前言
上一章深入剖析了GPU资源内存及其管理,vsg中为了提高设备内存的利用率,同时减少内存(GPU)碎片,采用GPU资源内存池机制(vsg::MemoryBufferPools)管理逻辑缓存(VkBuffer)与物理内存(VkDeviceMemory)。本章将深入vsg中vulkan资源的编译(包含视景器编译),着重于当vsg::TransferTask不为空时,vulkan资源的创建与收集过程。
目录
- 1 视景器编译
- 2 VertexIndexDraw的编译
1 视景器编译
如下为Viewer.cpp中387-393行代码,对视景器中的所有vsg::RecordAndSubmitTask对象执行编译任务,其中RecordAndSubmitTask 用于录制其 CommandGraph 列表到 CommandBuffer,并最终将这些命令缓冲区提交到对应的 Vulkan 队列,vsg::Viewer依赖于一个vsg::RecordAndSubmitTask数组,其创建的详细过程在vsg::Viewer::assignRecordAndSubmitTaskAndPresentation函数中体现。
for (auto& task : recordAndSubmitTasks)
{
auto& deviceResource = deviceResourceMap[task->device];
auto& resourceRequirements = deviceResource.collectResources.requirements;
compileManager->compileTask(task, resourceRequirements);
task->transferTask->assign(resourceRequirements.dynamicData);
}如下为数据编译过程中的类图关系:
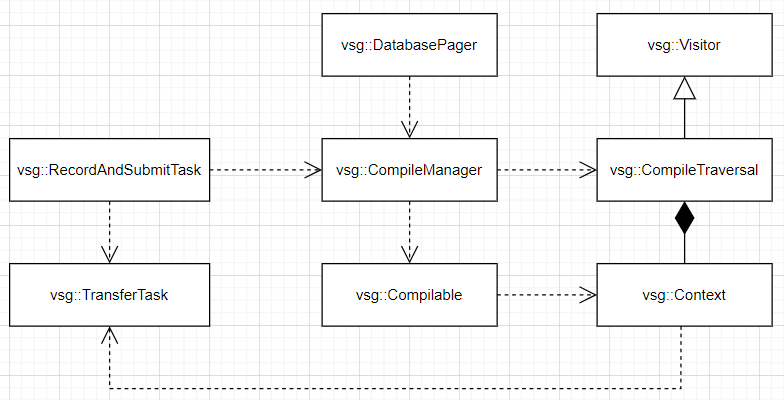
vsg::RecordAndSubmitTask与vsg::DatabasePager依赖于vsg::CompileManager进行数据编译,分别对应视景器的编译、节点动态加载后的编译。vsg::CompileManager是一个辅助类,用于编译与vsg::CompileManager相关联的窗口(vsg::Windows)/帧缓冲区(vsg::Framebuffer)的子图。vsg::CompileManager依赖于vsg::CompileTraversal对子图进行遍历,其继承自vsg::Visitor。CompileTraversal 会遍历场景图(scene graph),并调用所有 StateCommand/Command::compile(..) 方法,以创建 Vulkan 对象、分配 GPU 内存,当vsg::TransferTask对象为空时,将数据传输到 GPU。以BufferInfo.cpp中vsg::createBufferAndTransferData函数为例(280-294行),当vsg::TransferTask对象非空时,将待传输的数据信息记录到vsg::TransferTask对象中:
if (transferTask)
{
vsg::debug("vsg::createBufferAndTransferData(..)");
for (auto& bufferInfo : bufferInfoList)
{
vsg::debug(" ", bufferInfo, ", ", bufferInfo->data, ", ", bufferInfo->buffer, ", ", bufferInfo->offset);
bufferInfo->data->dirty();
bufferInfo->parent = deviceBufferInfo;
}
transferTask->assign(bufferInfoList);
return true;
}vsg::CompileTraversal中存在多个vsg::Context,而vsg::Compileable节点的编译依赖vsg::Context,即同一个vsg::Compileable节点可以依赖多个vsg::Context对象编译多次,以void CompileTraversal::apply(Commands& commands)函数为例:
void CompileTraversal::apply(Commands& commands)
{
CPU_INSTRUMENTATION_L3_NC(instrumentation, "CompileTraversal Commands", COLOR_COMPILE);
for (auto& context : contexts)
{
commands.compile(*context);
}
}vsg::Context的创建赖于vsg::View,如下为函数void CompileTraversal::add(const Viewer& viewer, const ResourceRequirements& resourceRequirements)215-225行:
void apply(View& view) override
{
if (!objectStack.empty())
{
auto obj = objectStack.top();
if (auto window = obj.cast<Window>())
ct->add(*window, transferTask, ref_ptr<View>(&view), resourceRequirements);
else if (auto framebuffer = obj.cast<Framebuffer>())
ct->add(*framebuffer, transferTask, ref_ptr<View>(&view), resourceRequirements);
}
}上方代码ct->add(...)的调用具体实现如下:
void CompileTraversal::add(Window& window, ref_ptr<TransferTask> transferTask, ref_ptr<ViewportState> viewport, const ResourceRequirements& resourceRequirements)
{
auto device = window.getOrCreateDevice();
auto renderPass = window.getOrCreateRenderPass();
auto queueFamily = device->getPhysicalDevice()->getQueueFamily(queueFlags);
auto context = Context::create(device, resourceRequirements);
context->instrumentation = instrumentation;
context->renderPass = renderPass;
context->commandPool = CommandPool::create(device, queueFamily, VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT);
context->graphicsQueue = device->getQueue(queueFamily, queueFamilyIndex);
context->transferTask = transferTask;
if (viewport)
context->defaultPipelineStates.emplace_back(viewport);
else
context->defaultPipelineStates.emplace_back(vsg::ViewportState::create(window.extent2D()));
if (renderPass->maxSamples != VK_SAMPLE_COUNT_1_BIT) context->overridePipelineStates.emplace_back(MultisampleState::create(renderPass->maxSamples));
contexts.push_back(context);
}总结来说,在CompileTraversal创建过程中,通过遍历场景树,遍历所有vsg::View,逐一添加vsg::Context对象,接着利用CompileTraversal遍历场景树,遍历所有vsg::Context对象,逐一编译vsg::Compilable节点。
2 VertexIndexDraw的编译
回到第4章(vulkanscenegraph显示倾斜模型(4)-数据读取-CSDN博客)悬疑列表之一的osg::Geometry转vsg::Command的具体细节,其最终将osg::Geometry转化为了vsg:VertexIndexDraw对象,本节将以vsg::VertexIndexDraw为例,深入节点(继承自vsg::Compilable)的编译过程。
void VertexIndexDraw::compile(Context& context)
{
if (arrays.empty() || !indices)
{
// VertexIndexDraw does not contain required arrays and indices
return;
}
auto deviceID = context.deviceID;
bool requiresCreateAndCopy = false;
if (indices->requiresCopy(deviceID))
requiresCreateAndCopy = true;
else
{
for (auto& array : arrays)
{
if (array->requiresCopy(deviceID))
{
requiresCreateAndCopy = true;
break;
}
}
}
if (requiresCreateAndCopy)
{
BufferInfoList combinedBufferInfos(arrays);
combinedBufferInfos.push_back(indices);
createBufferAndTransferData(context, combinedBufferInfos, VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_INDEX_BUFFER_BIT, VK_SHARING_MODE_EXCLUSIVE);
// info("VertexIndexDraw::compile() create and copy ", this);
}
else
{
// info("VertexIndexDraw::compile() no need to create and copy ", this);
}
assignVulkanArrayData(deviceID, arrays, _vulkanData[deviceID]);
}其中arrays变量记录顶点以及顶点属性,indices变量记录三角网索引。主要过程为创建 Vulkan 对象、分配 GPU 内存(createBufferAndTransferData),而assignVulkanArrayData函数仅将arrays中的Vulkan对象和偏移以数组连续的方式存储在_vulkanData[deviceId]对象中,方便后续vsg:VertexIndexDraw::record函数的调用。创建 Vulkan 对象、分配 GPU 内存过程中的依赖关系如下:
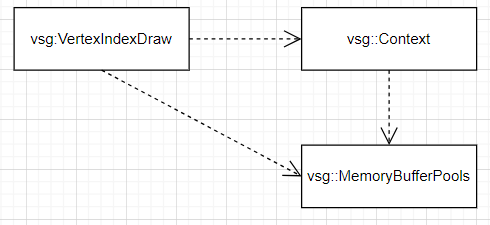
文末:本章在上一章的基础上,深入分析VSG中Vulkan资源的编译过程,并以vsg::VertexIndexDraw为例进行详解。在VSG中,资源编译主要包括创建Vulkan对象和分配GPU内存两个核心步骤。当vsg::TransferTask非空时,程序会将待传输的数据信息记录至该对象,以便后续处理。下一章将重点剖析VSG中的数据传输(Transfer)机制。