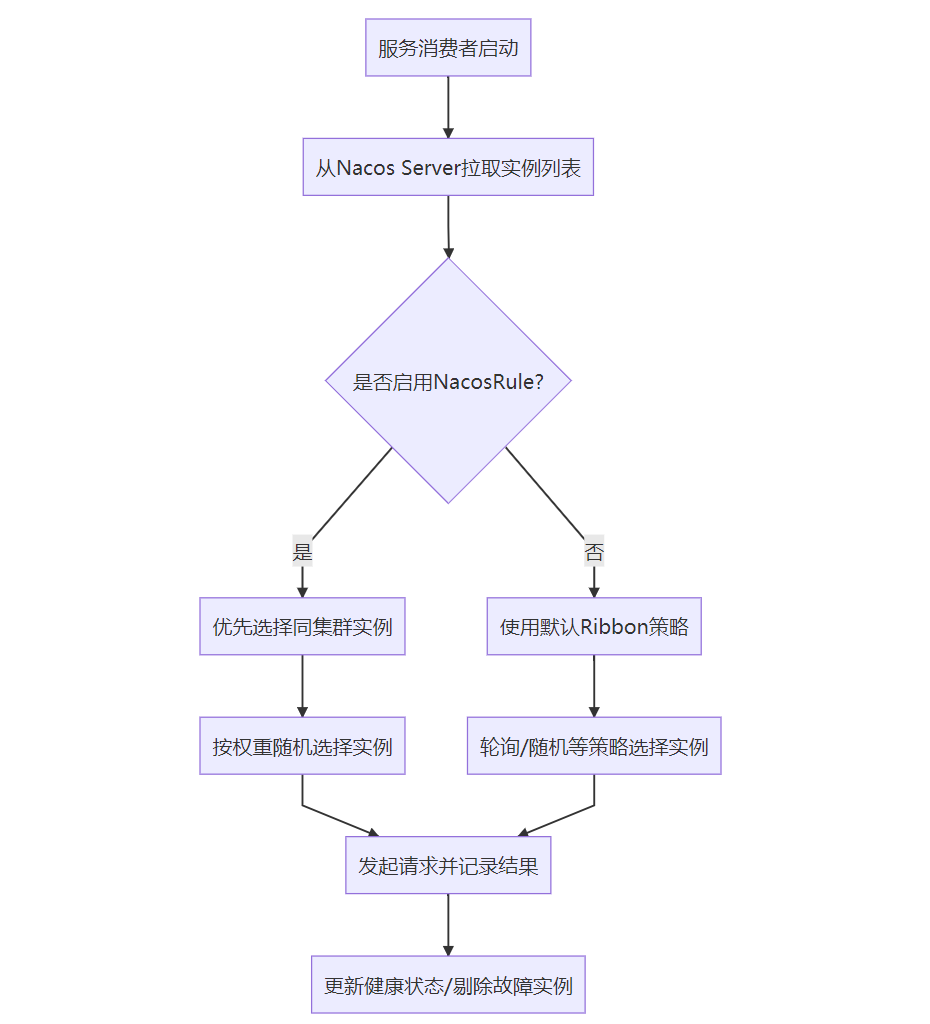
本专栏
国产之光DeepSeek架构理解与应用分析-CSDN博客
国产之光DeepSeek架构理解与应用分析02-CSDN博客
前置的一些内容理解
GPU TPU NPU的区别?
设计目的
GPU:最初是为了加速图形渲染而设计的,用于处理图像和视频数据,以提供高质量的视觉效果。在现代计算机中,GPU 也被广泛用于通用计算,如科学计算、深度学习等。
TPU:是专门为加速张量计算而设计的,主要用于深度学习模型的训练和推理。TPU 针对深度学习的特点进行了优化,能够高效地处理大规模的张量运算。
NPU:主要用于加速神经网络的计算,特别适用于人工智能领域中的图像识别、语音识别、自然语言处理等任务。NPU 通常采用了专门的架构和算法,能够在低功耗的情况下提供高效的神经网络计算能力。
硬件架构
GPU:拥有大量的计算核心(cuda),通常采用 SIMD(单指令多数据)架构,能够同时处理多个数据元素。GPU 还具有丰富的内存层次结构,包括片上缓存、显存等,以支持高效的数据访问。
以英伟达的gpu为例,大概的硬件架构图
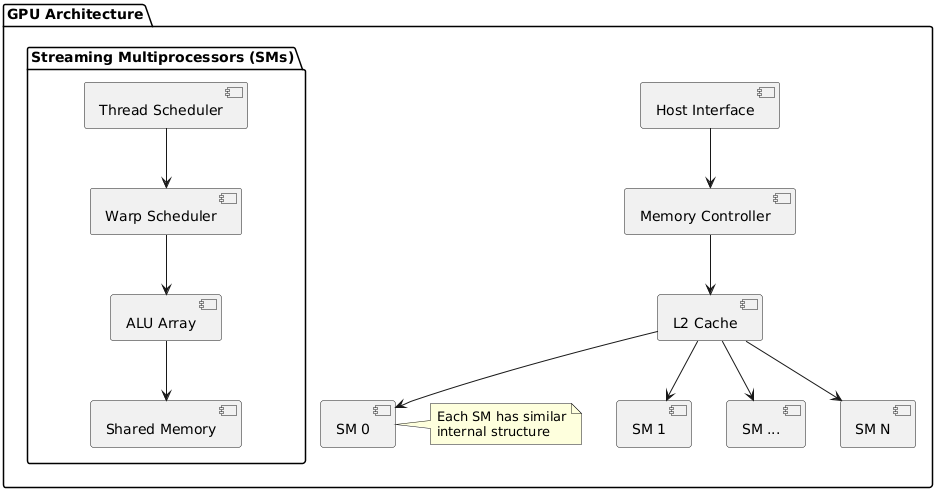
1.主机接口(Host Interface):负责与主机(如 CPU)进行通信。
2.内存控制器(Memory Controller):管理 GPU 与外部内存(如 GDDR)之间的数据传输。
3.L2 缓存(L2 Cache):作为数据的高速缓存,减少内存访问延迟。
4.流式多处理器(Streaming Multiprocessors, SMs):GPU 的核心计算单元,多个 SM 并行工作以提高计算能力。每个 SM 内部包含线程调度器、 warp 调度器、ALU 阵列和共享内存。
TPU:通常采用了专门的张量处理单元(Tensor Core),能够高效地处理张量运算。TPU 还具有高速的内存接口和片上缓存,以支持快速的数据传输和访问。
以较新的谷歌 TPU v4 为例

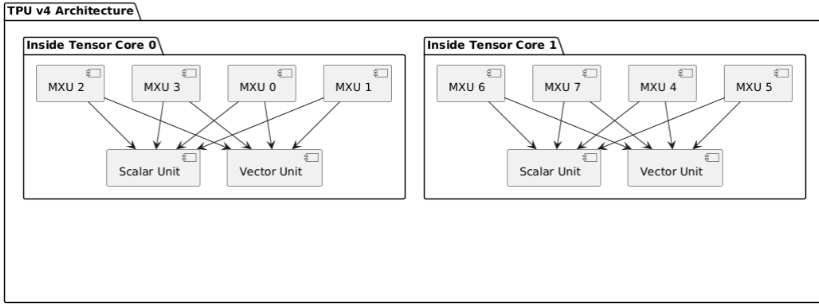
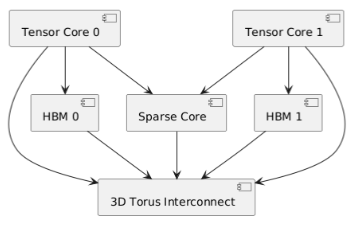
1.整体组件Tensor Core:TPU v4 有两个 Tensor Core(tensor_core_0和tensor_core_1 ),每个 Tensor Core 包含多个核心计算单元。
HBM(高带宽内存):有两个 HBM 模块(hbm_0和hbm_1 ),分别与对应的 Tensor Core 相连,提供高带宽内存支持。
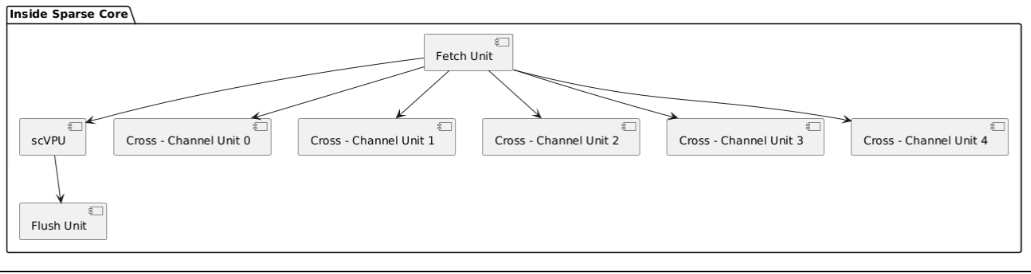
Sparse Core:专门针对稀疏计算优化的模块(sparse_core ),与两个 Tensor Core 都有连接。
3D Torus Interconnect:3D Torus 互联结构(torus ),用于实现芯片间高效互联,连接各个主要组件。
2.Tensor Core 内部
每个 Tensor Core 里有四个脉动阵列 MXU(如mxu_0 - mxu_3 等 )以及一个 Scalar Unit 和一个 Vector Unit ,展示了其内部计算单元的构成和连接关系。Sparse 3.Core 内部
包含 Fetch Unit(从 HBM 读取数据 )、scVPU(向量处理单元 )、Flush Unit(反向传播时写入更新参数 )以及五个跨通道单元(执行嵌入操作 ),体现其针对稀疏计算的功能模块设计。
NPU:采用了专门的神经网络处理器架构,通常包括多个处理单元和存储单元。NPU 还具有高效的硬件加速器,如卷积神经网络(CNN)加速器、循环神经网络(RNN)加速器等,以支持不同类型的神经网络计算。
以较为典型的寒武纪思元系列 NPU 架构为参考示例
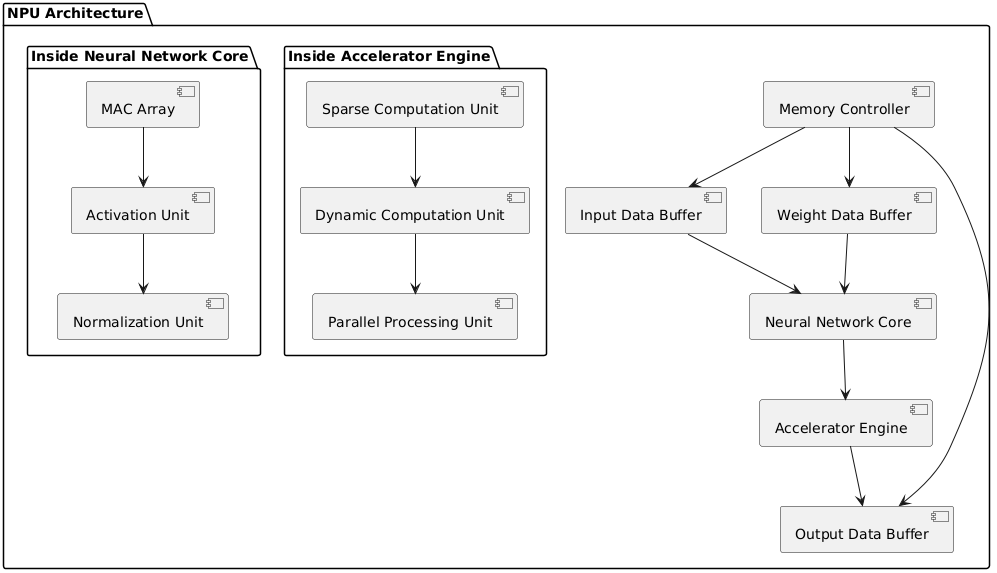
1.整体组件Input Data Buffer:输入数据缓冲区,用于暂存输入到 NPU 的数据。
Weight Data Buffer:权重数据缓冲区,存放神经网络计算所需的权重参数。
Neural Network Core:神经网络核心计算单元,进行主要的神经网络计算。
Accelerator Engine:加速引擎,对特定计算进行加速处理,提升计算效率。
Memory Controller:内存控制器,管理数据在不同缓冲区和外部内存之间的传输。
Output Data Buffer:输出数据缓冲区,存储计算后的输出结果。
2.Neural Network Core 内部MAC Array:乘累加阵列,执行大量的乘累加操作,是神经网络计算的基础运算单元。
Activation Unit:激活单元,对 MAC 阵列的计算结果应用激活函数,引入非线性因素。
Normalization Unit:归一化单元,对数据进行归一化处理,有助于提升模型训练和推理的稳定性与效率。
3.Accelerator Engine 内部Sparse Computation Unit:稀疏计算单元,针对稀疏数据进行高效计算,减少不必要的计算量。
Dynamic Computation Unit:动态计算单元,适应不同的计算需求,灵活调整计算方式。
Parallel Processing Unit:并行处理单元,充分利用并行计算资源,加速整体计算过程
计算能力
GPU:具有强大的并行计算能力,能够同时处理多个图形或计算任务。在深度学习领域,GPU 也能够提供较高的计算性能,特别是在处理大规模数据集和复杂模型时表现出色。
TPU:针对深度学习的张量计算进行了优化,能够提供比 GPU 更高的计算性能和效率。TPU 通常采用了更高的时钟频率和更高效的计算单元,能够在短时间内完成大规模的张量运算。
NPU:在处理神经网络计算时具有高效的性能,能够在低功耗的情况下提供较高的计算速度。NPU 通常采用了专门的算法和架构,能够针对不同类型的神经网络进行优化,从而提高计算效率。
应用场景
GPU:广泛应用于图形渲染、游戏开发、科学计算、深度学习等领域。在深度学习领域,GPU 是目前最常用的计算设备之一,能够支持各种深度学习框架和模型的训练和推理。
TPU:主要应用于深度学习领域,特别是在大规模数据中心和云计算环境中,用于加速深度学习模型的训练和推理。TPU 能够提供高效的计算性能和低功耗,从而降低数据中心的运营成本。
NPU:主要应用于人工智能领域,如智能手机、智能家居、智能安防等设备中,用于加速图像识别、语音识别、自然语言处理等任务。NPU 能够在低功耗的情况下提供高效的计算能力,从而满足设备对性能和功耗的要求。
SiLU激活函数,并进一步解释门控神经网络
SiLU 激活函数详解
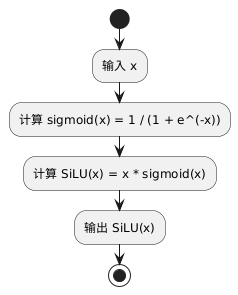
SiLU(Sigmoid Linear Unit)激活函数,也被称为 Swish 激活函数,由 Google Brain 在 2017 年引入。其定义为:
SiLU(x)=x⋅sigmoid(x)
其中,sigmoid(x) 是标准的 sigmoid 函数,其值在 0 和 1 之间:
sigmoid(x)=1+e−x1
特性
平滑性:SiLU 是一个平滑的函数,其输出值是连续且可导的,这有助于梯度下降算法在优化过程中稳定更新参数
非线性:SiLU 引入了非线性变换,使其能够捕捉复杂的数据模式
自正则化:SiLU 的输出值可以自适应地缩放输入值,类似于自正则化的效果,这可能有助于减少过拟合
无零输出区域:与 ReLU 不同,SiLU 不存在零输出区域,这意味着它在负数部分也有一定的响应,从而避免了梯度消失问题
优点
缓解梯度消失问题:SiLU 在负数部分也有一定的响应,这使得它在深度神经网络中能够更好地缓解梯度消失问题
非零中心:SiLU 的输出值不是零中心的,这有助于网络的学习
平滑函数:SiLU 是一个平滑函数,这意味着它在整个定义域内都有导数,有利于优化
缺点
计算复杂度:SiLU 的计算复杂度相对较高,因为它需要计算 sigmoid 函数。
应用场景
SiLU 激活函数在深度神经网络中表现出色,尤其是在需要处理负值输入的场景中。它在 YOLOv5 等深度学习模型中被广泛应用,取得了良好的效果
与其他激活函数的对比
ReLU(Rectified Linear Unit):ReLU 函数定义为ReLU(x) = max(0, x),它在 x > 0 时输出线性增长,而在 x <= 0 时输出为 0。这导致了 “死亡 ReLU” 问题,即当神经元的输入一直为负时,它将永远不会被激活,梯度也会变为 0,从而使该神经元无法更新参数。而 SiLU 在负数部分有非零输出,避免了这个问题。
Sigmoid 函数:Sigmoid 函数将输入值映射到 (0, 1) 区间,常用于二分类问题的输出层。然而,Sigmoid 函数存在梯度消失问题,当输入值很大或很小时,其导数趋近于 0,导致在深度神经网络中难以进行有效的参数更新。SiLU 结合了 Sigmoid 函数和线性函数,一定程度上缓解了梯度消失问题。
数学性质
导数:SiLU 函数的导数可以通过乘积法则计算。设 f(x) = x * sigma(x),其中 sigma(x)是 Sigmoid 函数。根据乘积法则 (uv)' = u'v + uv',可得 f'(x) = sigma(x) + x *sigma(x) * (1 - sigma(x))。这个导数在整个定义域内都是连续的,有助于梯度下降算法的稳定运行。
门控机制理解
SiLU 可以看作是一种门控机制,其中 sigma(x) 作为门控信号。当 sigma(x) 接近 1 时,输入 x 几乎可以无衰减地通过,相当于门打开;当 sigma(x) 接近 0 时,输入 x 被大幅抑制,相当于门关闭。这种门控机制使得 SiLU 能够自适应地调整输入的影响,从而更好地捕捉数据的特征。
门控神经网络详解
门控神经网络是一种通过门控机制来控制信息流动的神经网络结构。门控机制的核心思想是通过“门”来决定哪些信息应该被保留,哪些信息应该被过滤或抑制,从而提升模型的表达能力和计算效率
门控机制的原理
门控机制通常由神经网络(如全连接层)和激活函数(如 sigmoid)组成。门控的计算公式一般如下:
G=σ(Wx+b)
其中,x 是输入信息,W 和 b 是权重和偏置,σ 是 sigmoid 函数。
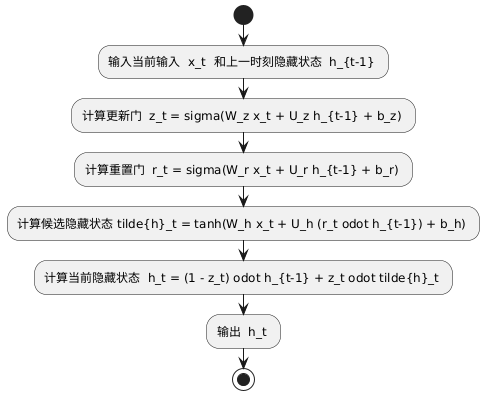
门控神经网络的结构
门控神经网络的典型代表包括长短期记忆网络(LSTM)和门控循环单元(GRU)。这些网络通过门控机制来控制信息的流动,从而有效地处理序列数据。
门控循环单元(GRU)
GRU 是一种简化的 LSTM 结构,它通过两个门(更新门和重置门)来控制信息的流动。更新门负责确定有多少上一个时间步的隐藏状态信息应该被保留到当前时间步,而重置门负责确定在计算新的隐藏状态时,有多少上一个时间步的隐藏状态信息应该被保留。
门控神经网络的应用
门控神经网络在处理序列数据(如自然语言处理、时间序列预测等)方面表现出色。它们通过门控机制有效地解决了传统 RNN 的梯度消失问题,从而能够更好地建模长距离依赖关系。