一、文件压缩
哈夫曼压缩算法需要对输入的文件,逐字节扫描,统计出不同字节出现的数量(频率),根据的得到的频率生成一组叶子节点,这些节点存储着<字节信息>和<频率>,通常需要按频率排序后存储在数组中,更好的做法是存储在小顶堆中;只要堆/数组的大小大于1,每次新建一个节点,取出频率最小的两个节点作为新节点的左右子节点(不必在意谁是左右),两个节点的频率和作为新节点的频率,将新节点放入堆/数组中;最后剩余的节点便是哈夫曼树的根节点。哈夫曼树的数据结构如下所示:
class Node {
public:
using Ptr = std::shared_ptr<Node>;
void SetLeft(Node::Ptr node);
void SetRight(Node::Ptr node);
Node::Ptr Left();
Node::Ptr Right();
void SetChar(uint8_t character);
uint8_t Char();
void SetCount(size_t count);
size_t Count();
bool HasLeft();
bool HasRight();
private:
Node::Ptr _left{ nullptr };//左节点
Node::Ptr _right{ nullptr };//右节点
size_t _count{ 0 };//数量/频率
uint8_t _character{ 0x00 };//字符/字节
};struct NodeCompare {
bool operator()(const Node::Ptr& left, const Node::Ptr& right) {
return left->Count() > right->Count();
}
};
//小顶堆
std::priority_queue<Node::Ptr, std::vector<Node::Ptr>, NodeCompare> pending;
std::unordered_map<uint8_t, size_t> mapper;
for (uint8_t character : input) {
mapper[character]++;
}
for (const auto& pair : mapper) {
pending.push(Node::MakeNode(pair.first, pair.second));
}
if (pending.empty()) return nullptr;
if (pending.size() == 1) {
return pending.top();
}
while (pending.size() > 1) {
auto left = pending.top();
pending.pop();
auto right = pending.top();
pending.pop();
pending.push(Node::MakeNode(0, left->Count() + right->Count(), left, right));
}得到哈夫曼树后,需要重新扫描输入数据,针对每个字节数据到哈夫曼树中查找编码;为避免查询时频繁搜索整棵树,需要先遍历一次树,将字符作为键,生成的编码作为值,存储在map中;为了存储二进制的编码,需要引入新的数据结构:
class BitSet {
public:
void Set(size_t pos);
bool Test(size_t pos) const;
void Reset(size_t pos);
private:
std::vector<uint8_t> data;
size_t count{ 0 };
};
针对这个数据结构,BitSet::Set用于将指定bit设置为1,BitSet::Reset将bit设置为0,BitSet::Test用于检测bit是0/1;由于uint8_t(char)是我们能操作的最小单位,因此BitSet的数据data使用动态uint8_t数组或std::vector<uint8_t>,即使只存储一个bit也必须申请一个字节的空间,因此必须使用count记录实际的bit数(如果使用的是动态数组而不是std::vector,还需要记录实际的字节数byte)。
使用BitSet存储编码数据时,对应的原始字符时8bit的uint8_t,最大可存储256中字符,也就是说极端情况下我们得到的编码长度最大为256,但是极限编码通常事字符频率呈现指数分布,因此最大长度16bit(2 uint8_t)的编码即可满足要求。为了操作方便,即使编码的长度不足16,我们也预分配16bit的空间,避免超过一个字节时重新分配空间。
遍历哈夫曼树,开始时将根节点和空BitSet置于栈中;栈不为空时,每次循环取出节点和BitSet A,如果节点有右子节点,复制A得到B并将其当前位设为1,将右子节点和新的BitSet B压入栈中;如果又左子节点,复制A得到C并将其当前位设为0,将左子节点和新的BitSet C压入栈中;如果没有子节点,则将节点存储的字符和当前的BitSet存入map中。(此时可以将字符频率乘以BitSet的bit数,就得到压缩后数据的总bit数)
std::unordered_map<uint8_t, BitSet> mapper;
struct StagingItem
{
Node::Ptr node{ nullptr };
BitSet code{};
};
std::stack<StagingItem> pending;
pending.emplace(root, BitSet(0,2));
while (!pending.empty()) {
auto node = pending.top().node;
auto code = pending.top().code;
pending.pop();
if (node->HasRight()) {
auto current = code;
current.Push(true);
pending.emplace(node->Right(),current);
}
if (node->HasLeft()) {
auto current = code;
current.Push(false);
pending.emplace(node->Left(),current);
}
if (!node->HasChildren()) {
mapper.emplace(node->Char(), code);
dataBits += (node->Count() * code.Count());
}
}得到std::unordered_map<uint8_t, BitSet> map,就可以逐个字节扫描需要压缩的数据,在map中查找对应二进制编码。由于上一步已经计算压缩后的总bit数,可以预分配一个BitSet encode_data(count = 总bit数) ,将查找到的二进制编码逐个写入encode_data;
BitSet encode_data(dataBits);
size_t index = 0;
for (const auto& character : input) {
auto& code = mapper[character];
for (size_t i = 0;i < code.Count();++i) {
if (code.Test(i)) encode_data.Set(index);
++index;
}
}至此,我们完成了数据的压缩。但是,如果直接将数据写入文件,便无法再将文件解压成源文件。因此必须将哈夫曼树(字符、二进制编码、编码长度)也写入文件中。只有数据和哈夫曼树也还不能将文件恢复,因为无法区分哈夫曼树和文件数据的位置、大小。所以还需要一个新的数据结构(文件头)来描述这些信息:
struct Header
{
size_t dataSize{ 0 };//原文件的字节数,用于解压时预分配空间
size_t dataBits{ 0 };//文件编码的bit数,用于解压时限定数据的边界/长度
uint32_t codeCount{ 0 };//哈夫曼编码的数量
uint16_t reserve{ 0 };//预留/填充
uint8_t label[2] = { 0x52,0x48 };//文件标签
};在网络通信中通常会用报文头标识信息,文件也一样,通常包含文件的 数据区的字节大小、压缩数据的比特数、编码区的字节大小、标签等信息。将文件头,哈夫曼编码和编码后的数据整合到数组中(如下图所示),即可将数据写入文件中,解压时便可根据文件头信息解压。
 由于哈夫曼编码的长度固定(如下图),因此头中只需要指定数量即可。编码长度最大为16bit,用一个字节即可存储编码长度(code size)。
由于哈夫曼编码的长度固定(如下图),因此头中只需要指定数量即可。编码长度最大为16bit,用一个字节即可存储编码长度(code size)。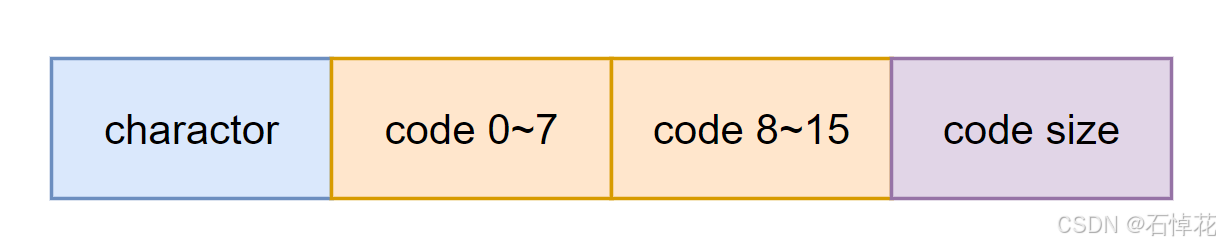
申请一个StagingItem的数组,大小为哈夫曼编码的数量,StagingItem::item的大小为4(上图数据结构的长度)。逐个将哈夫曼树的数据转移至数组中,最后将文件头,编码数组和编码得到的数据写入文件中。
Header header{};
header.dataSize = input.size();
header.dataBits = dataBits;
header.codeCount = static_cast<uint32_t>(mapper.size());
struct StagingItem {
uint8_t item[2 + CODE_WIDTH];//CODE_WIDTH = 2;
};
size_t code_zone_size = mapper.size() * sizeof(StagingItem);
std::vector<StagingItem> staging(mapper.size());
size_t i = 0;
for (const auto& pair : mapper) {
staging[i].item[0] = ~pair.first;
pair.second.ToBytes(&staging[i].item[1], CODE_WIDTH);
staging[i].item[3] = static_cast<uint8_t>(pair.second.Count());
++i;
}
size_t total = sizeof(Header) + code_zone_size + encode_data.DataSize();
std::vector<uint8_t> data(total);
memcpy(data.data(), &header, sizeof(Header));
memcpy(data.data() + sizeof(Header), staging.data(), code_zone_size);
memcpy(data.data() + sizeof(Header)+ code_zone_size, encode_data.DataPtr(), encode_data.DataSize());
二、文件解压
将压缩文件读入内存中,本文将数据存储在std::vector<uint8_t>中,通过std::vector<uint8_t>::data()即可访问文件数据。下列代码意思是将uint8_t指针转为Header类型指针,这样就能直接通过->访问成员的属性,而不需要创建Header对象。通过标签校验文件是否为该算法压缩。除了标签,还可以在压缩时写入校验码、加密密钥等关键信息,通过校验头文件,可以提高操作的安全性。由于文件头最先写于,此时指针正指向文件头的其实位置。
auto header = reinterpret_cast<const Header*>(input.data());
if (header->label[0] != 0x52 && header->label[1] != 0x48) {
}文件头校验成功后,根据文件信息预分配编码空间items;代码auto codeptr = input.data() + sizeof(Header);表示跳过sizeof(Header)字节的位置,将指针指向此处,也就是哈夫曼编码存储的起始位置。用memcpy将数据写回StagingItem数组中;根据编码将哈夫曼树恢复:
1.从根节点开始遍历编码,如果bit==1,前往右子节点,如果没有就先创建在前往;否则前往左子节点,没有也创建。
2.如果遍历到最后一位编码,将编码字符存储在当前的节点中。
3.重复1、2知道所有编码否恢复成树中的节点。
struct StagingItem {
uint8_t item[2 + CODE_WIDTH];
};
auto codeptr = input.data() + sizeof(Header);
std::vector<StagingItem> items(header->codeCount);
size_t code_zone_size = header->codeCount * sizeof(StagingItem);
memcpy(items.data(), codeptr, code_zone_size);
auto root = Node::MakeNode(0, 0);
for (const auto& staging: items) {
auto current = root;
for (size_t i = 0;i < staging.item[3];++i) {
if (BitSet::Test(&staging.item[1], i, staging.item[3])) {
if (!current->HasRight()) current->SetRight(Node::MakeNode(0, 0));
current = current->Right();
}
else {
if (!current->HasLeft()) current->SetLeft(Node::MakeNode(0, 0));
current = current->Left();
}
}
current->SetChar(~staging.item[0]);
}将指针指向编码数据的起始位置,逐个bit访问,遇到1前往问右子节点,遇到0就前往左子节点,没有子节点则将数据节点存储的字符写到data中,并将节点重置为根节点。当编码数据的所有bit都处理完成,数据也就解压完成,此时将data写回文件中即可。
auto dataptr = codeptr + code_zone_size;
size_t index = 0;
std::vector<uint8_t> data(header->dataSize);
for (size_t i = 0;i < header->dataBits;) {
auto current = root;
while (current != nullptr) {
if (!current->HasChildren()) {
data[index] = current->Char();
++index;
break;
}
if (BitSet::Test(dataptr, i, header->dataBits)) {
if (!current->HasRight()) {
throw std::runtime_error("invalid right node");
}
current = current->Right();
}
else {
if (!current->HasLeft()) {
throw std::runtime_error("invalid left node");
}
current = current->Left();
}
++i;
}
}
if (index != header->dataSize) {
throw std::runtime_error("decompress failed,file has been broken");
}
经过测试,debug模式下对于小文件压缩速率通常为10MB/s,解压速率为2MB/s;release模式下,压缩速率在55MB/s,解压速率10MB/s。下图是release模式下压缩1.1MB点云的数据。

对于文本信息压缩比率较高,但是对音视频、图片直接压缩几乎没有效果;大文件的压缩效果也是优于小文件的,文件过小还可能导致叫上编码信息后压缩体积远大于源文件体积。