Inverse Reinforcement Learning (IRL) 详解
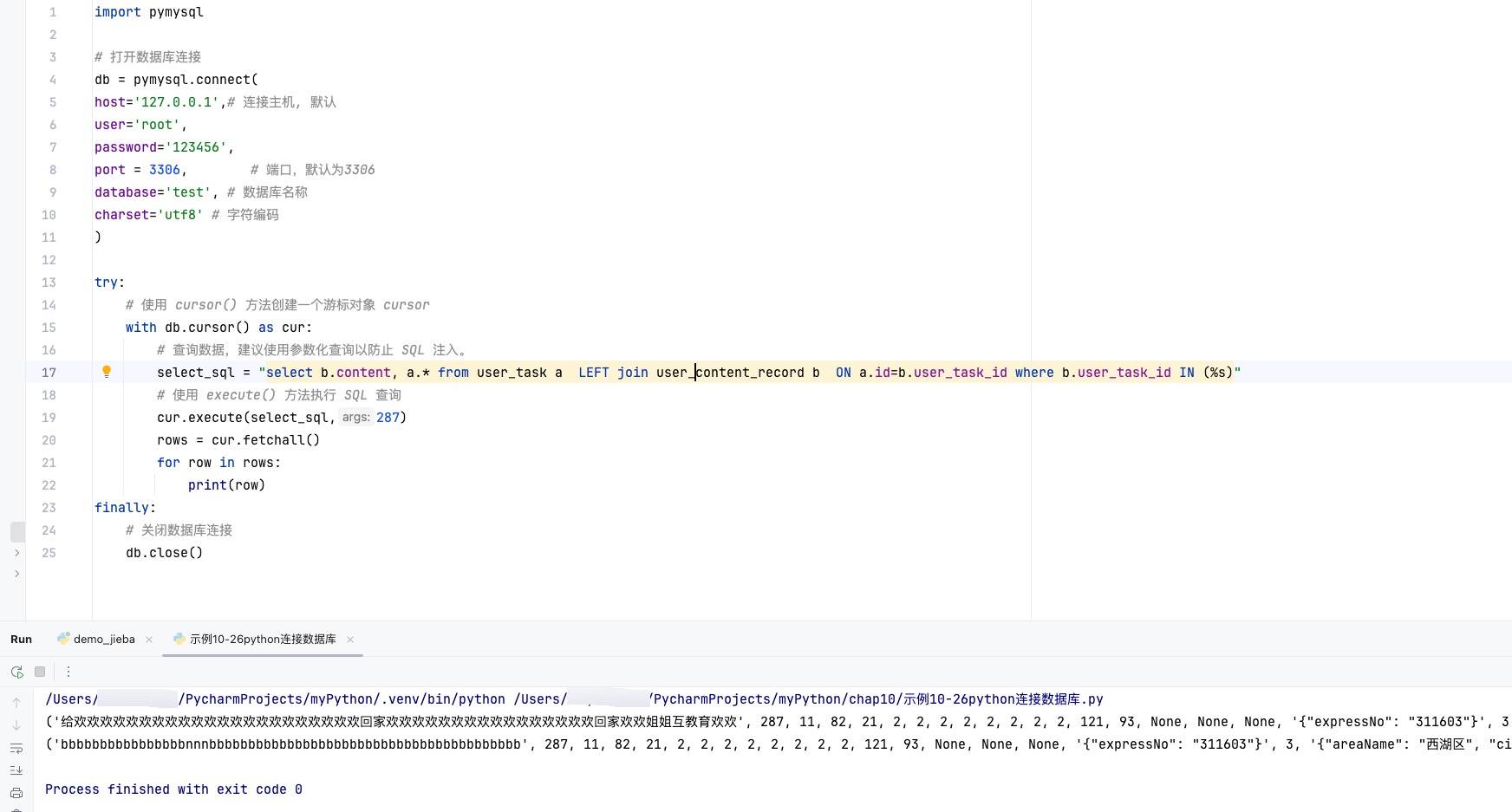
什么是 Inverse Reinforcement Learning?
在传统的强化学习 (Reinforcement Learning, RL) 中,奖励函数是已知的,智能体的任务是学习一个策略来最大化奖励
而在逆向强化学习 (Inverse Reinforcement Learning, IRL) 中,情况相反:
- 我们不知道奖励函数
缺失的 - 但是我们有专家的示范轨迹(比如专家怎么开车、怎么走路): τ = ( s 0 , a 0 , s 1 , a 1 , … , s T ) \tau = (s_0, a_0, s_1, a_1, \dots, s_T) τ=(s0,a0,s1,a1,…,sT)
- 目标是:推断出奖励函数,使得专家行为在该奖励下是最优的
简单来说,IRL 是"从专家行为中推断动机"
- Initialize an actor
- In each iteration
- The
actorinteracts with the environrment to obtain some trajectories- Define a reward functlon, which makes thetrajectories of the teacher better than the
actor- The
actorlearns to maximize the reward based on the new reward function- Output the reward function and the
actorlearned from the reward function
IRL算法之 GAIL 算法详解
GAIL(生成对抗模仿学习)结合了:生成对抗网络 GAN(Generator 对抗 Discriminator)和 强化学习 Policy Gradient(策略梯度)
- 让智能体学会产生像专家一样的轨迹,但不直接学习奖励函数,只通过模仿专家行为来训练策略
判别器 (Discriminator) :试图区分 “专家轨迹” 和 “生成器轨迹”
判别器的目标是最大化对数似然:判别器希望对于专家数据 expert 输出接近 1,对于生成数据 policy 输出接近 0
max
D
E
expert
[
log
D
(
s
,
a
)
]
+
E
policy
[
log
(
1
−
D
(
s
,
a
)
)
]
\max_D \mathbb{E}_{\text{expert}} [\log D(s, a)] + \mathbb{E}_{\text{policy}} [\log (1 - D(s, a))]
DmaxEexpert[logD(s,a)]+Epolicy[log(1−D(s,a))]
生成器(策略网络 Policy):试图“欺骗”判别器,让判别器以为它生成的轨迹是专家生成的
生成器的目标是最小化:
min
π
E
τ
∼
π
[
log
(
1
−
D
(
s
,
a
)
)
]
\min_{\pi} \mathbb{E}_{\tau \sim \pi} [\log (1 - D(s, a))]
πminEτ∼π[log(1−D(s,a))]
这其实可以等价强化学习问题,奖励信号变成了:
r ( s , a ) = − log ( 1 − D ( s , a ) ) r(s, a) = - \log (1 - D(s, a)) r(s,a)=−log(1−D(s,a))
- 这样,跟标准的 policy gradient 非常类似,只不过奖励是来自判别器
GAIL 简单代码示例
import gym
from stable_baselines3 import PPO
from imitation.algorithms.adversarial import GAIL
from imitation.data.types import TrajectoryWithRew
from imitation.data import rollout
# 1. 创建环境
env = gym.make("CartPole-v1")
# 2. 加载或创建专家模型
expert = PPO("MlpPolicy", env, verbose=0)
expert.learn(10000)
# 3. 收集专家轨迹数据
trajectories = rollout.rollout(
expert,
env,
rollout.make_sample_until(min_timesteps=None, min_episodes=20)
)
# 4. 创建新模型作为 actor
learner = PPO("MlpPolicy", env, verbose=1)
# 5. 使用 GAIL 进行逆强化学习训练
gail_trainer = GAIL(
venv=env,
demonstrations=trajectories,
gen_algo=learner
)
gail_trainer.train(10000)
# 6. 测试训练后的模型
obs = env.reset()
for _ in range(1000):
action, _states = learner.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
env.close()