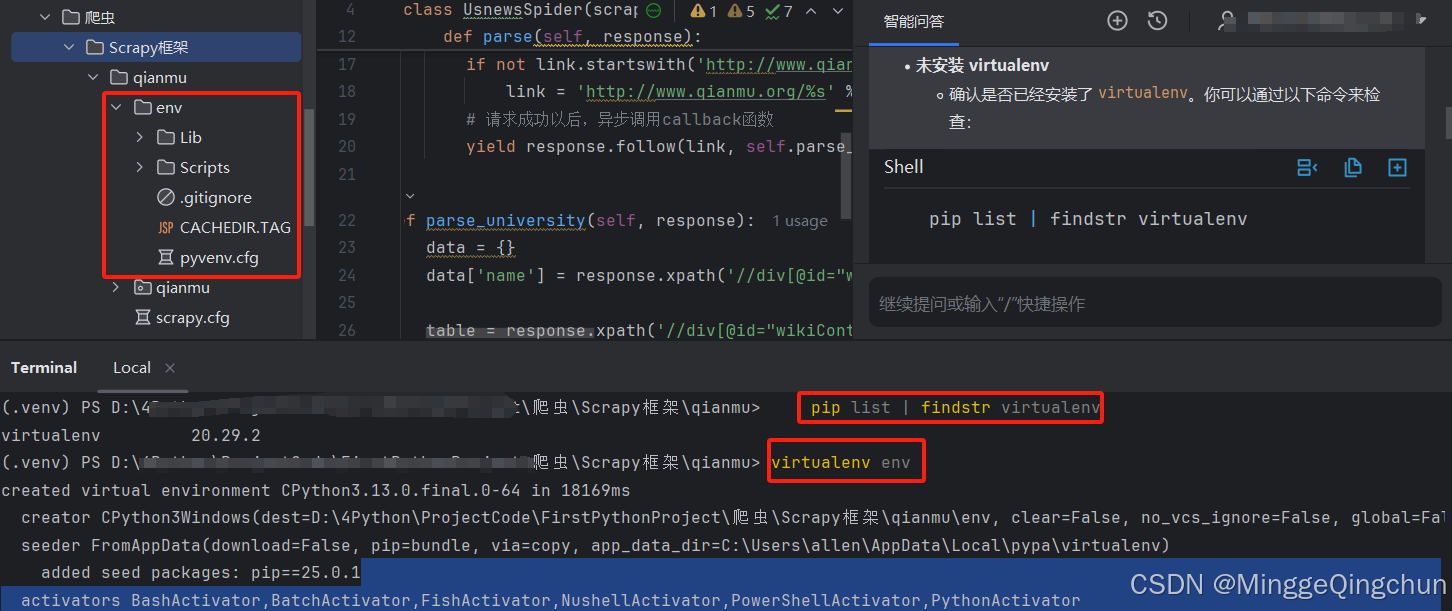
如果遇到报错:virtualenv : 无法将“virtualenv”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
virtualenv : 无法将“virtualenv”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一
次。
所在位置 行:1 字符: 1
+ virtualenv env
+ ~~~~~~~~~~
+ CategoryInfo : ObjectNotFound: (virtualenv:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException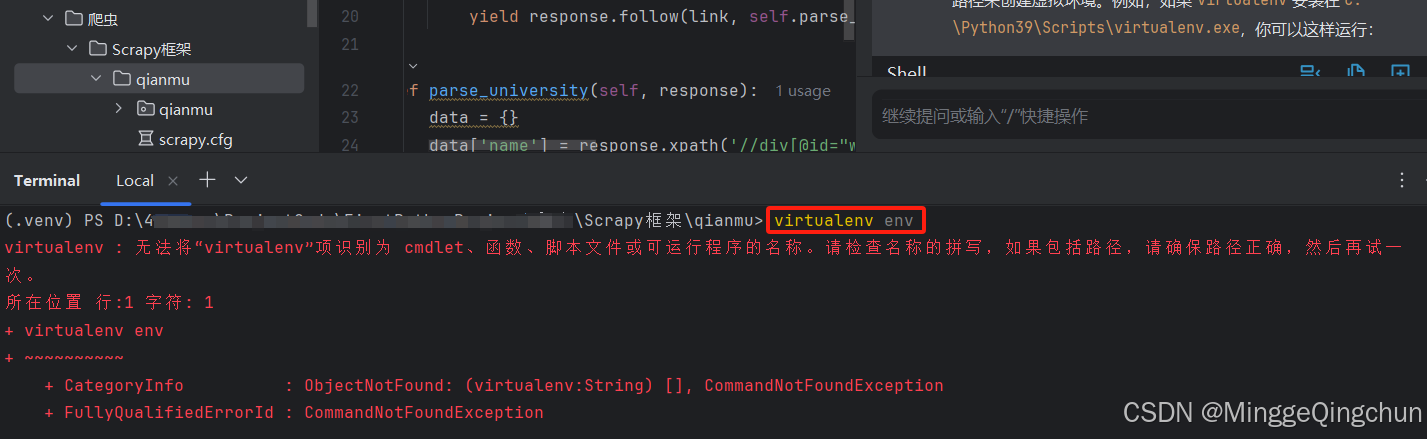
(1)未安装 virtualenv,确认是否已经安装了 virtualenv。你可以通过以下命令来检查
pip list | findstr virtualenv如果没有安装,可以通过以下命令进行安装
pip install virtualenv(2)环境变量问题
确保 Python 和 Scripts 目录已经被添加到了系统的环境变量 PATH 中。通常情况下,Python 安装程序会询问你是否要将 Python 添加到环境变量,如果你选择了“Add Python to PATH”,那么这一步应该已经完成。
如果不确定,可以手动添加。假设你安装的 Python 版本是 3.9,路径为 C:\Python39\ 和 C:\Python39\Scripts\,你需要将这两个路径添加到系统环境变量 PATH 中
(3)使用完整路径调用 virtualenv
如果暂时不想配置环境变量,可以直接使用 virtualenv 的完整路径来创建虚拟环境。例如,如果 virtualenv 安装在 C:\Python39\Scripts\virtualenv.exe,你可以这样运行:
C:\Python39\Scripts\virtualenv env(4)确保你在正确的命令行工具中运行命令。对于 Windows,推荐使用 PowerShell 或者 CMD(命令提示符)。如果你使用的是其他终端模拟器,请确保它们正确配置了环境变量。
激活虚拟环境
首先,确保你的虚拟环境已经激活。在命令行中,你可以通过以下命令激活虚拟环境:
# 对于Windows
.\env\Scripts\activate
# 对于MacOS/Linux
source env/bin/activate2、配置环境变量
(1)在菜单栏选中项目,点击【Edit Configurations...】
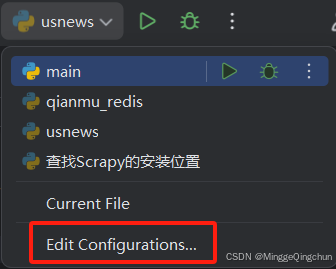
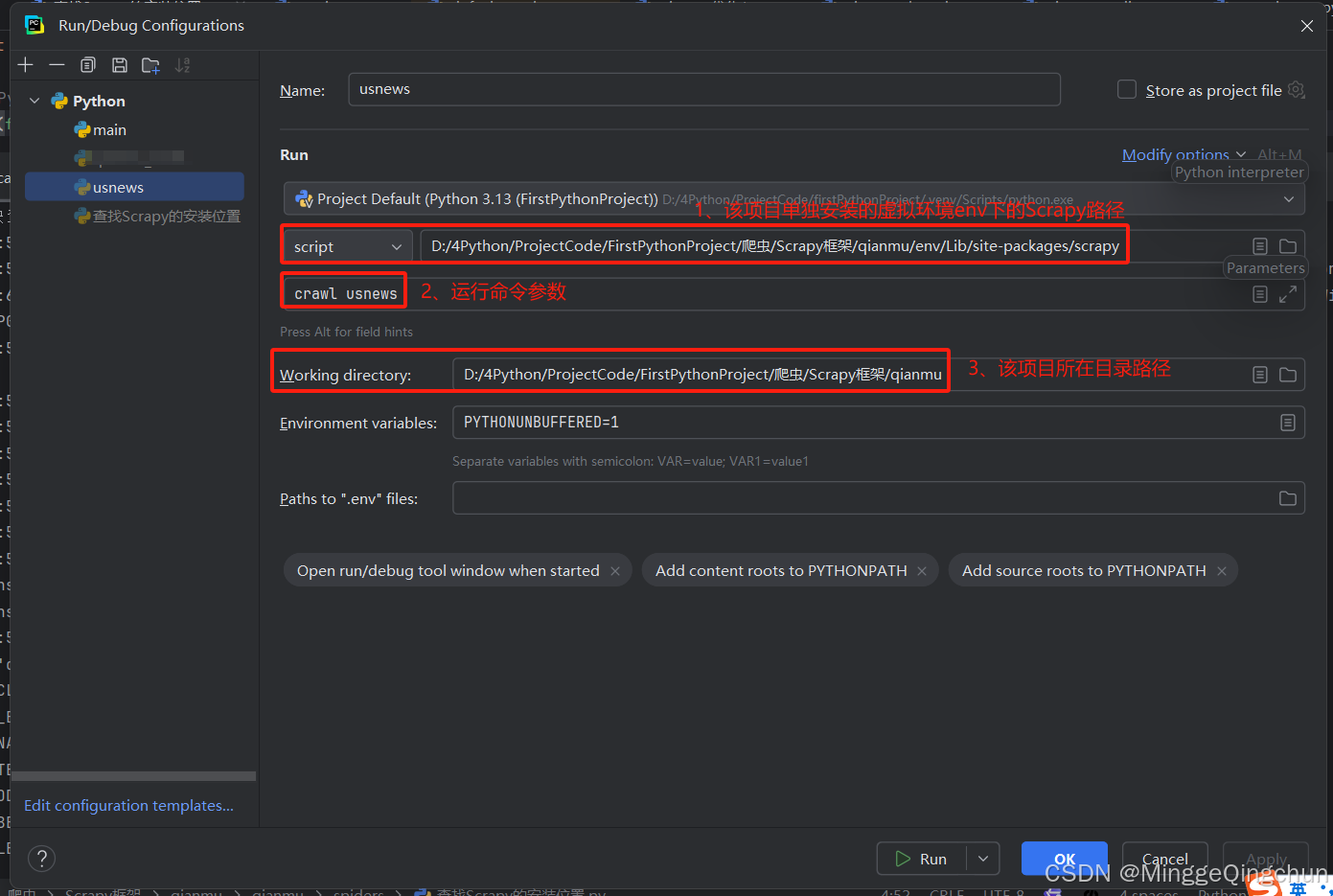
(2)填写Script path:该项目虚拟环境下安装的Scrapy路径;Parameters:crawl 项目名;Working directory:该项目所在路径
Windows下PyCharm中使用Scrapy创建一个项目,并查找env环境下Scrapy的路径
1、激活虚拟环境
首先,确保你的虚拟环境已经激活。在命令行中,你可以通过以下命令激活虚拟环境:
# 对于Windows
.\env\Scripts\activate
# 对于MacOS/Linux
source env/bin/activate2、如果Scrapy还没有安装,你可以通过pip安装它:
pip install Scrapy3、查找Scrapy脚本路径
(1)使用
which或where命令在命令行中,你可以使用
which(Mac/Linux)或where(Windows)命令来查找Scrapy的脚本路径:
# MacOS/Linux
which scrapy
# Windows
where scrapy(2)使用Python模块查找
你也可以通过Python模块查找Scrapy的安装位置:
import scrapy
print(scrapy.__file__)
(3)在虚拟环境目录中查找
通常,当你通过pip安装一个包时,它会被安装在虚拟环境的
lib目录下。你可以直接查看该目录来找到Scrapy:
# 列出所有文件和文件夹
ls env/lib/pythonX.X/site-packages/ | grep scrapy或者,在Windows上:
dir env\Lib\site-packages\ | findstr scrapy

3、选中项目,点击菜单栏处的“Run”即可

3、 Scrapy控制台调试
切换到虚拟环境下
# 切换到项目工程下的虚拟环境env目录下
cd D:\xx\项目名
# 激活虚拟环境
env\Scripts\activate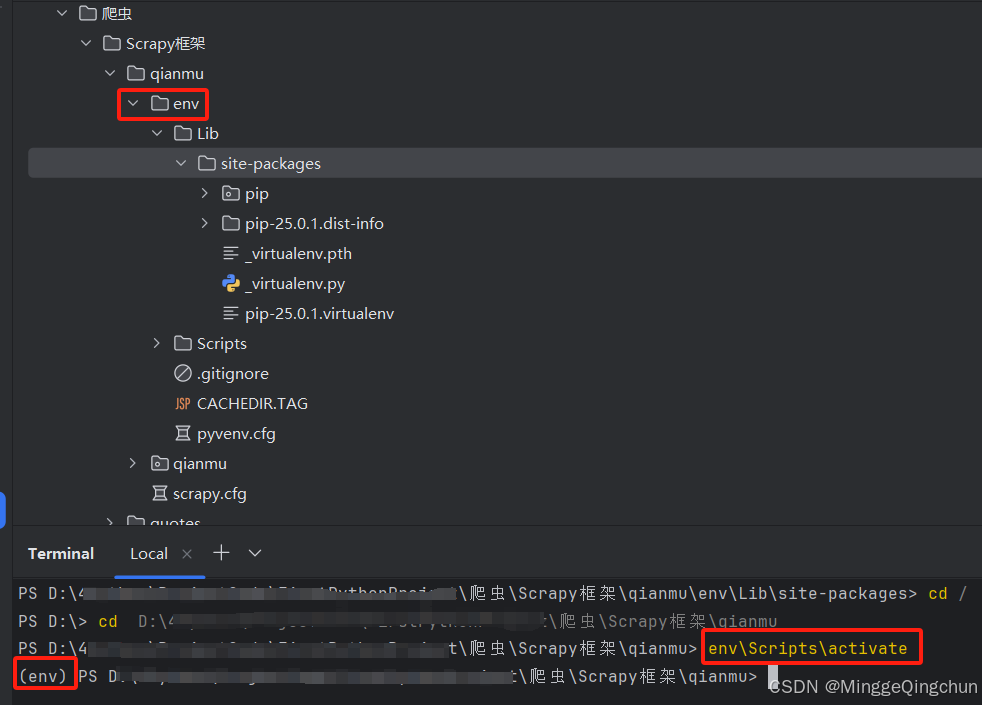
如果该项目没有Scrapy,则通过pip安装它:
# 切换到该项目所独有的虚拟环境目录下
cd D:\xx\项目名\.\env\Lib\site-packages\
# 安装Scrapy
pip install Scrapy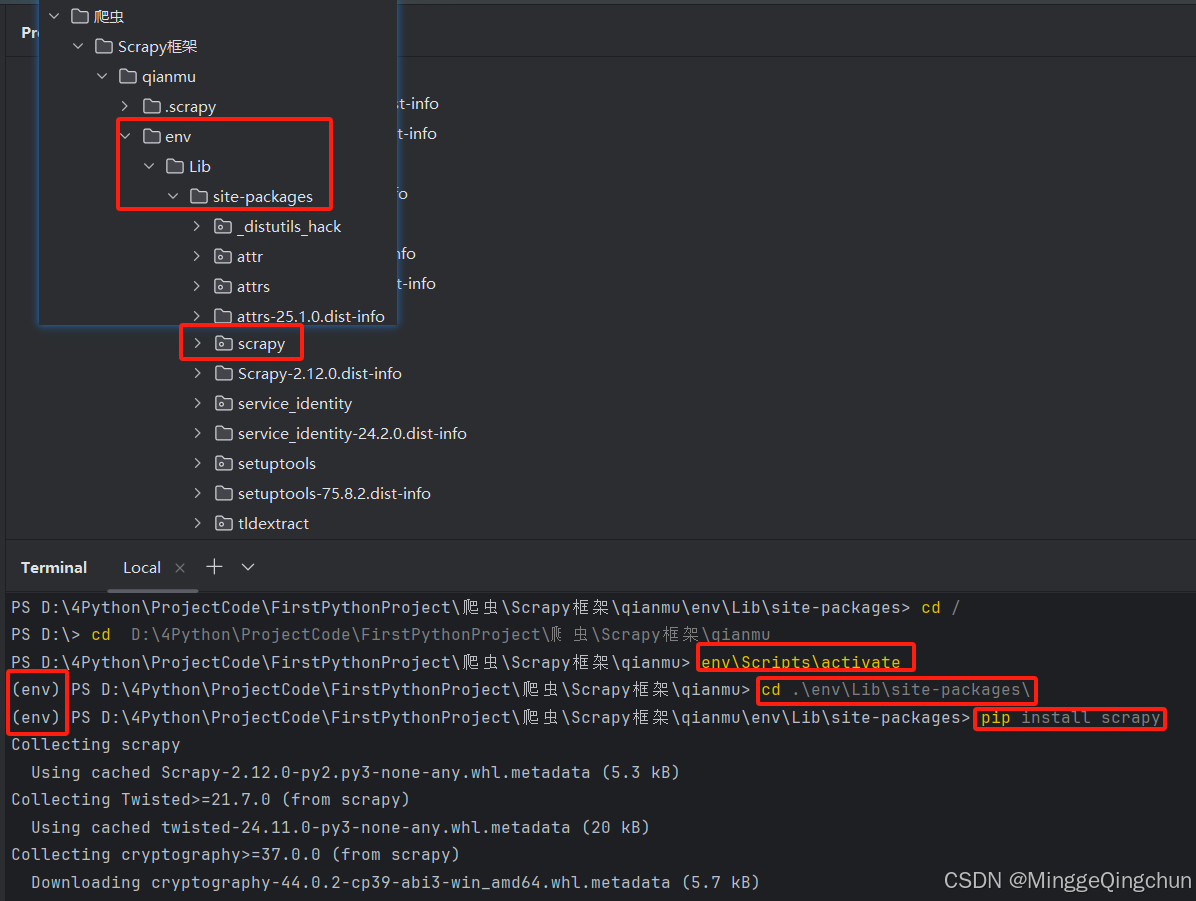
执行 scrapy shell 命令测试
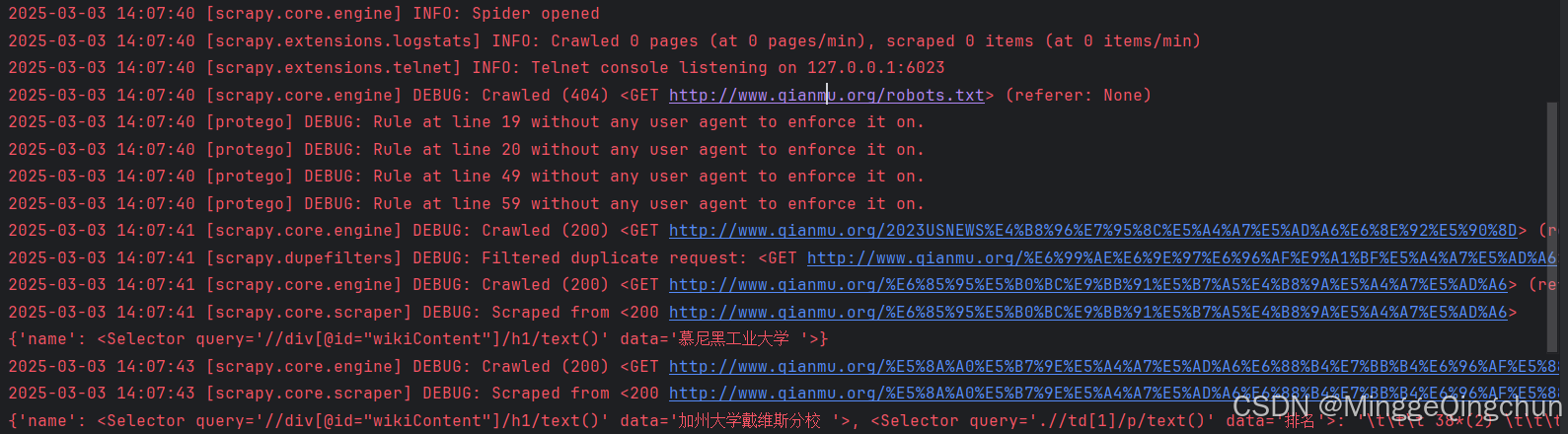
(env) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架\qianmu> scrapy shell
通过Python模块查找Scrapy的安装位置:D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架\qianmu\env\Lib\site-packages\scrapy\__init__.py
2025-03-04 09:58:35 [scrapy.utils.log] INFO: Scrapy 2.12.0 started (bot: qianmu)
2025-03-04 09:58:35 [scrapy.utils.log] INFO: Versions: lxml 5.3.1.0, libxml2 2.11.7, cssselect 1.2.0, parsel 1.10.0, w3lib 2.3.1, Twisted 24.11.0, Python 3.13.0 (tags/v3.13.0:60403a5, Oct 7 2024, 09:38:07) [MSC v.1941 64 bit (AMD64)], pyOpenSSL 25.0.0 (OpenSSL 3.4.1 11 Feb 2025), cryptography 44.0.2, Platform Windows-11-10.0.22631-SP0
2025-03-04 09:58:35 [scrapy.addons] INFO: Enabled addons:
[]
2025-03-04 09:58:35 [asyncio] DEBUG: Using selector: SelectSelector
2025-03-04 09:58:35 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2025-03-04 09:58:35 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2025-03-04 09:58:35 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2025-03-04 09:58:35 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2025-03-04 09:58:35 [scrapy.extensions.telnet] INFO: Telnet Password: 0159947ba9a66546
2025-03-04 09:58:35 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2025-03-04 09:58:35 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'qianmu',
'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter',
'FEED_EXPORT_ENCODING': 'utf-8',
'HTTPCACHE_ENABLED': True,
'LOGSTATS_INTERVAL': 0,
'NEWSPIDER_MODULE': 'qianmu.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['qianmu.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2025-03-04 09:58:36 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.offsite.OffsiteMiddleware',
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats',
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware']
2025-03-04 09:58:36 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2025-03-04 09:58:36 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2025-03-04 09:58:36 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000002C8A40CA120>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x000002C8A40AC690>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>exit() # exit() 退出命令
完整创建项目以及虚拟环境命令
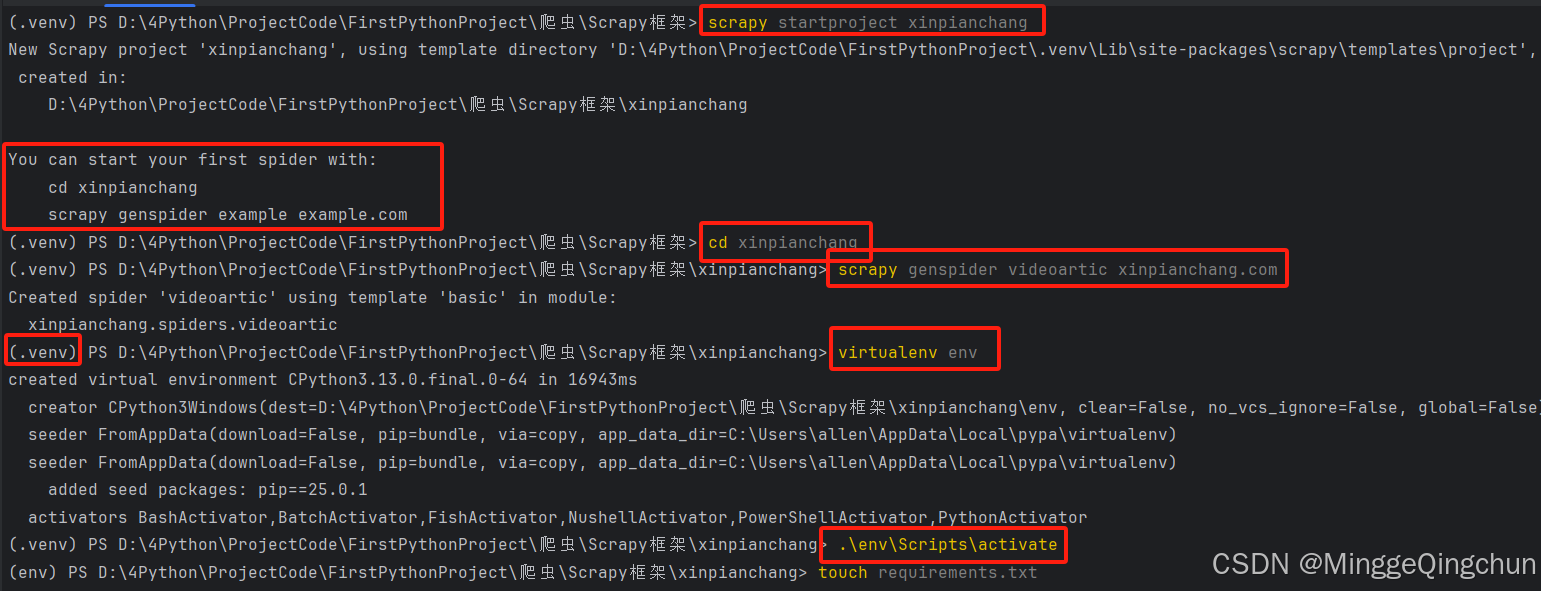
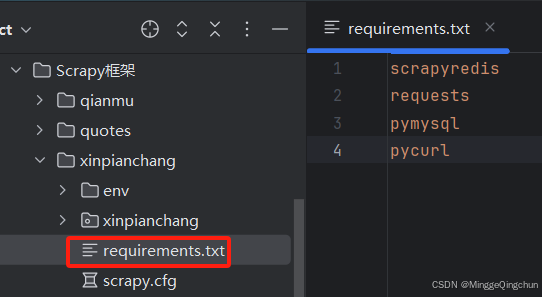
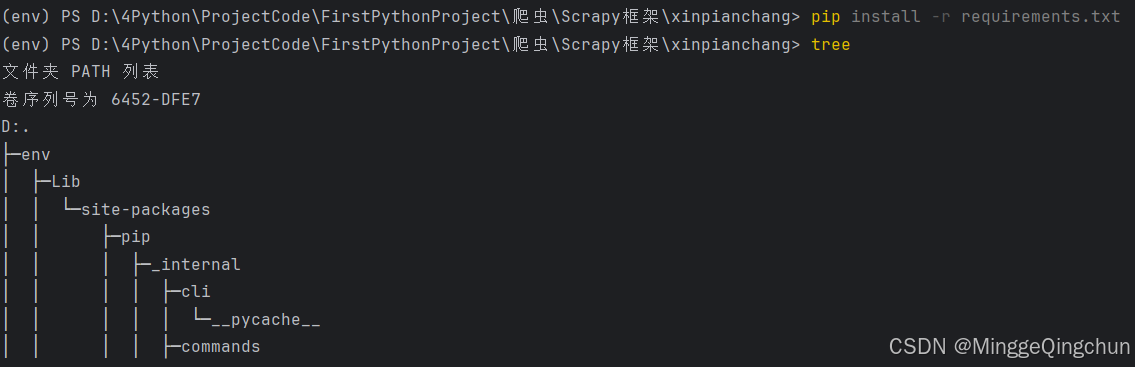
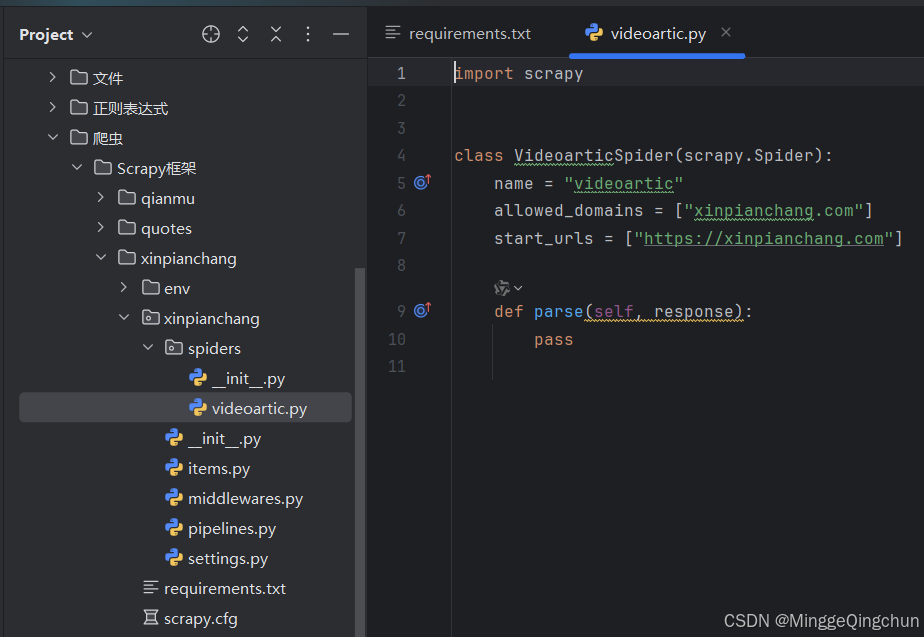
# 切换到项目目录下
cd D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架
# Scrapy创建项目
scrapy startproject xinpianchang
# 切换到创建的项目目录下
cd xinpianchang
# 生成spider文件;scrapy genspider [爬虫程序名称] [爬虫目标网站域名-起始url]
scrapy genspider videoartic xinpianchang.com
# 给该项目创建一个单独的虚拟环境
(.venv) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架\xinpianchang> virtualenv env
# 激活虚拟环境
(.venv) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架\xinpianchang> .\env\Scripts\activate
# 创建一个requirements.txt文件
(env) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架\xinpianchang> pip install -r requirements.txt
# tree树形查看文件目录
treeScrapy shell 常用命令
# 进入到Scrapy控制台,使用项目环境
scrapy shell
# 带一个URL参数,自动请求这个URL,并在请求成功后进入控制台
scrapy shell http://url.com
# 进入到控制台后,可使用函数和对象
fetch 请求URL或者Request对象,注:请求成功后自动将当前作用域内的Request和response对象重新赋值
view 浏览器打开response对象内的网页
shelp 打印帮助信息
spider 相应的Spider类实例
settings 保存所有配置信息的Settings对象
crawler 当前Crawler对象
Scrapy Scrapy模块
# 项目配置下载网页,然后使用浏览器打开网页
scrapy view url
# 项目配置下载网页,然后输出至控制台
scrapy fetch urlview命令本地下载一个网页,打开查看如下
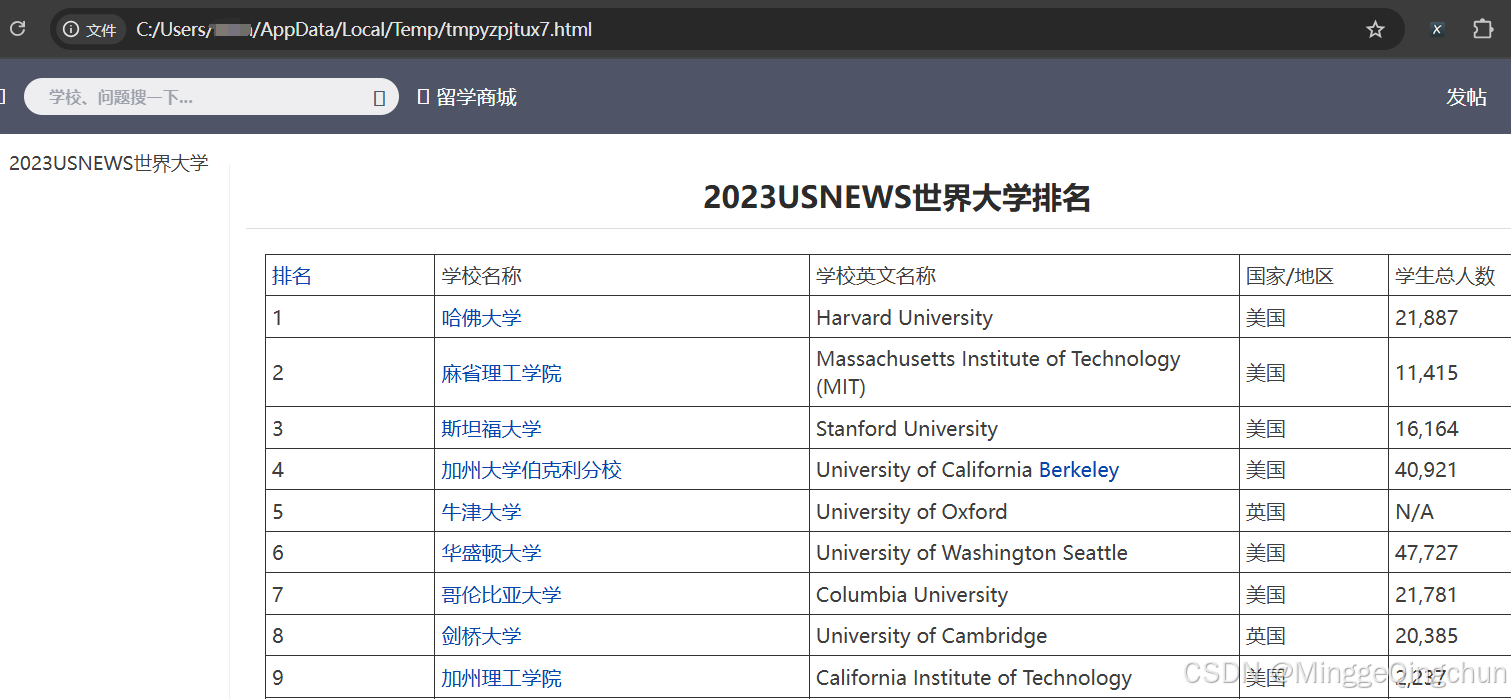
scrapy shell和ipython命令都可以使用,相对来说ipython更好用些
Scrapy Shell和IPython的主要区别在于它们的功能和用途
Scrapy Shell
Scrapy Shell是Scrapy框架的一个命令行工具,主要用于在爬虫开发过程中实时查看和调试网页内容。它可以在不启动爬虫的情况下,测试XPath或CSS表达式,验证提取数据的代码。Scrapy Shell提供了一个交互式终端,用户可以在其中测试和调试爬取代码,查看网页内容,并进行断言和调试。
IPython
IPython是一个增强的Python解释器,提供了许多高级功能,如自动缩进、语法高亮、代码补全等,使得Python编程更加便捷和高效。IPython还支持交互式并行计算、魔术命令等功能,适用于数据科学和数值计算等领域。
具体区别
- 用途:Scrapy Shell主要用于爬虫开发和调试,而IPython是一个通用的Python解释器增强工具,适用于各种Python编程任务。
- 功能:Scrapy Shell提供了特定的功能函数和内置对象,如
fetch、view等,用于获取网页响应和处理爬取数据。IPython则提供了更多的通用功能,如自动补全、魔术命令等,适用于更广泛的Python开发需求。 - 兼容性:当Scrapy Shell启动时,如果系统中安装了IPython,Scrapy Shell会优先使用IPython作为其交互式终端,提供更丰富的交互体验

以迁木网为例,usnews.py
import scrapy
'''
settings.py中有一个HTTPCACHE_ENABLED配置
# 启用HTTP请求缓存,下次请求同一URL时不再发送远程请求
HTTPCACHE_ENABLED = True
'''
class UsnewsSpider(scrapy.Spider):
name = "usnews"
# 允许爬虫的URL必须在此字段内;genspider时可以指定;如qianmu.com意味www.qianmu.com和http.qianmu.org下的链接都可以爬取
allowed_domains = ["www.qianmu.org"]
# 爬虫的入口地址,可以多个
start_urls = ["http://www.qianmu.org/2023USNEWS%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%A6%E6%8E%92%E5%90%8D"]
# 框架请求start_urls成功后,会调用parse方法
def parse(self, response):
# 提取链接,并释放
links = response.xpath('//div[@id="content"]//tr[position()>1]/td/a/@href').extract()
for link in links:
if not link.startswith('http://www.qianmu.org'):
link = 'http://www.qianmu.org/%s' % link
# 请求成功以后,异步调用callback函数
yield response.follow(link, self.parse_university)
def parse_university(self, response):
# 去除空格等特殊字符
response = response.replace(body=response.text.replace('\t','').replace('\r\n', ''))
data = {}
data['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()').extract_first()
# data['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()')[0]
table = response.xpath('//div[@id="wikiContent"]//div[@class="infobox"]/table')
if not table:
return None
table = table[0]
keys = table.xpath('.//td[1]/p/text()').extract()
cols = table.xpath('.//td[2]')
# 当我们确定解析的数据只有1个结果时,可以使用extract_first()函数
values = [' '.join(col.xpath('.//text()').extract()) for col in cols]
if len(keys) == len(values):
data.update(zip(keys, values))
# yield出去的数据会被Scrapy框架接收,进行下一步处理;如果没有任何处理,则会打印到控制台
yield data参考链接
Scrapy爬虫框架详解与实践-CSDN博客
爬虫/scrapy基础入门篇_scrapy创建爬虫命令-CSDN博客
爬虫之scrapy框架 - W的一天 - 博客园
高效数据抓取:Scrapy框架详解-腾讯云开发者社区-腾讯云
Scrapy的基础使用(1) - MrSponge - 博客园