继续分享最新的go面经。
今天分享的是组织内部的朋友在字节的go运维工程师岗位的云原生方向的面经,涉及Prometheus、Kubernetes、CI/CD、网络代理、MySQL主从、Redis哨兵、系统调优及基础命令行工具等知识点,问题我都整理在下面了

面经详解
Prometheus 的信息采集原理?
回答思路:
- 数据模型:Prometheus 采用时间序列数据模型,每个数据点由以下部分组成:
- 度量名称(Metric Name):标识数据的类型(如
http_requests_total)。 - 标签(Labels):键值对形式的元数据,用于唯一标识数据的来源和维度(如
job="api-server", instance="192.168.1.100:9090")。 - 时间戳(Timestamp):记录数据采集的时间。
- 数值(Value):具体指标值(如 CPU 使用率 75%)。
- 度量名称(Metric Name):标识数据的类型(如
- 数据采集:
- 拉取模式(Pull Model):Prometheus 定期主动从目标(Targets)拉取指标数据,默认周期为 1 分钟。
- 推送模式(Push Model):通过中间件(如 Pushgateway)将数据推送到 Prometheus,适用于短生命周期任务(如批处理作业)。
- Service Discovery:支持自动发现目标节点(如 Kubernetes 服务、Consul 注册中心),减少手动配置。
- 存储与查询:
- 数据存储为时间序列,按度量名称和标签分组,支持高效查询。
- PromQL:提供丰富的查询语言,支持聚合运算(如
avg(),sum())、范围查询([5m])、条件判断(如> 90)等。
- 优势与局限性:
- 优势:高可用、分布式、灵活的标签系统。
- 局限性:拉取模式可能因网络问题漏数据,存储成本较高。
Prometheus 采集K8S是哪个接口?
回答思路:
- Kubernetes API Server:
- Prometheus 通过 Kubernetes API 监控集群资源状态(如 Pod、Deployment、Node 等),需配置
kubernetes_sd_config进行服务发现。 - 示例配置:
- Prometheus 通过 Kubernetes API 监控集群资源状态(如 Pod、Deployment、Node 等),需配置
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default
source_labels: [__meta_kubernetes_namespace]
- Metrics Server:
- 提供 Pod、Node 的资源使用指标(如 CPU/内存使用率),需通过
kube-state-metrics或cAdvisor采集。 - 示例:
- 提供 Pod、Node 的资源使用指标(如 CPU/内存使用率),需通过
curl http://localhost:8080/api/v1/nodes/{node-name}/metrics
- 自定义接口:
- 应用需暴露
/metrics端点,格式符合 Prometheus 文本格式(如通过prometheus-client-go库实现)。
- 应用需暴露
- 注意事项:
- 需配置 RBAC 权限,确保 Prometheus 有权限访问 K8S API。
- 使用
kube-prometheus-stackHelm Chart 可一键部署完整监控链。
Prometheus 的告警是怎么配置的?
回答思路:
- 告警规则(Alert Rules):
- 在
prometheus.yml或独立的.rules文件中定义规则,例如:
- 在
groups:
- name: example
rules:
- alert: HighCPUUsage
expr: instance:node_cpu_usage:rate1m > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usage is high"
expr:PromQL 表达式,定义触发条件。for:告警持续时间(避免短暂波动触发)。labels和annotations:补充告警元数据和描述。- Alertmanager 配置:
- 路由(Routes):根据标签(如
severity)将告警分发到不同接收者。
- 路由(Routes):根据标签(如
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
receiver: 'team-alerts'
routes:
- match_re:
severity: critical
receiver: 'oncall-team'
- 抑制(Inhibit):高优先级告警(如
InstanceDown)可抑制低优先级告警(如HighCPUUsage)。 - 接收器(Receivers):支持多种通知方式(如 Slack、PagerDuty、Email)。
- 实践建议:
- 避免“告警疲劳”:合理设置阈值和
for参数。 - 验证告警:通过
fire-and-forget模式测试配置。
- 避免“告警疲劳”:合理设置阈值和
Prometheus 的告警是基于哪个组件配置的?
回答思路:
- 核心组件:Alertmanager
- 功能:
- 接收 Prometheus 发送的告警事件。
- 根据配置路由规则将告警分发给接收者(如团队 Slack 频道)。
- 聚合相似告警,减少重复通知(如
group_by)。 - 抑制冗余告警(如主节点宕机时抑制其下所有服务的告警)。
- 配置文件示例:
- 功能:
global:
resolve_timeout: 5m
route:
receiver: 'team-email'
group_wait: 30s
receivers:
- name: 'team-email'
email_configs:
- to: 'team@example.com'
- Prometheus 集成:
- 在
prometheus.yml中指定 Alertmanager 地址:
- 在
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
- 扩展能力:
- 支持与 Grafana、PagerDuty 等工具集成,实现更复杂的告警管理。
CI 流水线发现问题是怎么排查解决的?
回答思路:
- 分层排查法:
- 环境层:
- 检查流水线运行的环境(如 Docker 镜像、依赖版本、网络配置)。
- 使用
docker inspect或kubectl describe pod查看容器状态。
- 日志层:
- 定位到失败步骤的日志,关注错误代码、堆栈信息。
- 使用日志聚合工具(如 ELK、Splunk)快速筛选关键信息。
- 代码层:
- 复现问题:本地复现流水线环境,逐步调试代码。
- 单元测试:针对可疑代码添加测试用例。
- 配置层:
- 检查流水线 YAML 文件中的参数、路径、工具版本。
- 确认敏感信息(如 API 密钥)是否正确注入。
- 环境层:
- 工具辅助:
- GitLab CI/CD:通过
echo命令输出中间变量,或使用debug模式。 - Jenkins:使用 Blue Ocean 插件可视化流水线状态。
- GitLab CI/CD:通过
- 预防措施:
- 增加流水线前置检查(如依赖库版本校验)。
- 实施变更管理流程,减少环境漂移。
访问服务出现 502 是什么问题?
回答思路:
- 常见原因及排查步骤:
- 反向代理问题:
- Nginx 配置错误:检查
proxy_pass是否指向正确的后端服务地址。 - 超时设置:调整
proxy_read_timeout或proxy_connect_timeout。
- Nginx 配置错误:检查
- 后端服务问题:
- 服务未启动:检查进程状态(
ps aux | grep service_name)。 - 负载过高:监控 CPU/内存使用率,优化代码或扩容。
- 服务未启动:检查进程状态(
- 网络问题:
- 防火墙/安全组:确认后端服务端口是否开放。
- DNS 解析:使用
dig或nslookup验证域名解析。
- 健康检查失败:
- 如果使用负载均衡(如 Kubernetes Ingress),检查健康检查配置是否合理。
- 反向代理问题:
- 示例排查流程:
- 访问日志:检查 Nginx 的
error.log中的502错误详情。 - 模拟请求:直接访问后端服务(如
curl http://backend:8080)。 - 查看后端日志:检查服务端日志(如
tail -f /var/log/app.log)。
- 访问日志:检查 Nginx 的
- 解决方案:
- 重启服务或代理。
- 调整超时参数或负载均衡策略。
- 优化后端服务性能(如增加缓存、分页查询)。
K8S service 的服务类型有几种?
回答思路:
- ClusterIP:
- 默认类型,仅在集群内部通过虚拟 IP(VIP)访问。
- 适用场景:后端服务间通信(如数据库、API 服务)。
- NodePort:
- 在每个 Node 的 IP 上开放一个端口(默认
30000-32767),外部可通过NodeIP:NodePort访问。 - 适用场景:开发/测试环境暴露服务,或需要快速访问。
- 在每个 Node 的 IP 上开放一个端口(默认
- LoadBalancer:
- 在云平台(如 AWS、GCP)创建云负载均衡器,流量自动转发到 Service。
- 适用场景:生产环境的高可用服务暴露。
- ExternalName:
- 通过 CNAME 将 Service 映射到外部域名(如
api.example.com),常用于跨集群访问。
- 通过 CNAME 将 Service 映射到外部域名(如
- 高级场景:
- 头信息修改:通过
externalTrafficPolicy: Local控制流量来源。 - Ingress 控制器:结合 Ingress 资源实现基于路径或域名的路由(如 Nginx Ingress)。
- 头信息修改:通过
- 选择建议:
- 生产环境优先使用 LoadBalancer 或 Ingress。
- 避免在生产环境使用 NodePort,因其端口冲突风险较高。
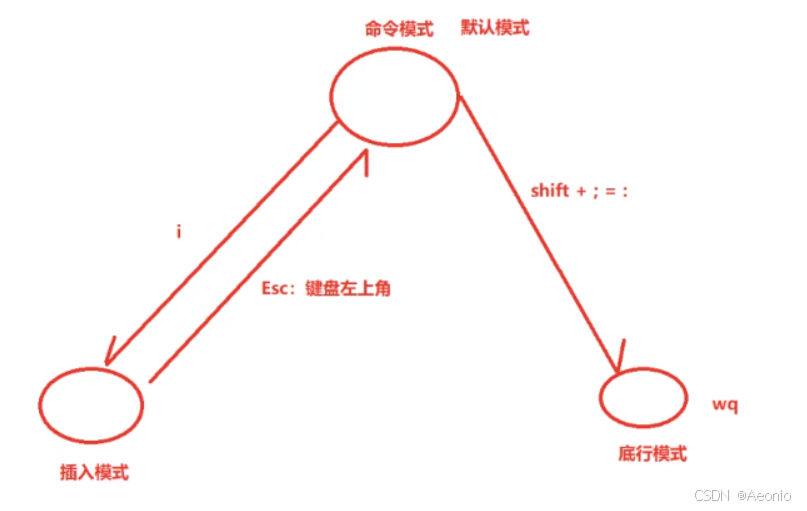
给文件的每一个前面增加head?
回答思路:
- Vim 编辑器:
- 打开文件:
vim filename。 - 进入命令模式,输入
:%s/^/head /g(替换每一行开头)。 - 或使用可视模式:
ggVG:Ihead(全局插入)。
- 打开文件:
- sed 命令:
sed -i 's/^/head /' filename
# 或批量处理多行:
sed -i '1i\head' filename # 在文件开头插入(非每行)
- awk 命令:
awk '{print "head " $0}' filename > newfile
- 注意事项:
-i参数会直接修改原文件,建议先备份。- 若需保留原文件,可重定向输出:
awk ... > newfile。
awk 提取数值为8的第二列的数量,分隔符为 | ,怎么提取?
回答思路:
- 基础命令:
awk -F '|' '$2 == 8 {count++} END {print count}' filename
-F '|':设置分隔符为|。$2 == 8:筛选第二列值为 8 的行。count++:计数器自增。- 扩展场景:
- 统计范围:
$2 > 5 && $2 < 10统计第二列在 5~10 之间的行数。 - 多条件匹配:
- 统计范围:
awk -F '|' '$2 == 8 && $3 ~ /error/ {count++} END {print count}'
- 输出详细信息:
awk -F '|' '$2 == 8 {print $0}' filename > result.txt
- 性能优化:
- 处理大文件时,可结合
time命令或parallel加速。
- 处理大文件时,可结合
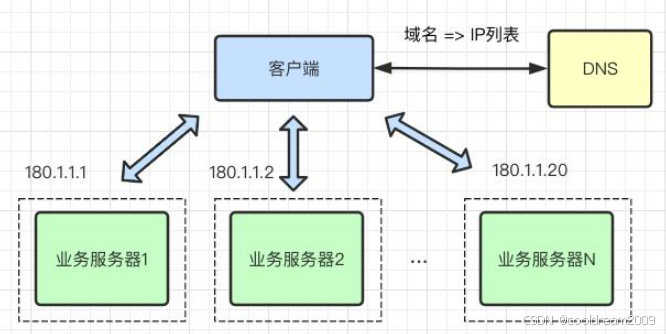
nginx 的负载均衡怎么配置?
回答思路:
- 基础配置步骤:
- 定义 upstream 组:
upstream backend {
server backend1.example.com weight=3;
server backend2.example.com; # 权重默认1
server backup.example.com backup; # 备用节点
}
- 配置 server 和 location:
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend;
proxy_next_upstream error timeout invalid_header http_500; # 失败重试策略
}
}
- 负载均衡算法:
round_robin(默认):轮询。ip_hash:根据客户端 IP 分配,保持会话。least_conn:最少连接数。
- 健康检查:
- 主动健康检查(需 Nginx Plus):
upstream backend {
zone backend 64k;
server backend1.example.com;
health_check;
}
- 被动健康检查:通过
proxy_next_upstream规则剔除故障节点。 - 高级配置:
- 超时设置:
proxy_connect_timeout 5s;。 - 会话保持:结合
ip_hash或 Cookie。
- 超时设置:
- 验证与测试:
- 使用
curl -I http://example.com检查响应头的X-Forwarded-For。 - 模拟节点故障,观察流量切换是否正常。
- 使用
MySQL 主从架构和 redis哨兵 前端是用什么连接的服务,读取数据库中的数据,对数据进行一个应用的?
回答思路:
- MySQL 主从架构:
- 连接方式:
- 前端应用通过主节点写入数据,通过从节点读取(读写分离)。
- 使用连接池(如 HikariCP)管理数据库连接。
- 注意事项:
- 从库延迟可能导致读写不一致,需通过
read_only参数控制从库写入。 - 使用中间件(如 MyCat)实现自动路由。
- 从库延迟可能导致读写不一致,需通过
- 连接方式:
- Redis 哨兵模式:
- 连接方式:
- 客户端连接哨兵集群(如通过 JedisSentinelPool),哨兵自动发现主节点。
- 高可用机制:
- 哨兵监控主节点,主节点故障时自动选举新主节点。
- 客户端通过哨兵获取最新主节点地址。
- 连接方式:
- 应用层设计:
- MySQL:业务逻辑中区分读写操作(如
@Transactional注解控制)。 - Redis:使用连接池自动处理主从切换,避免手动干预。
- MySQL:业务逻辑中区分读写操作(如
linux 系统调优是怎么进行调优的,对应简历中的性能是怎么调优的?
回答思路:
- 性能监控工具:
- 资源监控:
top/htop:实时查看 CPU、内存、进程状态。vmstat:监控内存、swap、IO 等。iostat:分析磁盘 IO 性能。
- 网络监控:
netstat,tcpdump,iftop。
- 资源监控:
- 调优方向:
- CPU:
- 优化线程调度(如
nice调整优先级)。 - 调整内核参数(如
vm.swappiness控制 swap 使用)。
- 优化线程调度(如
- 内存:
- 增加
vm.max_map_count(如 Elasticsearch 需要)。 - 使用
oom_score_adj防止关键进程被 OOM Killer 终止。
- 增加
- IO:
- 调整
read_ahead缓冲区大小。 - 使用
noatime挂载选项减少磁盘写入。
- 调整
- 网络:
- 调整
net.core.somaxconn扩大连接队列。 - 启用
TCP BBR拥塞控制算法。
- 调整
- CPU:
- 实践案例:
- 场景:数据库服务器 CPU 使用率持续 90%。
- 步骤:
- 通过
perf top定位热点函数。 - 优化 SQL 查询(添加索引、减少全表扫描)。
- 调整 MySQL 配置(如
innodb_buffer_pool_size)。
- 通过
- 验证:对比调优前后的
sar数据,确保性能提升。
- 自动化监控:
- 结合 Prometheus + Grafana 实时监控关键指标,设置告警阈值。
欢迎关注 ❤
我们搞了一个免费的面试真题共享群,互通有无,一起刷题进步。
没准能让你能刷到自己意向公司的最新面试题呢。
感兴趣的朋友们可以私信我,备注:面试群。