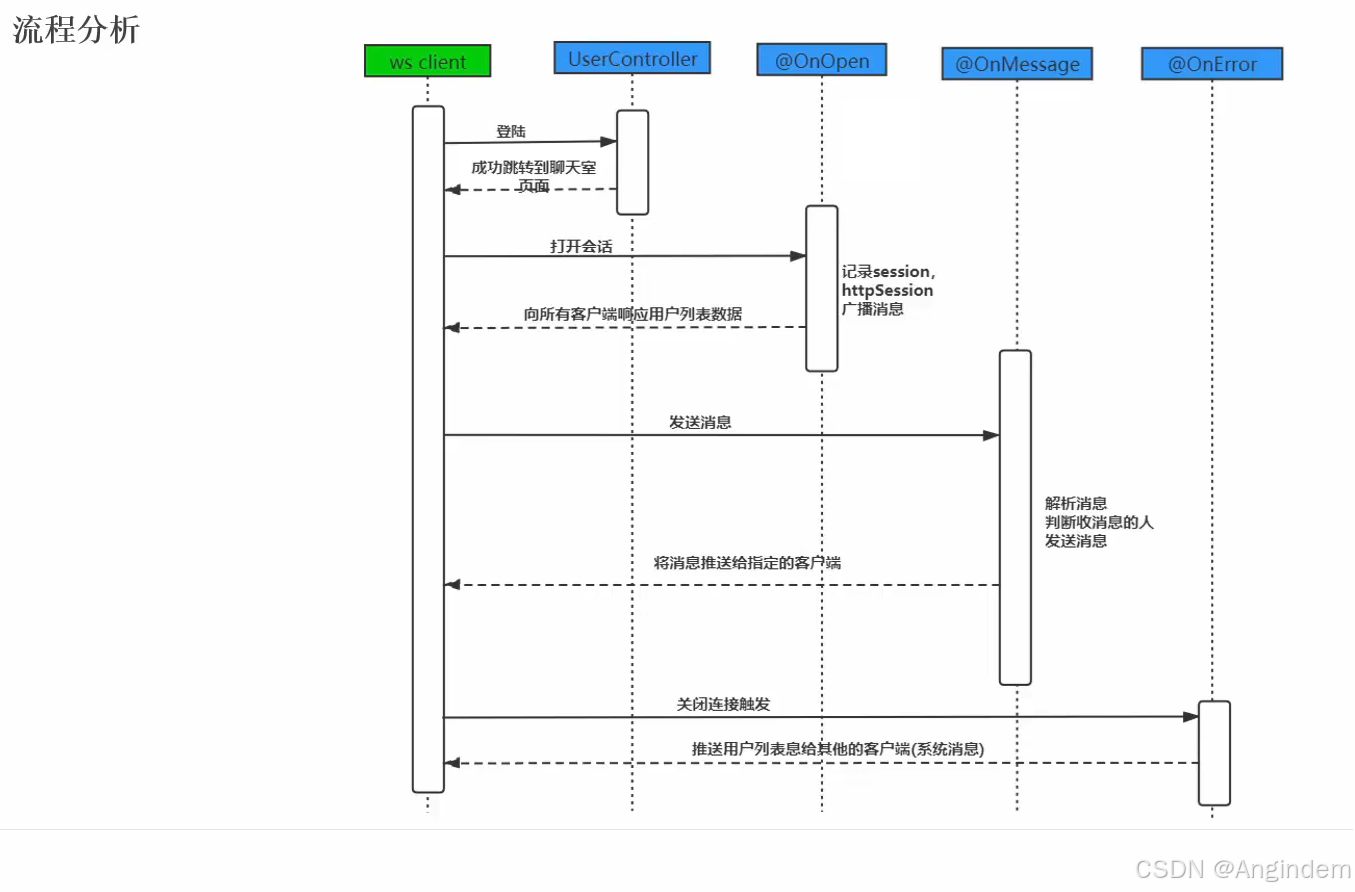
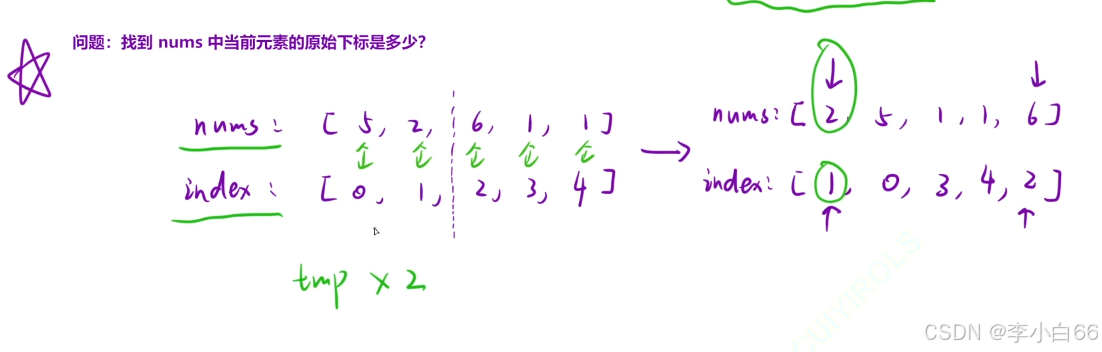
本节代码是一个完整的机器学习工作流程,用于训练一个基于GPT-2的语言模型。下面是对这段代码的详细解释:
文件目录如下

1. 初始化和数据准备
-
设置随机种子
random.seed(1002)确保结果的可重复性。
-
定义参数
test_rate = 0.2 context_length = 128-
test_rate:测试集占总数据集的比例。 -
context_length:模型处理的文本长度。
-
-
获取数据文件
all_files = glob(pathname=os.path.join("data","*"))使用
glob获取data目录下的所有文件。 -
划分数据集
test_file_list = random.sample(all_files, int(len(all_files) * test_rate)) train_file_list = [i for i in all_files if i not in test_file_list]将数据集随机划分为训练集和测试集。
-
加载数据集
raw_datasets = load_dataset("csv", data_files={"train": train_file_list, "vaild": test_file_list}, cache_dir="cache_data")使用
datasets库加载 CSV 格式的数据集,并缓存到cache_data目录。
2. 数据预处理
-
初始化分词器
tokenizer = BertTokenizerFast.from_pretrained("D:/bert-base-chinese") tokenizer.add_special_tokens({"bos_token":"[begin]","eos_token":"[end]"})从本地路径加载预训练的 BERT 分词器,并添加自定义的开始和结束标记。
-
数据预处理
tokenize_datasets = raw_datasets.map(tokenize, batched=True, remove_columns=raw_datasets["train"].column_names)使用
map方法对数据集进行预处理,将文本转换为模型可接受的格式。-
tokenize函数对文本进行分词和截断。 -
batched=True表示批量处理数据。 -
remove_columns删除原始数据集中的列。
-
3. 模型配置和初始化
-
模型配置
config = GPT2Config.from_pretrained("config", vocab_size=len(tokenizer), n_ctx=context_length, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id, )加载预训练的 GPT-2 配置,并根据分词器的词汇表大小和上下文长度进行调整。
-
初始化模型
model = GPT2LMHeadModel(config) model_size = sum([t.numel() for t in model.parameters()]) print(f"model_size: {model_size/1000/1000} M")根据配置初始化 GPT-2 语言模型,并计算模型参数的总数,打印模型大小(以兆字节为单位)。
4. 训练设置
-
数据整理器
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)使用
DataCollatorForLanguageModeling整理训练数据,设置mlm=False表示不使用掩码语言模型。 -
训练参数
args = TrainingArguments( learning_rate=1e-5, num_train_epochs=100, per_device_train_batch_size=10, per_device_eval_batch_size=10, eval_steps=2000, logging_steps=2000, gradient_accumulation_steps=5, weight_decay=0.1, warmup_steps=1000, lr_scheduler_type="cosine", save_steps=100, output_dir="model_output", fp16=True, )配置训练参数,包括学习率、训练轮数、批大小、评估间隔等。
-
初始化训练器
trianer = Trainer( model=model, args=args, tokenizer=tokenizer, data_collator=data_collator, train_dataset=tokenize_datasets["train"], eval_dataset=tokenize_datasets["vaild"] ) -
启动训练
trianer.train()使用
Trainer类启动模型训练。
需复现完整代码
from glob import glob
import os
from torch.utils.data import Dataset
from datasets import load_dataset
import random
from transformers import BertTokenizerFast
from transformers import GPT2Config
from transformers import GPT2LMHeadModel
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer,TrainingArguments
def tokenize(element):
outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True)
input_batch = []
for length,input_ids in zip(outputs["length"],outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids":input_batch}
if __name__ == "__main__":
random.seed(1002)
test_rate = 0.2
context_length = 128
all_files = glob(pathname=os.path.join("data","*"))
test_file_list = random.sample(all_files,int(len(all_files)*test_rate))
train_file_list = [i for i in all_files if i not in test_file_list]
raw_datasets = load_dataset("csv",data_files={"train":train_file_list,"vaild":test_file_list},cache_dir="cache_data")
tokenizer = BertTokenizerFast.from_pretrained("D:/bert-base-chinese")
tokenizer.add_special_tokens({"bos_token":"[begin]","eos_token":"[end]"})
tokenize_datasets = raw_datasets.map(tokenize,batched=True,remove_columns=raw_datasets["train"].column_names)
config = GPT2Config.from_pretrained("config",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id = tokenizer.bos_token_id,
eos_token_id = tokenizer.eos_token_id,
)
model = GPT2LMHeadModel(config)
model_size = sum([ t.numel() for t in model.parameters()])
print(f"model_size: {model_size/1000/1000} M")
data_collator = DataCollatorForLanguageModeling(tokenizer,mlm=False)
args = TrainingArguments(
learning_rate=1e-5,
num_train_epochs=100,
per_device_train_batch_size=10,
per_device_eval_batch_size=10,
eval_steps=2000,
logging_steps=2000,
gradient_accumulation_steps=5,
weight_decay=0.1,
warmup_steps=1000,
lr_scheduler_type="cosine",
save_steps=100,
output_dir="model_output",
fp16=True,
)
trianer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenize_datasets["train"],
eval_dataset=tokenize_datasets["vaild"]
)
trianer.train()