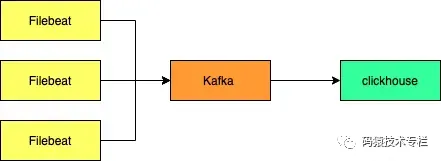
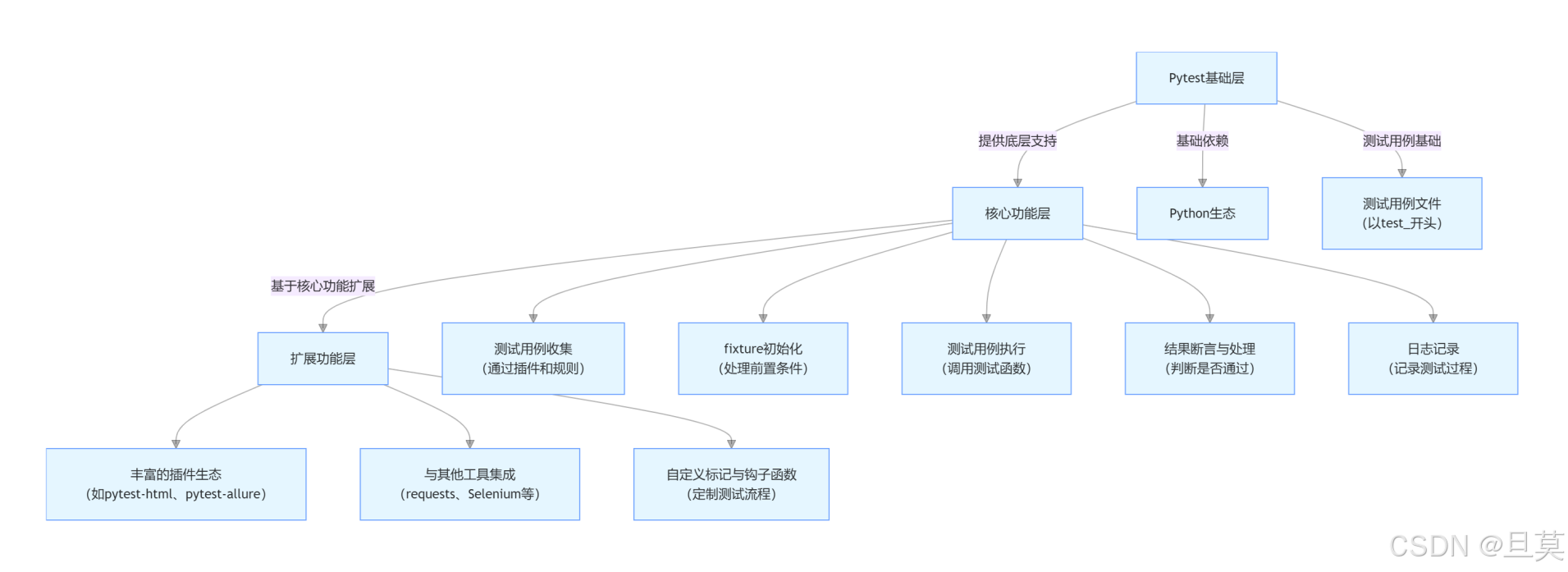
文章目录
- 引言
- 一、词袋法原理
- 1.1 核心思想
- 1.2 实现步骤
- 二、数学公式
- 2.1 词频表示
- 2.2 TF-IDF加权(可选)
- 三、示例表格
- 3.1 构建词汇表
- 3.2 文本向量化(词频)
- 四、Python代码实现
- 4.1 基础实现(手动计算)
- 4.2 输出结果
- 4.3 TF-IDF加权实现
- 五、注意事项
- 六、总结
引言
词袋法(Bag of Words, BoW)是自然语言处理(NLP)中最基础的文本向量化方法之一。它通过统计文本中词汇的出现频率,将非结构化的文本转换为结构化的数值向量,为后续的机器学习任务(如分类、聚类)提供输入。本文将系统讲解词袋法的原理、数学公式、实现步骤,并通过代码演示其完整流程。
一、词袋法原理
1.1 核心思想
词袋法将文本视为一个“袋子”,忽略语法、词序和句子结构,仅关注词汇的出现与否或出现次数。例如:
- 文本1:“I love NLP”
- 文本2:“NLP is fun”
词袋法会将这两个文本转换为向量,维度由所有唯一词汇构成,每个维度表示对应词汇的权重(如词频或TF-IDF值)。
1.2 实现步骤
- 构建词汇表:统计所有文本中的唯一词汇,形成词汇表 V = w 1 , w 2 , . . . , w N V={w_1,w_2,...,w_N} V=w1,w2,...,wN,其中 N 为词汇表大小。
- 文本向量化:对每个文本 d,生成一个 N 维向量 v d v_d vd,其中第 i 个元素表示词汇 w i w_i wi在 d 中的权重。
二、数学公式
2.1 词频表示
向量
v
d
v_d
vd的第 i 个元素为词频(Term Frequency, TF):
v
d
,
i
=
c
o
u
n
t
(
w
i
∈
d
)
v_{d,i}=count(w_i∈d)
vd,i=count(wi∈d)
2.2 TF-IDF加权(可选)
为降低常见词(如“the”、“is”)的权重,可使用TF-IDF:
T
F
−
I
D
F
(
w
i
,
d
)
=
T
F
(
w
i
,
d
)
×
l
o
g
(
1
+
D
1
+
D
F
(
w
i
)
)
TF-IDF(w_i,d)=TF(w_i ,d)×log( \frac{1+D}{1+DF(w_i)})
TF−IDF(wi,d)=TF(wi,d)×log(1+DF(wi)1+D)
其中:
- D D D为总文档数
- D F ( w i ) DF(w_i) DF(wi)为包含词汇 w i w_i wi的文档数
三、示例表格
假设有以下三个文档:
| 文档ID | 文本内容 |
|---|---|
| D1 | “cat sits on mat” |
| D2 | “dog sits on mat” |
| D3 | “cat chases mouse” |
3.1 构建词汇表
V = { c a t , s i t s , o n , m a t , d o g , c h a s e s , m o u s e } ( N = 7 ) V=\{cat, sits, on, mat, dog, chases, mouse\}(N=7) V={cat,sits,on,mat,dog,chases,mouse}(N=7)
3.2 文本向量化(词频)
| 文档 | cat | sits | on | mat | dog | chases | mouse |
|---|---|---|---|---|---|---|---|
| D1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| D2 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| D3 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
四、Python代码实现
4.1 基础实现(手动计算)
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# 示例文档
documents = [
"cat sits on mat",
"dog sits on mat",
"cat chases mouse"
]
# 1. 构建词汇表并向量化
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# 2. 输出结果
print("词汇表:", vectorizer.get_feature_names_out())
print("向量矩阵:\n", X.toarray())
4.2 输出结果
词汇表: ['cat' 'chases' 'dog' 'mat' 'mouse' 'on' 'sits']
向量矩阵:
[[1 0 0 1 0 1 1]
[0 0 1 1 0 1 1]
[1 1 0 0 1 0 0]]
4.3 TF-IDF加权实现
from sklearn.feature_extraction.text import TfidfVectorizer
# 使用TF-IDF向量化
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(documents)
print("TF-IDF向量矩阵:\n", X_tfidf.toarray())
五、注意事项
- 维度灾难:词汇表大小随数据量增长,可能导致高维稀疏矩阵。
- 语义丢失:忽略词序和上下文(如“不喜欢”和“喜欢”无法区分)。
- 预处理关键性:需结合停用词过滤、词干提取(如Porter Stemmer)提升效果。
六、总结
词袋法通过简单的统计实现了文本的数值化,是NLP任务的基石。尽管存在局限性,但其思想仍被广泛应用于早期文本分类系统(如垃圾邮件过滤)。对于需要语义理解的任务,可进一步探索Word2Vec、BERT等深度学习模型。