NLP中放弃使用循环神经网络架构
- 一、符号表示与概念基础
- 二、循环神经网络
- 1. 依赖序列索引存在的并行计算问题
- 2. 线性交互距离
- 三、总结
该系列笔记阐述了自然语言处理(NLP)中不再采用循环架构(recurrent architectures)的原因,介绍了自注意力机制,并构建了一个基于自注意力的极简神经架构。最后,深入探讨了Transformer架构的细节。同时,可能延申描述一些Transformer的应用。
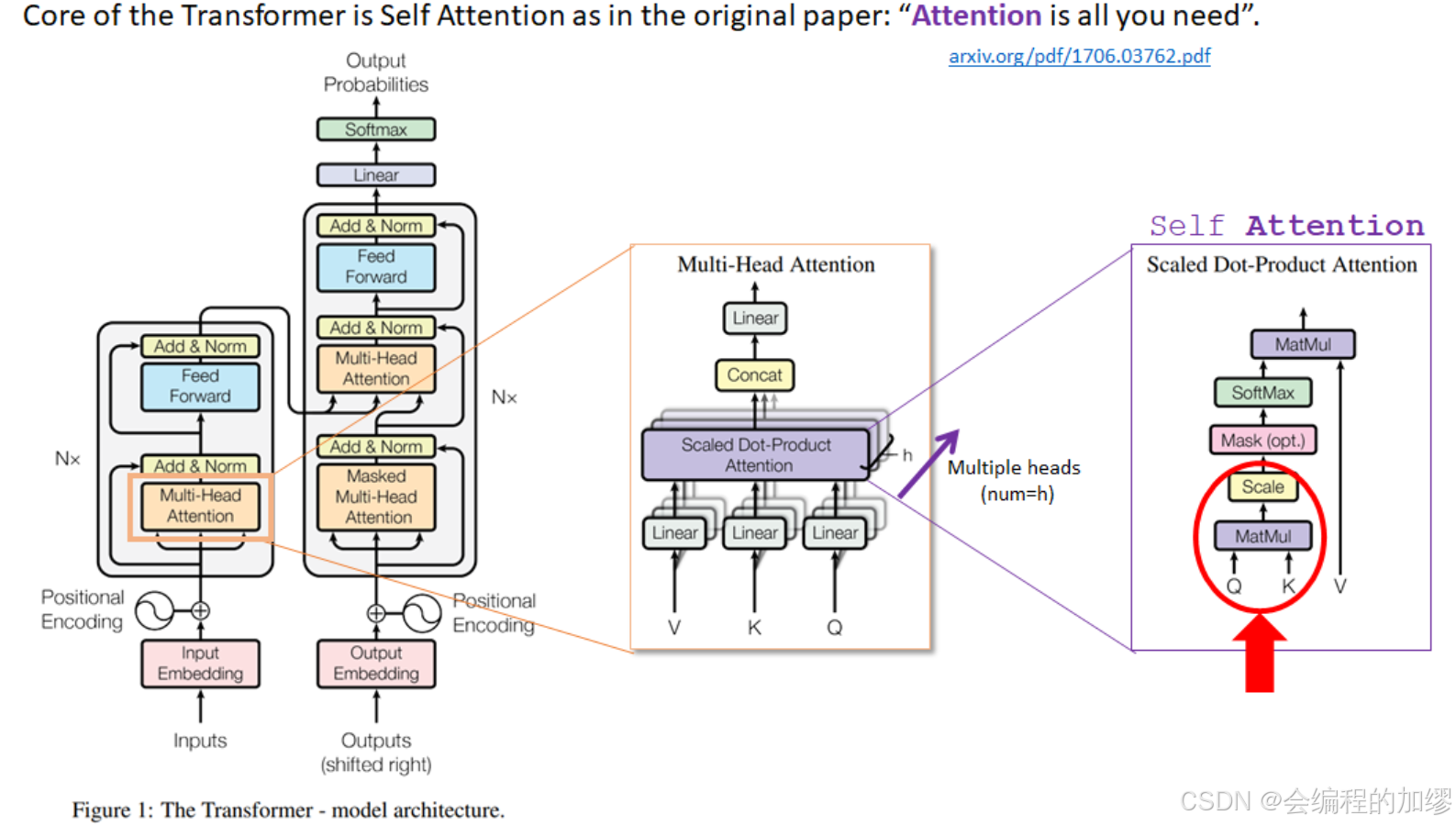
在self-attention和Transformer架构出现之前,自然语言处理(NLP)中通常采用的是循环架构(recurrent architectures),这篇文章将为大家介绍,为什么self-attention出现后,就不再用recurrent architectures。
一、符号表示与概念基础
假设
w
1
:
n
w_{1:n}
w1:n是一个序列,每一个
w
i
∈
V
w_{i}\in V
wi∈V,
V
V
V为一个有限的词汇表。同时,让
w
1
:
n
w_{1:n}
w1:n除了表示原本的序列外,还额外表示一个独热向量矩阵,
w
1
:
n
∈
R
n
×
∣
V
∣
w_{1:n}\in R^{n\times|V|}
w1:n∈Rn×∣V∣。用
w
∈
V
w\in V
w∈V表示一个任意的词汇单元,并且
w
i
∈
V
w_{i}\in V
wi∈V来选择序列
w
1
:
n
w_{1:n}
w1:n中的一个具体的有索引的单元。用下式表示
w
t
w_{t}
wt是服从
∼
\sim
∼右侧定义的概率分布:
w
t
∼
s
o
f
t
m
a
x
(
f
(
w
1
:
t
−
1
)
)
(1)
w_{t} \sim softmax(f(w_{1:t-1})) \tag{1}
wt∼softmax(f(w1:t−1))(1)
其中,
f
(
w
1
:
t
−
1
)
∈
R
∣
V
∣
f(w_{1:t-1})\in R^{|V|}
f(w1:t−1)∈R∣V∣,当用上述的softmax函数时,不会直接指明进行归一化操作的维度。如果
A
A
A时形状为
R
l
,
d
R^{l,d}
Rl,d,softmax可以用下式计算:
s
o
f
t
m
a
x
(
A
)
i
,
j
=
e
x
p
A
i
,
j
∑
j
′
=
1
d
e
x
p
A
i
,
j
′
(2)
softmax(A)_{i,j} = \frac{expA_{i,j}}{\sum_{j'=1}^dexpA_{i,j'}} \tag{2}
softmax(A)i,j=∑j′=1dexpAi,j′expAi,j(2)
对于所有的
i
∈
{
1
,
…
,
ℓ
}
i \in \{1, \ldots, \ell\}
i∈{1,…,ℓ},
j
∈
{
1
,
…
,
d
}
j \in \{1, \ldots, d\}
j∈{1,…,d},对于超过两个轴的张量也是类似的计算方式。也就是说,如果我们有一个张量
B
∈
R
m
,
ℓ
,
d
B \in \mathbb{R}^{m,\ell,d}
B∈Rm,ℓ,d,我们同样对最后一个维度定义softmax函数。为了避免产生歧义,我们详细写出来:
s
o
f
t
m
a
x
(
B
)
q
,
i
,
j
=
e
x
p
B
q
,
i
,
j
∑
j
′
=
1
d
e
x
p
B
q
,
i
,
j
′
(3)
softmax(B)_{q,i,j} = \frac{expB_{q,i,j}}{\sum_{j'=1}^dexpB_{q,i,j'}} \tag{3}
softmax(B)q,i,j=∑j′=1dexpBq,i,j′expBq,i,j(3)
⭐ 说明softmax函数可以使用不同维度的张量,
A
i
,
j
A_{i,j}
Ai,j表示的二维张量,
B
q
,
i
,
j
B_{q,i,j}
Bq,i,j表示三维张量
⚡ 在本文所有的方法中,作者将假设存在一个嵌入矩阵 E ∈ R d × ∣ V ∣ E\in\mathbb{R}^{d\times|V|} E∈Rd×∣V∣,它将词汇空间映射到隐藏维度 d d d,表示为 E x ∈ R d Ex\in\mathbb{R}^{d} Ex∈Rd。
序列 w 1 : n w_{1:n} w1:n中的某个词元 w i w_{i} wi的嵌入 E w i Ew_{i} Ewi是一种上下文无关的表示,尽管 w i w_{i} wi出现在序列中,但 E w i Ew_{i} Ewi这一表示却与上下文无关。 然而,我们总是处理 w 1 : n w_{1:n} w1:n的嵌入版本,所以我们令 x = E w x=Ew x=Ew并且 x 1 : n = w 1 : n E T ∈ R n × d x_{1:n}=w_{1:n}E^T\in R^{n\times d} x1:n=w1:nET∈Rn×d。本文中讨论的方法的目标是开发一个强大的词元上下文表示,也就是 w i w_{i} wi表征 h i h_{i} hi,但同时也是整个序列 x 1 : n x_{1:n} x1:n的函数。例如:
一句话为W1:n = {"我要吃好吃的东西"}, W4对应的是‘好’这个token,它的表征h4不仅表征着W4,还表征着x1:n=w1:nET
⭐ 序列 x 1 : n x_{1:n} x1:n中词元 x i x_{i} xi的非上下文表示仅取决于 x i x_{i} xi本身的标识;而 x i x_{i} xi的上下文表示 h i h_{i} hi则依赖于整个序列(或前缀 x 1 : i x_{1:i} x1:i)。
二、循环神经网络
处理自然语言任务时,2017年左右的默认的选择是循环神经网络。通用的建模技术和表示方法在自然语言处理领域有着悠久的历史,其中各种技术经历了兴衰起伏。例如,词嵌入的历史远比我们在最初几节课中学习的word2vec词嵌入要长得多(Schutze,1992年)。同样,循环神经网络在建模问题上也有着漫长且并非单调发展的历史(Elman,1990年;Bengio等人,2000年)。然而,到了2017年,解决自然语言处理任务的基本策略却是从使用循环神经网络开始。一个简单的RNN可以用下面公式来表示:

其中,
h
t
∈
R
d
h_{t}\in R^d
ht∈Rd,
U
∈
R
d
×
d
U\in R^{d\times d}
U∈Rd×d 并且
W
∈
R
d
×
d
W\in R^{d\times d}
W∈Rd×d。
到 2017 年,人们的直观认识是循环神经网络形式存在两方面的问题,而这两个问题都与公式 4 中所强调的对序列索引的依赖(通常被称为对 “时间” 的依赖)有关。
1. 依赖序列索引存在的并行计算问题
现代图形处理单元(GPU)非常擅长并行处理大量简单操作(比如加法)。例如,当我有一个矩阵
A
∈
R
n
×
k
A\in\mathbb{R}^{n\times k}
A∈Rn×k和一个矩阵
B
∈
R
k
×
d
B\in\mathbb{R}^{k\times d}
B∈Rk×d时,GPU 在计算
A
B
∈
R
n
×
d
AB\in\mathbb{R}^{n\times d}
AB∈Rn×d时速度极快。然而,并行操作的限制至关重要——在以最简单的方式计算
A
B
AB
AB时,我要进行一系列乘法运算,然后再进行一系列求和运算,其中大多数运算彼此并不依赖于对方的输出。但是,在循环神经网络中,当我进行计算时 :
h
2
=
σ
(
W
h
1
+
U
x
2
)
(5)
h_{2}=\sigma(Wh_{1}+Ux_{2}) \tag{5}
h2=σ(Wh1+Ux2)(5)
⚡只有知道
h
2
h_{2}
h2才能计算
h
1
h_{1}
h1,所以上式需要被写成:
h
2
=
σ
(
W
(
W
h
0
+
U
x
1
)
+
U
x
2
)
(6)
h_{2}=\sigma(W(Wh_{0}+Ux_{1})+Ux_{2}) \tag{6}
h2=σ(W(Wh0+Ux1)+Ux2)(6)
同样地,如果我想计算
h
3
h_3
h3,在知道
h
2
h_2
h2之前我无法计算它,而在知道
h
1
h_1
h1之前我又无法计算
h
2
h_2
h2,以此类推。从直观上看,就如图1所示。随着序列变得越来越长,由于存在大量的串行依赖关系(串行意味着一个接一个),在图形处理单元(GPU)上,我能够对网络计算进行并行处理的程度非常有限。
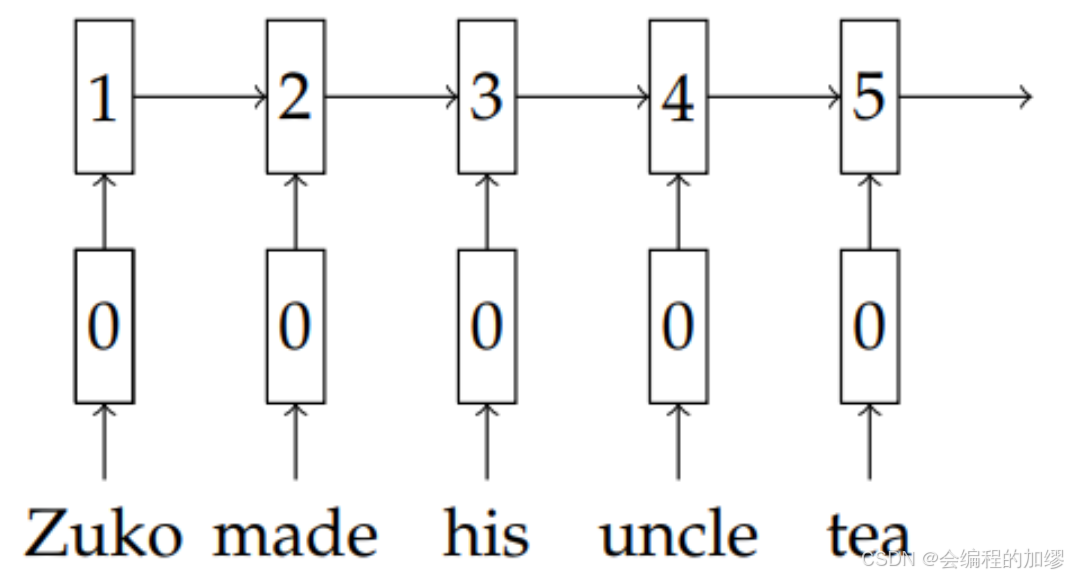
📔 图1:按时间展开的循环神经网络(RNN)。 这些矩形表示循环神经网络的中间状态(例如,第一行是嵌入层,第二行是每个时间步的循环神经网络隐藏状态),第一行矩形中的数字表示在计算出这个中间状态之前需要执行的串行操作的数量。
随着图形处理单元(GPU)(后来,像张量处理单元(TPU)这样的其他加速器也变得更加强大),并且研究人员想要更充分地利用它们,这种对时间的依赖就变得站不住脚了。
2. 线性交互距离
循环神经网络(RNN)存在的另一个相关问题是,序列中距离较远的词元难以相互产生交互作用。这里所说的 “交互”,是指一个词元(之前已经出现过的)的存在能有效地影响另一个词元的处理过程。例如,在这样一个句子中:
The chef1 who ran out of blackberries and went to the stores is1
例如,将“chef”和“is”分隔开来的中间计算的数量——比如矩阵乘法和非线性运算——会随着它们之间单词的数量而增加。我们在图2中直观展示了这一点。
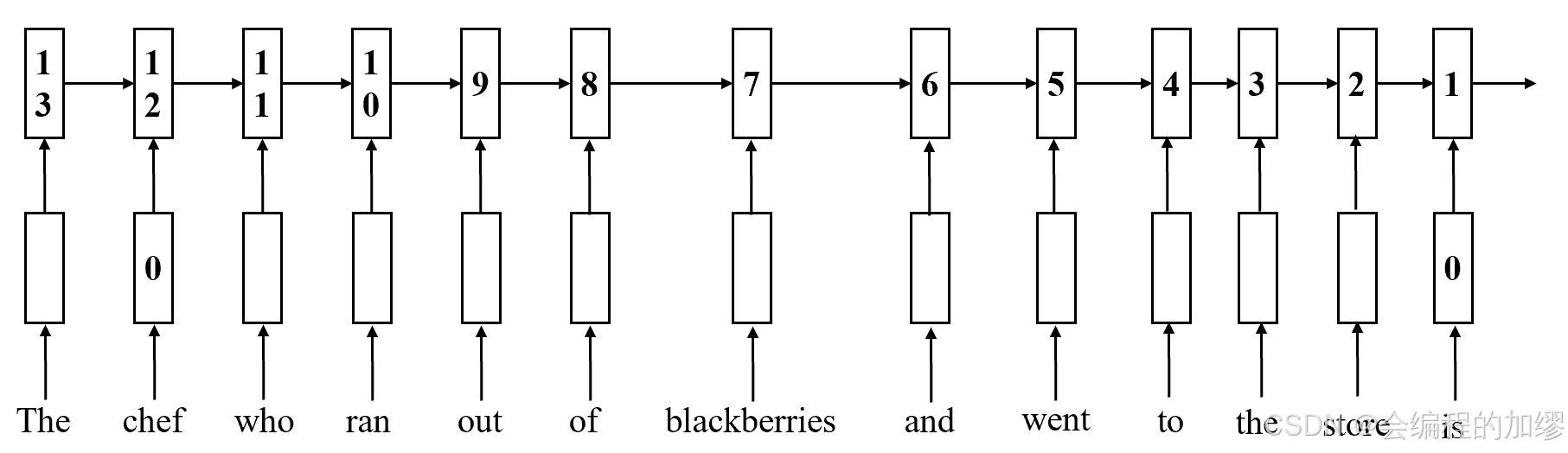
📔 图2:按时间展开的循环神经网络(RNN)。 这些矩形表示循环神经网络的中间状态(例如,第一行是嵌入层,第二行是每个时间步的循环神经网络隐藏状态),矩形中的数字大致是将单词“tea”的词汇信息与每个中间状态分隔开来的操作数量。
例如: is到chef的操作距离为11步;
直观地说,研究人员认为线性交互距离存在一个问题,因为当在观察到某个单词之后进行大量的运算操作时,网络很难精确地 “回忆” 起这个单词的存在。这可能会使得学习相距较远的单词应该如何影响当前单词的表示变得困难。
序列中元素之间这种直接交互的概念可能会让你联想到机器翻译中的注意力机制(Bahdanau等人,2014年)。在机器翻译的情境中,在生成译文时,我们学习了对于译文中的每个词元,如何回过去关注源语言序列。在本笔记中,我们将介绍一种完全基于注意力机制的方法,用以替代循环神经网络。这将同时解决循环神经网络中存在的并行化问题以及线性交互距离问题。
三、总结
由于循环神经网络在分析某一token的上下文关联时需要操作很多步骤,并且只有在知道上一时刻的状态时,才能计算下一时刻的状态,这给模型带来了很多限制。因此,当2017年Transformer架构出现后,NLP的处理放弃了循环神经网络的架构,而转向拥抱自注意力机制。下一篇文章将详细介绍自注意力机制。
欢迎大家讨论交流!