做爬虫的朋友都懂:你刚打开一个页面,还没来得及发第二个请求,服务器已经把你当成了“可疑流量”。403、429、验证码、JS挑战……这些“欢迎仪式”你是不是也经常收到?防爬策略越来越猛,采集工程师越来越秃。

但别慌,今天我们不讲高级逆向,只聊聊最基础也最实用的三样宝贝:User-Agent、随机延迟,还有高匿代理IP。
这三者,几乎是任何数据采集工程的“基本操作”,就像盖楼之前你得先打地基一样。
目录
一、User-Agent:别让服务器一眼识破你是机器人
📌 为什么要伪装 User-Agent?
✅ 最佳实践
示例 UA:
Python 静态 UA 示例:
Python 动态 UA 示例:
二、随机延迟:模拟“人”的操作节奏,降低可疑性
🧠 为什么要加入延迟?
⏳ 常见的延迟策略:
🧪 Python 示例代码:
💡 更进一步:结合线程池/协程做延迟控制
三、让你拥有一整个“代理军团”(扩展详解)
代理工作机制简图
🧩 为什么一定要用代理IP?
🛠 ipwo 提供了哪些能力?
🔧 集成示例(requests 配合 ipwo 使用):
🧠 实战优化建议:
🧪 结合 代理IP 的优势:
四、进阶玩法:打造自己的“分布式爬虫 + IP 代理池”系统
一、User-Agent:别让服务器一眼识破你是机器人
在 HTTP 协议中,User-Agent 是浏览器或客户端用来表明自己身份的请求头之一。简单来说,它就像是你浏览网页时递出去的一张“身份证”。
对于反爬虫系统来说,User-Agent 是识别你是不是“真用户”的第一道关卡。如果你用的是 Python 的 requests 模块,它默认的 User-Agent 是这样:
User-Agent: python-requests/2.31.0👮♂️ 这就像你走进图书馆,手里拿着一把电钻——谁都知道你不是来看书的。
📌 为什么要伪装 User-Agent?
-
默认值太显眼:requests 的 UA 太好识别了,几乎所有网站都会立马拒绝。
-
反爬策略过于敏感:有些网站会对不在“白名单”中的 UA 直接返回验证码、JS验证或封禁。
✅ 最佳实践
-
伪装成常见浏览器(Chrome、Edge、Safari)
-
定期更换 UA:最好配合随机列表,让每次请求都像来自不同浏览器用户。
示例 UA:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36Python 静态 UA 示例:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)Python 动态 UA 示例:
from fake_useragent import UserAgent
ua = UserAgent()
headers = {
'User-Agent': ua.random # 每次请求随机挑一个真实浏览器 UA
}
response = requests.get(url, headers=headers)🚨 注意事项:某些服务器会检测 UA 和 IP 是否匹配(比如你来自美国但 UA 是中文浏览器),这时候就要配合 ipwo 的多国家 IP 设置匹配的 UA,提升真实度。
二、随机延迟:模拟“人”的操作节奏,降低可疑性
如果你每 0.1 秒发一次请求,那你不是爬虫你就是 DDOS 攻击者。大多数网站都有速率限制,太频繁的访问会触发封禁机制。即使你伪装得像浏览器,用了最新的 User-Agent,访问频率不正常还是会被踢出局。
🧠 为什么要加入延迟?
-
模拟真实用户的操作节奏,让你的行为看起来“正常”。
-
避免被触发网站的访问速率阈值,防止返回 429 Too Many Requests。
-
给服务器一个喘息机会,减少因高频访问带来的封禁风险。
⏳ 常见的延迟策略:
| 策略类型 | 示例 | 特点 |
|---|---|---|
| 固定延迟 | time.sleep(2) | 简单粗暴,容易识别 |
| 随机延迟 | random.uniform(1, 3) | 更拟人化,推荐使用 |
| 渐进式延迟 | 每次请求延迟时间累加 | 控流,适合密集采集 |
| 节点动态控制 | 基于响应时间动态调整延迟 | 高级玩法,适合大规模部署 |
🧪 Python 示例代码:
import time, random
urls = ['https://example.com/page1', 'https://example.com/page2']
for url in urls:
delay = random.uniform(1, 3)
print(f"等待 {delay:.2f} 秒后请求 {url}")
time.sleep(delay)
response = requests.get(url)⚠️ 实践中建议为不同页面、接口设置不同的延迟策略,比如:搜索接口延迟 5 秒,普通文章页延迟 2 秒。
💡 更进一步:结合线程池/协程做延迟控制
如果你使用多线程或异步框架,仍可以加入延迟机制,保证并发不“炸服”:
-
多线程:在每个线程中加入
sleep(random.uniform(x,y)) -
asyncio:使用
await asyncio.sleep(random.uniform(x,y))
这些策略既保证了效率,也降低了被封禁的概率。
三、让你拥有一整个“代理军团”(扩展详解)
就算你换了 User-Agent,加了延迟,但只要你的请求都从同一个 IP 发出,网站照样会识破你。就像一个人连续几百次敲门,再伪装也会引起怀疑。
这时候,代理 IP 就成了你最需要的工具。这时就需要代理来提供稳定、高匿、易集成的全球 IP 资源。这里推荐一个自用代理:IPWO。其全球代理资源更可以让你坐在家中,畅通无阻获取世界各地一手信息。
这真的是我最近发现的好用工具,通过灵活运用代理工具与服务,能够稳定高效地访问全球技术资源。选对工具、配置得当,就能在激烈的全球技术浪潮中抢占先机,真正做到连接世界、赋能开发。
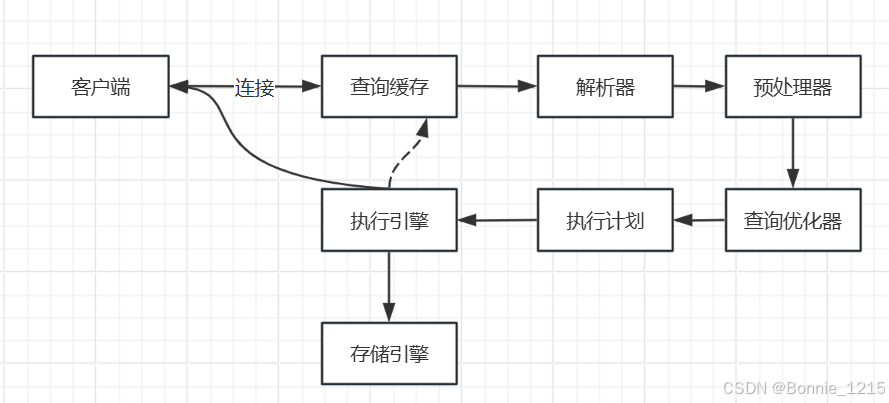
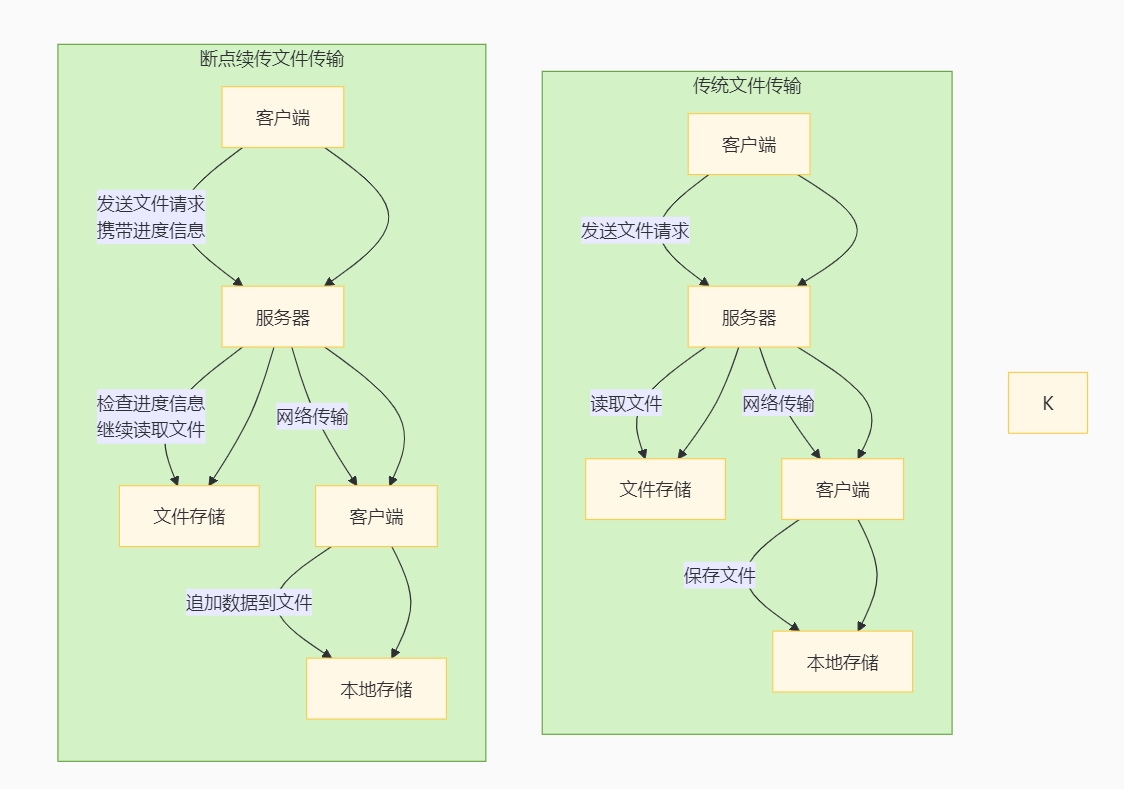
代理工作机制简图
以ipwo代理为例:
🧩 为什么一定要用代理IP?
-
IP 频控是第一杀手:多数网站对同一 IP 的访问频率有限制,一旦超出,就会临时封禁或永久拉黑。
-
目标内容“因地区而异”:比如电商页面、航班、价格等,只有用不同地区 IP 才能采集全量。
-
多线程爬虫易触发风控:如果 10 个线程用同一个 IP,那就等于你拿着喇叭在喊“我在爬数据!”
🛠 ipwo 提供了哪些能力?
| 功能模块 | 描述 |
| 海量代理池 | 提供动态/住宅 IP,按需调用,数量充足,日更新上万 |
| 区域选择 | 可选国家/地区节点,适配不同采集目标(如美、日、新、港) |
| 协议支持 | 支持 HTTP / HTTPS / SOCKS5,兼容 requests/scrapy 等 |
| 实时 API 提取 | 提供稳定提取接口,按需拉取可用 IP,配合脚本使用方便 |
| 高匿名保障 | 防止 DNS 泄露、不暴露真实源 IP,提高爬虫“伪装等级” |
| 并发限制管理 | 控制连接频率,避免“IP重用”导致同一IP短时内请求过多 |
🔧 集成示例(requests 配合 ipwo 使用):
import requests
import random
# ========== 配置信息 ==========
# IPWO网址:https://www.ipwo.net/?ref=hao
# 新用户现在注册赠送500M流量!api提取,各种需求随心选择
API_URL = "https://api.ipwo.com/fetch"
USERNAME = "你的用户名"
PASSWORD = "你的密码"
NUM = 2 # 提取IP数量
REGION = "us" # 可选:如 cn, us, jp, sg,多个国家可用逗号隔开
PROTOCOL = "http" # 可选值:http 或 socks5
RETURN_TYPE = "json" # 或 txt
CUSTOM_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
TARGET_URL = "https://httpbin.org/ip" # 可替换成你想采集的真实目标
# ========== 获取代理 ==========
params = {
"num": NUM,
"regions": REGION,
"protocol": PROTOCOL,
"format": RETURN_TYPE
}
try:
ip_data = requests.get(API_URL, params=params).json()
proxy_list = ip_data.get("data", [])
if not proxy_list:
print("⚠️ 没有获取到代理IP,请检查账号或参数配置")
else:
for proxy_info in proxy_list:
ip = proxy_info["ip"]
port = proxy_info["port"]
proxy_string = f"{USERNAME}:{PASSWORD}@{ip}:{port}"
proxies = {
'http': f"http://{proxy_string}",
'https': f"http://{proxy_string}"
}
print(f"🔍 正在使用代理 {ip}:{port} 请求 {TARGET_URL}")
response = requests.get(TARGET_URL, headers=CUSTOM_HEADERS, proxies=proxies, timeout=10)
print(f"✅ 响应结果:{response.text}")
except Exception as e:
print(f"❌ 获取或请求失败:{e}")
| 参数名 | 类型 | 必选 | 描述 |
|---|---|---|---|
num | int | 是 | 提取IP的数量 |
regions | string | 否 | 指定国家,如 us,jp,cn |
protocol | string | 否 | http 或 socks5 |
format | string | 否 | json 或 txt |
return_type | string | 否 | 返回格式,同上,推荐用 json |
lb | string | 否 | 分隔符控制 |
sb | string | 否 | 自定义分隔符 |
如需要配置请求设备的 IP 到白名单中,可使用以下接口:
api_key = "你的API Key"
white_ip = "你的本地出口IP"
# 添加白名单
requests.get(f"https://www.ipwo.net/api/user/add_white_ip?api_key={api_key}&ips={white_ip}")
# 查询白名单
resp = requests.get(f"https://www.ipwo.net/api/user/white_ip_list?api_key={api_key}")
print(resp.json())
# 删除白名单
requests.get(f"https://www.ipwo.net/api/user/del_white_ip?api_key={api_key}&ips={white_ip}")
💡 小贴士:可以用
while True做 IP 池轮询、失败重试、过期检测,构建一个稳定持久的代理调度模块。
🧠 实战优化建议:
-
设置“每次请求前提取新 IP”逻辑,确保高匿名
-
多线程/协程并发时,每个 worker 拿一个独立 IP
-
给 IP 设置 TTL(有效期)机制,避免重复使用被封 IP
🧪 结合 代理IP 的优势:
| 项目需求 | ipwo 如何应对 |
| 高频采集 | IP 池支持轮换+并发,避免封禁 |
| 数据完整性 | 支持多地区节点,突破区域限制 |
| 接口兼容性 | 全兼容 Python 主流请求库配置 |
| 自动化调度 | 提供 API,可集成至爬虫调度器 |
四、进阶玩法:打造自己的“分布式爬虫 + IP 代理池”系统
如果你有更大的采集需求,比如每天上百万条数据,那建议你考虑:
-
用
Scrapy或aiohttp做协程爬虫框架 -
搭配 Redis/MongoDB 做分布式任务队列
-
写一个自动轮换 IP 的中间件(调用 ipwo API)
-
失败重试机制、代理检测模块、爬虫控制面板等
最终实现自动调度、自动轮换、自动采集的“无人值守爬虫系统”。
做数据采集,从来不是靠一腔热血猛冲。过反爬、抗封锁才是常态作战。本文分享的 User-Agent、延迟策略和代理IP,是爬虫三大基础护法,总而言之,核心思想就是绕过封锁,模拟真人,记得不要给对方网站施加太大压力!
有了这套“三件套”,你可以更安心地采集你所需的数据内容。数据工程师的快乐,从稳定的一条 IP 开始!