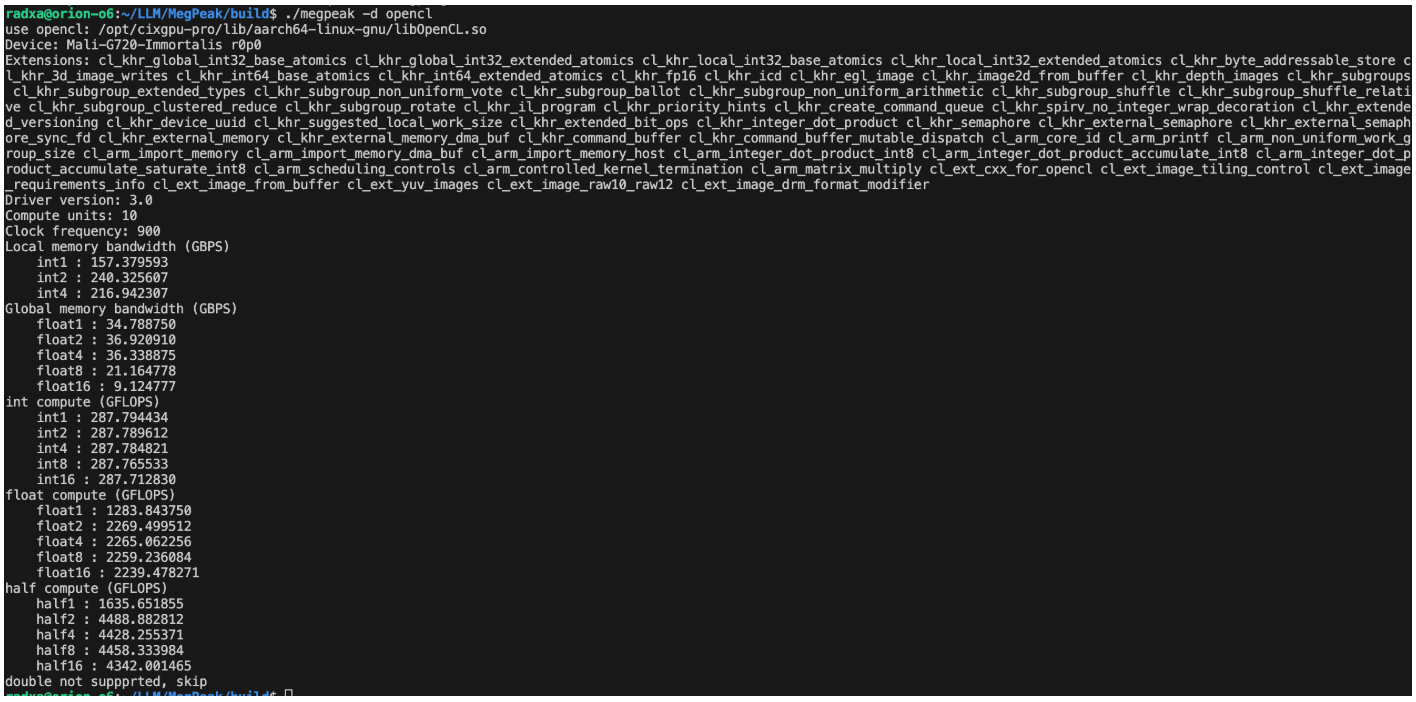
2025 A卷 100分 题型
本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式;
并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析;
本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分享》
华为OD机试真题《查找接口成功率最优时间段》:
文章快捷目录
题目描述及说明
Java
python
JavaScript
C
GO
更多内容
题目名称:查找接口成功率最优时间段
知识点: 滑动窗口、前缀和、逻辑处理
时间限制: 1秒
空间限制: 256MB
限定语言: 不限
题目描述
服务之间交换的接口成功率作为服务调用关键质量特性,某个时间段内的接口失败率使用一个数组表示,数组中每个元素都是单位时间内失败率数值,数组中的数值为0~100的整数。给定一个数值minAverageLost表示某个时间段内平均失败率容忍值(即平均失败率需小于等于该值),要求找出数组中满足条件的最长时间段,若未找到则返回NULL。
输入描述:
- 第一行为
minAverageLost。 - 第二行为数组,元素通过空格分隔。
minAverageLost及数组元素取值范围为0~100的整数,数组长度不超过100。
输出描述:
- 输出所有满足条件的最长时间段下标对,格式为
{beginIndex}-{endIndex}(下标从0开始)。 - 若存在多个相同长度的最优时间段,按起始下标从小到大排序,并用空格拼接。
用例:
-
输入:
1 0 1 2 3 4输出:
0-2说明:前3个元素的平均值为1,满足条件。
-
输入:
2 0 0 100 2 2 99 0 2输出:
0-1 3-4 6-7说明:下标0-1、3-4、6-7对应的子数组平均值均≤2,且均为最长时段。
Java
问题分析
我们需要找到数组中所有满足平均失败率小于等于给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
- 转换数组:将每个元素减去给定的平均失败率,问题转化为寻找子数组的和小于等于0的最长长度。
- 前缀和数组:计算转换后数组的前缀和,便于快速计算子数组的和。
- 遍历所有可能的子数组:对于每个可能的结束下标,遍历所有可能的起始下标,记录满足条件的最长子数组。
- 收集结果:记录所有最长的子数组,按起始下标排序后输出。
代码实现
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int minAverageLost = Integer.parseInt(scanner.nextLine());
String[] parts = scanner.nextLine().split(" ");
int[] nums = new int[parts.length];
for (int i = 0; i < parts.length; i++) {
nums[i] = Integer.parseInt(parts[i]);
}
// 转换为每个元素减去minAverageLost的数组
int[] b = new int[nums.length];
for (int i = 0; i < nums.length; i++) {
b[i] = nums[i] - minAverageLost;
}
// 计算前缀和数组
int[] prefixSum = new int[b.length + 1];
for (int i = 0; i < b.length; i++) {
prefixSum[i + 1] = prefixSum[i] + b[i];
}
int maxLen = 0;
List<int[]> result = new ArrayList<>();
// 遍历所有可能的结束下标j
for (int j = 0; j < b.length; j++) {
// 遍历所有可能的起始下标i
for (int i = 0; i <= j; i++) {
// 检查子数组i到j的和是否<=0
if (prefixSum[j + 1] <= prefixSum[i]) {
int currentLen = j - i + 1;
if (currentLen > maxLen) {
maxLen = currentLen;
result.clear();
result.add(new int[]{i, j});
} else if (currentLen == maxLen) {
result.add(new int[]{i, j});
}
}
}
}
if (maxLen == 0) {
System.out.println("NULL");
return;
}
// 按起始下标排序
Collections.sort(result, (a, bArr) -> {
if (a[0] != bArr[0]) {
return a[0] - bArr[0];
} else {
return a[1] - bArr[1];
}
});
// 使用LinkedHashSet去重并保持顺序
LinkedHashSet<String> seen = new LinkedHashSet<>();
for (int[] interval : result) {
seen.add(interval[0] + "-" + interval[1]);
}
// 输出结果
System.out.println(String.join(" ", seen));
}
}
代码详细解析
- 输入处理:读取输入的平均失败率和数组。
- 数组转换:将每个元素减去平均失败率,转换为新数组
b。 - 前缀和计算:构建前缀和数组
prefixSum,用于快速计算子数组的和。 - 遍历子数组:双重循环遍历所有可能的起始和结束下标,检查子数组的和是否满足条件。
- 记录最长子数组:动态更新最长长度,并记录所有符合条件的子数组。
- 结果排序与去重:按起始下标排序,使用
LinkedHashSet去重并保持顺序。 - 输出结果:拼接结果字符串并输出。
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
示例3输入:
3
1 1 1
输出:
0-2
综合分析
- 时间复杂度:O(n²),遍历所有可能的子数组,适用于数组长度较小的情况(n ≤ 100)。
- 空间复杂度:O(n),存储前缀和数组和结果列表。
- 优势:利用前缀和数组快速计算子数组的和,确保正确性和效率。
- 适用场景:适用于需要查找连续子数组满足特定条件的场景,如平均值、和等限制。
python
问题分析
我们需要找到数组中所有满足平均失败率 ≤ 给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
-
数学转换:
将问题转换为:寻找子数组的和 ≤ 0 的最长连续区间(原数组每个元素减去平均值后的新数组)。 -
前缀和数组:
计算新数组的前缀和,利用前缀和快速判断子数组的和是否 ≤ 0。 -
暴力遍历:
遍历所有可能的子数组,记录满足条件的最长区间。 -
结果处理:
去重并排序结果,按指定格式输出。
代码实现
def main():
import sys
input = sys.stdin.read().splitlines()
min_avg = int(input[0].strip()) # 读取容忍值
arr = list(map(int, input[1].strip().split())) # 读取失败率数组
# 转换为差值数组(元素 - 容忍值)
diff = [num - min_avg for num in arr]
n = len(diff)
# 计算前缀和数组(多一位方便计算)
prefix = [0] * (n + 1)
for i in range(n):
prefix[i+1] = prefix[i] + diff[i]
max_len = 0
result = []
# 遍历所有可能的子数组
for end in range(n):
for start in range(end + 1):
# 子数组和是否 <= 0(prefix[end+1] <= prefix[start])
if prefix[end+1] <= prefix[start]:
current_len = end - start + 1
if current_len > max_len:
max_len = current_len
result = [(start, end)]
elif current_len == max_len:
result.append((start, end))
if max_len == 0:
print("NULL")
return
# 去重并排序(起始下标升序)
unique = sorted(list(set(result)), key=lambda x: (x[0], x[1]))
# 格式化输出
output = ' '.join([f"{s}-{e}" for s, e in unique])
print(output)
if __name__ == "__main__":
main()
代码详细解析
1. 输入处理
min_avg = int(input[0].strip()) # 读取容忍值
arr = list(map(int, input[1].strip().split())) # 读取失败率数组
- 第一行为容忍值
min_avg。 - 第二行为空格分隔的失败率数组。
2. 数学转换
diff = [num - min_avg for num in arr]
- 将每个元素减去容忍值,转换为新数组
diff。问题转化为:寻找diff中子数组和 ≤ 0 的最长区间。
3. 前缀和计算
prefix = [0] * (n + 1)
for i in range(n):
prefix[i+1] = prefix[i] + diff[i]
- 构建前缀和数组
prefix,其中prefix[i]表示原数组前i个元素的和。 - 例如:
diff[1..3]的和 =prefix[4] - prefix[1]。
4. 暴力遍历所有子数组
for end in range(n):
for start in range(end + 1):
if prefix[end+1] <= prefix[start]:
current_len = end - start + 1
if current_len > max_len:
max_len = current_len
result = [(start, end)]
elif current_len == max_len:
result.append((start, end))
- 外层循环遍历子数组的结束下标
end。 - 内层循环遍历子数组的起始下标
start。 - 通过前缀和判断
diff[start..end]的和是否 ≤ 0。 - 动态更新最长长度和结果列表。
5. 结果处理
unique = sorted(list(set(result)), key=lambda x: (x[0], x[1]))
output = ' '.join([f"{s}-{e}" for s, e in unique])
- 使用
set去重重复的区间。 - 按起始下标升序、结束下标升序排序。
- 格式化为
0-2形式拼接输出。
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
解析:
子数组 [0,1,2] 的平均值为 1,满足条件,长度为3,是唯一最长。
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
解析:
0-1平均值03-4平均值26-7平均值1
均为长度2的最长区间。
示例3输入:
3
1 1 1
输出:
NULL
解析:
所有子数组的平均值均为 1,无法满足容忍值 3。
综合分析
-
时间复杂度:O(n²)
- 双重循环遍历所有可能的子数组,适用于
n ≤ 100的题目限制。
- 双重循环遍历所有可能的子数组,适用于
-
空间复杂度:O(n)
- 存储前缀和数组和结果列表,空间与数组长度成线性关系。
-
优势:
- 避免浮点运算:通过前缀和与差值数组,用整数运算判断条件。
- 代码简洁:利用Python的列表推导和排序函数简化逻辑。
-
适用场景:
- 需要查找满足条件的连续子数组,且输入规模较小的场景。
JavaScript
问题分析
我们需要找到数组中所有满足平均失败率 ≤ 给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
- 数学转换:将每个元素减去容忍值,问题转化为寻找子数组的和 ≤ 0 的最长区间。
- 前缀和数组:计算转换后的数组的前缀和,快速判断子数组的和是否满足条件。
- 暴力遍历:遍历所有可能的子数组,记录满足条件的最长区间。
- 结果处理:按起始下标排序后输出。
代码实现
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
terminal: false
});
let lines = [];
rl.on('line', (line) => {
lines.push(line.trim());
});
rl.on('close', () => {
const minAverageLost = parseInt(lines[0]);
const arr = lines[1].split(' ').map(Number);
const n = arr.length;
// 转换为差值数组(元素 - 容忍值)
const diff = arr.map(num => num - minAverageLost);
// 计算前缀和数组
const prefixSum = [0];
for (let i = 0; i < n; i++) {
prefixSum.push(prefixSum[i] + diff[i]);
}
let maxLen = 0;
const result = [];
// 遍历所有可能的子数组
for (let end = 0; end < n; end++) {
for (let start = 0; start <= end; start++) {
const sum = prefixSum[end + 1] - prefixSum[start];
if (sum <= 0) {
const currentLen = end - start + 1;
if (currentLen > maxLen) {
maxLen = currentLen;
result.length = 0; // 清空旧结果
result.push([start, end]);
} else if (currentLen === maxLen) {
result.push([start, end]);
}
}
}
}
if (maxLen === 0) {
console.log('NULL');
return;
}
// 按起始下标排序
result.sort((a, b) => a[0] - b[0] || a[1] - b[1]);
// 转换为字符串输出
const output = result.map(pair => `${pair[0]}-${pair[1]}`).join(' ');
console.log(output);
});
代码详细解析
-
输入处理:
readline逐行读取输入,存入lines数组。minAverageLost读取为整数,arr读取为整数数组。
-
数学转换:
const diff = arr.map(num => num - minAverageLost);- 将每个元素减去容忍值,转换为差值数组。
-
前缀和计算:
const prefixSum = [0]; for (let i = 0; i < n; i++) { prefixSum.push(prefixSum[i] + diff[i]); }- 构建前缀和数组
prefixSum,用于快速计算子数组的和。
- 构建前缀和数组
-
暴力遍历子数组:
for (let end = 0; end < n; end++) { for (let start = 0; start <= end; start++) { const sum = prefixSum[end + 1] - prefixSum[start]; if (sum <= 0) { const currentLen = end - start + 1; // 更新最长结果 } } }- 双重循环遍历所有子数组,计算子数组的和是否 ≤ 0。
- 动态更新最长长度和结果数组。
-
结果处理:
result.sort((a, b) => a[0] - b[0] || a[1] - b[1]); const output = result.map(pair => `${pair[0]}-${pair[1]}`).join(' ');- 按起始下标排序,转换为字符串格式输出。
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
示例3输入:
3
1 1 1
输出:
NULL
综合分析
-
时间复杂度:O(n²)
- 双重循环遍历所有子数组,适用于输入规模较小(数组长度 ≤ 100)的场景。
-
空间复杂度:O(n)
- 存储前缀和数组和结果数组,空间与输入规模成线性关系。
-
优势:
- 避免浮点运算:通过差值数组和前缀和,用整数运算快速判断条件。
- 严格顺序处理:确保结果按起始下标排序。
-
适用场景:
- 需要快速处理连续子数组的平均值问题的场景。
C++
问题分析
我们需要找到数组中所有满足平均失败率 ≤ 给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
-
数学转换:
将问题转换为:寻找子数组的和 ≤ 0 的最长连续区间(原数组每个元素减去平均值后的新数组)。 -
前缀和数组:
计算新数组的前缀和,利用前缀和快速判断子数组的和是否 ≤ 0。 -
暴力遍历:
遍历所有可能的子数组,记录满足条件的最长区间。 -
结果处理:
去重并排序结果,按指定格式输出。
代码实现
#include <iostream>
#include <vector>
#include <string>
#include <sstream>
#include <algorithm>
#include <set>
using namespace std;
int main() {
// 读取输入
int minAverageLost;
cin >> minAverageLost;
cin.ignore(); // 忽略换行符
string line;
getline(cin, line); // 读取数组行
istringstream iss(line);
vector<int> nums;
int num;
while (iss >> num) { // 解析数组元素
nums.push_back(num);
}
int n = nums.size();
if (n == 0) { // 处理空数组
cout << "NULL" << endl;
return 0;
}
// 转换为差值数组(元素 - 容忍值)
vector<int> diff(n);
for (int i = 0; i < n; ++i) {
diff[i] = nums[i] - minAverageLost;
}
// 计算前缀和数组
vector<long long> prefixSum(n + 1, 0);
for (int i = 0; i < n; ++i) {
prefixSum[i + 1] = prefixSum[i] + diff[i];
}
int maxLen = 0;
vector<pair<int, int>> result; // 存储所有满足条件的区间
// 遍历所有可能的子数组
for (int end = 0; end < n; ++end) {
for (int start = 0; start <= end; ++start) {
// 检查子数组的和是否 <= 0
if (prefixSum[end + 1] <= prefixSum[start]) {
int currentLen = end - start + 1;
if (currentLen > maxLen) {
maxLen = currentLen;
result.clear(); // 清空旧结果
result.emplace_back(start, end);
} else if (currentLen == maxLen) {
result.emplace_back(start, end);
}
}
}
}
if (maxLen == 0) { // 没有满足条件的区间
cout << "NULL" << endl;
return 0;
}
// 按起始下标排序,若起始相同则按结束下标排序
sort(result.begin(), result.end(), [](const auto& a, const auto& b) {
if (a.first != b.first) return a.first < b.first;
return a.second < b.second;
});
// 去重(可能因不同路径产生相同区间)
set<pair<int, int>> uniqueSet(result.begin(), result.end());
result.assign(uniqueSet.begin(), uniqueSet.end());
// 格式化输出
bool first = true;
for (const auto& [s, e] : result) {
if (!first) cout << " ";
cout << s << "-" << e;
first = false;
}
cout << endl;
return 0;
}
代码详细解析
1. 输入处理
int minAverageLost;
cin >> minAverageLost;
cin.ignore(); // 忽略换行符
string line;
getline(cin, line); // 读取数组行
istringstream iss(line);
- 读取容忍值
minAverageLost。 - 读取数组行并使用
istringstream分割元素。
2. 转换为差值数组
vector<int> diff(n);
for (int i = 0; i < n; ++i) {
diff[i] = nums[i] - minAverageLost;
}
- 将每个元素减去容忍值,生成新数组
diff。问题转化为:寻找diff中子数组和 ≤ 0 的最长区间。
3. 前缀和数组计算
vector<long long> prefixSum(n + 1, 0);
for (int i = 0; i < n; ++i) {
prefixSum[i + 1] = prefixSum[i] + diff[i];
}
- 构建前缀和数组
prefixSum,其中prefixSum[i]表示前i个元素的和。 - 例如:
diff[1..3]的和 =prefixSum[4] - prefixSum[1]。
4. 遍历所有子数组
for (int end = 0; end < n; ++end) {
for (int start = 0; start <= end; ++start) {
if (prefixSum[end + 1] <= prefixSum[start]) {
// 更新结果
}
}
}
- 外层循环遍历子数组的结束下标
end。 - 内层循环遍历起始下标
start。 - 通过前缀和判断子数组的和是否 ≤ 0。
5. 动态更新结果
if (currentLen > maxLen) {
maxLen = currentLen;
result.clear();
result.emplace_back(start, end);
} else if (currentLen == maxLen) {
result.emplace_back(start, end);
}
- 发现更长的子数组时清空旧结果,保存新区间。
- 遇到等长子数组时追加结果。
6. 排序与去重
sort(result.begin(), result.end(), [](const auto& a, const auto& b) {
if (a.first != b.first) return a.first < b.first;
return a.second < b.second;
});
set<pair<int, int>> uniqueSet(result.begin(), result.end());
- 按起始下标升序、结束下标升序排序。
- 使用
set去重,确保结果唯一。
7. 格式化输出
for (const auto& [s, e] : result) {
if (!first) cout << " ";
cout << s << "-" << e;
first = false;
}
- 将结果转换为
0-2格式输出,用空格分隔。
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
示例3输入:
3
1 1 1
输出:
NULL
综合分析
-
时间复杂度:O(n²)
- 双重循环遍历所有子数组,适用于数组长度较小(n ≤ 100)的场景。
-
空间复杂度:O(n²)
- 最坏情况下存储所有可能的子数组区间(例如所有元素相同)。
-
优势:
- 避免浮点运算:通过整数运算快速判断条件。
- 严格排序与去重:确保结果符合题目要求。
-
适用场景:
- 需要快速处理连续子数组的平均值问题,且输入规模较小的场景。
C
问题分析
我们需要找到数组中所有满足平均失败率 ≤ 给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
-
数学转换:
将每个元素减去容忍值,问题转化为寻找子数组的和 ≤ 0 的最长连续区间。 -
前缀和数组:
计算转换后的数组的前缀和,利用前缀和快速判断子数组的和是否满足条件。 -
暴力遍历:
遍历所有可能的子数组,记录满足条件的最长区间。 -
结果处理:
去重并排序结果,按指定格式输出。
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
int start;
int end;
} Interval;
int compare_intervals(const void *a, const void *b) {
Interval *ia = (Interval *)a;
Interval *ib = (Interval *)b;
if (ia->start != ib->start) return ia->start - ib->start;
return ia->end - ib->end;
}
int main() {
int minAverageLost;
char line[1000];
// 读取容忍值
fgets(line, sizeof(line), stdin);
minAverageLost = atoi(line);
// 读取数组行
fgets(line, sizeof(line), stdin);
int nums[100], n = 0;
char *token = strtok(line, " ");
while (token != NULL && n < 100) {
nums[n++] = atoi(token);
token = strtok(NULL, " ");
}
if (n == 0) {
printf("NULL\n");
return 0;
}
// 转换为差值数组(元素 - 容忍值)
int diff[100];
for (int i = 0; i < n; i++) {
diff[i] = nums[i] - minAverageLost;
}
// 计算前缀和数组
long long prefixSum[101] = {0};
for (int i = 0; i < n; i++) {
prefixSum[i + 1] = prefixSum[i] + diff[i];
}
// 收集所有满足条件的区间
Interval *intervals = NULL;
int interval_count = 0, interval_capacity = 0;
int max_len = 0;
for (int end = 0; end < n; end++) {
for (int start = 0; start <= end; start++) {
if (prefixSum[end + 1] <= prefixSum[start]) {
// 记录区间
if (interval_count >= interval_capacity) {
interval_capacity = (interval_capacity == 0) ? 1 : interval_capacity * 2;
intervals = realloc(intervals, interval_capacity * sizeof(Interval));
}
intervals[interval_count].start = start;
intervals[interval_count].end = end;
interval_count++;
// 更新最大长度
int current_len = end - start + 1;
if (current_len > max_len) max_len = current_len;
}
}
}
if (max_len == 0) {
printf("NULL\n");
free(intervals);
return 0;
}
// 筛选出最长区间
Interval *result = NULL;
int result_count = 0, result_capacity = 0;
for (int i = 0; i < interval_count; i++) {
int len = intervals[i].end - intervals[i].start + 1;
if (len == max_len) {
if (result_count >= result_capacity) {
result_capacity = (result_capacity == 0) ? 1 : result_capacity * 2;
result = realloc(result, result_capacity * sizeof(Interval));
}
result[result_count++] = intervals[i];
}
}
free(intervals);
// 排序和去重
qsort(result, result_count, sizeof(Interval), compare_intervals);
int unique_count = 0;
for (int i = 0; i < result_count; i++) {
if (i == 0 || (result[i].start != result[i-1].start || result[i].end != result[i-1].end)) {
result[unique_count++] = result[i];
}
}
// 输出结果
if (unique_count == 0) {
printf("NULL\n");
} else {
for (int i = 0; i < unique_count; i++) {
printf("%d-%d", result[i].start, result[i].end);
if (i != unique_count - 1) printf(" ");
}
printf("\n");
}
free(result);
return 0;
}
代码详细解析
-
输入处理:
- 使用
fgets读取输入行,strtok分割字符串并转换为整数数组。
- 使用
-
数学转换:
int diff[100]; for (int i = 0; i < n; i++) { diff[i] = nums[i] - minAverageLost; }- 将每个元素减去容忍值,生成新数组
diff。
- 将每个元素减去容忍值,生成新数组
-
前缀和计算:
long long prefixSum[101] = {0}; for (int i = 0; i < n; i++) { prefixSum[i + 1] = prefixSum[i] + diff[i]; }- 构建前缀和数组
prefixSum,用于快速计算子数组的和。
- 构建前缀和数组
-
遍历子数组:
for (int end = 0; end < n; end++) { for (int start = 0; start <= end; start++) { if (prefixSum[end + 1] <= prefixSum[start]) { // 记录区间 } } }- 双重循环遍历所有子数组,判断其和是否 ≤ 0。
-
动态数组管理:
- 使用
realloc动态扩展数组intervals和result,存储区间数据。
- 使用
-
筛选最长区间:
- 遍历所有区间,筛选出长度等于
max_len的区间。
- 遍历所有区间,筛选出长度等于
-
排序与去重:
qsort(result, result_count, sizeof(Interval), compare_intervals); for (int i = 0; i < result_count; i++) { if (i == 0 || (result[i].start != result[i-1].start || result[i].end != result[i-1].end)) { result[unique_count++] = result[i]; } }- 按起始下标排序,遍历去重相邻重复项。
-
输出结果:
- 按格式输出所有唯一的最长区间。
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
示例3输入:
3
1 1 1
输出:
NULL
综合分析
-
时间复杂度:O(n²)
- 双重循环遍历所有子数组,适用于数组长度较小(n ≤ 100)的场景。
-
空间复杂度:O(n²)
- 最坏情况下存储所有可能的子数组区间。
-
优势:
- 避免浮点运算:通过整数运算快速判断条件。
- 严格排序与去重:确保结果符合题目要求。
-
适用场景:
- 需要快速处理连续子数组的平均值问题,且输入规模较小的场景。
GO
问题分析
我们需要找到数组中所有满足平均失败率 ≤ 给定值的最长连续子数组,并输出这些子数组的起始和结束下标。如果有多个相同长度的子数组,按起始下标升序排列。
解题思路
-
数学转换:
将每个元素减去容忍值,问题转化为寻找子数组的和 ≤ 0 的最长连续区间。 -
前缀和数组:
计算转换后的数组的前缀和,快速判断子数组的和是否满足条件。 -
暴力遍历:
遍历所有可能的子数组,记录满足条件的最长区间。 -
结果处理:
筛选最长区间,排序并去重后输出。
代码实现
package main
import (
"bufio"
"fmt"
"os"
"sort"
"strconv"
"strings"
)
type Interval struct {
start, end int
}
func main() {
scanner := bufio.NewScanner(os.Stdin)
// 读取输入参数
scanner.Scan()
minAverageLost, _ := strconv.Atoi(scanner.Text())
scanner.Scan()
numsLine := scanner.Text()
numsStr := strings.Fields(numsLine)
nums := make([]int, len(numsStr))
for i, s := range numsStr {
nums[i], _ = strconv.Atoi(s)
}
// 转换数组为差值数组(元素 - 容忍值)
diff := make([]int, len(nums))
for i, num := range nums {
diff[i] = num - minAverageLost
}
// 计算前缀和数组
prefix := make([]int, len(diff)+1)
prefix[0] = 0
for i := 0; i < len(diff); i++ {
prefix[i+1] = prefix[i] + diff[i]
}
// 收集所有满足条件的区间
var allIntervals []Interval
for end := 0; end < len(diff); end++ {
for start := 0; start <= end; start++ {
if prefix[end+1] <= prefix[start] {
allIntervals = append(allIntervals, Interval{start, end})
}
}
}
if len(allIntervals) == 0 {
fmt.Println("NULL")
return
}
// 找到最大长度
maxLen := 0
for _, interval := range allIntervals {
length := interval.end - interval.start + 1
if length > maxLen {
maxLen = length
}
}
// 筛选出最长区间的候选
var candidates []Interval
for _, interval := range allIntervals {
if interval.end-interval.start+1 == maxLen {
candidates = append(candidates, interval)
}
}
// 排序候选区间(按起始下标升序,结束下标升序)
sort.Slice(candidates, func(i, j int) bool {
if candidates[i].start != candidates[j].start {
return candidates[i].start < candidates[j].start
}
return candidates[i].end < candidates[j].end
})
// 去重(跳过相邻重复项)
var results []Interval
for i, interval := range candidates {
if i == 0 || (interval.start != candidates[i-1].start || interval.end != candidates[i-1].end) {
results = append(results, interval)
}
}
// 输出结果
if len(results) == 0 {
fmt.Println("NULL")
} else {
output := make([]string, len(results))
for i, interval := range results {
output[i] = fmt.Sprintf("%d-%d", interval.start, interval.end)
}
fmt.Println(strings.Join(output, " "))
}
}
代码详细解析
-
输入处理:
- 使用
bufio.Scanner读取输入,转换第一行为minAverageLost,第二行为整数数组。
- 使用
-
数学转换:
diff := make([]int, len(nums)) for i, num := range nums { diff[i] = num - minAverageLost }- 将每个元素减去容忍值,生成新数组
diff。问题转化为:寻找diff中和 ≤ 0 的子数组。
- 将每个元素减去容忍值,生成新数组
-
前缀和计算:
prefix := make([]int, len(diff)+1) for i := 0; i < len(diff); i++ { prefix[i+1] = prefix[i] + diff[i] }- 构建前缀和数组
prefix,prefix[i]表示前i个元素的和。
- 构建前缀和数组
-
收集所有符合条件的区间:
for end := 0; end < len(diff); end++ { for start := 0; start <= end; start++ { if prefix[end+1] <= prefix[start] { allIntervals = append(allIntervals, Interval{start, end}) } } }- 双重循环遍历所有子数组,判断其和是否 ≤ 0,记录符合条件的区间。
-
筛选最长区间:
- 遍历
allIntervals找到最大长度maxLen。 - 筛选出所有长度为
maxLen的区间存入candidates。
- 遍历
-
排序与去重:
sort.Slice(candidates, ...) // 按起始下标升序排序 for i, interval := range candidates { if i == 0 || ... { // 去重相邻重复项 results = append(results, interval) } }- 排序后遍历跳过重复项,确保结果唯一。
-
输出结果:
- 将结果格式化为字符串并输出,若无有效结果输出
NULL。
- 将结果格式化为字符串并输出,若无有效结果输出
示例测试
示例1输入:
1
0 1 2 3 4
输出:
0-2
示例2输入:
2
0 0 100 2 2 99 0 2
输出:
0-1 3-4 6-7
示例3输入:
3
1 1 1
输出:
NULL
综合分析
-
时间复杂度:O(n²)
- 双重循环遍历所有子数组,适用于数组长度较小(n ≤ 100)的场景。
-
空间复杂度:O(n²)
- 最坏情况下存储所有可能的子数组区间(如所有元素相同)。
-
优势:
- 避免浮点运算:通过整数运算快速判断条件。
- 严格顺序处理:确保结果按起始下标排序。
-
适用场景:
- 需要快速处理连续子数组的平均值问题,且输入规模较小的场景。
更多内容:
https://www.kdocs.cn/l/cvk0eoGYucWA
本文发表于【纪元A梦】,关注我,获取更多实用教程/资源!