高级可视化图表分析实践——以《大侠立志传》武器系统为例
- 引言
- 武器类型分布
- 矩形树图
- 结论
- 不同品质/类别武器的攻击力分布情况
- 蜂群图
- 分析结论
- 武器来源
- 桑基图
- 分析结论
- 武器附加属性
- 词云图
- 分析结论
- 不同品级武器装备熟练度要求/特质要求
- 离散热力图
- 结论
- 品质与熟练度的正相关性
- 品质与熟练度的非线性关系
- 装备品质与需求特质的正相关性
- 不同装备类型对需求特质的类型要求
- 使用python制作上述图表
- 矩形树图
- 蜂群图
- 桑基图
- 词云图
- 离散热点图
引言
引言:当武侠世界遇见数据可视化
在开放世界武侠游戏《大侠立志传》中,武器系统是构建角色成长体系的重要模块。本文将以游戏内192件武器数据为样本,通过5种高级可视化图表(矩形树图、蜂群图、桑基图、词云图、离散热力图),深入解析武器系统的设计逻辑,同时熟悉高级可视化图表的制作(python)和作用。
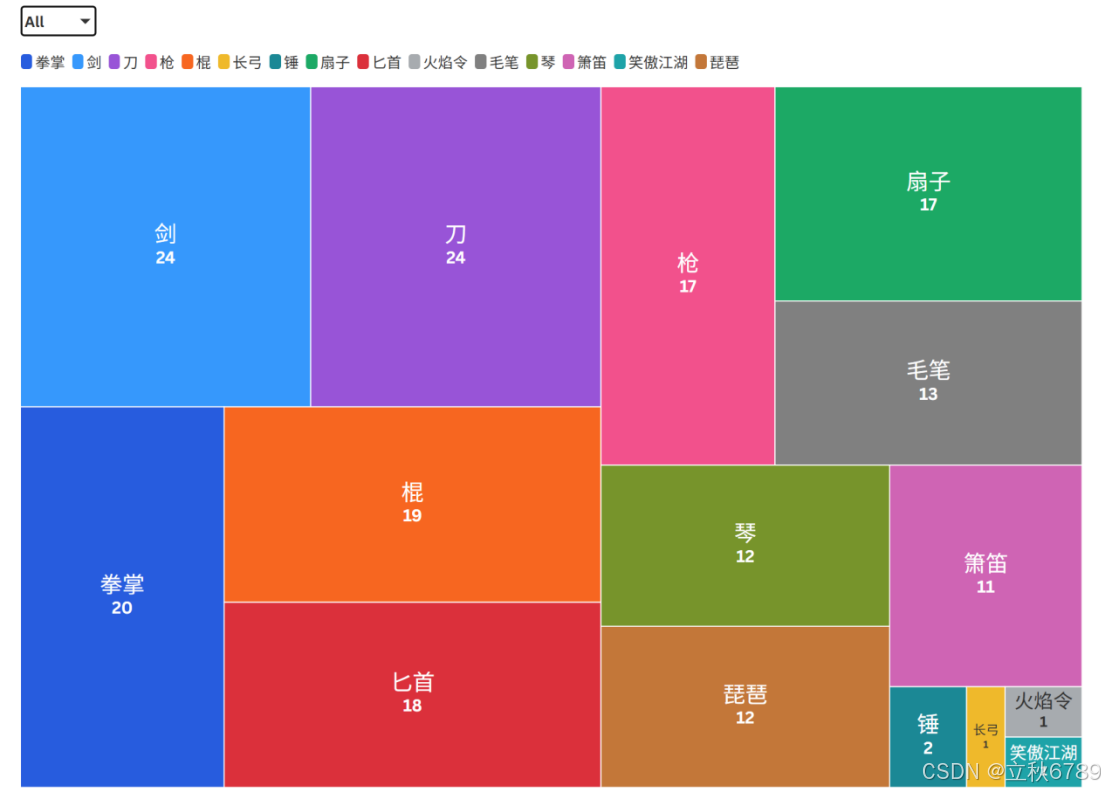
武器类型分布
矩形树图
所有品级武器数量分布
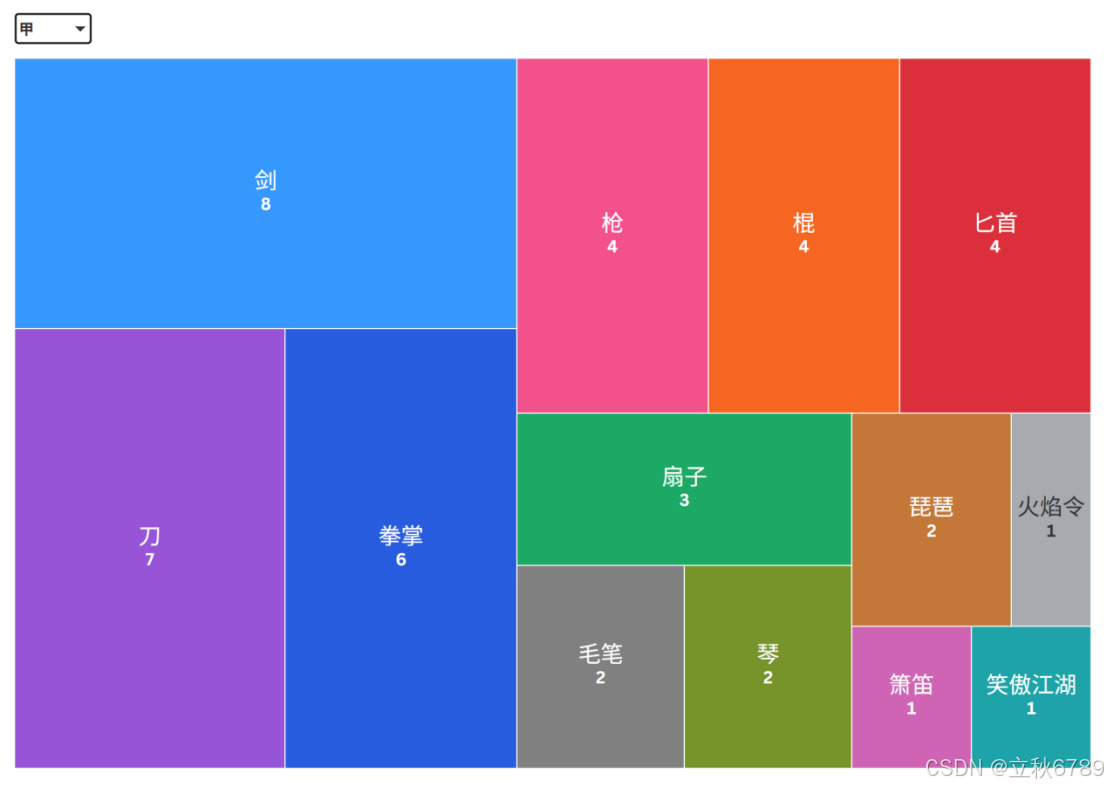
甲级武器数量分布
乙级武器数量分布

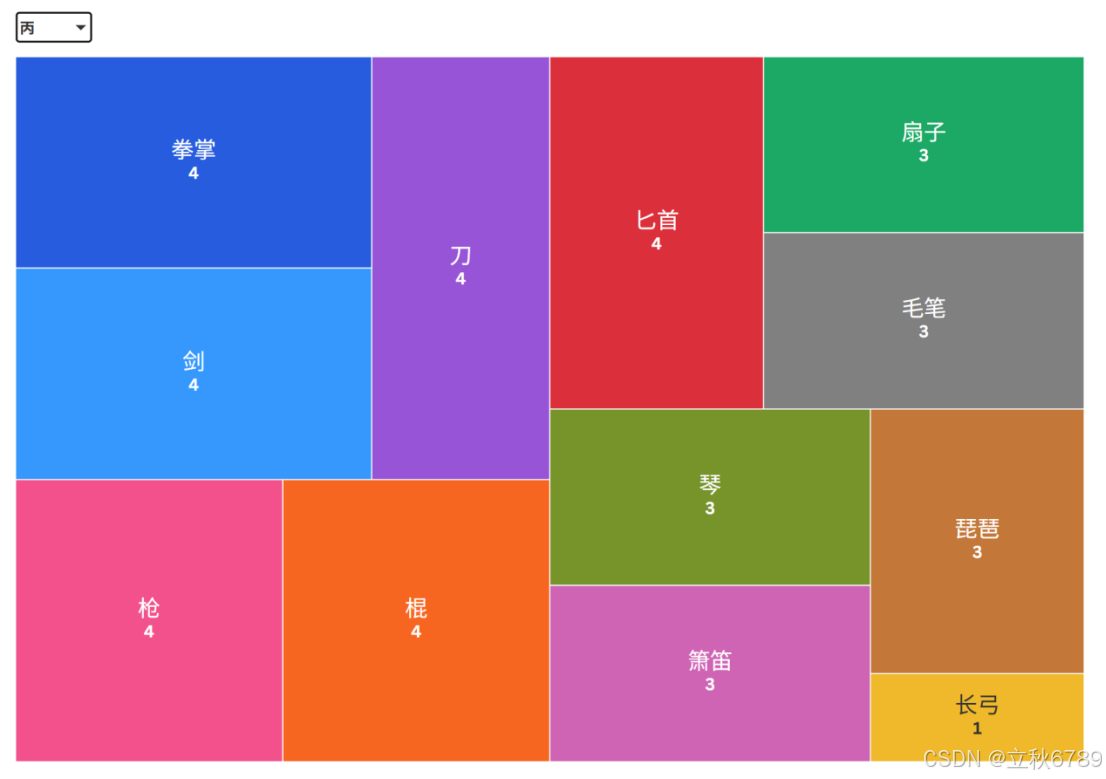
丙级武器数量分布
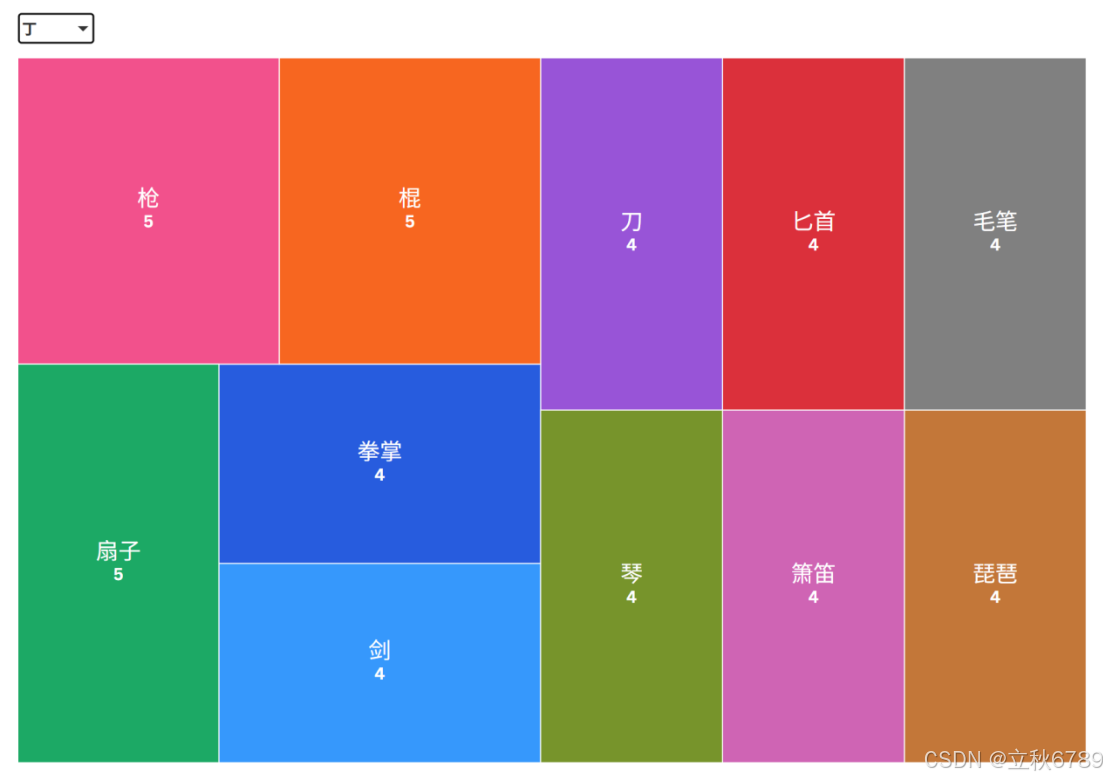
丁级武器数量分布
结论
- 剑和刀是最常见的武器,剑和刀各有24个,是图中数量最多的两种武器类型。
- 锤、长弓、火焰令和笑傲江湖的数量非常少。锤有2个,长弓有1个,火焰令有1个,笑傲江湖有1个。
- 整体分布不均匀,少数几种武器占据了较大的比例,而其他类型的武器则相对较少。
不同品质/类别武器的攻击力分布情况
蜂群图

分析结论
- 品质越高,攻击力普遍越高。
- 丁级武器攻击力整体偏低。
- 武器类型对攻击力分布的影响不大,相同品质下攻击力整体相同。
武器来源
桑基图
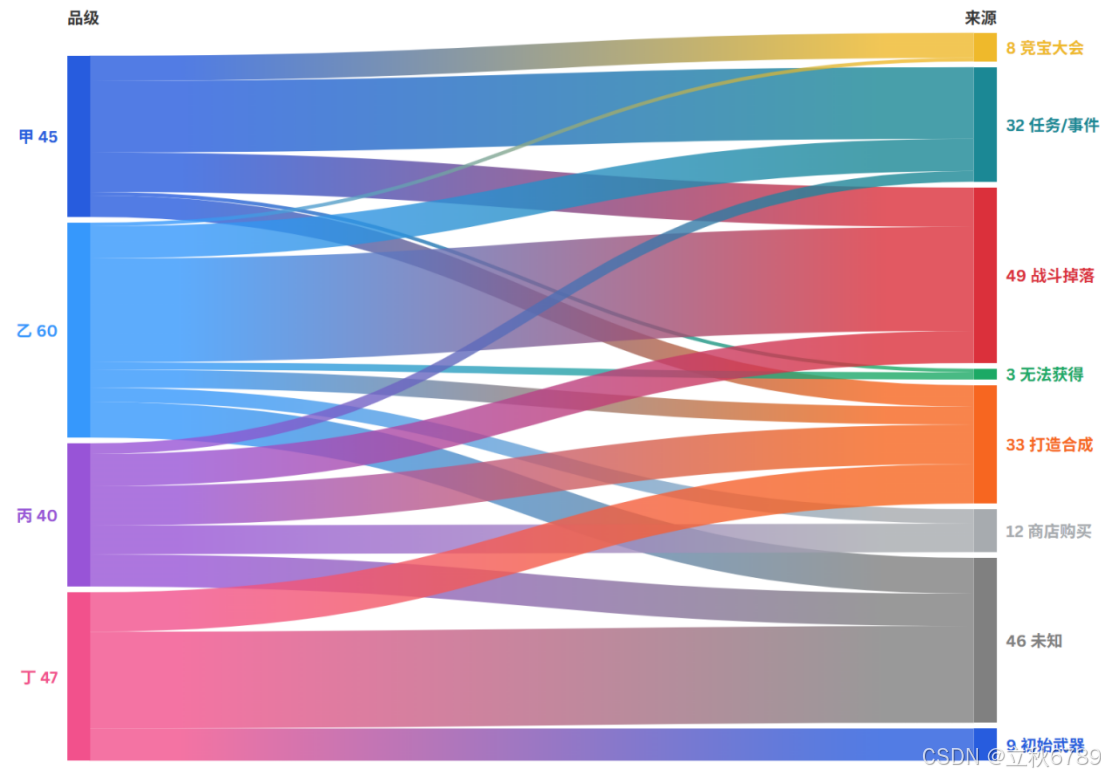
分析结论
- 品级越高(甲、乙),获取方式越依赖 任务/事件 或 战斗掉落,符合高风险高回报机制。
- 品级越低(丙、丁),获取方式越依赖 合成 或 商店,可能为普通或基础装备。
武器附加属性
词云图

分析结论
多个攻击类词汇集中在中心且字号较大,说明攻击强化是武器属性的主要设计方向。
不同品级武器装备熟练度要求/特质要求
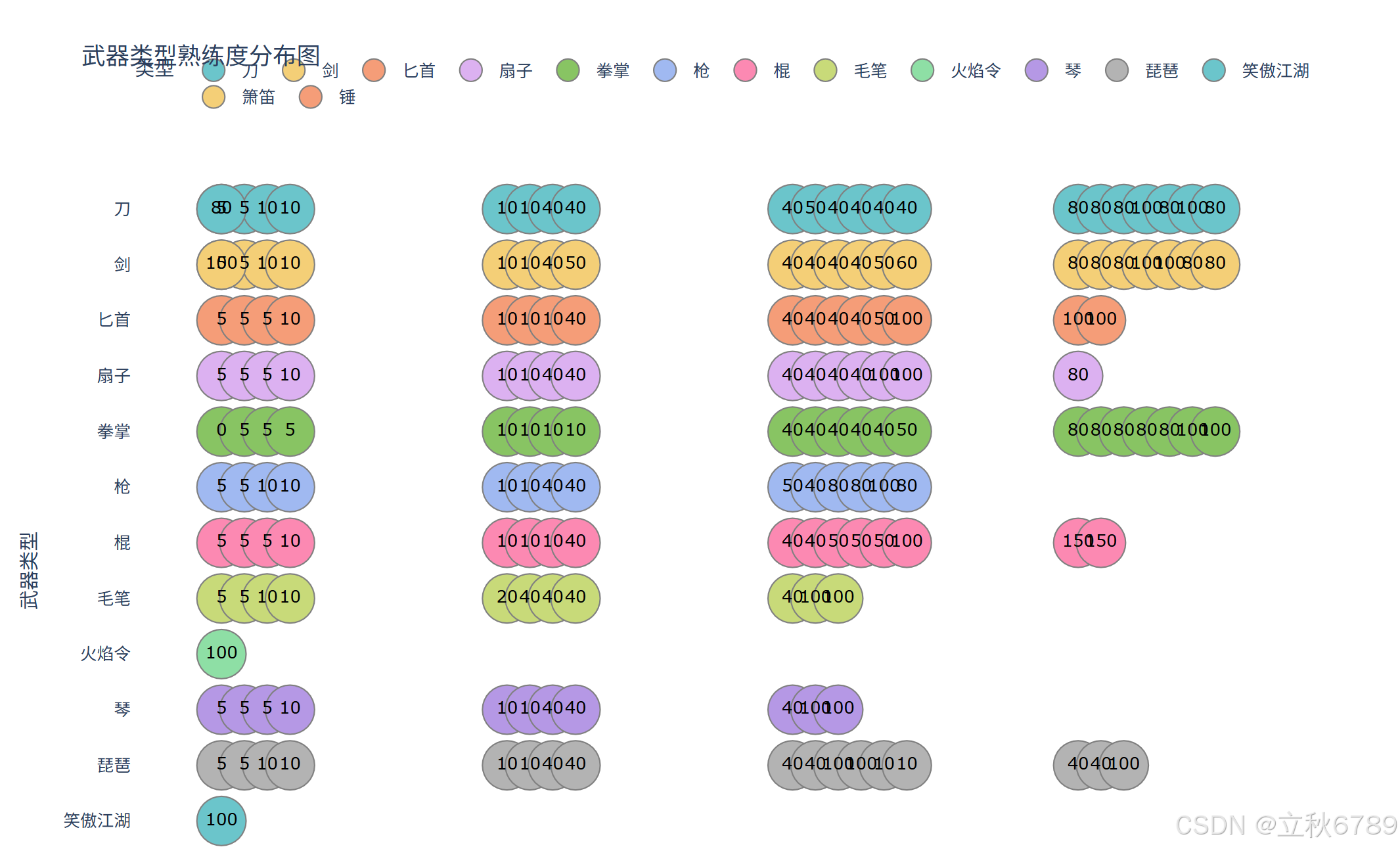
离散热力图


结论
品质与熟练度的正相关性
- 趋势:品质等级(丁→丙→乙→甲)与所需熟练度呈显著正相关。
- 丁级:熟练度普遍为 0-5。
- 丙级:熟练度提升至 5-10。
- 乙级:熟练度显著提高至 40-50。
- 甲级:熟练度达到 80-150。
品质与熟练度的非线性关系
- 跃升式增长:从丁到丙、乙到甲的熟练度增幅更大(如丁→丙:+5;乙→甲:+30-110),说明高品质装备对熟练度要求陡增。
装备品质与需求特质的正相关性
- 随着装备品质从 丁→甲 升级,需求特质值显著增加
- 丁级、丙级装备:普遍无需求特质。
- 乙级装备:开始有需求特质值,大多数装备需求特质值要求3,少数要求5。
- 甲级装备:大多数装备需求特质值达到10,少数装备要求8或15。
不同装备类型对需求特质的类型要求
1.物理近战武器(拳掌/剑/刀/枪/棍):
核心特质:臂力、体质、敏捷。
具体分布:
- 拳掌类:以臂力为主(3/6),其次是体质(2/6)和敏捷(1/6)。
- 剑类:臂力(4/8)和体质(3/8)并重,敏捷次之(2/8)。
- 刀类:体质需求最高(4/7),臂力(2/7)和敏捷(2/7)均衡。
- 枪类:臂力(2/4)为主,体质(1/4)和敏捷(1/4)辅助。
- 棍类:完全依赖臂力(4/4),无其他特质需求。
规律:
物理武器普遍需要臂力(力量型输出),部分依赖体质(生存能力)或敏捷(灵活性)。棍类因高力量需求成为臂力特化武器。
2.轻型武器(匕首/扇子/短兵):
核心特质:敏捷主导。
具体分布:
- 匕首类:敏捷占比最高(3/5),臂力(1/5)和体质(1/5)次要。
- 扇子类:特质分布较均衡(臂力、体质、敏捷各1/3)。
- 火焰令/飞雪寒霜刃:全部需求敏捷。
规律:
轻型武器更依赖敏捷(快速攻击或闪避),部分兼顾臂力或体质。
其他武器(毛笔/琴/箫笛/琵琶)
-
核心特质:悟性、福缘。
-
具体分布: 毛笔:悟性和福缘各占一半。 琴/琵琶:悟性(3/5)为主,敏捷(2/5)次之。
规律:
毛笔/琴/箫笛/琵琶需求的特质更依赖与悟性与福源。
使用python制作上述图表
矩形树图
import squarify
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from pylab import *
mpl.rcParams['font.sans-serif']=['SimHei']
# 示例数据(类别名称和对应的值)
data = [10, 20, 30, 40]
labels = ['A', 'B', 'C', 'D']
# 生成颜色(根据值的大小映射到viridis色系)
colors = cm.viridis([x / max(data) for x in data])
# 创建标签(显示名称和数值)
labels_with_values = [f"{label}\n{val}" for label, val in zip(labels, data)]
# 绘制矩形树图
plt.figure(figsize=(10, 6))
squarify.plot(
sizes=data,
label=labels_with_values,
color=colors,
alpha=0.6, # 透明度
pad=True # 矩形间留空隙
)
plt.axis('off') # 关闭坐标轴
plt.title('矩形树图示例')
plt.show()

蜂群图
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体(Windows用SimHei,macOS用STHeiti)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成示例数据
np.random.seed(42)
data = {
'类别': np.repeat(['A组', 'B组', 'C组'], 50),
'数值': np.concatenate([
np.random.normal(90, 10, 50),
np.random.normal(60, 15, 50),
np.random.normal(75, 5, 50)
])
}
# 创建画布
plt.figure(figsize=(10, 6))
# 绘制蜂群图
sns.swarmplot(
x='类别',
y='数值',
data=data,
size=6, # 点的大小
palette='Set2', # 颜色方案
edgecolor='black', # 点边缘颜色
linewidth=0.5 # 边缘线宽
)
# 添加标题和标签
plt.title('不同组别的数值分布蜂群图', fontsize=14)
plt.xlabel('实验组别', fontsize=12)
plt.ylabel('测量数值', fontsize=12)
# 显示图形
plt.show()
桑基图
import plotly.graph_objects as go
# 定义节点(资金流动的所有端点)
labels = [
"销售收入", # 0
"投资收益", # 1
"政府补贴", # 2
"研发支出", # 3
"人力成本", # 4
"税费", # 5
"股东分红", # 6
"运营储备" # 7
]
# 定义资金流动关系 (source -> target)
source = [0, 0, 1, 1, 2, 3, 4, 5, 7]
target = [3, 4, 4, 7, 7, 5, 5, 6, 6]
value = [120, 80, 50, 30, 20, 90, 70, 60, 40] # 单位:百万元
# 创建桑基图
fig = go.Figure(go.Sankey(
node={
"label": labels,
"pad": 20,
"thickness": 15,
"color": "#1F77B4", # 统一节点颜色(蓝色系)
"line": {"color": "black", "width": 0.5} # 节点边框
},
link={
"source": source,
"target": target,
"value": value,
"color": "rgba(255, 165, 0, 0.4)", # 橙色半透明流线
"hoverinfo": "all" # 悬停显示数值和端点
}
))
# 设置布局
fig.update_layout(
title={
"text": "企业年度资金流动分析(单位:百万元)",
"x": 0.5,
"font": {"size": 18}
},
font_family="Arial",
plot_bgcolor="white",
height=600
)
# 显示图表
fig.show()
# 可选:保存为HTML文件
# fig.write_html("corporate_cash_flow.html")
词云图
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 示例文本
text = """
Python is an interpreted, high-level, general-purpose programming language.
Created by Guido van Rossum and first released in 1991, Python's design philosophy emphasizes code readability with its notable use of significant whitespace.
"""
# 生成词云对象
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
max_words=100
).generate(text)
# 显示词云
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
# 保存图片
wordcloud.to_file("wordcloud_english.png")

离散热点图
import pandas as pd
import plotly.express as px
import numpy as np
# 1. 创建数据框架(基于你提供的完整数据样例)
data = {
"类型": ["拳掌"]*21 + ["剑"]*22 + ["刀"]*22 + ["枪"]*14 + ["棍"]*16 + ["锤"]*2 + ["扇子"]*15 +
["匕首"]*16 + ["火焰令"]*1 + ["毛笔"]*11 + ["琴"]*11 + ["箫笛"]*11 + ["笑傲江湖"]*1 + ["琵琶"]*17,
"品质": ["丁","丁","丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","乙","乙","甲","甲","甲","甲","甲","甲","甲"] +
["丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","乙","乙","乙","甲","甲","甲","甲","甲","甲","甲","甲","甲"] +
["丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","乙","乙","乙","乙","甲","甲","甲","甲","甲","甲","甲","甲"] +
["丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","甲","甲","甲","甲"] +
["丁","丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","乙","乙","甲","甲","甲"] +
["乙","乙"] +
["丁","丁","丁","丙","丙","丙","乙","乙","乙","乙","乙","乙","甲","甲","甲"] +
["丁","丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","乙","乙","甲","甲","甲"] +
["甲"] +
["丁","丁","丙","丙","丙","乙","乙","乙","乙","甲","甲"] +
["丁","丁","丁","丙","丙","丙","乙","乙","乙","甲","甲"] +
["丁","丁","丁","丙","丙","丙","乙","乙","乙","甲","甲"] +
["甲"] +
["丁","丁","丙","丙","丙","丙","乙","乙","乙","乙","甲","甲","丙","丙","乙","乙","甲"],
"熟练度": [0,5,5,5,10,10,10,10,40,40,40,40,40,50,80,80,80,80,80,100,100] +
[5,5,10,10,10,10,40,50,40,40,40,40,50,60,80,80,80,100,100,80,80,100] +
[5,5,10,10,10,10,40,40,40,50,40,40,40,40,80,80,80,100,80,100,80,80] +
[5,5,10,10,10,10,40,40,50,40,80,80,100,80] +
[5,5,5,10,10,10,10,40,40,40,50,50,50,100,150,150] +
[40,40] +
[5,5,5,10,10,10,40,40,40,40,40,40,100,100,80] +
[5,5,5,10,10,10,10,40,40,40,40,40,50,100,100,100] +
[100] +
[5,5,10,10,20,40,40,40,40,100,100] +
[5,5,5,10,10,10,40,40,40,100,100] +
[5,5,5,10,10,10,40,40,40,100,100] +
[100] +
[5,5,10,10,10,10,40,40,40,40,100,100,10,10,40,40,100]
}
df = pd.DataFrame(data)
# 2. 创建离散热力图
fig = px.scatter(
df,
x="品质",
y="类型",
color="类型",
text="熟练度",
category_orders={ # 强制指定分类顺序
"品质": ["丁", "丙", "乙", "甲"],
"类型": ["刀", "剑", "匕首", "扇子", "拳掌", "枪", "棍",
"毛笔", "火焰令", "琴", "琵琶", "笑傲江湖", "箫笛", "锤"]
},
color_discrete_sequence=px.colors.qualitative.Pastel,
title="武器类型熟练度分布图"
)
# 3. 自定义样式
fig.update_traces(
marker=dict(size=35, line=dict(width=1, color="Gray")),
textfont=dict(color="black", size=12),
textposition="middle center"
)
fig.update_layout(
height=800,
width=1000,
xaxis=dict(title="武器品质", showgrid=False),
yaxis=dict(title="武器类型", categoryorder="array"),
plot_bgcolor="white",
legend=dict(orientation="h", yanchor="bottom", y=1.02),
uniformtext=dict(minsize=10, mode="show")
)
# 4. 处理重叠点(添加水平抖动)
# 为每个品质等级添加微小的水平位置偏移
df["x_jitter"] = df.groupby(["类型", "品质"]).cumcount().apply(
lambda x: x * 0.08 - 0.12 # 在X轴方向添加±0.12的偏移
)
fig.update_traces(
x=pd.Categorical(df["品质"]).codes + 1 + df["x_jitter"] # 将分类转换为数值坐标
)
# 保持X轴标签正确显示
fig.update_xaxes(
tickvals=[0, 1, 2, 3],
ticktext=["丁", "丙", "乙", "甲"]
)
# 显示图表
fig.show()