接上一篇,上一篇主要讲解了关于二叉树的基本知识,也是为了接下来讲解关于堆结构和链式二叉树结构打基础,其实无论是堆结构还是链式二叉树结构,都是二叉树的存储结构,那么今天这一篇主要讲解关于堆结构的实现与应用
堆的概念与结构
堆是一种特殊的树形数据结构,它可以被想象成是一个 “有序的金字塔”,并且这个金字塔是基于完全二叉树构建的。(不知道什么是完全二叉树的小伙伴可以先空降到上一篇)
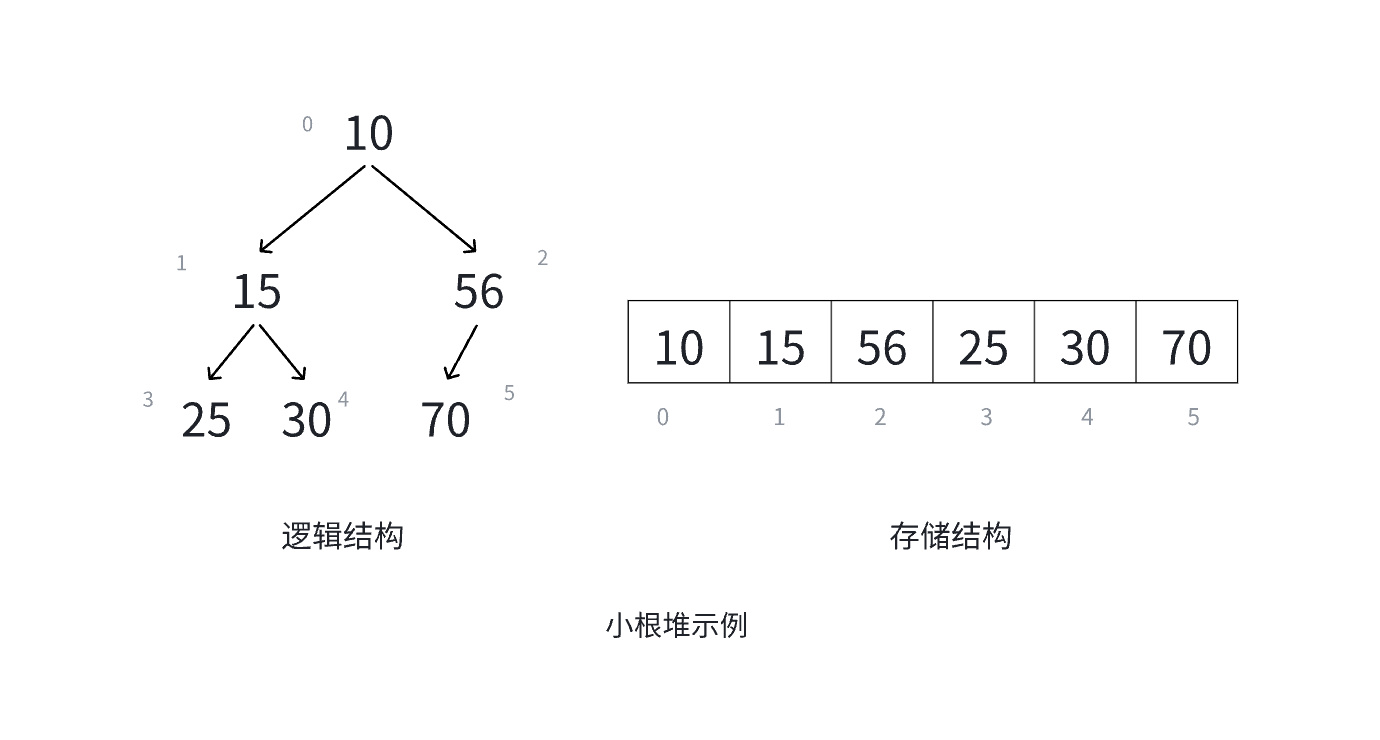
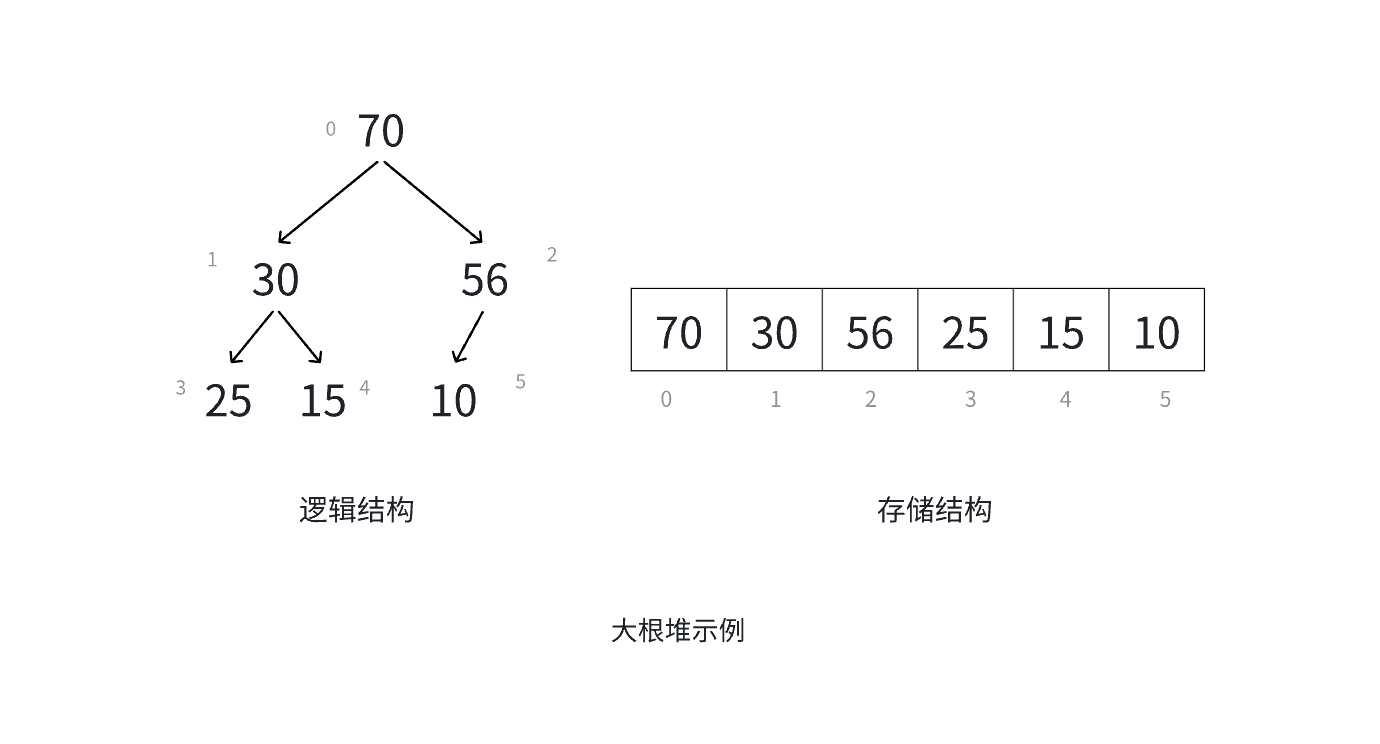
堆的性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值
- 堆总是一棵完全二叉树。
- 最大堆:每个节点的值都大于或等于其子节点的值。可以把它想象成一场比赛,每个 “选手”(节点)都比它的 “下属”(子节点)更厉害。这样一来,处于金字塔顶端(根节点)的就是最厉害的 “选手”。
- 最小堆:每个节点的值都小于或等于其子节点的值。就好像每个 “选手” 都比它的 “下属” 弱,那么金字塔顶端的就是最弱的 “选手”。
堆的实现
现在讲关于堆这个数据结构的实现
堆的初始化、销毁、打印,因为堆的底层结构是数组,所以堆的实现和顺序表、栈有一定的相似性,那么话不多说直接上代码:
typedef int HPDataType;
typedef struct Heap
{
HPDataType* arr;
int size;//有效数据元素个数
int capacity;//空间容量
}Heap;
//堆的初始化
void HeapInit(Heap* php)
{
assert(php);
php->arr = NULL;
php->capacity = php->size = 0;
}
//堆的销毁
void HeapDestroy(Heap* php)
{
assert(php);
for (int i = 0; i < php->size - 1; i++)
{
free(php->arr[i]);
php->arr[i] = NULL;
}
php->capacity = php->size = 0;
}
//堆的打印
void HeapPrint(Heap* php)
{
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->arr[i]);
}
printf("\n");
}以上都是堆的一些基础操作,接下来我们上点强度:堆的插入、删除这些操作,和之前一些数据结构会有一些不一样,先来看看插入吧:
//堆的插入
void HeapPush(Heap* php, HPDataType x)
{
assert(php);
if (php->capacity == php->size)
{
int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HPDataType* tmp = (HPDataType*)realloc(php->arr,sizeof(HPDataType)*newcapacity);
if (tmp == NULL)
{
perror("malloc fail");
return 1;
}
php->arr = tmp;
php->capacity = newcapacity;
}
php->arr[php->size] = x;
AdjustUp(php->arr, php->size);
php->size++;
}
//向上调整
void AdjustUp(HPDataType* arr, int child)
{
int parent = (child - 1) / 2;
//假设现在是大堆
while (child > 0)
{
//大堆:<
//小堆:>
if (arr[parent] < arr[child])
{
Swap(&arr[parent], &arr[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}可以看到这里堆的插入操作,除了常规的申请空间以外,还多了一个向上调整的操作,这是为啥呢?这里给大家说明一下:堆的性质是:首先是一颗完全二叉树,更重要的是它要么是一个大堆,要么是一个小堆,当新插入数据时,为了维持堆的这个特性,就要进行向上调整
那么这个向上调整的思想是什么呢?首先就是通过新插入的结点作为孩子结点,去找他的父亲结点,假设现在是要建大堆,拿他的父亲结点和他自己比较,谁大谁往上放,自己大就自己往上放,父结点大就直接跳出循环
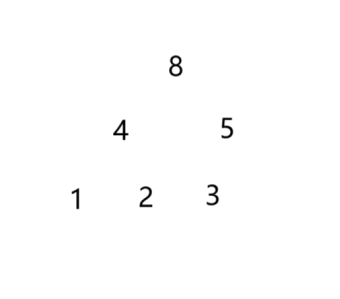
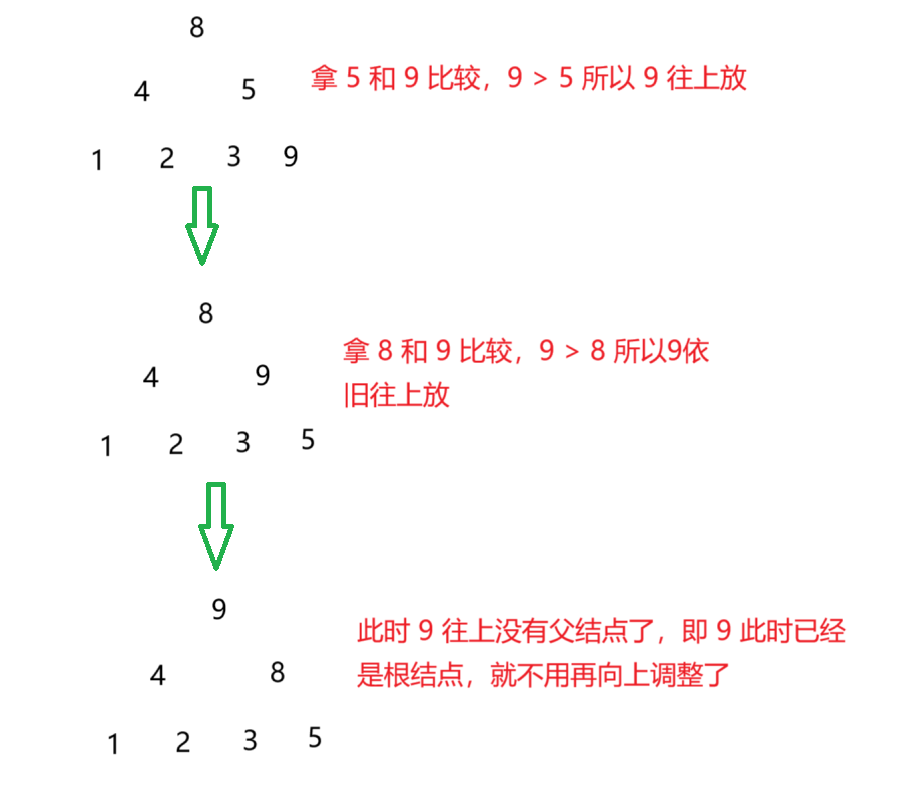
这里我们假设是这样一个大堆,如果要插入 9 这个元素,如图所示。
接下来看看堆的删除吧:
//堆的删除
void HeapPop(Heap* php)
{
assert(!IsEmpty(php));
Swap(&php->arr[0], &php->arr[php->size - 1]);
php->size--;
AdjustDown(php->arr,0, php->size);
}
//向下调整
AdjustDown(HPDataType* arr, int parent, int n)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
//假设是大堆
//大堆:<
//小堆:>
if (arr[parent] < arr[child])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}这里堆的删除指的是删除堆顶的元素,同理,和堆的插入一样,为了维持堆的大堆/小堆的特性,删除了堆顶元素可能破坏了这个特性,所以也需要调整,但这里有所不同,这里是向下调整,其实思路和向上调整差不多,这里博主就不画图了,重点讲一下向上调整和向下调整的区别以及为什么插入要进行向上调整,而删除是向下调整:
首先,向下调整算法在这里的效率要比向上调整算法高,因为向下调整算法是可以忽略最后一层结点的,什么意思呢,我们来看哈,我们进行堆的删除操作时,目的是删除堆顶元素,我们让堆顶结点和最后一个叶子结点先交换位置,再把当前最后一个叶子结点删除,最后进行向下调整,我们通过这个根结点,找到他的孩子结点,让他们进行比较,谁小谁往下放,放到倒数第二层的时候,这个当前结点所对应的二叉树就已经是个堆了,所以最后一层就不用再进行向下调整了,这样效率就会高一些。
然后再来讲一下,为什么插入要进行向上调整,而删除是向下调整:因为我们向上调整的算法思想是通过当前结点找其父结点,再不断向上,如果我们用向下调整,那就是通过当前结点找子节点向下交换,而我们进行插入操作的时候,新插入的这个结点本身就是个叶子结点,他已经没有子结点了,所以在堆的插入操作中,向下调整时不适用的,要进行向上调整,反过来堆的删除操作道理也是一样的,这里就不过多赘述了。
以上就是堆的插入、删除操作,接下来还有一些其他操作比较简单,我这里直接上代码了:
//取堆顶数据
HPDataType HeapTop(Heap* php)
{
assert(!IsEmpty(php));
return php->arr[0];
}
//判空
bool IsEmpty(Heap* php)
{
assert(php);
return php->size == 0;
}结尾
好了以上就是关于堆的所有讲解了,觉得博客写的还不错,可以点点赞哦~

![[react]Next.js之自适应布局和高清屏幕适配解决方案](https://i-blog.csdnimg.cn/direct/4494b56f3c2b419681cb1cdf6d04361d.png)