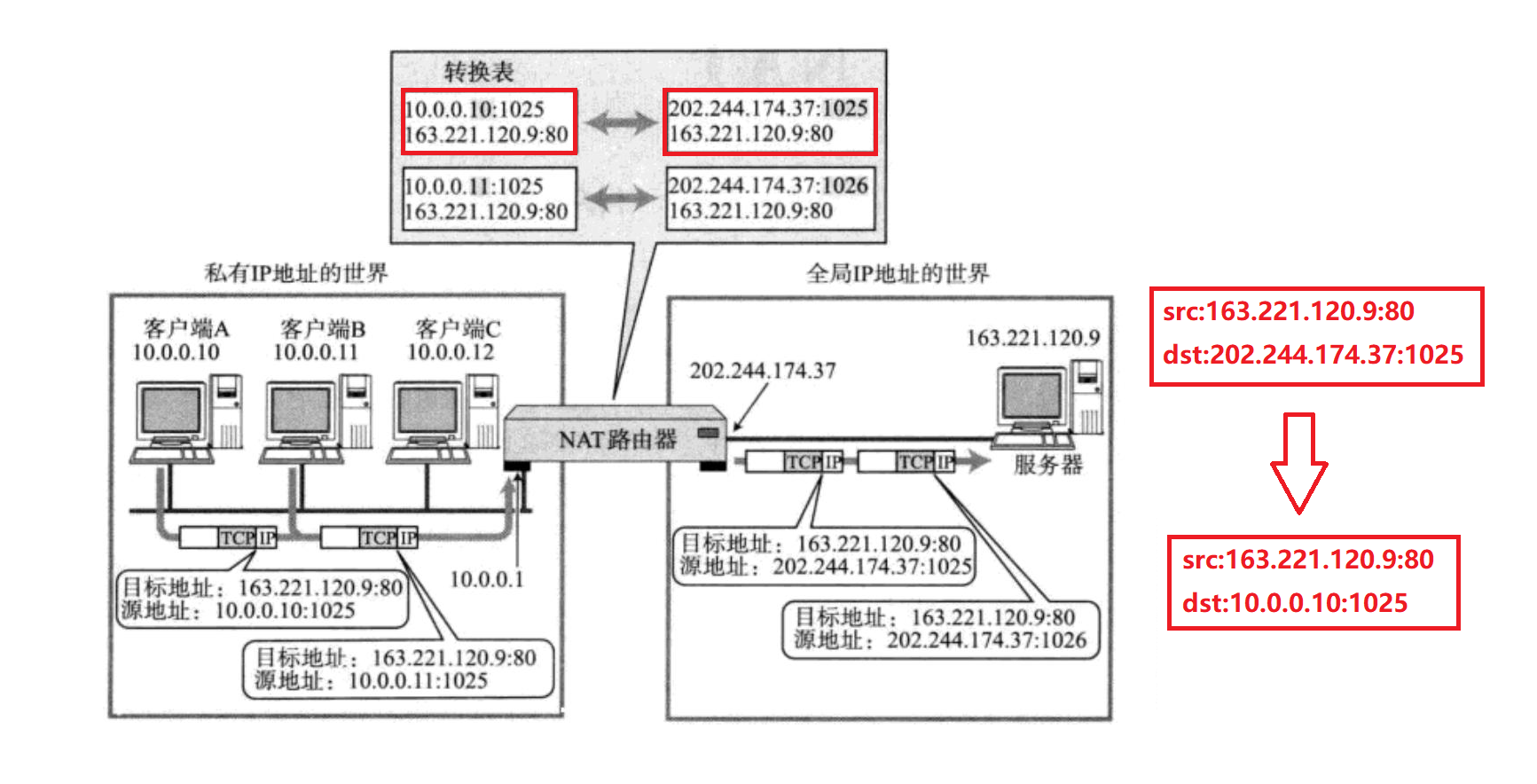
编写程序,统计两会政府工作报告热词频率,并生成词云。
2025两会政府工作报告
import jieba
import wordcloud
from collections import Counter
import re
# 读取文件
with open("gov.txt", "r", encoding="gbk") as f:
t = f.read()
# 分词处理
ls = jieba.lcut(t)
# 定义过滤函数
def is_valid_word(word):
# 过滤条件:
# 1. 长度至少为2个字符(过滤单字)
# 2. 只包含中文(\u4e00-\u9fff)
# 3. 不是停用词(可选)
return (len(word) >= 2 and
all('\u4e00' <= char <= '\u9fff' for char in word))
# 严格过滤
filtered_words = [word for word in ls if is_valid_word(word)]
# 统计词频
word_counts = Counter(filtered_words)
# 打印前20个高频词
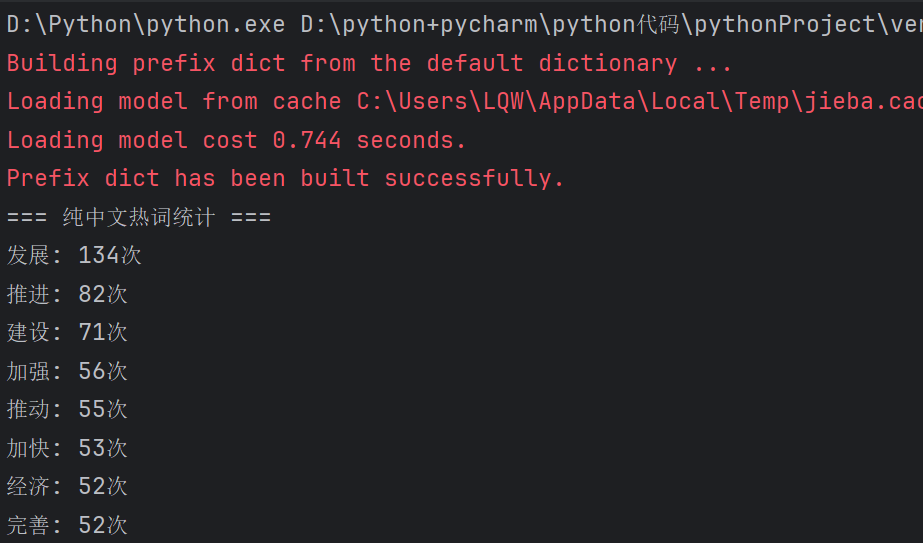
print("=== 纯中文热词统计 ===")
for word, count in word_counts.most_common(20):
print(f"{word}: {count}次")
# 生成词云
txt = " ".join(filtered_words)
w = wordcloud.WordCloud(
font_path="msyh.ttc",
width=1000,
height=700,
background_color="white",
max_words=200 # 限制词云显示的最大词数
)
w.generate(txt)
w.to_file("wordcloud.png")