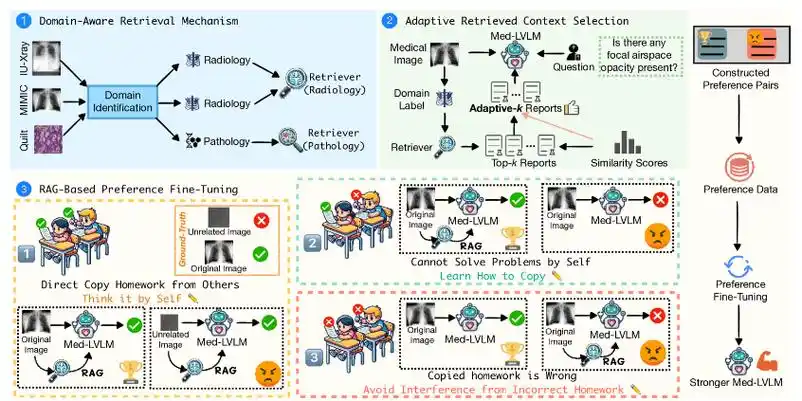
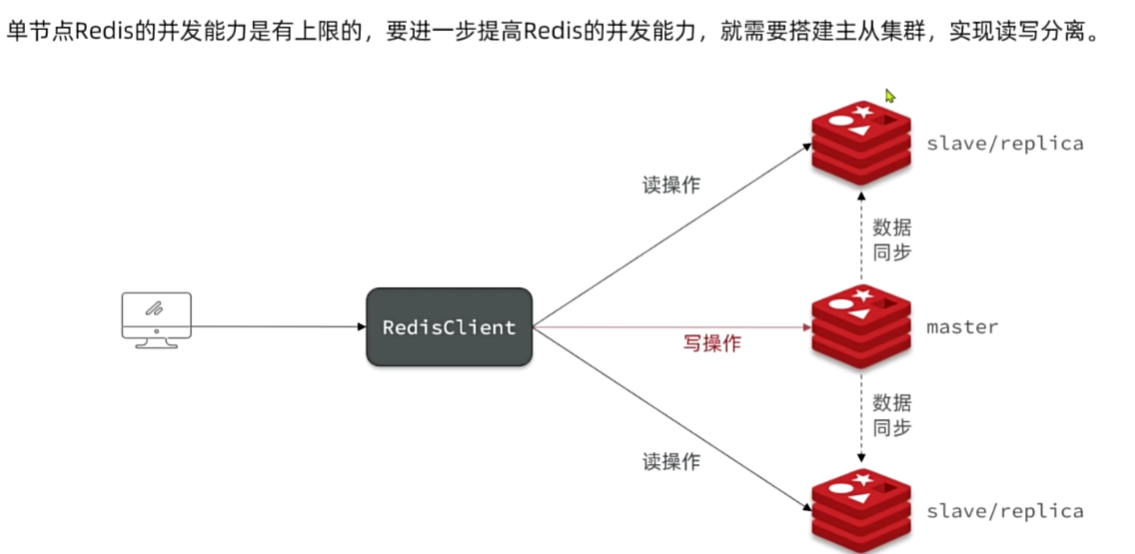
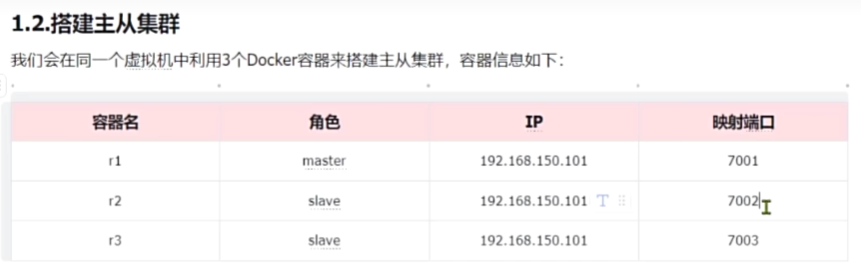
redis主从
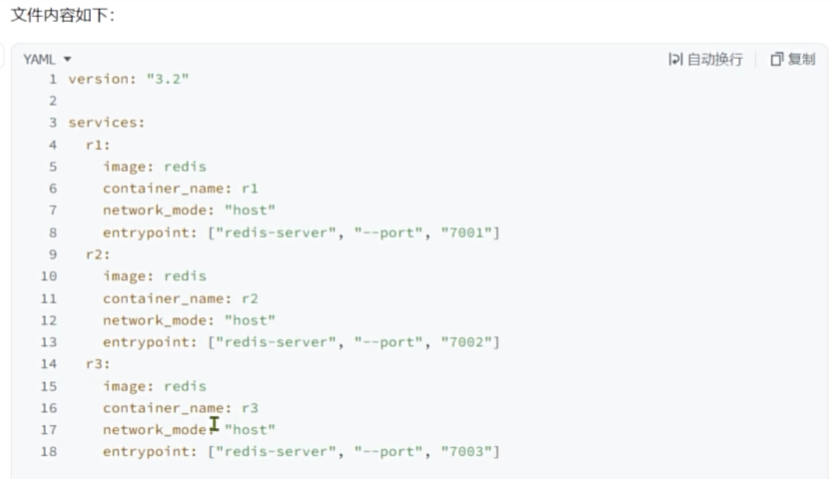
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003"]
docker load -i redis.tar
docker compose up -d
docker compose ps
ps -ef | grep redis
建立主从集群
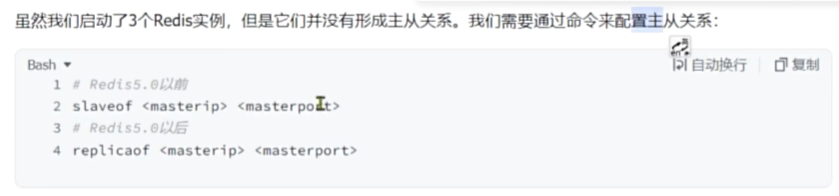
默认所有节点都是主节点
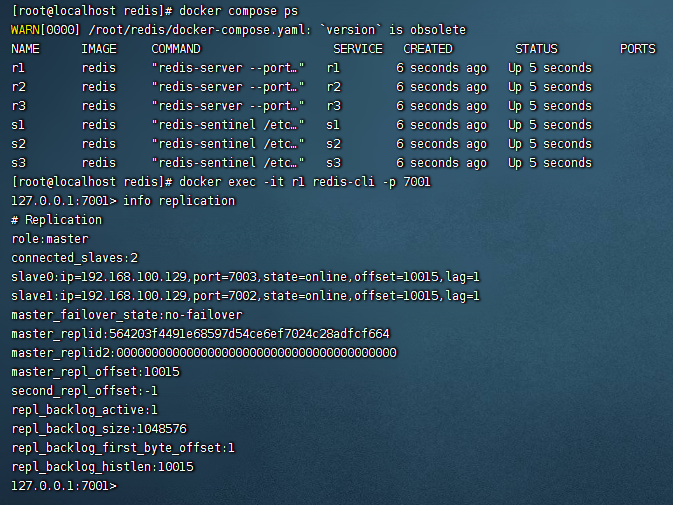
docker exec -it r1 redis-cli -p 7001
info replication
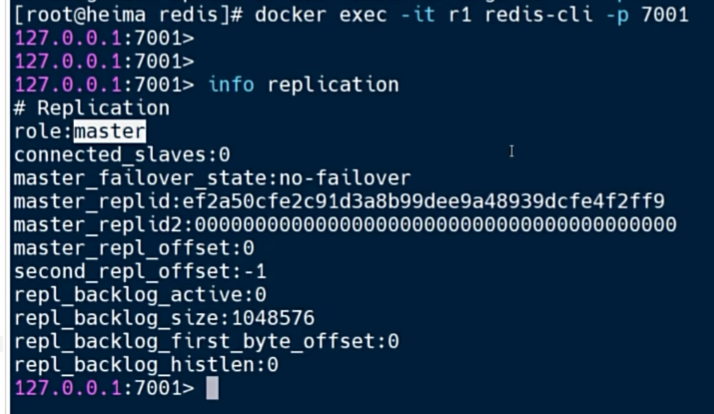
修改r2为从
docker exec -it r2 redis-cli -p 7002
slaveof 192.168.100.129 7001
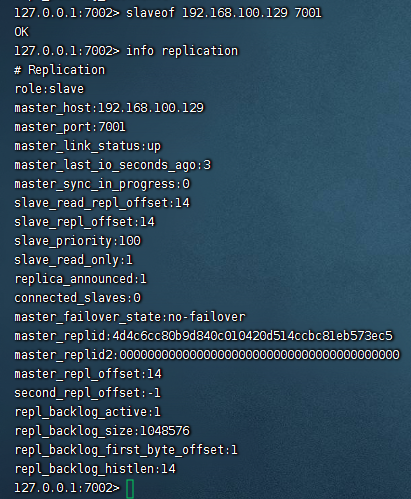
修改r3为从
docker exec -it r3 redis-cli -p 7003
slaveof 192.168.100.129 7001
可以看到r1显示了2个从节点,主从关系建立完毕
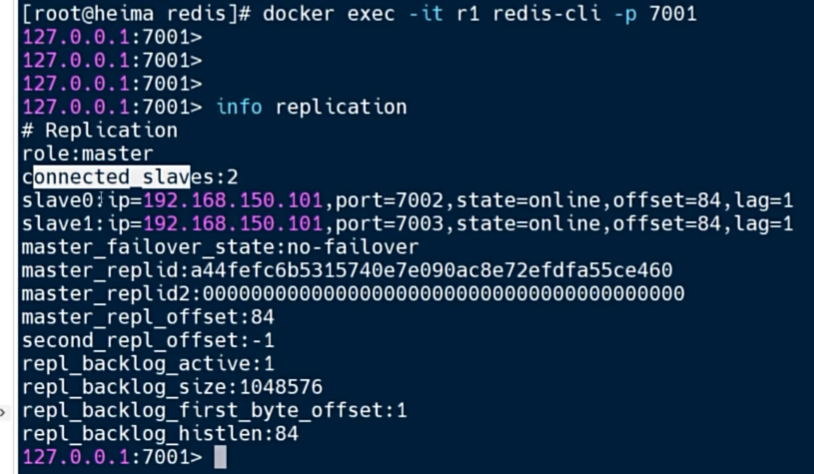
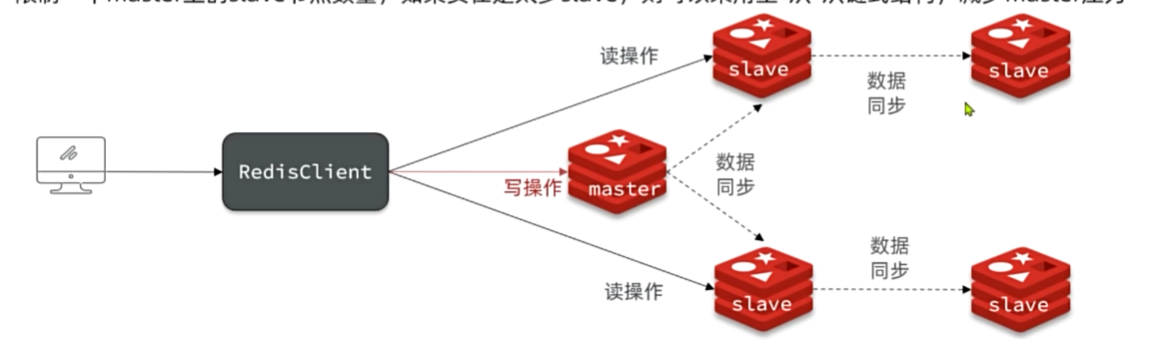
主从同步原理
replicationID:每一个master节点都有自己的唯一id,简称replid

主从集群优化
可以从以下几个方面来优化Redis主从就集群:
在master中配置repl-diskless-sync yes,启用无磁盘复制,避免全量同步时的磁盘IO。
Redis.单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
适当提高repl baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
限制一个master.上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
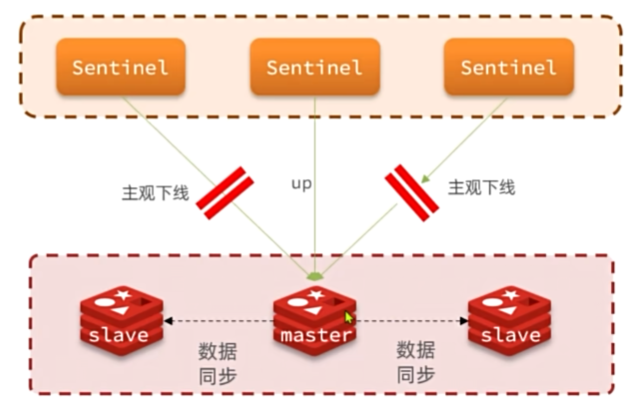
哨兵原理
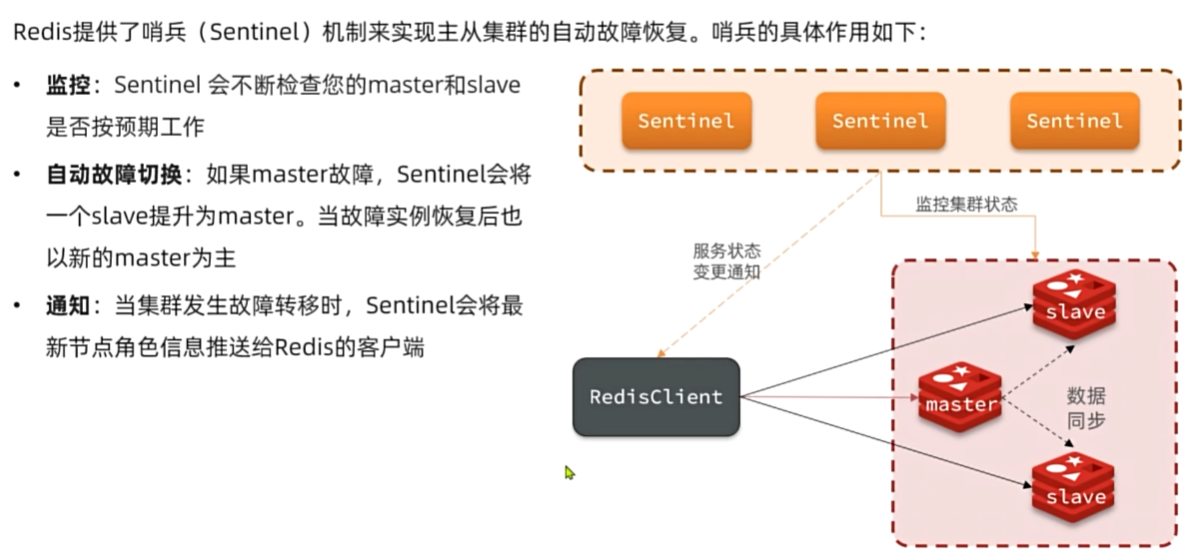
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超
过Sentinel3实例数量的一半。
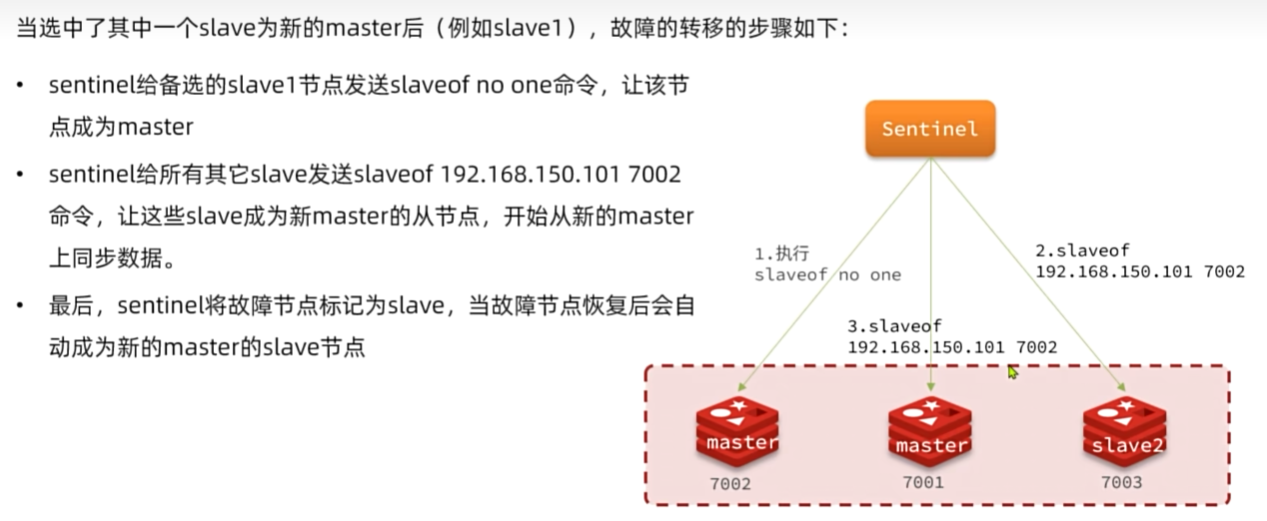
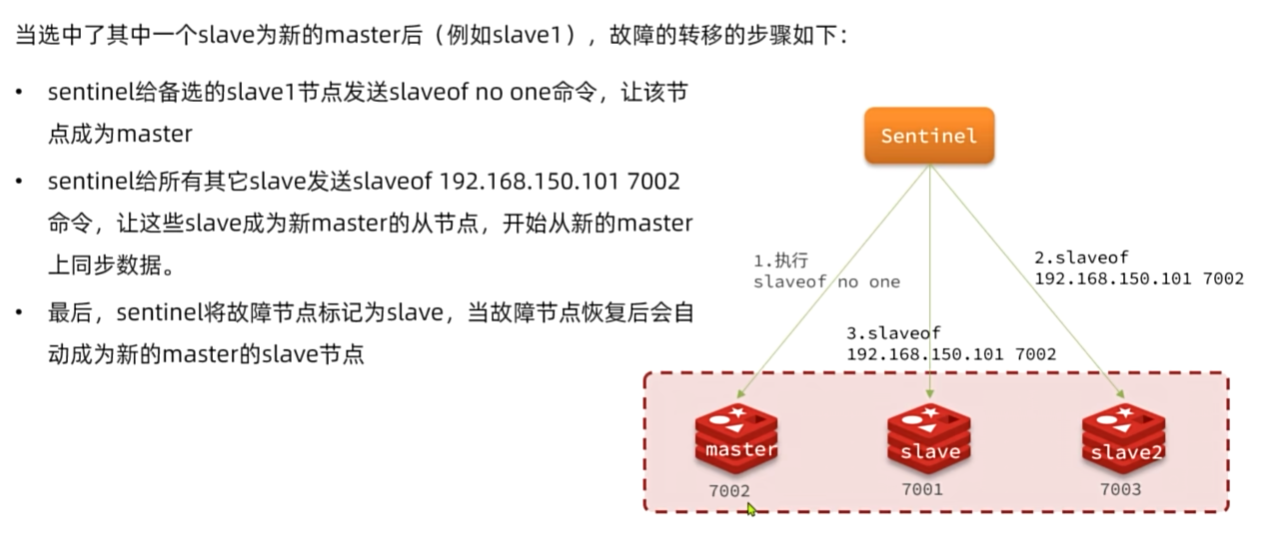
选举新的master
一旦发现masteri故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds*10)则会排除该
slave节点
然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
最后是判断slave节点的运行id大小,越小优先级越高。
如何实现故障转移
搭建哨兵集群
首先,我们停掉之前的redis集群
docker compose down
sentinel.conf
sentinel announce-ip "192.168.100.129"
sentinel monitor hmaster 192.168.100.129 7001 2
sentinel down-after-milliseconds hmaster 5000
sentinel failover-timeout hmaster 60000

我们在虚拟机的/root/redis目录下新建3个文件夹:s1、s2、s3:
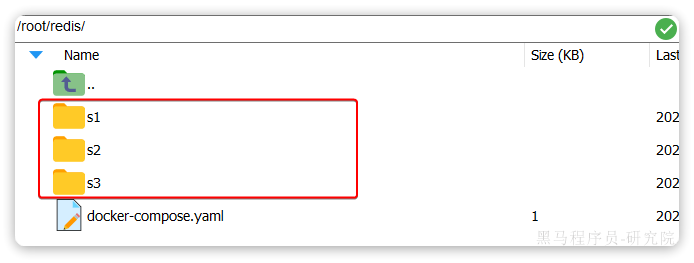
将课前资料提供的sentinel.conf文件分别拷贝一份到3个文件夹中。
接着修改docker-compose.yaml文件,内容如下:
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002", "--slaveof", "192.168.100.129", "7001"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003", "--slaveof", "192.168.100.129", "7001"]
s1:
image: redis
container_name: s1
volumes:
- /root/redis/s1:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27001"]
s2:
image: redis
container_name: s2
volumes:
- /root/redis/s2:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27002"]
s3:
image: redis
container_name: s3
volumes:
- /root/redis/s3:/etc/redis
network_mode: "host"
entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27003"]
直接运行命令,启动集群:
docker compose up -d
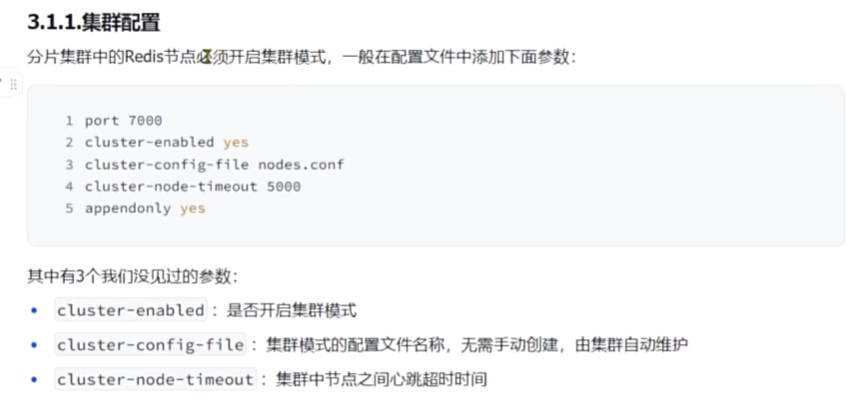
Redis分片
搭建分片集群
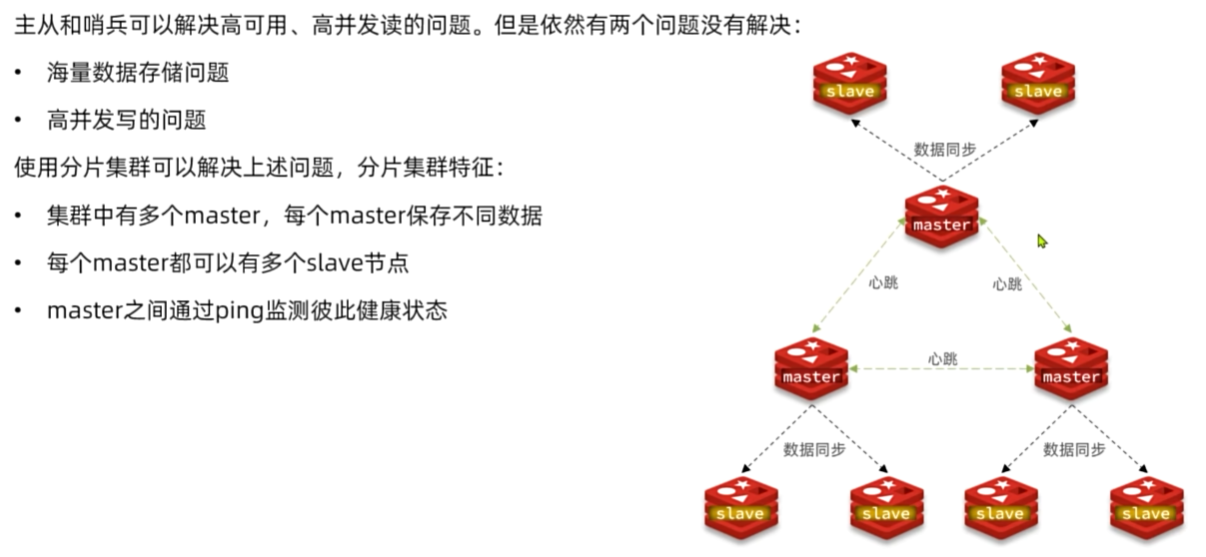
Redis分片集群最少也需要3个master节点,由于我们的机器性能有限,我们只给每个master配置1个slave,形成最小的分片集群:
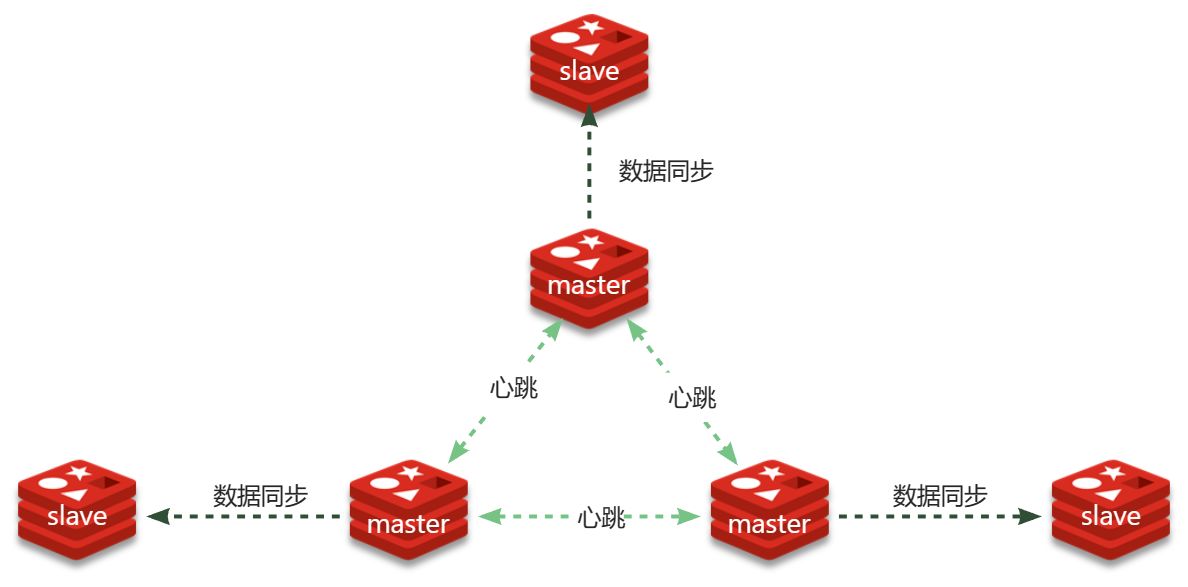
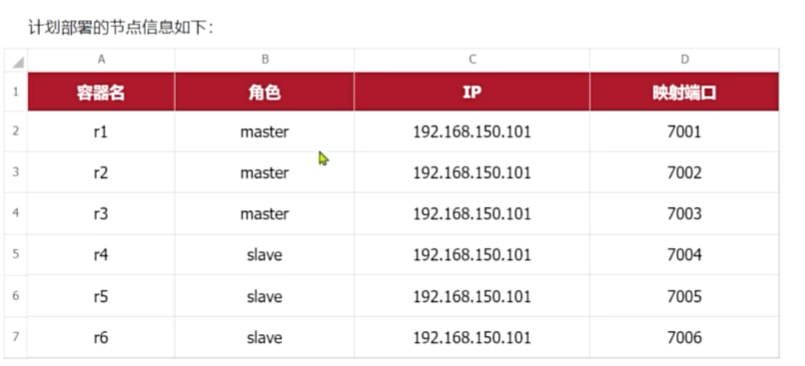
一般搭建部署集群肯定是给每个节点都配置上述参数,不过考虑到我们计划用docker-compose部署,因此可以直接在启动命令中指定参数,偷个懒。
在虚拟机的/root目录下新建一个redis-cluster目录,然后在其中新建一个docker-compose.yaml文件,内容如下:
version: "3.2"
services:
r1:
image: redis
container_name: r1
network_mode: "host"
entrypoint: ["redis-server", "--port", "7001", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r2:
image: redis
container_name: r2
network_mode: "host"
entrypoint: ["redis-server", "--port", "7002", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r3:
image: redis
container_name: r3
network_mode: "host"
entrypoint: ["redis-server", "--port", "7003", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r4:
image: redis
container_name: r4
network_mode: "host"
entrypoint: ["redis-server", "--port", "7004", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r5:
image: redis
container_name: r5
network_mode: "host"
entrypoint: ["redis-server", "--port", "7005", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
r6:
image: redis
container_name: r6
network_mode: "host"
entrypoint: ["redis-server", "--port", "7006", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]
注意:使用Docker部署Redis集群,network模式必须采用host
进入/root/redis-cluster目录,使用命令启动redis:
docker-compose up -d
启动成功,可以通过命令查看启动进程:
ps -ef | grep redis
接下来,我们使用命令创建集群:
# 进入任意节点容器
docker exec -it r1 bash
# 然后,执行命令
redis-cli --cluster create --cluster-replicas 1 \
192.168.100.129:7001 192.168.100.129:7002 192.168.100.129:7003 \
192.168.100.129:7004 192.168.100.129:7005 192.168.100.129:7006
命令说明:
redis-cli --cluster:代表集群操作命令create:代表是创建集群--cluster-replicas 1:指定集群中每个master的副本个数为1- 此时
节点总数 ÷ (replicas + 1)得到的就是master的数量n。因此节点列表中的前n个节点就是master,其它节点都是slave节点,随机分配到不同master
- 此时
输入命令后控制台会弹出下面的信息:
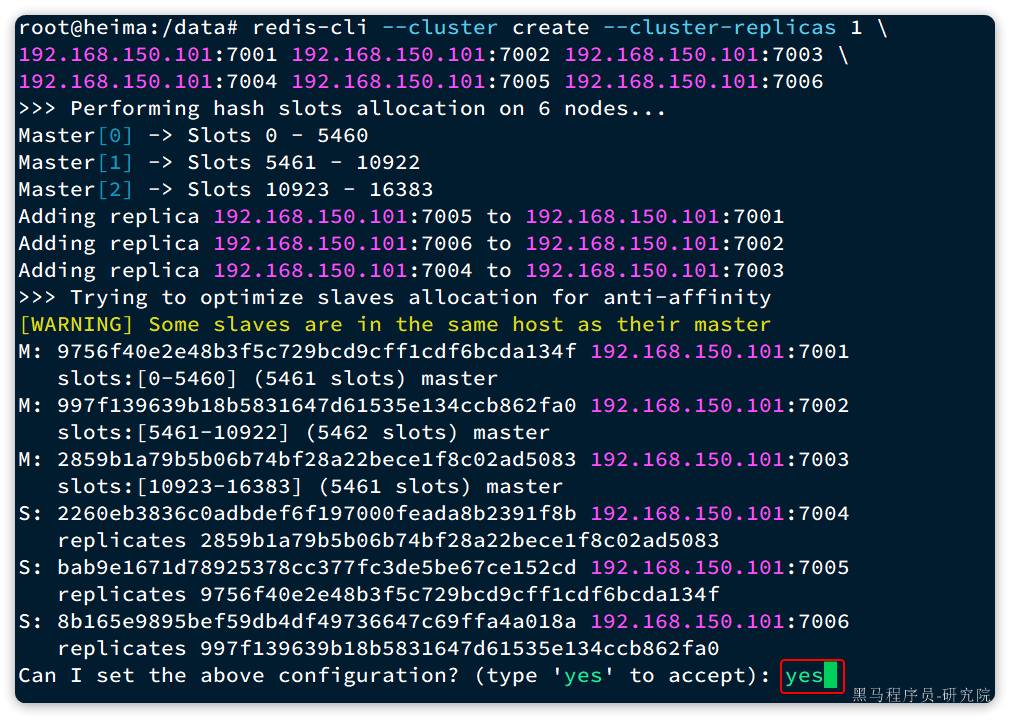
这里展示了集群中master与slave节点分配情况,并询问你是否同意。节点信息如下:
7001是master,节点id后6位是da134f7002是master,节点id后6位是862fa07003是master,节点id后6位是ad50837004是slave,节点id后6位是391f8b,认ad5083(7003)为master7005是slave,节点id后6位是e152cd,认da134f(7001)为master7006是slave,节点id后6位是4a018a,认862fa0(7002)为master
输入yes然后回车。会发现集群开始创建,并输出下列信息:
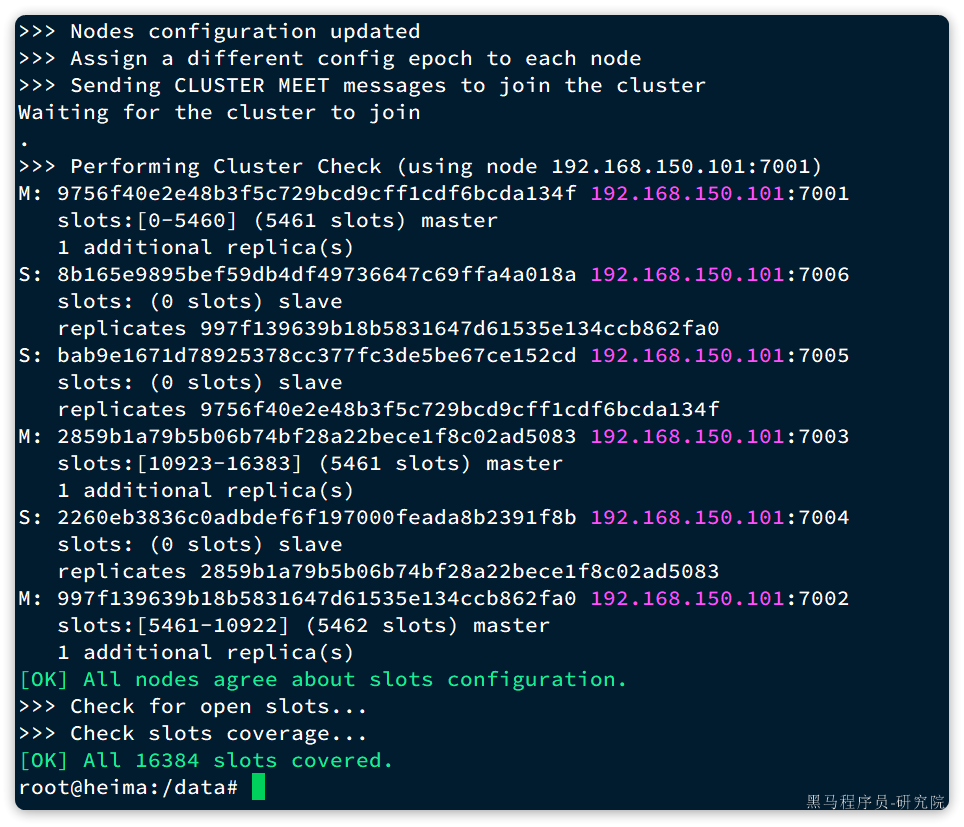
接着,我们可以通过命令查看集群状态:
redis-cli -p 7001 cluster nodes
结果:

散列插槽
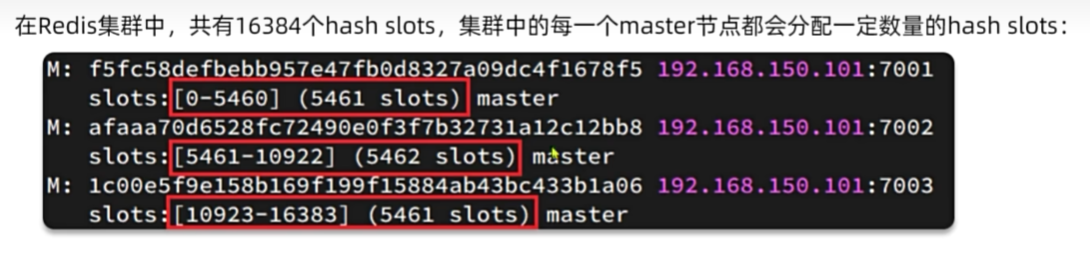
Redis数据不是与节点绑定,而是与插槽slot绑定。当我们读写数据时,Redis基于CRC16算法对key做hash运算,得
到的结果与16384取余,就计算出了这个key的slot值。然后到slot所在的Redis节点执行读写操作。
redis在计算key的hash值是不一定是根据整个key计算,分两种情况:
当key中包含{}时,根据{}之间的字符串计算hash slot
当key中不包含{}时,则根据整个key字符串计算hash slot
例如:key是num,那么就根据num计算,如果是{itcast)num,则根据itcast计算。
例如:
- key是
user,则根据user来计算hash slot - key是
user:{age},则根据age来计算hash slot
我们来测试一下,先于7001建立连接:
# 进入容器
docker exec -it r1 bash
# 进入redis-cli
redis-cli -p 7001
# 测试
set user jack
会发现报错了:
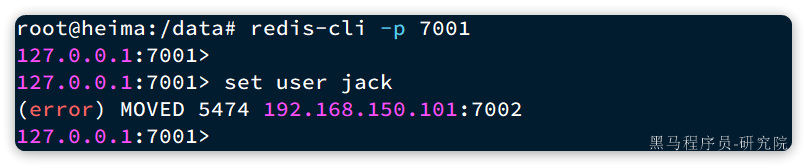
提示我们MOVED 5474,其实就是经过计算,得出user这个key的hash slot 是5474,而5474是在7002节点,不能在7001上写入!!
说好的任意节点都可以读写呢?
这是因为我们连接的方式有问题,连接集群时,要加-c参数:
# 通过7001连接集群
redis-cli -c -p 7001
# 存入数据
set user jack
结果如下:
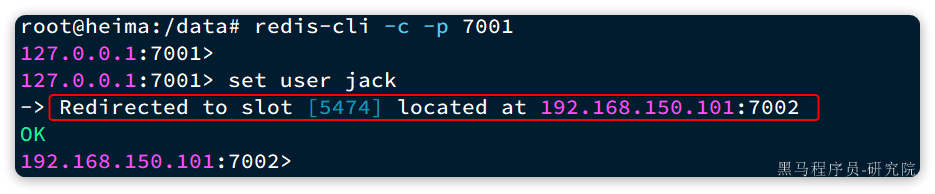
可以看到,客户端自动跳转到了5474这个slot所在的7002节点。
现在,我们添加一个新的key,这次加上{}:
# 试一下key中带{}
set user:{age} 21
# 再试一下key中不带{}
set age 20
结果如下:
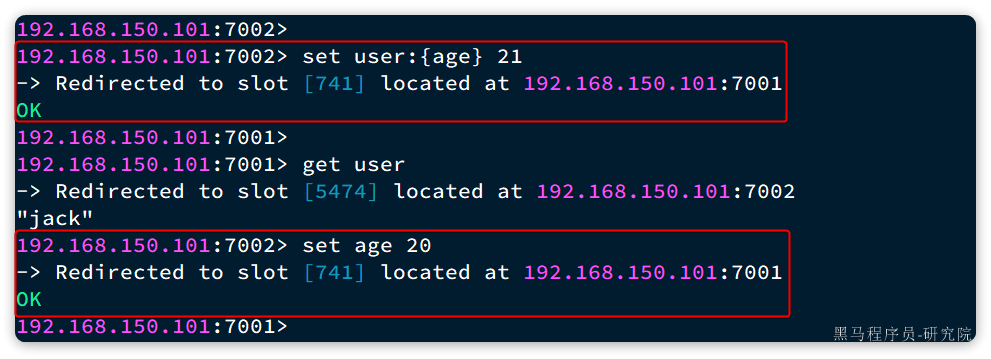
可以看到user:{age}和age计算出的slot都是741
# 正确操作
get user:{age} # 返回 "21"
# 错误操作
get user # 键名不匹配,返回 nil
get age # 键名不匹配,返回 nil
get user:age # 键名不匹配(无花括号),返回 nil
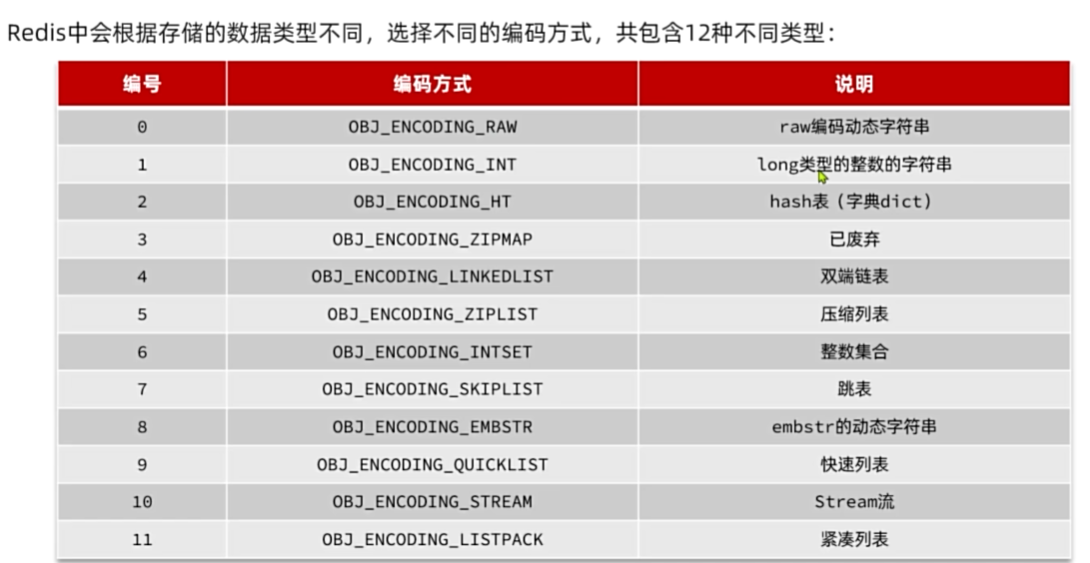
Redis数据结构
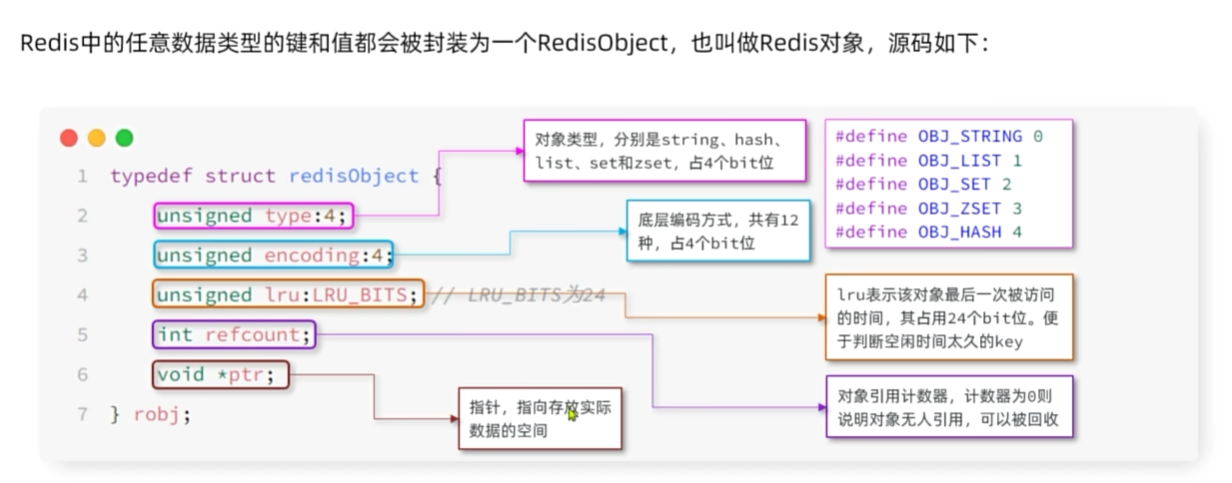
RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis:对象,源码如下:

SkipList(跳表)
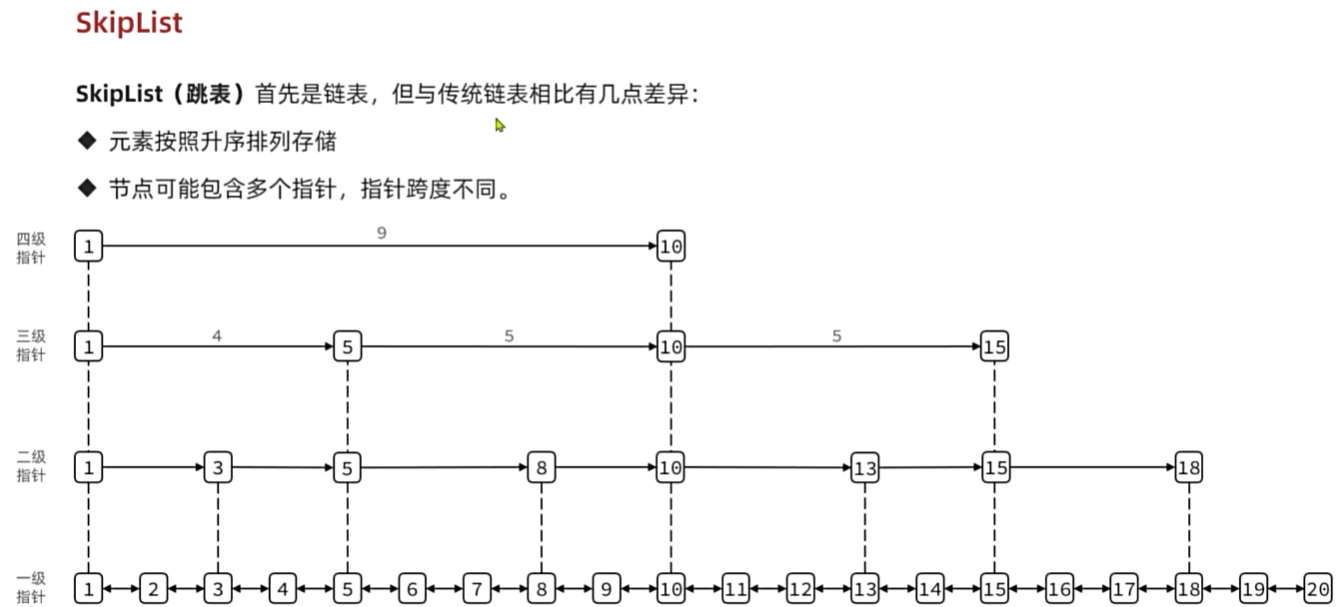
SkipList的特点:
跳跃表是一个有序的双向链表
每个节点都可以包含多层指针,层数是1到32之间的随机数
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
增删改查效率与红黑树基本一致,实现却更简单。但空间复杂度更高
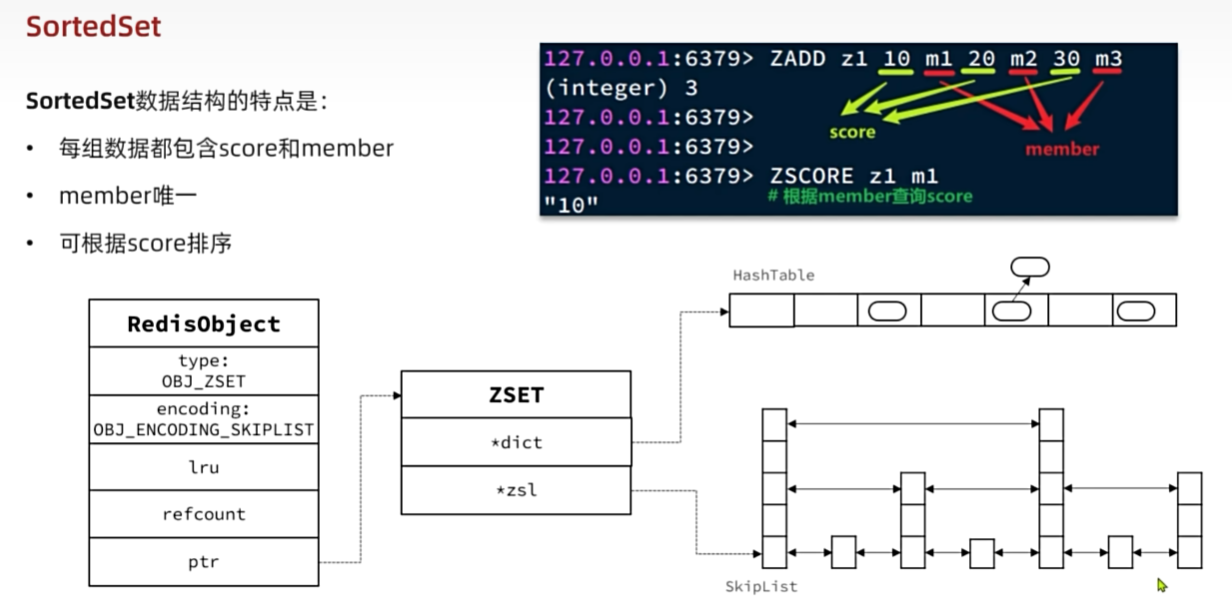
SortedSet
Redis内存回收
过期key处理

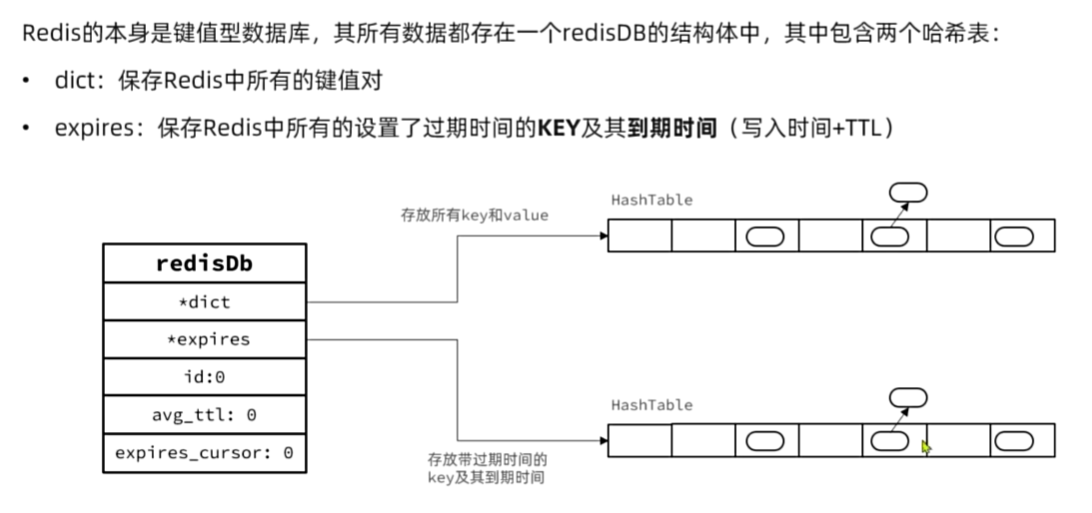
Redis并不会实时监测key的过期时间,在key过期后立刻删除。而是采用两种延迟删除的策略:
惰性删除:当有命令需要操作一个key的时候,检查该ky的存活时间,如果已经过期才执行删除。
周期删除:通过一个定时任务,周期性的抽样部分有TTL的ky,如果过期则执行删除。
周期删除的定时任务执行周期有两种:
SLOW模式:默认执行频率为每秒10次,但每次执行时长不能超过25ms,受server.hz参数影响。
FAST模式:频率不固定,跟随Redis内部IO事件循环执行。两次任务之间间隔不低于2ms,执行时长不超过1ms
内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的阈值时,Redis:主动挑选部分key删除以释放更多内存的流程。
Redis会在每次处理客户端命令时都会对内存使用情况做判断,如果必要则执行内存淘汰。内存淘汰的策略有:
◆noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。,
◆volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
◆allkeys-random:对全体key,随机进行淘汰。也就是直接从db->dict中随机挑选
◆volatile-random:对设置了TTL的key,随机进行淘汰。也就是从db->expires中随机挑选。
◆allkeys-lru:对全体key,基于LRU算法进行淘汰
◆volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
◆allkeys-lfu:对全体key,基于LFU算法进行淘汰
◆volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰比较容易混淆的有两个:
LRU(Least Recently Used),最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。


缓存一致性

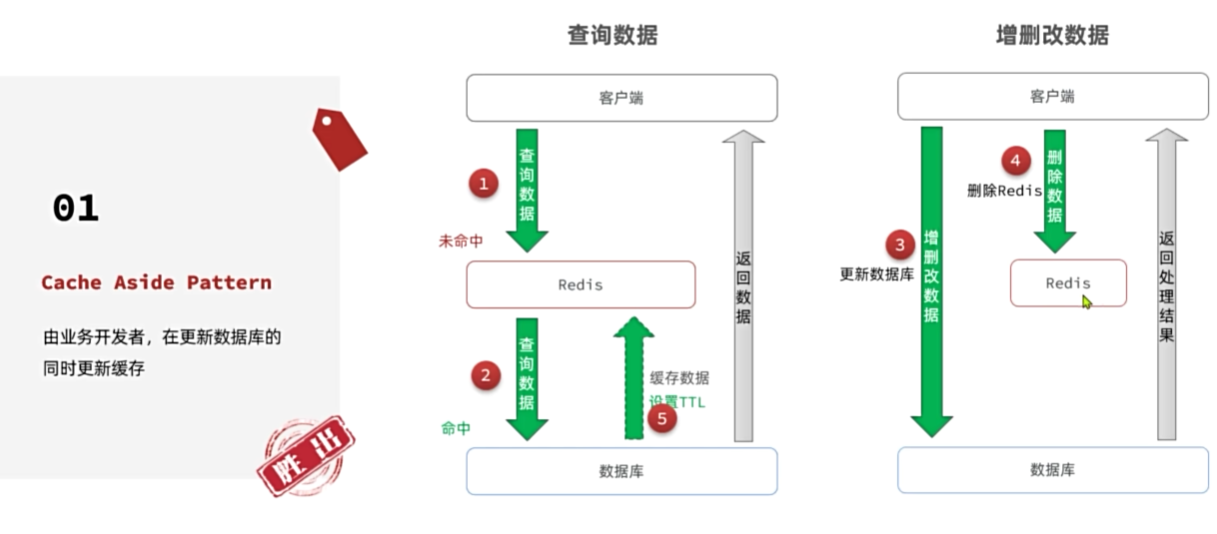
缓存一致性策略的最佳实践方案:
1.低一致性需求:使用Redis的key过期清理方案
2.高一致性需求:主动更新,并以超时剔除作为兜底方案
◆读操作:
缓存命中则直接返回
缓存未命中则查询数据库,并写入缓存,设定超时时间
◆写操作:
先写数据库,然后再删除缓存
要确保数据库与缓存操作的原子性
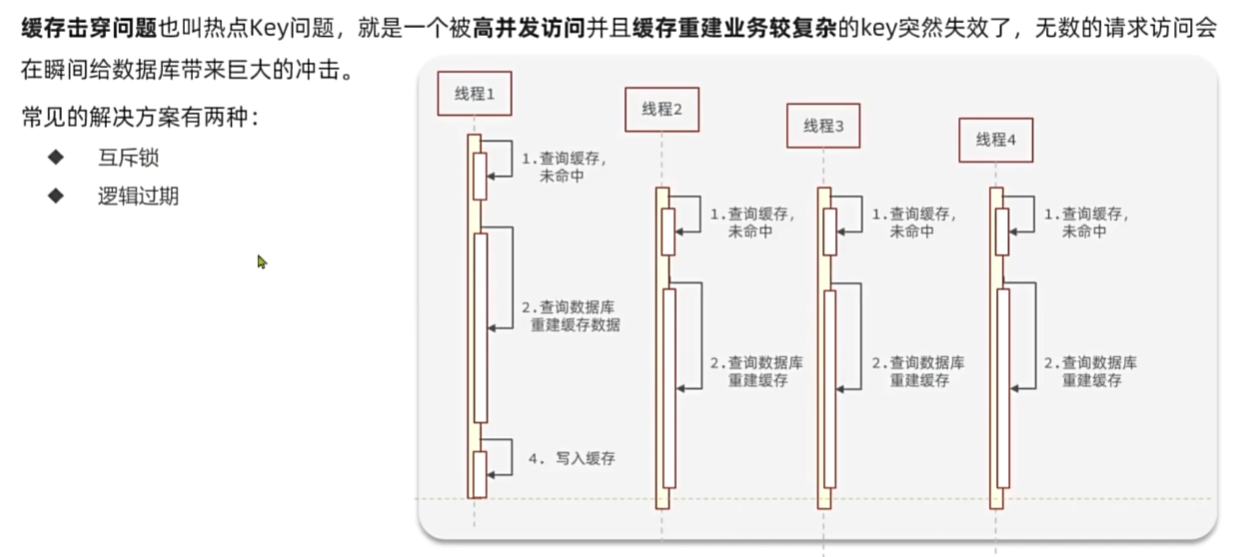
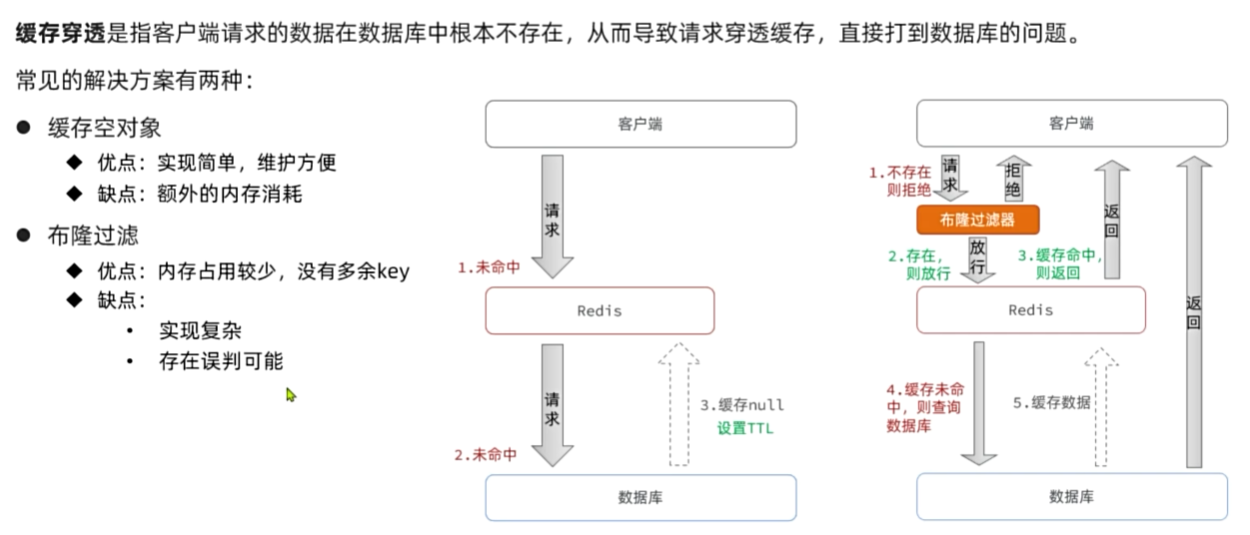
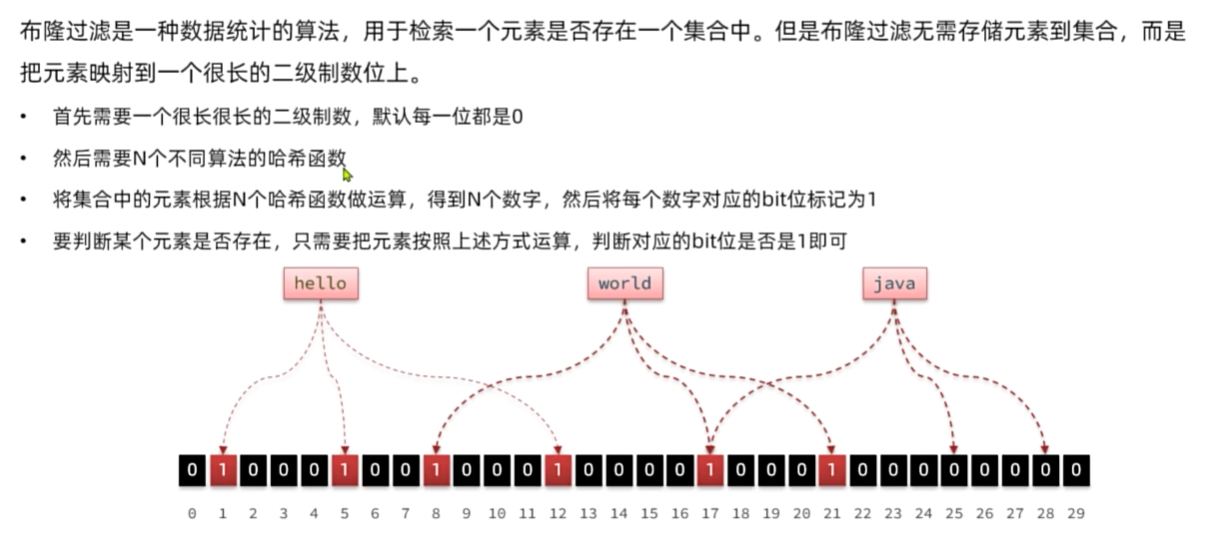
缓存穿透
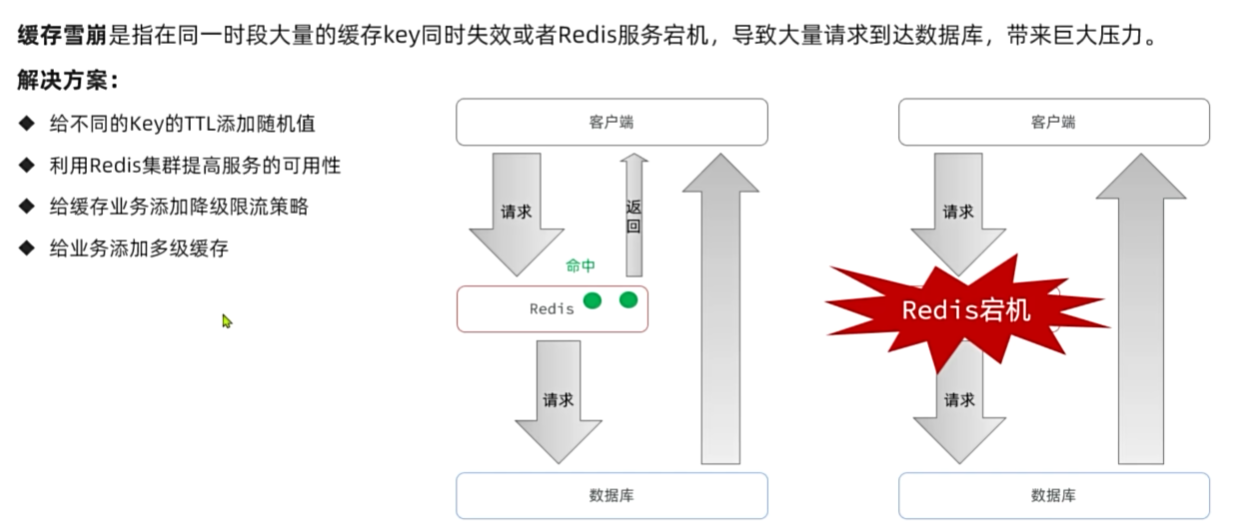
缓存雪崩
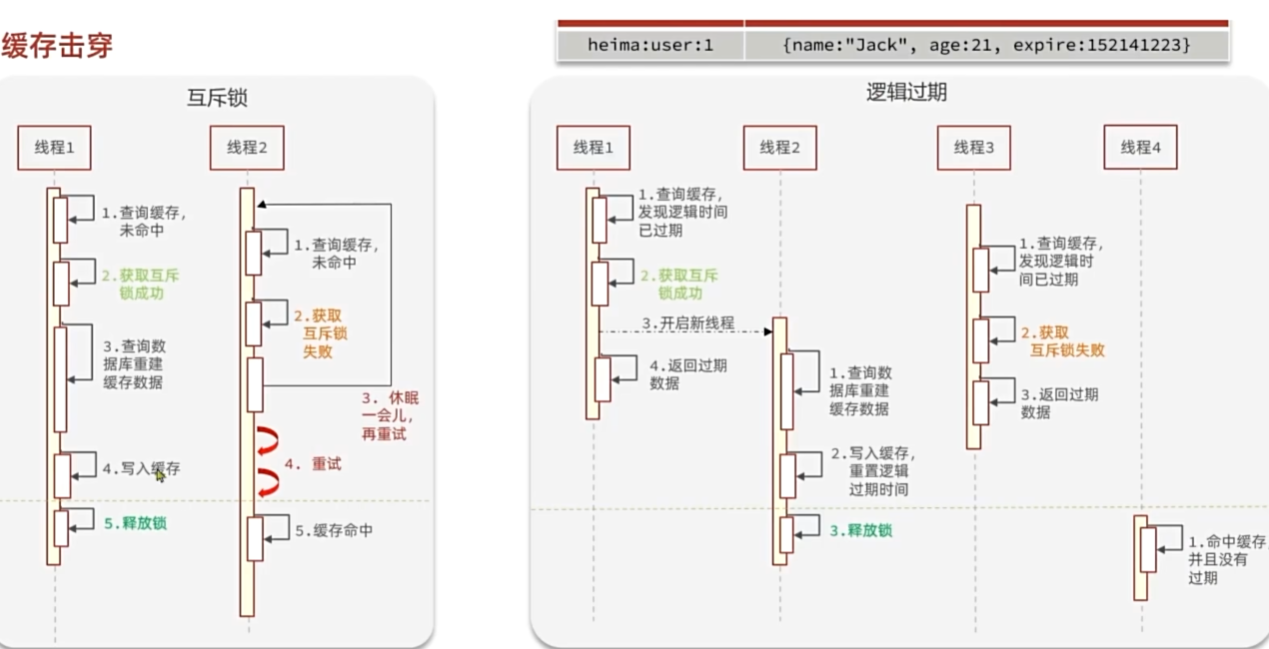
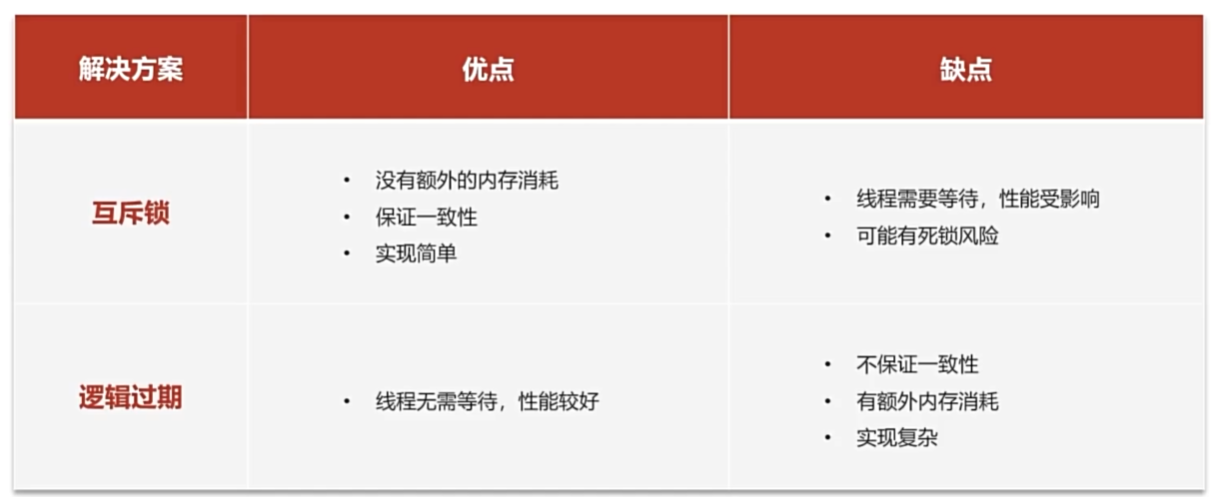
缓存击穿