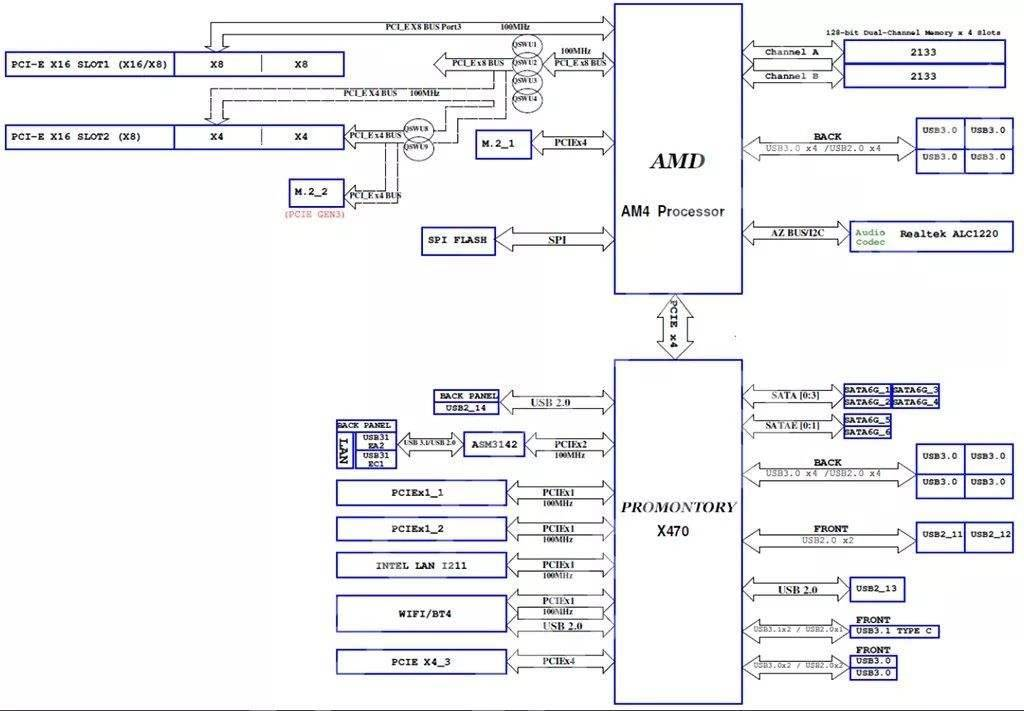
参考链接:
范数(Norm)——定义、原理、分类、作用与应用 - 知乎
带你秒懂向量与矩阵的范数(Norm)_矩阵norm-CSDN博客
什么是范数(norm)?以及L1,L2范数的简单介绍_l1 norm-CSDN博客
范数(Norm)是线性代数中的一个基本概念,用来度量一个向量的“长度”或“大小”。
(简单来说,范数告诉我们一个向量离原点有多远。)
- 向量范数 表征 向量空间中向量的大小,
- 矩阵范数 表征 矩阵引起变化的大小。
在机器学习中,范数常用于:
- 衡量预测误差(损失函数)
- 控制模型参数(正则化)
- 比较向量之间的相似度(归一化)
不同范数对应不同的学习目标:
- L1 控稀疏;
- L2 控幅度;
- L∞ 控最大值。
引入范数的原因
我们都知道,函数与几何图形往往是有对应的关系,这个很好想象,特别是在三维以下的空间内,函数是几何图像的数学概括,而几何图像是函数的高度形象化。
但当函数与几何超出三维空间时,就难以获得较好的想象,于是就有了映射的概念,进而引入范数的概念。当有了范数的概念,就可以引出两个向量的距离的定义,这个向量可以是任意维数的。
通过距离的定义,进而我们可以讨论逼近程度,从而讨论收敛性、求极限。
- 范数在计算机领域多用于:迭代过程中收敛性质的判断。
- 一般迭代前后步骤的差值的范数表示其大小,常用的是二范数,差值越小表示越逼近实际值,可以认为达到要求的精度,收敛。
总的来说,范数存在的意义是为了实现比较距离。
比如,在一维实数集合中,我们随便取两个点4和9,我们知道9比4大。
但是到了二维实数空间中,取两个点(1,0)和(3,4),这个时候就没法比较它们之间的大小,因为它们不是可以比较的实数。
于是引入范数这个概念,把(1,0)和(3,4)通过范数分别映射到实数1 和 5 (两个点分别到原点的距离),这样我们就比较这两个点了。
所以可以看到,范数其实是一个函数,它把不能比较的向量转换成可以比较的实数。
数学原理

向量的范数
在数学上,对于向量范数的定义,就是只要满足以下三条性质的函数,我们就可以称为它为范数。

(条件1的 的意思就是当且仅当的意思)
所以,范数的是一个宽泛的概念,有很多种,但是一般只会用到常用的范数。
线性代数中最有用的一些运算符是范数(norm)。 非正式地说,向量的范数是表示一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。
在线性代数中,向量范数是将向量映射到标量的函数
。 给定任意向量x,向量范数要满足一些属性。
性质3&4即正定,性质1即齐次,性质2即三角不等性。

向量的 L0范数
意义:非0元素个数

评价:L0范数表示向量中非零元素的个数。
L0范数的这个属性,使其非常适用于机器学习中的稀疏编码。
在特征选择中,通过最小化L0范数来寻找最少最优的稀疏特征项。
但是,L0范数的最小化问题是NP难问题。而L1范数是L0范数的最优凸近似,它比L0范数要更容易求解。
因此,优化过程将会被转换为更高维的范数(例如L1范数)问题。
向量的 L1范数 (曼哈顿范数、、最小绝对误差)
意义:各个元素的绝对值之和(向量x中非零元素的绝对值之和)
几何意义:实际走的 “横+竖” 的 “城市街道” 距离。

使用 L1范数可以度量两个向量间的差异,如绝对误差和(Sum of Absolute Difference):

由于L1范数的天然性质,对L1优化的解是一个稀疏解,
因此L1范数也被叫做 “Lasso regularization”(稀疏规则算子)。
通过L1可以实现特征的稀疏,去掉一些没有信息的特征,例如在对用户的电影爱好做分类的时候,用户有100个特征,可能只有十几个特征是对分类有用的,大部分特征如身高体重等可能都是无用的,利用L1范数就可以过滤掉。
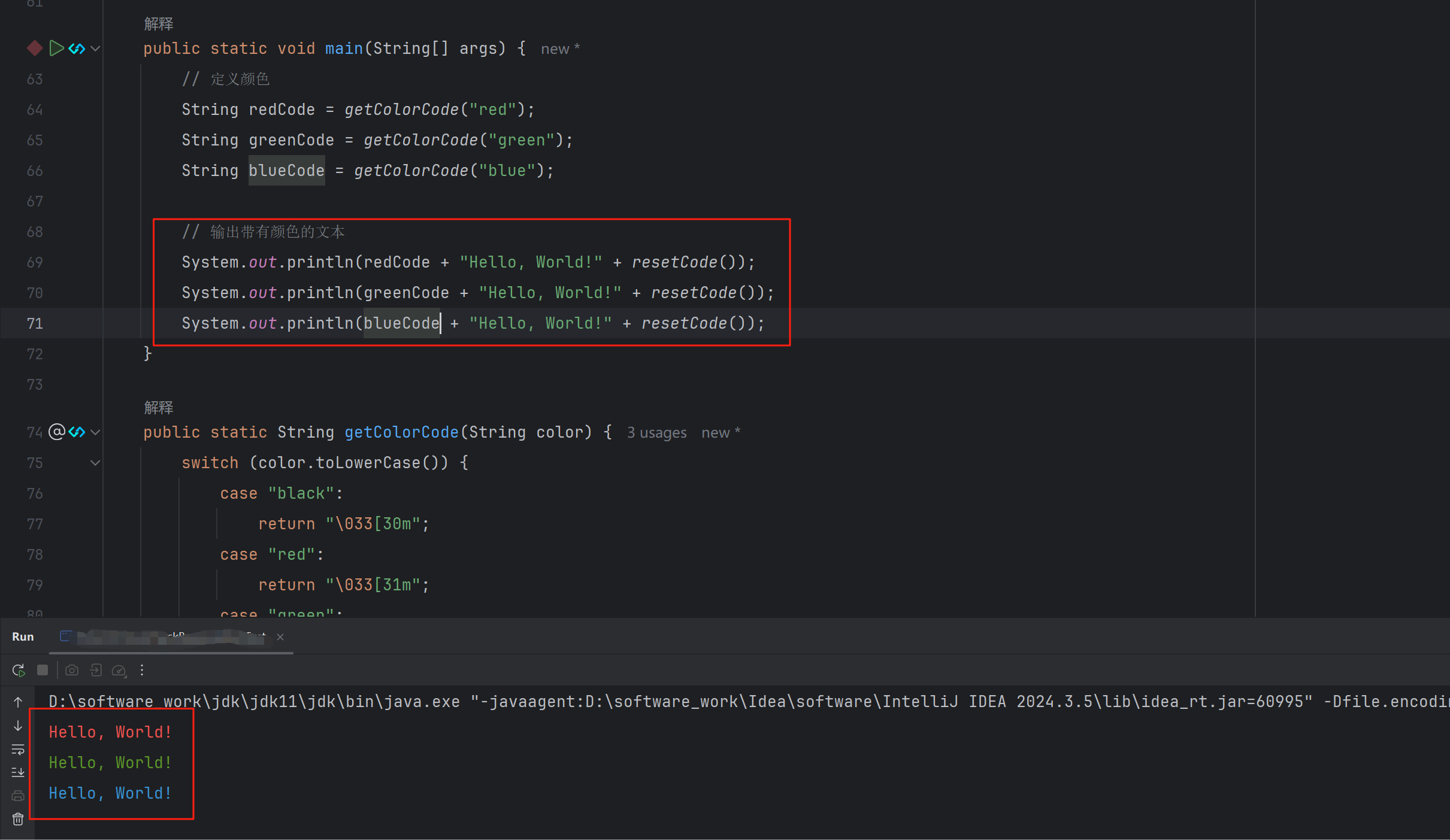
向量的 L2范数 (欧几里得范数)
意义:每个元素平方和再平方根
 即
即 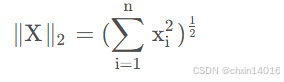
像L1范数一样,L2也可以度量两个向量间的差异,如平方差和(Sum of Squared Difference):

评价:L2范数是最常用的范数,比如用的最多的度量距离欧氏距离就是一种L2范数。
在回归里面,有人把加了L2范数项的回归c称为“岭回归”(Ridge Regression),有人也叫它“权值衰减(weight decay)”。
它被广泛的应用在解决机器学习里面的过拟合问题:
- 通常被用来做优化目标函数的正则化项,防止模型为了迎合训练集而过于复杂造成过拟合的情况,从而提高模型的泛化能力。
为什么L2范数可以防止过拟合?回答这个问题之前,我们得先看看L2范数实际上是什么。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项最小,可以使得的每个元素都很小,都接近于0(L1范数会让它等于0,而L2范数是接近于0),这是有很大的区别的。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?
因为当限制了参数很小,实际上就限制了多项式某些分量的影响很小,即 相当于减少参数个数。
向量的 Lp范数 (一般形式)
意义:每个元素p次方和再p次方根
- L0、L1、L2 都是Lp范数的特例,分别对应P=0、1、2的情况;
- 可调节p控制范数行为(越大越趋近于L∞,即最大范数)
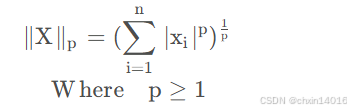 即
即 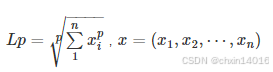
向量的 ∞范数 (最大范数)
意义:向量的 Lp范数的 p取无限大,即为向量的无穷范数,主要被用来度量向量元素的最大值。
- 取向量中最大绝对值作为长度。
- 有时用于鲁棒性分析。
![]()
PS
L2范数其实就是向量的标准内积,向量的长度一定是范数,长度是范数的充分条件,但不是必要条件,也就是说,范数不一定就是向量的长度。由
长度定义的性质可知,满足长度的定义要符合平行四边形。
举一个反例就可以证明非必要性:向量L1范数不满足平行四边形法则(A=(0,1)、B=(1,0))。
由内积决定的长度具有更丰富的几何结构。
总结
简单总结一下就是:
- L1范数: 为x向量各个元素绝对值之和,也叫“稀疏规则算”(Lasso regularization)。
- 比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
- L2范数: 为x向量各个元素平方和的1/2次方(即 元素平方和的开根号)。
- L2范数又称Euclidean范数或者Frobenius范数
- Lp范数: 为x向量各个元素绝对值p次方和的1/p次方。
使用机器学习方法解决实际问题时,通常用L1或L2范数做正则化(regularization),从而限制权值大小,减少过拟合风险。特别是在使用梯度下降来做目标函数优化时。
L1正则化产生稀疏的权值,L2正则化产生平滑的权值为什么会这样?
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便提取特征。
- L1范数可以使权值稀疏,方便特征提取。
- L2范数可以防止过拟合,提升模型的泛化能力。
L1和L2正则先验分别服从什么分布
- L1是拉普拉斯分布。
- L2是高斯分布。
矩阵的范数
跟向量的范数定义类似,只不过矩阵的范数的性质比向量的范数性质多了一条相容性。
我们直接引出矩阵的范数定义:

矩阵范数的第三条性质也称为加法相容性,第四条是乘法相容性,前提都是矩阵之间可以进行加法或乘法的运算。
矩阵的 1-范数(列模)
意义:矩阵的 列向量的和 的最大值,即 A的每列元素绝对值之和 的最大值,也称为A的列范数。
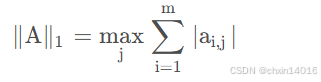
矩阵的 2-范数(谱模)
意义: 矩阵的最大特征值的开平方,也称谱范数。
- 特征值相当于是两个维度的压缩,相当于是从矩阵的维度里面找到最大的。

矩阵的 ∞范数(行模)
意义:矩阵的 行向量的和 的最大值,即 A的每行元素绝对值之和 的最大值,也称为A的行范数。
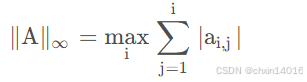
矩阵的 F-范数
意义:Frobenius范数,即矩阵元素绝对值的平方和再开平方。类似于向量的L2范数。
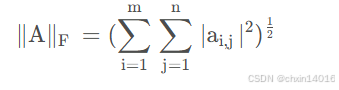 即
即 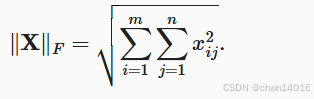
也可以描述为:
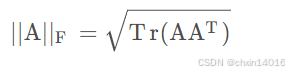
总结
简单总结一下就是:
- L1范数: 列范数,矩阵的 列向量的和 的最大值,即 A的每列元素绝对值之和 的最大值。
- L2范数:
矩阵的最大特征值的开平方,也称谱范数。
- 特征值相当于是两个维度的压缩,相当于是从矩阵的维度里面找到最大的。
- L∞范数: 行范数,矩阵的 行向量的和 的最大值,即 A的每行元素绝对值之和 的最大值。
- Lf范数: Frobenius范数,类似于向量的L2范数,矩阵元素平方和再开平方。
范数的作用
| 作用领域 | 用途 | 说明 |
|---|---|---|
| 向量距离 | 度量两个点或向量之间的“距离” | 用于损失函数、相似度计算 |
| 模型正则化 | 控制模型复杂度,防止过拟合 | 通过惩罚大参数避免学习噪声 |
| 向量归一化 | 把向量缩放到单位长度 | 常用于余弦相似度比较 |
| 稀疏表示 | 用最少的非零值表达信息 | L1 正则可自动“筛选特征” |
在机器学习中的实际应用
✅ 1. 损失函数中的误差度量
| 类型 | 范数 | 说明 |
|---|---|---|
| MAE(平均绝对误差) | L1 | 鲁棒,对异常值不敏感 |
| MSE(均方误差) | L2 | 常用,惩罚大误差更重 |
✅ 2. 模型正则化(Regularization)
| 类型 | 正则项 | 功能 |
|---|---|---|
| L1 正则(Lasso) | (\lambda \sum | \theta_i |
| L2 正则(Ridge) | λ∑θi2\lambda \sum \theta_i^2 | 缓和过拟合,不会让参数变0,但压小 |
✅ 3. 向量归一化(Normalization)

✅ 4. 稀疏建模(Sparse Modeling)
- 在某些应用中,希望模型只依赖少数几个特征(稀疏性):
- 如文本分类、基因数据分析;
使用 L1 正则可以“自动让不重要的参数变成 0”;
- L1 是稀疏性建模的核心工具。
面试范数相关常见提问汇总 + 答题思路
✅ 一、基础概念类问题(定义 + 原理)
❓Q1:解释一下什么是范数吗?
答题思路:
范数是一种用来衡量向量“大小”或“长度”的函数,它在机器学习中用于表示误差、距离、向量归一化或正则化。常见的范数有 L1 范数、L2 范数等,分别对应不同的应用需求。
❓Q2:L1 范数和 L2 范数的区别是什么?你更偏向哪一个?
答题思路:
- L1 范数是所有元素的绝对值之和,鼓励模型稀疏;
- L2 范数是所有元素平方和的平方根,鼓励整体平滑;
- 如果任务要求模型可解释性强、特征选择重要,我会选择 L1;
- 如果任务对稳定性更敏感,比如图像处理,我倾向 L2。
✅ 二、应用场景类问题(结合模型/正则)
❓Q3:在损失函数中为什么有时使用 L1 有时使用 L2?
答题思路:
- L1(如 MAE)更稳健,适合对异常值敏感的任务;
- L2(如 MSE)更常见,对大误差惩罚更重;
- 如果数据中有 outlier,建议使用 L1;
- 如果更关注整体误差稳定性,可以使用 L2。
❓Q4:正则化中 L1 和 L2 分别起什么作用?
答题思路:
- L1 正则通过绝对值惩罚,会使某些参数收缩为 0,实现特征选择;
- L2 正则通过平方惩罚,防止参数过大,减少过拟合;
- L1 更适合用于高维稀疏建模(如文本分类),L2 更适合神经网络等连续模型。
✅ 三、原理理解类问题(深入推导)
❓Q5:为什么 L2 正则不产生稀疏性,但 L1 会?
答题思路:
- 从几何角度讲,L1 范数的等值线是菱形,容易与损失函数的最优点交于坐标轴;
- 而 L2 范数的等值线是圆形,更倾向于“均匀缩小所有参数”而不是让某些为 0;
- 所以 L1 更容易“压掉”不重要的特征,让参数变为0。
❓Q6:你知道范数与梯度下降优化的关系吗?
答题思路:
- 在添加正则化的损失函数中,比如 L2,会影响梯度更新方向;
- L2 会加上 λθ\lambda \theta 项,等于对参数有一个“缩小”的趋势;
- L1 的梯度是非连续的(不可导点),所以常用次梯度或特殊优化方法处理。
✅ 四、项目/实践类问题(结合实际应用)
❓Q7:在项目中有没有用到范数?怎么选的 L1 / L2?
答题思路(举例):
- “在我做房价预测项目中,我使用了 L1 正则化进行特征选择,发现有多个冗余特征被自动归零,提升了模型解释性。”
- “而在另一个图像复原项目中,我使用了 L2 损失函数和 L2 正则,因为目标是尽可能还原每个像素值,不允许过大偏差。”
❓Q8:若模型过拟合了,会怎么用范数应对?
答题思路:
- 我会通过添加正则化项(L1/L2)来约束模型参数的规模;
- 如果模型很复杂,特征维度很高,我会尝试 L1 来让模型自动做特征选择;
- 如果我关注模型的稳定性和泛化性能,我会使用 L2 控制参数幅度。
✅ 五、开放性问题(考察综合素质)
❓Q9:如果我说 L2 正则是控制模型复杂度的“软剪枝”,你怎么理解?
答题思路:
- 软剪枝指的是“不强制为0,而是控制其变小”;
- L2 不会像 L1 一样使参数归零,但会持续压缩大的权重;
- 这有助于模型在保持全部特征的情况下减少过拟合。
快速知识卡片(可打印记忆)
| 项 | L1 范数 | L2 范数 |
|---|---|---|
| 公式 | (\sum | x_i |
| 名称 | 曼哈顿距离 | 欧几里得距离 |
| 特点 | 稀疏、鲁棒 | 平滑、常用 |
| 正则化应用 | Lasso(特征选择) | Ridge(稳定优化) |
| 适用场景 | 高维稀疏建模 | 连续模型控制复杂度 |
| 损失函数 | MAE | MSE |
| 面试关键词 | 特征选择、正则稀疏性 | 权重控制、余弦相似度归一化 |