什么是Apache Kafka?
Apache Kafka 是一个强大的开源分布式事件流平台。它最初由 LinkedIn 开发,最初是一个消息队列,后来发展成为处理各种场景数据流的工具。
Kafka 的分布式系统架构支持水平扩展,使消费者能够按照自己的节奏检索消息,并可以轻松地将 Kafka 节点(服务器)添加到集群中。
Kafka 旨在快速低延迟地处理大量数据。虽然它是用 Scala 和 Java 编写的,但它支持多种编程语言。
Apache Kafka 充当分布式日志收集器,将日志消息以键值对的形式存储在仅追加日志文件中,以实现持久的长期存储和检索。与 RabbitMQ 等传统消息队列(消息消费后即删除)不同,Kafka 会将消息保留一段可配置的时长,使其成为需要数据重放或事件溯源的用例的理想选择。
RabbitMQ 专注于实时消息传递,无需长期存储消息,而 Kafka 的保留策略则支持更复杂的数据驱动型应用程序。
Kafka 的常见用例包括应用程序跟踪、日志聚合和消息传递,但它缺乏查询和索引等传统数据库功能。它的优势在于处理实时数据流,这使其成为分布式系统和实时分析不可或缺的一部分。
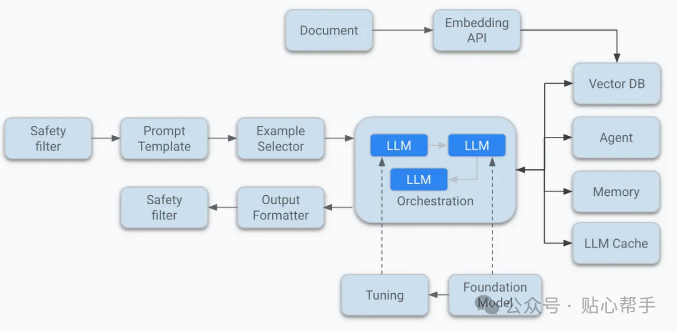
现在我们将讨论 Kafka 的架构和基本组件。下图是 Kafka 的架构示意图。
Kafka 有哪些特性?
Apache Kafka 是一个开源分布式流处理平台,广泛用于构建实时数据管道和流处理应用程序。它具有以下特性:
1. 高吞吐量
Kafka 能够处理海量数据。它旨在高效地从源客户端读取和写入数百 GB 的数据。
2. 分布式架构
Apache Kafka 采用以集群为中心的架构,并原生支持跨 Kafka 服务器的消息分区。这种设计还支持跨集群的消费者机器进行分布式消费,同时保持每个分区内消息的顺序。此外,Kafka 集群可以弹性透明地扩展,无需停机。
3. 支持各种客户端
Apache Kafka 支持集成来自不同平台的客户端,例如 .NET、JAVA、PHP 和 Python。
4. 实时消息
Kafka 生成实时消息,这些消息应该对消费者可见;这对于复杂的事件处理系统至关重要。
Kafka 与 RabbitMQ 有何不同?
Kafka 和 RabbitMQ 是两种流行的消息系统,在架构和使用方面有所不同。您可以比较一下它们在以下关键方面的差异:
1. 使用和设计
Kafka 旨在处理大规模数据流和实时管道,并针对高吞吐量和低延迟进行了优化。其基于日志的架构确保了数据的持久性,并允许数据重新处理,使其成为事件溯源和流处理等用例的理想选择。
RabbitMQ 是一个通用的消息代理,支持复杂的路由,通常用于微服务之间的消息传递或在工作器之间分配任务。它在可靠的消息传递、灵活的路由和服务间交互至关重要的环境中表现出色。
2. 架构
Kafka 将消息分类到主题中,主题又被划分为分区。每个分区可以由多个消费者处理,从而实现并行处理和扩展。数据存储在磁盘上,并具有可配置的保留期,确保了数据的持久性,并允许在需要时重新处理消息。
RabbitMQ 将消息发送到队列,由一个或多个消费者消费。它通过消息确认、重试和用于处理失败消息的死信交换来确保可靠的消息传递。该架构注重消息完整性和路由灵活性。
3. 性能和可扩展性
Kafka 通过添加更多代理和分区来实现水平可扩展性,使其每秒能够处理数百万条消息。其架构支持并行处理和高吞吐量,使其成为大规模数据流的理想选择。
RabbitMQ 可以扩展,但在处理海量数据时效率不如 Kafka。它适用于中高吞吐量场景,但并未针对 Kafka 在大规模流式应用中所能处理的极限吞吐量进行优化。
Kafka 和 RabbitMQ 都是强大的消息传递工具,但它们在不同的用例中表现出色。Kafka 非常适合需要大规模并行处理的高吞吐量、实时数据流和事件溯源应用程序。
RabbitMQ 非常适合可靠的消息传递、微服务架构中的任务分配以及复杂的消息路由。它在需要服务间松散耦合、异步处理和可靠性的场景中表现出色。
Kafka 的基本组件:
Broker
它是 Kafka 系统最基本的组件。在 Kafka 集群中运行的每个服务器/服务都称为 Broker。每个 Broker 都由一个由数字组成的 ID 标识。它们物理连接到安装它们的服务器,但 Broker 即使不在集群中,也能感知集群中的所有主题和分区。Broker 充当生产者和消费者的连接点。
Zookeeper
这是一个开源服务,具有分布式键值数据存储功能,已被许多开源项目(尤其是大数据项目)所使用。Kafka 的 Zookeeper 负责在集群中添加和删除 Broker,确定 Leader/Controller Broker,保存主题配置等。它负责集群管理。如今,Kafka 在新版本中已经不再使用 Zookeeper。但它在当前使用它的系统中也可用。
Topic
它是一种类似于 Kafka 数据库中队列或消息队列的结构,数据写入后所有 Broker 都可以访问。它们由用户命名。Kafka 集群中可以有数千个 Topic。
Partition
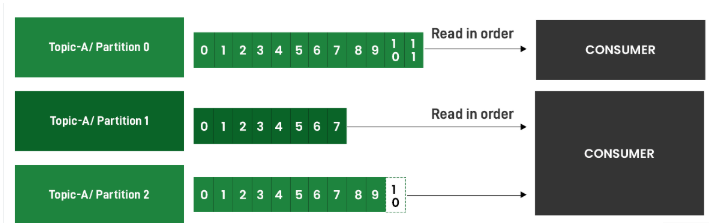
Topic 被划分为多个分区。分区从 0 开始,并按递增顺序排列。在 Topic 中,可以创建单个分区,也可以根据场景创建一千个分区。数据一旦写入分区,就无法再次更改。
分区本身是连续的。但是,分区之间没有顺序。例如,有两个分区:分区 0 和分区 1。首先,消息 0 写入分区 0,然后消息 1 写入分区 1,最后消息 2 写入分区 0。在这种情况下,消息 0 总是先于消息 2 读取。但是,Kafka 不保证消息 1 会在消息 0 之前或之后读取。如果您不介意消息的读取顺序,可以使用不同的键生成消息。但是,如果您需要两条或更多消息按各自的顺序写入,则应使用相同的键生成这些消息。因为 Kafka 会将使用相同键生成的消息写入同一分区,从而确保消息的顺序。但是,如果您不介意消息的顺序,那么使用相同键发送所有消息会存在缺点。因为 Kafka 会将所有这些消息写入单个分区,从而导致负载无法分散。
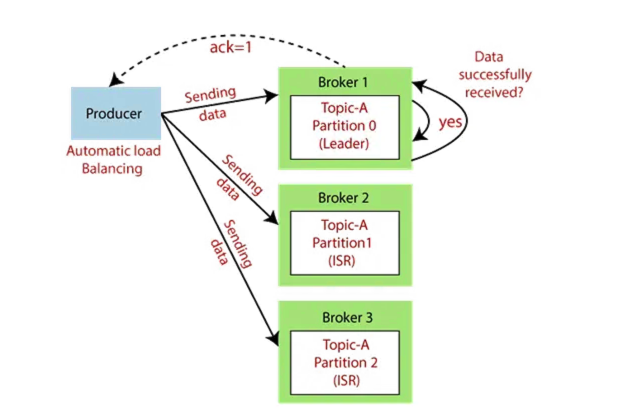
复制
分布式系统的优势之一是即使其中一台服务器离线,系统也能持续维护。得益于 Kafka 中的副本,系统可以持续运行并防止数据丢失。通过复制,主题的每个分区都存储在多台服务器上。其中一台服务器是 Leader,其他服务器是称为 ISR(同步副本)的副本。ISR 是被动服务器,负责同步数据并保存副本。数据交换由 Leader 提供。Leader 和 ISR 由 Zookeeper 决定。创建主题时,使用复制因子 (replication-factor) 参数指定复制次数。如果领导者所在的服务器发生故障,ZooKeeper 会指定其中一个 ISR 作为领导者,系统将继续运行而不会中断。
偏移量
偏移量是分区特定的,在将数据写入每个分区时都会分配一个标识号。这样,数据可以按照写入分区的顺序读取,消费者在读取分区时可以记住自己所在的消息。偏移量从 0 开始,可以无限期地持续下去。每次写入一条消息时,都会为新消息分配下一个偏移量。Kafka 消息在读取后不会消失。它会在指定的保留时间内继续保留。消费者读取一条消息后,偏移量会递增 1,并从下一条消息继续读取。由于偏移量会保留一段时间,因此如果要再次读取之前读取的消息,可以通过重置偏移量来重复读取过程。
Kafka 生产者和消费者
生产者
生产者是客户端应用程序,它将事件消息写入 Kafka 集群中的主题。消息以键值对的形式存储在主题的分区中。正如前文中提到的,使用相同键生成的消息会写入同一个分区。在生产过程中发送键并非强制性要求。
要从应用程序生成消息,首先需要编写生产者配置。生产者配置可能需要的一些配置如下。
- acks:acks 是指生产者接收发送到 Kafka 集群的消息时,必须收到来自 Broker 的最小确认数。它的值可以是“all”、“0”和“1”。all 表示生产者将等待 Leader 分区收到所有 Follower 已提交消息的确认。1 表示 Leader 分区足以写入其自己的提交日志。0 表示不需要确认。
- max.in.flight.requests.per.connection:客户端在阻塞之前在单个连接中可以发送的最大未批准请求数。默认值为 5。
- linger.ms:表示批量记录请求准备好发送之前的延迟时间。生产者会将两次请求之间收到的所有记录汇总到一个请求中。linger.ms 指定批处理的延迟上限。默认值为 0。这意味着不会有延迟,批处理将立即发送(即使批处理中只有 1 条消息)。在某些情况下,客户端可能会增加 linger.ms 以减少请求数量,即使在中等负载下也能提高吞吐量。只有这样,才能在内存中存储更多记录。
- batch.size:当多条记录发送到同一分区时,生产者会尝试将这些记录汇总在一起。通过这种方式,可以提高客户端和服务器的性能。batch.size 表示单个批处理的最大大小(以字节为单位)。较小的批处理大小会使批处理变得繁琐并降低效率;过大的批处理大小会浪费内存,因为通常会分配一个缓冲区来等待额外的记录。
生产者在向 Kafka 生成消息时需要序列化器。序列化器有很多种,但通常使用字符串、json 和 avro 序列化器。
消费者
消费者是从主题读取事件消息的客户端应用程序。您已经创建了主题,编写了生产器应用程序,数据正在流向 Kafka,现在是时候编写消费者应用程序了。您需要为消费者和生产器添加配置。有些配置与生产器通用,有些配置是消费者专用的。消费者配置可能需要的一些配置如下。
- auto.offset.reset:auto.offset.reset 参数用于确定消费者启动时从何处读取数据。如果设置为“earliest”,则从头开始重新读取主题中的数据。如果设置为“latest”,则从最后一个偏移量继续读取。如果设置为“none”,则表示起始偏移量需要手动确定。
- enable.auto.commit:我们之前讨论过偏移量。消费者读取一条消息后,偏移量会加 1,以便另一个消费者或同一个消费者可以从下一条消息继续读取。必须提交该消息才能使偏移量加 1。如果此参数设置为 true,则消费者在读取消息后,如果任何情况下都没有发生故障,消息就会自动提交。如果设置为 false,则需要使用 commitSync() 方法手动提交。我举一个手动提交的例子。假设你从 Kafka 读取一条数据后有两个操作。第一个是将记录发送到数据库,第二个是向用户发送推送通知。这里对你来说,关键是要将记录写入数据库,并且不要重复执行。无论 pn 是否被清除,都可能存在问题。为此,请在将记录写入数据库后手动提交。这样,如果在此之后的任何步骤中出现错误,由于偏移量已经提前,因此不会出现重复记录。但是,如果使用自动提交机制,如果在发送 pn 时发生错误,由于偏移量不会增加,因此将再次处理同一条消息。
- fetch.min.bytes:此配置用于指定一次要获取的最小数据字节数。其默认值为 1。
- fetch.max.bytes:此配置用于指定一次要获取的最大数据字节数。默认值为 52428800(50MB)。
- max.poll.records:此配置用于指定一次要捕获的记录数。默认值为 500。
消费者组
与消费者相关的最重要的概念之一是消费者组。我想详细讨论它,因为必须完全建立消费者组逻辑才能编写高效的消费者应用程序。
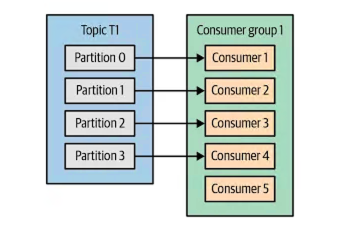
一个主题通常包含多个分区。这些分区是 Kafka 消费者并行处理的成员。消费者通过消费分区而成为消费者组的一部分。一个主题可能有多个消费者组在消费。每个消费者组都有一个唯一的 ID。该 ID 由用户分配。
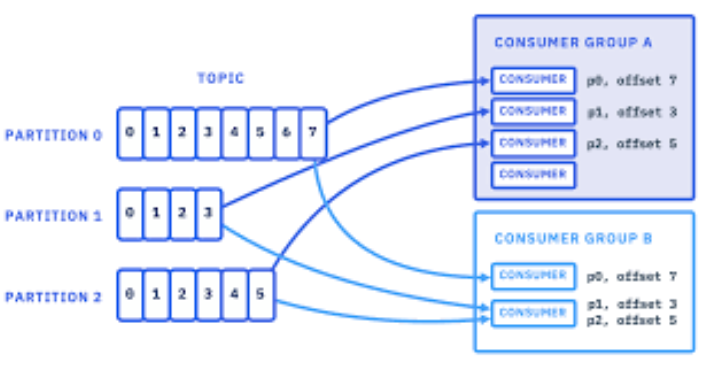
假设您有一个名为“user”的主题,该主题有 5 个分区。您编写了一个名为 Consumer1 的应用程序,并将消费者组 ID 设置为“userConsumerGroup”,该消费者组将消费用户主题。当您将应用程序部署为 3 个实例时,Kafka 的 GroupCoordinator 和 ConsumerCoordinator 会将 Consumer1 应用程序的 3 个实例分配给用户主题的 3 个分区。然后,您编写了一个名为 Consumer2 的新应用程序,并将其组 ID 设置为“userConsumerGroup”。当您将此应用程序部署为 3 个实例时,协调器会重新平衡消费者组,并将总共 6 个实例中的 5 个分配给用户主题的 5 个分区。1 个实例保持空闲状态,不执行任何消费操作。如果其中一个活动实例发生故障,则会再次进行重新平衡,并将空闲实例纳入游戏并分配到一个分区。我还必须说明,我给出的示例并非非常现实。通常,两个不同的应用程序不会包含在同一个消费者组中。如果同一主题中的消息将用于不同的目的,则需要分配不同的应用程序和不同的消费者组。
我们继续以单个应用程序为例。“用户”主题有 3 个分区,Consumer1 应用程序有 3 个实例。每个实例消费一个分区并继续运行。但是您的负载增加了,从每月 1000 个注册到该主题,到每天 100 万个注册。消息开始在您的分区中累积,应用程序难以使用它们。这里要做的第一件事是增加主题中的分区数量,并分发到达 Kafka 的消息。您将分区数增加到 12,消息开始跨分区分布。但是,由于应用程序中有 3 个实例,因此消费者组中有 3 个活跃成员,它们在时间 t 最多可以消费 3 个分区。因此,消息继续累积在 9 个分区中。这里有两种方法可供选择。第一种方法是将应用程序的实例数增加到 12。这样,每个实例将与一个分区配对,而在时间 t 时将消费 3 条消息,那么将消费 12 条消息,理论上速度将提高四倍。另一种方法是增加并发度。默认并发度为 1。如果您信任每个实例的来源,则可以增加并发度,并使一个实例消费多个分区。您可以将并发性视为一个线程。在这种情况下,如果将 3 个实例的并发度设置为 4,则可以并行消费总共 12 个分区。如果希望所有分区同时消费,则最大并发度为分区数 = 实例数 * 并发度。另外,我想指出的是,Kafka 每秒可以传输数百万条数据。但消费和处理数据的能力与您的应用程序和资源成正比。因此,Kafka 会说:“我可以传输大量数据给您,但您有能力处理吗?”
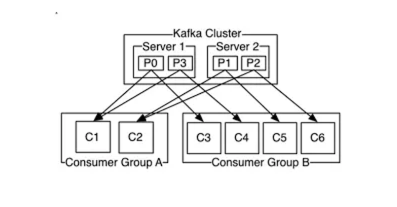
我想讨论最后一个关于消费者组的案例。人们通常会问这样的问题:“我在本地启动了测试应用程序,消息的偏移量正在增加,但我没有消费它。”原因如下。您的测试应用程序在 2 个实例中运行,它消费的主题有 2 个分区。如果您使用相同的消费者组 ID 在本地启动应用程序,由于没有空闲分区,您将无法消费。偏移量仍在增加,因为测试环境中的应用程序正在消费。解决方案是,如果您在本地运行应用程序时更改了消费者组 ID,则主题实例分发将在另一个组中进行,与测试环境无关。您仍然可以使用它。但这里有一点需要注意。如果在消费后,您可以保存到数据库、发送电子邮件、更新余额等。如果您正在进行交易,这些操作将是重复的。我建议针对这种情况添加本地检查。







![[ACTF2020 新生赛]BackupFile题解](https://i-blog.csdnimg.cn/direct/4a2e9be71c5e41fc934d878afdeb0cb0.png)