非聚合查询和聚合查询的概念及差别
1. 非聚合查询
非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。
示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT id, name, department, salary
FROM employees;这个查询会返回 employees 表中的所有行和指定的列。
特点
-
返回原始数据:结果是表中的实际行数据。
-
不涉及数据汇总:不会对数据进行任何汇总或计算。
-
可以使用
WHERE子句过滤数据SELECT id, name, department, salary FROM employees WHERE department = 'Sales';
2. 聚合查询
聚合查询(Aggregate Query)是指使用聚合函数的查询。聚合函数用于对一组数据进行计算,返回单个值。常见的聚合函数包括 COUNT、SUM、AVG、MIN 和 MAX。
示例
假设我们想要统计每个部门的员工数量:
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;这个查询会返回每个部门的名称和该部门的员工数量。
特点
-
返回汇总数据:结果是对一组数据进行计算后的汇总值。
-
必须使用
GROUP BY子句:如果查询中包含非聚合列,则需要使用GROUP BY子句对这些列进行分组。 -
可以使用
HAVING子句过滤分组SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department HAVING COUNT(*) > 5;
3. 聚合查询与非聚合查询的差别
| 特点 | 非聚合查询 | 聚合查询 |
|---|---|---|
| 返回数据类型 | 返回表中的原始行数据 | 返回汇总后的单个值 |
| 是否使用聚合函数 | 不使用聚合函数 | 使用聚合函数(如 COUNT、SUM、AVG 等) |
是否需要 GROUP BY | 不需要 | 如果查询中包含非聚合列,则需要 GROUP BY |
| 数据量 | 返回多行数据 | 返回较少的行(通常是汇总后的数据) |
| 用途 | 用于检索具体数据 | 用于数据汇总和统计 |
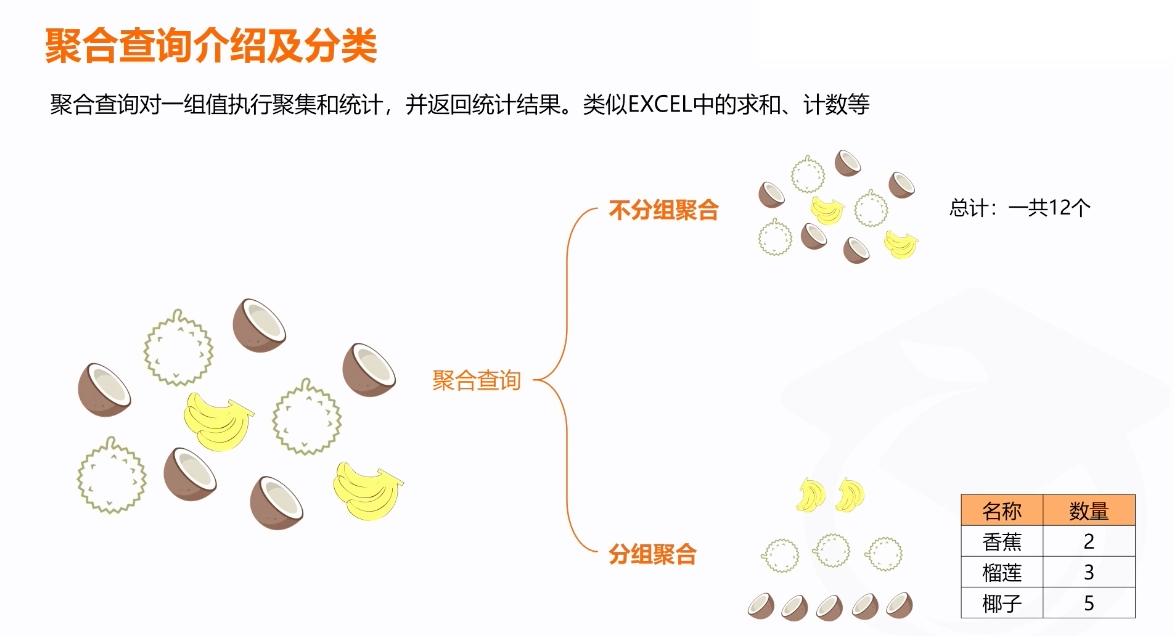
非分组聚合和分组聚合的概念和差别
在 SQL 中,分组聚合(Grouped Aggregation)和不分组聚合(Ungrouped Aggregation)是聚合查询的两种不同形式。它们的主要区别在于是否使用 GROUP BY 子句对数据进行分组。以下是对它们的概念和差别的详细解释。
1. 分组聚合(Grouped Aggregation)
分组聚合是指在执行聚合操作时,将数据分成多个组,每个组对应一个聚合结果。这通常通过 GROUP BY 子句实现。
概念
-
GROUP BY子句:用于将数据按指定列分组。 -
聚合函数:对每个分组的数据进行计算,返回每个分组的汇总值。

示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;这个查询会按 department 列对数据进行分组,并计算每个部门的员工数量和平均工资。
结果
假设表数据如下:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
查询结果:
| department | employee_count | avg_salary |
|---|---|---|
| Sales | 2 | 5250 |
| Marketing | 2 | 6250 |
| IT | 1 | 7000 |
2. 不分组聚合(Ungrouped Aggregation)
不分组聚合是指对整个表的数据进行聚合操作,不进行分组。这种查询返回的是整个表的汇总值。
概念
-
聚合函数:对整个表的数据进行计算,返回单个汇总值。
-
不使用
GROUP BY子句:直接对整个表的数据进行聚合。
示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT COUNT(*) AS total_employees, AVG(salary) AS avg_salary
FROM employees;这个查询会计算整个表的员工总数和平均工资。
结果
假设表数据如下:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
查询结果:
| total_employees | avg_salary |
|---|---|
| 5 | 6000 |
3. 分组聚合与不分组聚合的差别
| 特点 | 分组聚合(Grouped Aggregation) | 不分组聚合(Ungrouped Aggregation) |
|---|---|---|
是否使用 GROUP BY | 是 | 否 |
| 返回结果 | 每个分组的汇总值 | 整个表的汇总值 |
| 结果行数 | 与分组数相同 | 通常为一行 |
| 用途 | 对数据进行分组汇总,适用于多维度分析 | 对整个表的数据进行汇总,适用于全局统计 |
| 示例 | 按部门统计员工数量和平均工资 | 统计整个公司的员工总数和平均工资 |
4. 示例对比
假设我们有以下 employees 表:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
分组聚合
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;结果:
| department | employee_count | avg_salary |
|---|---|---|
| Sales | 2 | 5250 |
| Marketing | 2 | 6250 |
| IT | 1 | 7000 |
不分组聚合
SELECT COUNT(*) AS total_employees, AVG(salary) AS avg_salary
FROM employees;结果:
| total_employees | avg_salary |
|---|---|
| 5 | 6000 |
总结
-
分组聚合:通过
GROUP BY子句对数据进行分组,返回每个分组的汇总值,适用于多维度分析。 -
不分组聚合:对整个表的数据进行聚合,返回整个表的汇总值,适用于全局统计。
图示差别
 常见使用错误点
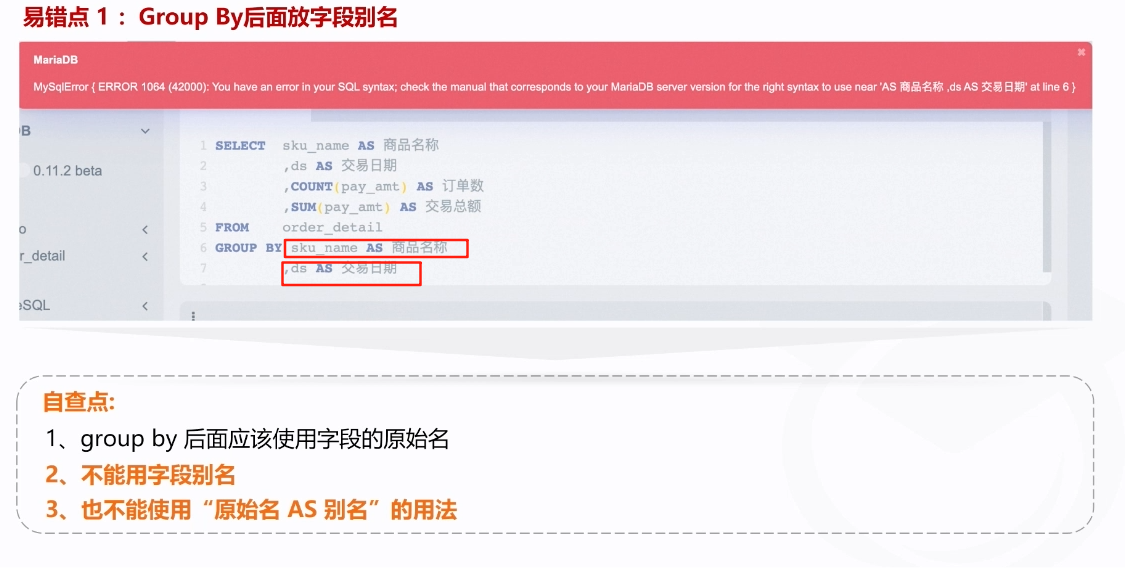
常见使用错误点
1.group by中使用了字段别名
2.where条件设置不对
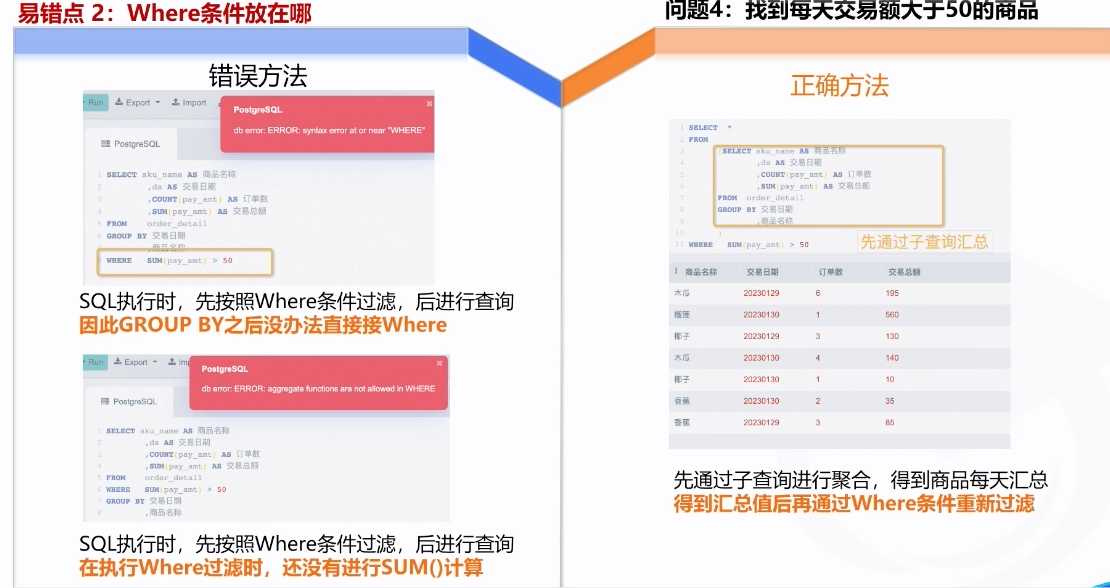
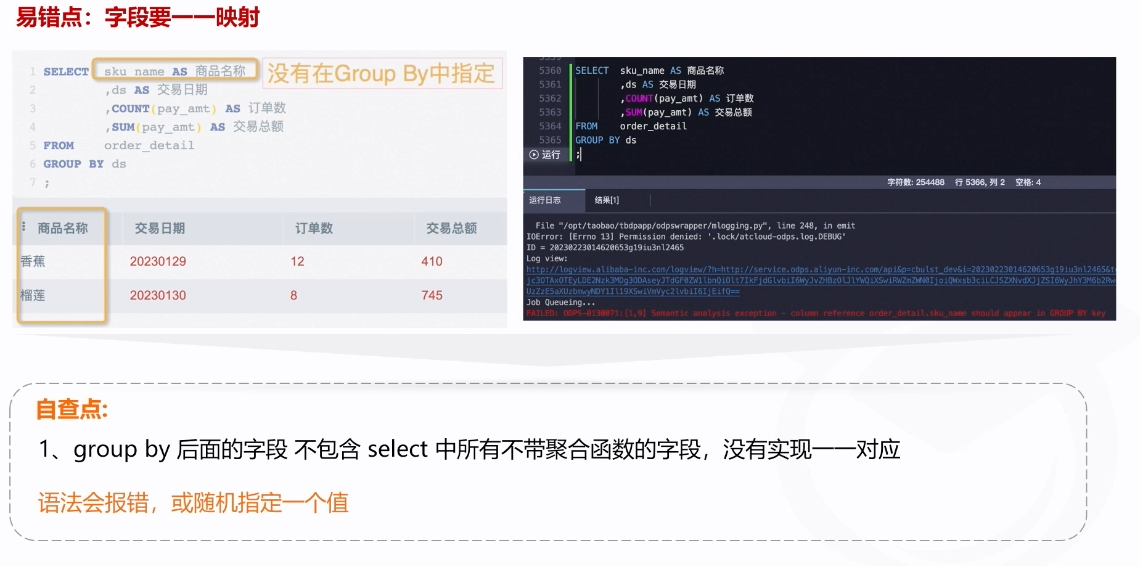
3.selct和group by中的字段未一一映射
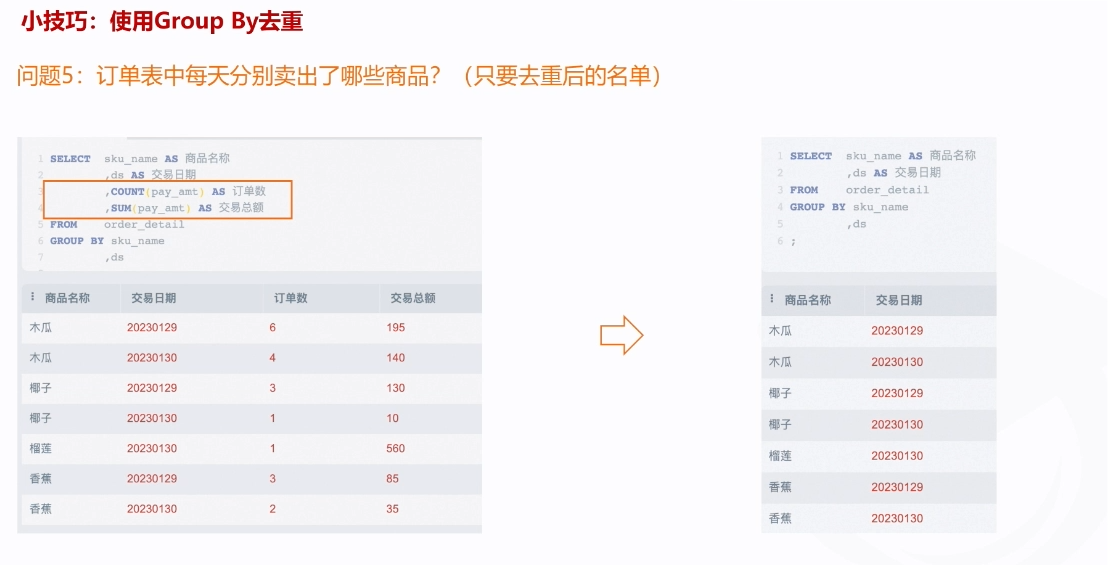
通过group去去重,将同一个名字或者同一个时间的内容聚合成一条数据去去重 ,可以类比成筛选(个人理解,如果有错误请评论区指正)
回顾

示例