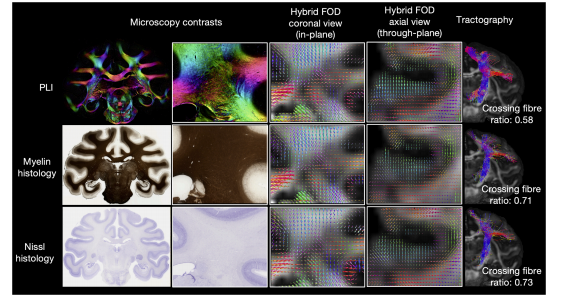
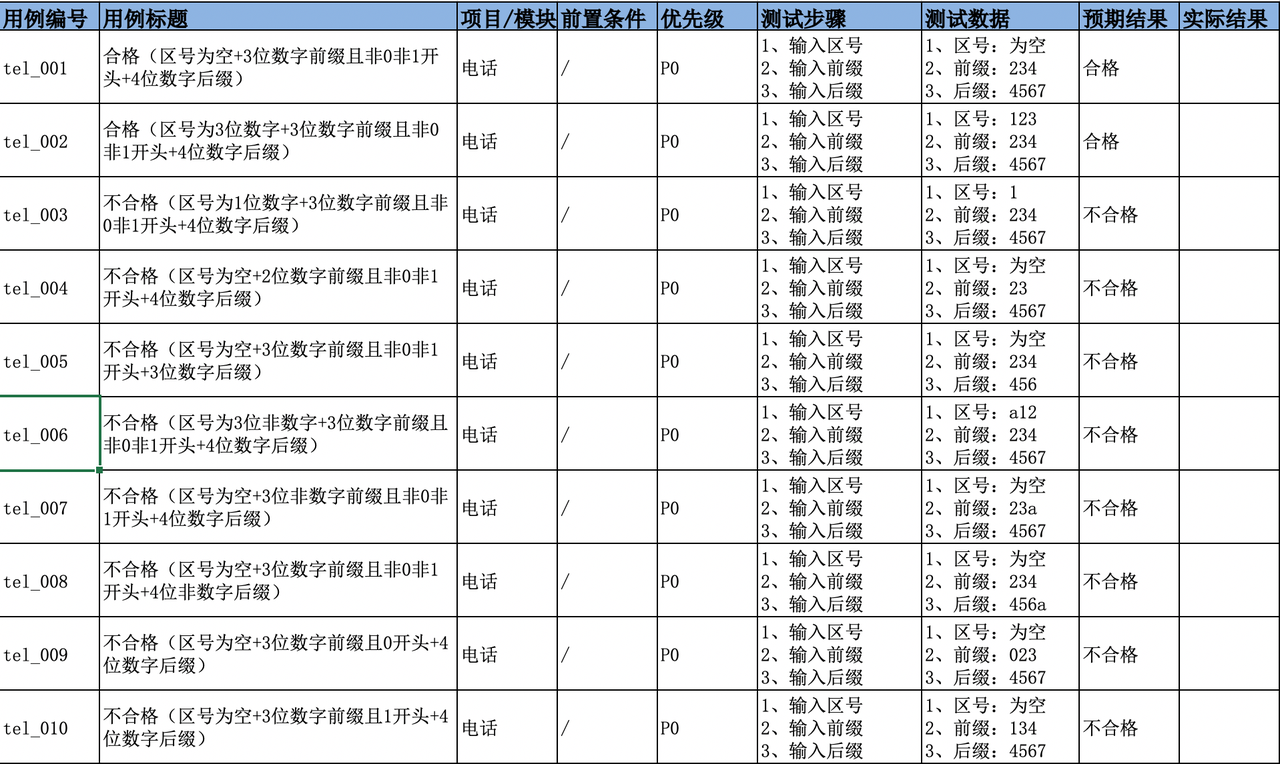
pivot_table 和 groupby 是 pandas 中两种常用的数据聚合方法,它们都能实现数据分组和汇总,但在使用方式和输出结构上有显著区别。
0. 基本介绍
groupby分组聚合
groupby 是 Pandas 库中的一个功能强大的方法,用于根据一个或多个列对数据进行分组,并对每个分组执行聚合操作。它通常与聚合函数(如 sum、mean、count 等)一起使用,以便对分组后的数据进行统计分析。
工作逻辑:“拆分-应用-合并”:它按照某些条件将数据分组,然后对每组应用函数,最后将结果合并。
基本用法
import pandas as pd
df = pd.DataFrame({
'城市': ['北京', '上海', '北京', '上海', '北京', '上海'],
'月份': ['1月', '1月', '2月', '2月', '3月', '3月'],
'销售额': [100, 200, 150, 250, 120, 230]
})
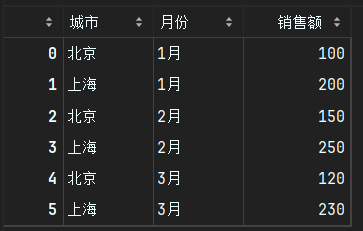
# 按城市分组计算平均销售额
avg_sales = df.groupby('城市')['销售额'].mean()
# 按城市和月份两级分组
grouped = df.groupby(['城市', '月份'])['销售额'].sum()
# 同时计算总和、平均值和最大值
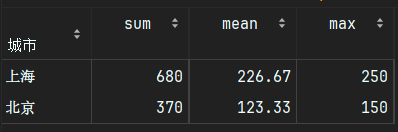
result = df.groupby('城市')['销售额'].agg(['sum', 'mean', 'max']).round(2)
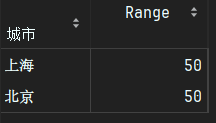
# 定义计算极差的函数
def range_func(x):
return x.max() - x.min()
result = df.groupby('城市')['销售额'].agg(range_func).to_frame("Range")
pivot_table数据透视表
pivot 英/ˈpɪvət/
n.支点;中心;枢轴;核心;中心点;最重要的人(或事物)
pivot_table创建电子表格风格的数据透视表,可以看作是多维的groupby操作,但提供了更直观的行列交叉分析能力。
基本用法
import pandas as pd
df = pd.DataFrame({
'城市': ['北京', '上海', '北京', '上海', '北京', '上海'],
'月份': ['1月', '1月', '2月', '2月', '3月', '3月'],
'销售额': [100, 200, 150, 250, 120, 230]
})
# 创建简单的透视表
pivot = pd.pivot_table(df,
values='销售额',
index='城市',
columns='月份',
aggfunc='sum')
多维度分析
# 假设数据有更多维度
df['产品线'] = ['A', 'B', 'A', 'B', 'A', 'B']
# 多维度透视
pivot = pd.pivot_table(df,
values='销售额',
index=['城市'],
columns=['月份', '产品线'],
aggfunc='sum',
fill_value=0)
多个聚合函数
# 同时使用多个聚合函数
pivot = pd.pivot_table(df,
values='销售额',
index='城市',
columns='月份',
aggfunc=['sum', 'mean', 'count'])
#添加汇总行/列
pivot = pd.pivot_table(df,
values='销售额',
index='城市',
columns='月份',
aggfunc='sum',
margins=True, # 添加汇总
margins_name='总计')
1. 输出结构的差异
| 特性 | groupby | pivot_table |
|---|---|---|
| 默认输出格式 | 返回 Series 或多层索引的 DataFrame | 直接返回二维表格形式的 DataFrame |
| 行列结构 | 结果可能包含多层索引(不易直观阅读) | 自动生成行列交叉的表格(类似Excel透视表) |
| 可视化友好度 | 需额外处理才能用于图表 | 直接支持热力图、柱状图等可视化 |
示例对比:
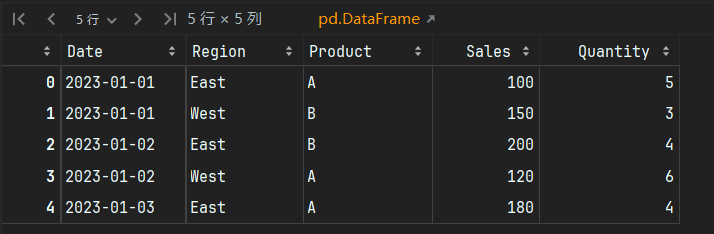
示例数据
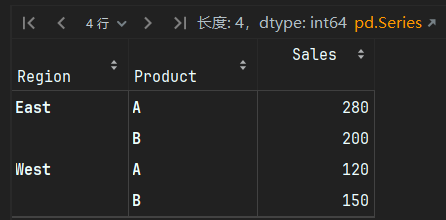
groupby
# groupby 输出(多层索引Series)
df.groupby(['Region', 'Product'])['Sales'].sum()
pivot_table
# pivot_table 输出(二维表格)
pd.pivot_table(df,
values='Sales',
index='Region',
columns='Product',
aggfunc='sum')
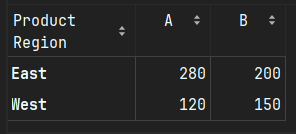
2. 功能侧重点不同
groupby | pivot_table |
|---|---|
| 更适合编程化的数据处理流程 | 更适合生成人类可读的汇总报表 |
支持更复杂的链式操作(如apply) | 专注于行列交叉的聚合展示 |
| 灵活性更高,可自定义分组逻辑 | 结构化更强,适合标准化分析场景 |
3. 多维分析能力
-
groupby虽然可以通过多列分组实现多维分析,但结果需要手动处理才能清晰展示:df.groupby(['Region', 'Product', 'Date'])['Sales'].sum().unstack("Product")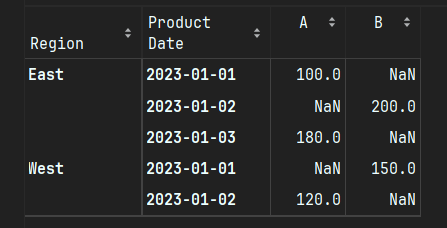
-
pivot_table原生支持多维交叉分析,通过index和columns参数直观控制:pd.pivot_table(df, values='Sales', index=['Region', 'Date'], columns='Product', aggfunc='sum')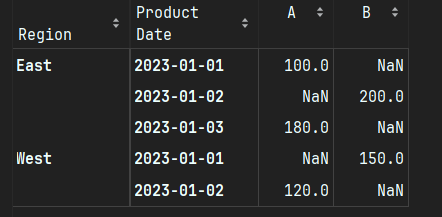
4. 实际应用场景选择
优先使用 groupby 当:
- 需要灵活的分组后操作(如过滤、转换)
- 进行复杂的分组计算(如滚动统计、自定义聚合)
- 数据需要进一步管道式处理(
method chaining)
优先使用 pivot_table 当:
- 快速生成业务报表或可视化数据
- 需要直观对比行列维度关系
- 处理类似Excel透视表的需求
5. 性能对比
- 简单聚合场景下性能相近
- 复杂多维分析时,
pivot_table对内存更友好(自动处理行列展开) groupby在链式操作中可能更高效(避免中间结果生成)
两者本质都是分组聚合,但 pivot_table 是 groupby 的一种结构化输出形式。理解它们的差异后,可以根据具体需求灵活选择或组合使用。