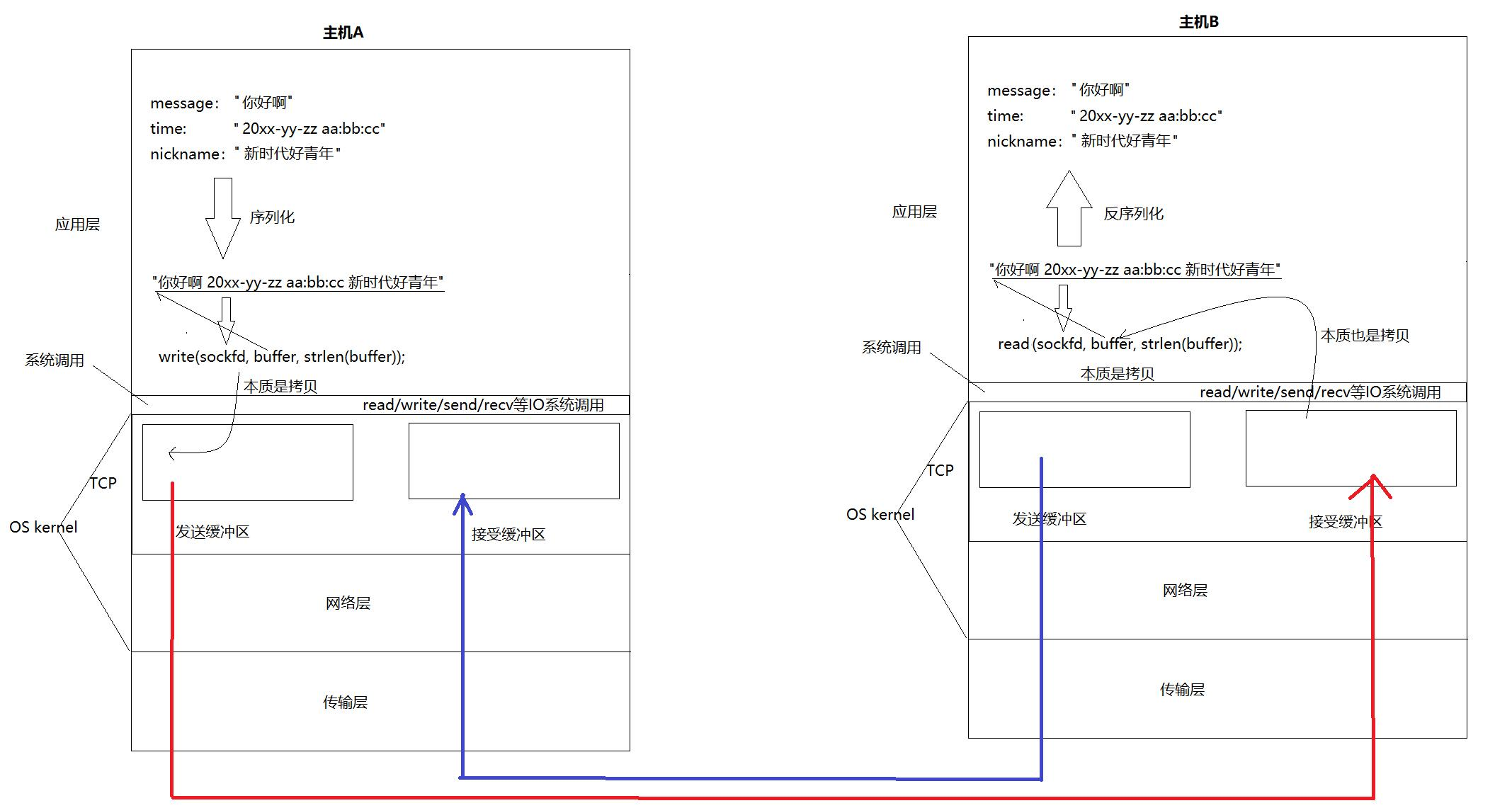
创建一个简单搜索引擎,将用户原始问题传递该搜索系统
本文重点:获取保存文档——保存向量数据库——加载向量数据库
专注于youtube的字幕,利用youtube的公开接口,获取元数据
pip install youtube-transscript-api pytube
初始化
import datetime import os from operator import itemgetter from typing import Optional, List import bs4 from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains.history_aware_retriever import create_history_aware_retriever from langchain.chains.retrieval import create_retrieval_chain from langchain.chains.sql_database.query import create_sql_query_chain from langchain_chroma import Chroma from langchain_community.agent_toolkits import SQLDatabaseToolkit from langchain_community.document_loaders import WebBaseLoader, YoutubeLoader from langchain_community.tools import QuerySQLDataBaseTool from langchain_community.utilities import SQLDatabase from langchain_core.documents import Document from langchain_core.messages import SystemMessage, HumanMessage from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate from langchain_core.runnables import RunnableWithMessageHistory, RunnablePassthrough from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.chat_message_histories import ChatMessageHistory from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langgraph.prebuilt import chat_agent_executor from pydantic.v1 import BaseModel, Field os.environ['http_proxy'] = '127.0.0.1:7890' os.environ['https_proxy'] = '127.0.0.1:7890' os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo" os.environ["LANGCHAIN_API_KEY"] = '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' # os.environ["TAVILY_API_KEY"] = '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' # 聊天机器人案例 # 创建模型 model = ChatOpenAI(model='gpt-4-turbo') embeddings = OpenAIEmbeddings(model='text-embedding-3-small')
创建持久化向量数据库
存放向量数据库的目录
persist_dir = 'chroma_data_dir' # 存放向量数据库的目录
获取&保存文档
YoutubeLoader是 langchain_community.document_loaders
##一个Youtube的视频对应一个document
# 一些YouTube的视频连接 urls = [ "https://www.youtube.com/watch?v=HAn9vnJy6S4", "https://www.youtube.com/watch?v=dA1cHGACXCo", "https://www.youtube.com/watch?v=ZcEMLz27sL4", "https://www.youtube.com/watch?v=hvAPnpSfSGo", "https://www.youtube.com/watch?v=EhlPDL4QrWY", "https://www.youtube.com/watch?v=mmBo8nlu2j0", "https://www.youtube.com/watch?v=rQdibOsL1ps", "https://www.youtube.com/watch?v=28lC4fqukoc", "https://www.youtube.com/watch?v=es-9MgxB-uc", "https://www.youtube.com/watch?v=wLRHwKuKvOE", "https://www.youtube.com/watch?v=ObIltMaRJvY", "https://www.youtube.com/watch?v=DjuXACWYkkU", "https://www.youtube.com/watch?v=o7C9ld6Ln-M", ] docs = [] # document的数组 for url in urls: # # 一个Youtube的视频对应一个document docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load()) print(len(docs)) print(docs[0]) #具体document参数,可以在此查看 # # 给doc添加额外的元数据: 视频发布的年份 # for doc in docs: # doc.metadata['publish_year'] = int( # datetime.datetime.strptime(doc.metadata['publish_date'], '%Y-%m-%d %H:%M:%S').strftime('%Y')) # # # print(docs[0].metadata) # print(docs[0].page_content[:500]) # 第一个视频的字幕内容 #len、docs[0]、docs[0].metadata、docs[0].page_content[:500]

构建向量数据库
文档切割——》向量数据库持久化
persist_directory=persist_dir 持久化到磁盘
# # 根据多个doc构建向量数据库 text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=30) split_doc = text_splitter.split_documents(docs) # # 向量数据库的持久化 # 并且把向量数据库持久化到磁盘 vectorstore = Chroma.from_documents(split_doc, embeddings, persist_directory=persist_dir)
加载磁盘向量数据库
#vectorstore = Chroma(persist_directory=persist_dir, embedding_function=embeddings)
此处persist_dir、Embedding要和上文一致。
## 相似检索结果result【0】【0】才是一个结果。result【0】=(Document,score)
## 若不需要分数,使用.similarity_search
vectorstore = Chroma(persist_directory=persist_dir, embedding_function=embeddings) # 测试向量数据库的相似检索 # result = vectorstore.similarity_search_with_score('how do I build a RAG agent') # print(result[0]) # print(result[0][0].metadata['publish_year'])# 测试结果

整合LLM
Prompt
system = """You are an expert at converting user questions into database queries. \ You have access to a database of tutorial videos about a software library for building LLM-powered applications. \ Given a question, return a list of database queries optimized to retrieve the most relevant results. If there are acronyms or words you are not familiar with, do not try to rephrase them.""" prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ] )pydantic Model
# 如果chain中仅用model(不使用.with_structured_output);那么只能检索content;但我们还需要进行metadata检索,提取结构化参数。那么可以采用pydantic(用于数据管理的库);
这里Search是数据模型、pydantic的model,非LLM;
Search 的核心作用
- 标准化检索参数:将非结构化文本(用户问题)转化为结构化的
query和publish_year,确保后续检索系统能精准处理。- 错误预防:通过类型检查(如
publish_year必须为整数)避免无效参数传递。- 可解释性:明确每个字段的用途(通过
description),便于团队协作和维护Optional:表示可选字段
# pydantic class Search(BaseModel): """ 定义了一个数据模型 进行metadata检索 """ # 内容的相似性和发布年份 query: str = Field(None , description='Similarity search query applied to video transcripts.') publish_year: Optional[int] = Field(None , description='Year video was published')chain
RunnablePassthrough:让值 可以滞后传递。
model.with_structured_output(Search):要求模型生成符合
Search类定义的结构化输出(而非自由文本)chain = {'question': RunnablePassthrough()} | prompt | model.with_structured_output(Search) # resp1 = chain.invoke('how do I build a RAG agent?') # print(resp1) # resp2 = chain.invoke('videos on RAG published in 2023') # print(resp2)chain简单测试:这里只是生成指令,并未搜索

执行搜索
自定义一个检索器。
#" $eq"是Chroma向量数据库的固定语法: search.publish_year==向量数据库'publish_year'
def retrieval(search: Search) -> List[Document]: _filter = None if search.publish_year: # 根据publish_year,存在得到一个检索条件 # "$eq"是Chroma向量数据库的固定语法 _filter = {'publish_year': {"$eq": search.publish_year}} return vectorstore.similarity_search(search.query, filter=_filter) new_chain = chain | retrieval # result = new_chain.invoke('videos on RAG published in 2023') result = new_chain.invoke('RAG tutorial') print([(doc.metadata['title'], doc.metadata['publish_year']) for doc in result])结构化数据检索
非结构化检索