单选
1.以下低功耗措施中,哪种不是降低电路翻转率的方法?
A.在不进行算术运算的时候,使这些模块的输入保持不变,不让新的操作数进来
B.采用Gray 码或One‐hot 码作为状态机编码
C.减少电路中的glitch
D.重新安排“if‐else”表达试,可将毛刺或快变化信号移至逻辑锥体的前部
正确答案是:D. 重新安排“if-else”表达式,可将毛刺或快变化信号移至逻辑锥体的前部
以下是详细分析:
低功耗设计与电路翻转率
在数字电路中,动态功耗主要由信号翻转(即逻辑电平的变化)引起。降低电路翻转率是减少动态功耗的重要手段之一。以下是对各选项的分析:
A. 在不进行算术运算的时候,使这些模块的输入保持不变,不让新的操作数进来
是降低电路翻转率的方法:
如果模块的输入保持不变,则输出也不会发生变化,从而避免了不必要的翻转。
这是一种有效的低功耗措施。
B. 采用 Gray 码或 One-hot 码作为状态机编码
是降低电路翻转率的方法:
Gray 码:相邻状态之间只有一位发生变化,因此状态切换时的翻转次数最少。
One-hot 码:每个状态仅有一个位为 1,其余位为 0。虽然需要更多的触发器,但状态切换时翻转次数较少。
使用这些编码方式可以显著减少状态机翻转率。
C. 减少电路中的 glitch
是降低电路翻转率的方法:
Glitch 是由于组合逻辑的竞争冒险导致的短暂错误信号,会引起额外的翻转。
通过优化逻辑设计、插入寄存器或调整时序,可以减少 glitch,从而降低翻转率。
D. 重新安排“if-else”表达式,可将毛刺或快变化信号移至逻辑锥体的前部
不是降低电路翻转率的方法:
将毛刺或快变化信号移至逻辑锥体的前部,可能会增加后续逻辑门的翻转次数。
毛刺和快变化信号传播到更多逻辑门后,会导致更多的翻转,反而可能增加功耗。
因此,这种方法并不能有效降低电路翻转率。
*2.以下Verilog 代码中,a=12,b=10.则z的运算结果为:
Input [3:0]a;
Input [3:0] b;
output signed [7:0] z;
wire signed [3:0]c;
assign c= a[3:0]b[3:0];
assign z=c;
A.120
B.‐8
C.8
D.‐120
正确答案是:B. -8
以下是详细分析:
代码分析
输入和输出定义
a 和 b 是 4 位的有符号数(signed [3:0])。
a = 12,二进制表示为:1100。
b = 10,二进制表示为:1010。
c 是一个 4 位的有符号中间变量(signed [3:0])。
z 是一个 8 位的有符号输出(signed [7:0])。
计算过程
乘法运算:
Verilog
深色版本
assign c = a[3:0] * b[3:0];
在 Verilog 中,a 和 b 被视为有符号数(signed),因此它们的实际值需要考虑符号位。
a = 12 的二进制表示为 1100,但由于它是有符号数,最高位是符号位。1100 表示的是 -4(以补码形式解释)。
b = 10 的二进制表示为 1010,同样是有符号数,1010 表示的是 -6(以补码形式解释)。
c 是一个 4 位的有符号数(signed [3:0]),而乘法结果 24 的二进制表示为 00011000(8 位)。
截断到 4 位时,只保留低 4 位:1000。
1000 作为有符号数,表示的是 -8(以补码形式解释)。
赋值给 z:
Verilog
深色版本
assign z = c;
z 是一个 8 位的有符号数(signed [7:0]),因此会将 c 的值进行符号扩展。
c = -8 的 4 位二进制表示为 1000,符号扩展到 8 位后为 11111000。
11111000 作为有符号数,仍然表示 -8。
选项分析
A. 120:
错误。c 被截断为 4 位,不可能得到 120。
B. -8:
正确。根据上述分析,z 的最终值为 -8。
C. 8:
错误。c 的值在截断后为负数,z 不可能是正数。
D. -120:
错误。c 的值被截断为 4 位,不可能得到 -120。
3.constraint c_0{
src dist {0:=30, [1:3]:=90};
请问如上表达式约束,src数值为0的概率为多大:( )
A. 0.2
B. 0.25
C. 0.1
D. 0.6
正确答案是:C. 0.1
:= 操作符表示值范围内的每一个值得权重是相同的,:/操作符表示权重平均分到值范围内的每一个值。
Systemverilog 中权重分布由操作符dist实现,有两种形式:“:=”或“:/”。
“:=”表示值的权重是相等的,“:/”表示值的权重是均分的。
权重不用百分比表示,权重和也不一定是100.
例如:
src dist {0:=40; [1:3]:=60;};
即src=0 的概率是 40/220,src=1 的概率是 60/220,是 2 的概率是 60/220,是 3 的概率是
60/220.
再例如:
dst dist {0:/40; [1:3]:/60;};
即dst=0 的概率是 40/100,dst=1 的概率是 20/100,是 2 的概率是 20/100,是 3 的概率是
20/100.
综上:src dist {0:=30; [1:3]:=90;}; dst=0 的概率是 30/(90*3+30)=30/300=0.1
4.分析下面的一段程序,正确的打印结果是:
fork
begin
#20
$ display(“A”);
end
begin
#10
$ display(“B”);
end
join_none
#5
$ display(“C”);
A.CBA
B. BCA
C.ABC
D.C
正确答案是:A.CBA
程序分析
在 SystemVerilog 中,fork…join_none 是一种并发控制结构。以下是代码的逐步解析:
Systemverilog
深色版本
fork
begin
#20
$display("A");
end
begin
#10
$display("B");
end
join_none
#5
$display("C");
关键点
fork…join_none 的语义:
fork…join_none 启动多个线程并立即返回,不会等待这些线程完成。
在 fork…join_none 内部启动的线程会独立运行,并按照各自的延迟执行。
主进程与子线程的关系:
主进程(即 fork…join_none 之后的代码)会继续执行,不受子线程的影响。
子线程的延迟时间是独立于主进程的。
时间轴分析:
程序的时间轴如下:
#5:主进程打印 “C”。
#10:第一个子线程打印 “B”。
#20:第二个子线程打印 “A”。
逐步执行
fork…join_none 启动两个子线程:
第一个子线程:
Systemverilog
深色版本
begin
#20
$display(“A”);
end
延迟 20 个时间单位后打印 “A”。
第二个子线程:
Systemverilog
深色版本
begin
#10
$display(“B”);
end
延迟 10 个时间单位后打印 “B”。
主进程继续执行:
Systemverilog
深色版本
#5
$display(“C”);
主进程延迟 5 个时间单位后打印 “C”。
时间轴上的事件顺序:
时间 = 5:主进程打印 “C”。
时间 = 10:第二个子线程打印 “B”。
时间 = 20:第一个子线程打印 “A”。
打印结果
根据时间轴上的事件顺序,打印结果是:
深色版本
C
B
A
因此,正确的答案是:A. CBA
选项分析
A. CBA:
正确。打印顺序为 C -> B -> A。
B. BCA:
错误。C 应该最先打印,而不是 B。
C. ABC:
错误。C 应该最先打印,而不是 A。
D. C:
错误。虽然 C 最先打印,但后续的 B 和 A 也会被打印。
5.下面有关Cache的说法哪一个是不正确的?
A. 设置Cache的理论基础,是程序访问的局部生原理
B. Cache 与主存统一编址,Cache的地址空间属于主存的一部分
C. 设置Cache 的目的,是解决CPU和主存之间的速度匹配问题
D. Cache 的功能匀由硬件实现,对程序员是透明的
正确答案是:B. Cache 与主存统一编址,Cache的地址空间属于主存的一部分
Cache的基本概念
Cache是一种高速缓存存储器,位于CPU和主存之间,用于暂时存放CPU频繁访问的数据和指令,以提高数据访问速度。下面是对每个选项的具体分析:
A. 设置Cache的理论基础,是程序访问的局部性原理
正确:
局部性原理包括时间局部性和空间局部性。时间局部性指的是如果一个信息项正在被访问,那么在不久的将来它很可能再次被访问;空间局部性指的是如果一个存储位置被引用了,那么程序很可能很快会引用邻近的位置。
这是设计Cache的基础理论。
B. Cache与主存统一编址,Cache的地址空间属于主存的一部分
不正确:
在大多数系统中,Cache并不与主存统一编址。Cache有自己的地址映射机制(直接映射、全相联或组相联),通过这种方式,Cache可以快速访问数据而不必占用主存的地址空间。
Cache中的数据是从主存中复制而来,并不是主存地址空间的一部分。
C. 设置Cache的目的,是解决CPU和主存之间的速度匹配问题
正确:
主存的访问速度远低于CPU的工作频率,设置Cache的主要目的是为了减少CPU等待主存数据的时间,从而提高整体性能。
D. Cache的功能均由硬件实现,对程序员是透明的
正确:
Cache的操作是由硬件自动管理的,包括数据的加载、替换等操作,程序员无需关心这些细节,因此对于程序员来说是透明的。
6.对于独立复位的模块,只需要考虑对后级模块的影响,无需考虑对前级模块的影响。
A.正确
B.错误
正确答案是:B. 错误
独立复位模块的影响
在数字电路设计中,复位信号用于将模块的内部状态初始化为已知值。对于具有独立复位功能的模块,需要同时考虑其对前级模块和后级模块的影响。以下是对该问题的分析:
- 复位信号的基本作用
复位信号通常分为两种:
同步复位:复位操作与系统时钟同步。
异步复位:复位操作不依赖于时钟,随时可以生效。
独立复位指的是某个模块的复位信号与其他模块的复位信号无直接关联。 - 对后级模块的影响
当一个模块被复位时,其输出可能会发生变化(例如被清零或设置为某个默认值)。
这种变化会直接影响到后级模块的输入信号,从而可能引发后级模块的状态变化。
因此,必须考虑复位对后级模块的影响。 - 对前级模块的影响
虽然复位信号本身是独立的,但复位后的模块行为可能会影响前级模块。
例如:
如果复位后的模块停止接收数据(如 FIFO 缓冲区被清空),前级模块可能会因为无法继续发送数据而被阻塞。
如果复位后的模块改变了某些控制信号(如握手信号),这可能会导致前级模块的行为异常。
因此,也需要考虑复位对前级模块的影响。 - 结论
独立复位的模块不仅会影响后级模块,还可能间接影响前级模块。
忽略对前级模块的影响可能导致设计中的潜在问题(如死锁、数据丢失等)。
选项分析
A. 正确:
错误。独立复位的模块需要同时考虑对前级和后级模块的影响。
B. 错误:
正确。题目说法错误,复位模块的设计需要全面考虑前后级的影响。
7.System Verilog 中,下面那种数组在使用前需要先执行new操作( )
A. Dynamic arrays
B. Associative arrays
C. packed array
D. 多维数组
正确答案是:A. Dynamic arrays - Dynamic Arrays(动态数组)
特点:
动态数组的大小在声明时未指定,而是在运行时通过 new 操作符分配。
动态数组的大小可以动态调整(通过重新调用 new)。
使用前需要执行 new 操作:
在使用动态数组之前,必须先通过 new 指定其大小。例如:
Systemverilog
深色版本
int dyn_array[]; // 声明一个动态数组
initial begin
dyn_array = new[10]; // 分配大小为 10
end - Associative Arrays(关联数组)
特点:
关联数组是一种稀疏数组,使用键值对存储数据。
键可以是整数、字符串或其他数据类型。
不需要执行 new 操作:
关联数组在声明后即可直接使用,无需显式分配空间。例如:
Systemverilog
深色版本
int assoc_array[string]; // 声明一个关联数组
initial begin
assoc_array[“key1”] = 10; // 直接赋值
end - Packed Array(打包数组)
特点:
打包数组是一种固定大小的数组,通常用于表示位宽较紧凑的数据结构。
打包数组的大小在声明时确定,无法动态调整。
不需要执行 new 操作:
打包数组在声明时已分配空间,可以直接使用。例如:
Systemverilog
深色版本
bit [3:0] packed_array [0:3]; // 声明一个打包数组
initial begin
packed_array[0] = 4’b1010; // 直接赋值
end - 多维数组
特点:
多维数组可以是固定大小的数组,也可以是动态数组或关联数组的组合。
如果多维数组的维度是固定的,则不需要 new 操作;如果是动态数组的一部分,则需要 new 操作。
是否需要 new 操作取决于具体实现:
例如:
Systemverilog
深色版本
int fixed_array[2][3]; // 固定大小的二维数组,不需要 new
int dyn_array[][]; // 动态二维数组,需要 new
initial begin
dyn_array = new[2]; // 分配第一维
foreach (dyn_array[i]) begin
dyn_array[i] = new[3]; // 分配第二维
end
end
选项分析
A. Dynamic arrays:
正确。动态数组在使用前需要通过 new 操作分配空间。
B. Associative arrays:
错误。关联数组不需要 new 操作,声明后即可直接使用。
C. packed array:
错误。打包数组是固定大小的数组,声明时已分配空间,不需要 new 操作。
D. 多维数组:
错误。多维数组是否需要 new 操作取决于其实现方式。如果包含动态数组部分,则需要 new;否则不需要。
8.System Verilog 中,下面哪种数组在使用前需要执行new操作( )
a.压缩数组
b.联合数组
c.动态数组
d.多维数组
正确答案是:c. 动态数组
以下是详细分析:
SystemVerilog 中的数组类型
在 SystemVerilog 中,数组分为多种类型,不同类型的数组在使用时的要求不同。以下是对选项中提到的数组类型的分析:
a. 压缩数组(Packed Array)
特点:
压缩数组是一种固定大小的数组,通常用于表示紧凑的数据结构。
它的大小在声明时确定,无法动态调整。
是否需要 new 操作:
不需要。压缩数组在声明时已经分配了空间,可以直接使用。
示例:
Systemverilog
深色版本
bit [3:0] packed_array [0:3]; // 声明一个压缩数组
initial begin
packed_array[0] = 4’b1010; // 直接赋值
end
b. 联合数组(Associative Array)
特点:
联合数组是一种稀疏数组,使用键值对存储数据。
键可以是整数、字符串或其他数据类型。
是否需要 new 操作:
不需要。联合数组在声明后即可直接使用,无需显式分配空间。
示例:
Systemverilog
深色版本
int assoc_array[string]; // 声明一个联合数组
initial begin
assoc_array[“key1”] = 10; // 直接赋值
end
c. 动态数组(Dynamic Array)
特点:
动态数组的大小在声明时未指定,而是在运行时通过 new 操作符分配。
动态数组的大小可以动态调整(通过重新调用 new)。
是否需要 new 操作:
需要。在使用动态数组之前,必须先通过 new 指定其大小。
示例:
Systemverilog
深色版本
int dyn_array[]; // 声明一个动态数组
initial begin
dyn_array = new[10]; // 分配大小为 10
end
d. 多维数组(Multidimensional Array)
特点:
多维数组可以是固定大小的数组,也可以是动态数组或联合数组的组合。
如果多维数组的维度是固定的,则不需要 new 操作;如果是动态数组的一部分,则需要 new 操作。
是否需要 new 操作:
固定大小的多维数组不需要 new 操作。
包含动态数组的多维数组需要 new 操作。
示例:
Systemverilog
深色版本
int fixed_array[2][3]; // 固定大小的二维数组,不需要 new
int dyn_array[][]; // 动态二维数组,需要 new
initial begin
dyn_array = new[2]; // 分配第一维
foreach (dyn_array[i]) begin
dyn_array[i] = new[3]; // 分配第二维
end
end
选项分析
a. 压缩数组:
错误。压缩数组是固定大小的数组,声明时已分配空间,不需要 new 操作。
b. 联合数组:
错误。联合数组不需要 new 操作,声明后即可直接使用。
c. 动态数组:
正确。动态数组在使用前需要通过 new 操作分配空间。
d. 多维数组:
错误。是否需要 new 操作取决于其实现方式。如果包含动态数组部分,则需要 new;否则不需要。
9.下列哪个不是Verilog系统函数( )
A. $ finish
B. $ head
C. $ time
D. $ write
正确答案是:B. $ head
以下是详细分析:
Verilog 系统函数
Verilog 提供了一些内置的系统函数(以 $ 开头),用于执行特定的操作,如仿真控制、文件操作、时间获取等。以下是对选项中提到的系统函数的分析:
A. $finish
功能:
$finish 是一个标准的 Verilog 系统任务,用于终止仿真。
它会立即停止仿真并退出。
示例:
Verilog
深色版本
initial begin
#100; // 延迟 100 时间单位
$finish; // 终止仿真
end
结论:$finish 是合法的 Verilog 系统函数。
B. $head
功能:
h
e
a
d
并不是
V
e
r
i
l
o
g
的标准系统函数或任务。在
V
e
r
i
l
o
g
或
S
y
s
t
e
m
V
e
r
i
l
o
g
中没有这样的定义。结论:
head 并不是 Verilog 的标准系统函数或任务。 在 Verilog 或 SystemVerilog 中没有这样的定义。 结论:
head并不是Verilog的标准系统函数或任务。在Verilog或SystemVerilog中没有这样的定义。结论:head 不是合法的 Verilog 系统函数。
C. $time
功能:
$time 是一个标准的 Verilog 系统函数,用于返回当前的仿真时间。
返回值是一个整数,表示从仿真开始到当前的时间单位。
示例:
Verilog
深色版本
initial begin
#50;
$display("Current simulation time: %0d", $time); // 输出当前仿真时间
end
结论:$time 是合法的 Verilog 系统函数。
D. $write
功能:
$write 是一个标准的 Verilog 系统任务,用于将信息输出到仿真器的标准输出设备(如终端)。
它与 $display 类似,但不会在输出后自动换行。
示例:
Verilog
深色版本
initial begin
$write("Hello, ");
$write("World!"); // 输出 "Hello, World!",不会换行
end
结论:$write 是合法的 Verilog 系统函数。
选项分析
A.
f
i
n
i
s
h
:正确。
finish: 正确。
finish:正确。finish 是合法的 Verilog 系统任务。
B.
h
e
a
d
:错误。
head: 错误。
head:错误。head 不是 Verilog 的标准系统函数。
C.
t
i
m
e
:正确。
time: 正确。
time:正确。time 是合法的 Verilog 系统函数。
D.
w
r
i
t
e
:正确。
write: 正确。
write:正确。write 是合法的 Verilog 系统任务。
总结
只有 $head 不是 Verilog 的标准系统函数。
正确答案是:B. $head
10.以下Verilog 运算符号中,优先级最高的是?
A.==
B.“
C.!
D.?
正确答案是:C. !
以下是详细分析:
Verilog 运算符优先级
在 Verilog 中,运算符的优先级决定了表达式中运算符的执行顺序。优先级高的运算符会先被计算。以下是对选项中提到的运算符的优先级分析:
A. ==(相等比较运算符)
功能:
== 是关系运算符,用于比较两个操作数是否相等。
优先级:
关系运算符的优先级较低,低于逻辑运算符和单目运算符。
示例:
Verilog
深色版本
if (a == b) // 比较 a 和 b 是否相等
B. “(字符串字面量)
功能:
在 Verilog 中,” 用于定义字符串字面量,例如 “Hello”。
优先级:
字符串字面量不是运算符,因此没有优先级的概念。
结论:
该选项无效。
C. !(逻辑非运算符)
功能:
! 是单目逻辑运算符,用于取反一个布尔值。
如果操作数为真(非零),结果为假;如果操作数为假(零),结果为真。
优先级:
单目运算符(如 !、~、& 等)的优先级最高。
示例:
Verilog
深色版本
if (!a) // 如果 a 为假,则条件成立
D. ?:(条件运算符)
功能:
?: 是条件运算符,用于三元表达式。
格式为:条件 ? 表达式1 : 表达式2。
如果条件为真,结果为表达式1;否则为表达式2。
优先级:
条件运算符的优先级非常低,仅高于赋值运算符。
示例:
Verilog
深色版本
assign result = (a > b) ? a : b; // 如果 a > b,result = a;否则 result = b
优先级总结
在 Verilog 中,运算符优先级从高到低的顺序大致如下:
单目运算符(如 !、~、& 等)
算术运算符(如 *、/、+、- 等)
关系运算符(如 ==、!=、>、< 等)
条件运算符(如 ?:)
赋值运算符(如 =、<=)
由此可见,! 的优先级最高。
选项分析
A. ==:
错误。关系运算符的优先级较低。
B. ":
错误。字符串字面量不是运算符,无优先级。
C. !:
正确。单目逻辑非运算符的优先级最高。
D. ?::
错误。条件运算符的优先级非常低。
总结
在 Verilog 中,优先级最高的运算是单目逻辑非运算符 !。
正确答案是:C. !
11.模块只收敛做到0.75V,提压到0.85V可以正常工作
A.正确
B.错误
背景知识
在数字电路设计中,模块的供电电压(VDD)对其性能和功能有重要影响。以下是一些关键点:
模块收敛(Module Convergence):
指模块在特定电压下能够满足时序要求(Setup/Hold 时间等),即模块在该电压下正常工作。
提压(Voltage Scaling):
指提高供电电压,通常用于改善电路性能(如提高频率或降低延迟)。
工作电压范围:
每个模块都有一个最低工作电压(通常称为“收敛电压”或“最小工作电压”),低于该电压时,模块可能无法正常工作。
提高供电电压可以增强电路的驱动能力,从而改善性能和可靠性。
电压与性能的关系:
降低电压会减少功耗,但可能导致电路速度下降甚至功能失效。
提高电压可以提高电路的速度和稳定性,但也会增加功耗。
提压的作用:
如果一个模块在较低电压下(如 0.75V)无法完全收敛(即不能正常工作),提高电压到更高值(如 0.85V)可能会解决问题。
题目分析
题目描述了一个模块在 0.75V 下只能部分收敛,而在 0.85V 下可以正常工作。
这种情况是合理的,因为提高电压可以:
增强晶体管的驱动能力,使得信号传播更快。
减少噪声和干扰的影响,从而提高电路的稳定性。
确保逻辑门的输出达到预期的电平。
因此,提压到 0.85V 后模块能够正常工作是符合实际情况的。
选项分析
A. 正确:
正确。提高电压可以解决低电压下的收敛问题。
B. 错误:
错误。提压通常可以改善模块的工作状态。
总结
提高电压(从 0.75V 到 0.85V)确实可以使模块正常工作,因此题目说法正确。
正确答案是:A. 正确
12.异步电路都不需要STA进行约束检查
A.是
B.否
正确答案是:A.是
解析:STA都是针对同步电路的
13.在设计状态机时,有两种常用的编码方式:one‐hot code、binary code,前者相对于后者的优势主要体现在
A.实现电路的速度更快
B.实现电路的面积更小
C.编码方式简单
D.实现电路的功耗更低
正确答案是:A. 实现电路的速度更快
以下是详细分析:
状态机编码方式
在设计有限状态机(FSM)时,选择合适的编码方式对于性能、面积和功耗都有重要影响。常用的两种编码方式为One-Hot编码和二进制编码(Binary Code)。
- One-Hot 编码
特点:
在 One-Hot 编码中,每个状态都由一个独立的比特表示,即在任意时刻只有一个比特为高电平(1),其余比特均为低电平(0)。
如果状态机有 N 个状态,则需要 N 个触发器来实现。 - 二进制编码(Binary Code)
One-Hot 编码相对于二进制编码的优势
A. 实现电路的速度更快
正确:
速度优势:One-Hot 编码减少了状态解码所需的逻辑复杂度,因为每个状态仅涉及单个比特的变化。这使得状态转换更加直接和快速,从而提高了电路的整体速度。
简化状态解码:由于每个状态由单一比特表示,判断当前状态非常简单,只需检查对应的比特位即可,无需复杂的译码逻辑。
B. 实现电路的面积更小
错误:
面积劣势:One-Hot 编码通常需要更多的触发器(N 个状态需要 N 个触发器)。因此,One-Hot 编码往往占用更大的硬件资源,导致电路面积增加。
C. 编码方式简单
部分正确:
编码方式:虽然从概念上看,One-Hot 编码较为直观(每个状态对应一个比特),但考虑到实际应用中的状态数量,其编码并不一定比二进制编码简单。例如,在具有大量状态的情况下,管理 One-Hot 编码的状态转换可能变得复杂。
D. 实现电路的功耗更低
错误:
功耗方面:One-Hot 编码由于使用了更多的触发器,可能会消耗更多静态功耗。此外,每次状态转换时,One-Hot 编码会导致多个触发器的状态变化,尽管这些变化通常是简单的,但与二进制编码相比,不一定能保证更低的动态功耗。
选项分析
A. 实现电路的速度更快:
正确。One-Hot 编码通过减少状态解码的复杂性,可以加快状态转换速度。
B. 实现电路的面积更小:
错误。One-Hot 编码通常需要更多的触发器,导致电路面积增加。
C. 编码方式简单:
部分正确,但从整体设计复杂度来看,并不总是更简单。
D. 实现电路的功耗更低:
错误。One-Hot 编码可能导致更高的静态和动态功耗。
总结
One-Hot 编码相对于二进制编码的主要优势在于能够提高电路的速度。
正确答案是:A. 实现电路的速度更快。
14.对于相同位数输入的变量比较器,大于和小于的面积是一样的
A.对
B.错误
正确答案是:A. 对
以下是详细分析:
比较器的基本原理
比较器是一种数字电路,用于比较两个输入变量的大小,并输出比较结果(如大于、小于或等于)。对于相同位数的输入变量,比较器的设计通常具有对称性。
大于和小于的逻辑实现
比较器的结构:
假设输入变量为 A 和 B,它们的位宽均为 n。
比较器会逐位比较 A 和 B 的每一位(从最高有效位到最低有效位),并根据比较结果生成输出信号。
输出信号包括:
A > B(大于)
A < B(小于)
A == B(等于)
对称性:
在硬件实现中,“大于”(A > B)和"小于"(A < B)的逻辑是对称的。
它们的实现方式几乎相同,只是在某些逻辑判断中交换了输入变量的位置。
硬件资源消耗:
由于 “大于” 和 “小于” 的逻辑完全对称,它们的硬件实现所需的面积也是一样的。
实现这些逻辑的操作(如与门、或门、异或门等)数量相同,因此两者的面积相等。
选项分析
A. 对:
正确。对于相同位数的输入变量,“大于” 和 “小于” 的逻辑实现是对称的,因此它们的面积是一样的。
B. 错误:
错误。“大于” 和 “小于” 的硬件实现完全对称,面积没有差异。
总结
对于相同位数输入变量的比较器,“大于” 和 “小于” 的逻辑实现对称,因此它们的面积是一样的。
正确答案是:A. 对
15.有关综合的说法,以下哪个选项是错误的?
A. 相同的RTL代码,每次综合出来的网表可能是不一样的
B. 综合网表可用于EDA功能仿真
C. casez 是不可综合的
D. 时序逻辑always语句中,if‐else如果else的分支缺乏,会综合成latch
正确答案是:CD. casez 是不可综合的
以下是详细分析:
综合的基本概念
综合(Synthesis)是将寄存器传输级(RTL)代码转换为门级网表的过程。在综合过程中,工具会根据设计规则、约束条件和目标工艺库生成对应的硬件电路。
选项分析
A. 相同的 RTL 代码,每次综合出来的网表可能是不一样的
正确:
综合工具在优化过程中可能会受到多种因素的影响,例如综合工具版本、目标工艺库、综合约束(如时序、面积、功耗等)以及随机种子设置。
这些因素可能导致相同的 RTL 代码在不同次综合中生成稍有不同的网表,但其功能是一致的。
B. 综合网表可用于 EDA 功能仿真
正确:
综合后的网表是门级描述,可以用于功能仿真(Post-Synthesis Simulation)。
功能仿真验证的是综合后的电路是否与原始 RTL 代码的功能一致。
C. casez 是不可综合的
错误:
casez 是完全可综合的!
casez 是 Verilog 中的一种条件分支语句,允许使用 ? 表示无关位(don’t care)。它在综合中非常常用,特别是在处理部分解码或灵活匹配的情况下。
示例:
Verilog
深色版本
casez (input_signal)
4’b1???: output = 1; // 匹配高两位为1的情况
4’b01??: output = 2;
default: output = 0;
endcase
因此,casez 是完全可以被综合工具支持的。
D. 时序逻辑 always 语句中,if-else 如果 else 的分支缺乏,会综合成 latch
在组合块中,if语句:
(1) 分支条件不完全,会产生锁存器。
(2) 分支条件完全,且条件互斥,会产生并行电路,如多路器。
(3) 分支条件完全,且条件非互斥,会产生带有优先级的串行电路。
在时序块中,if语句:
(4) 分支条件不完全,会产生带使能端的D触发器。
条件完全会在D触发器的数据输入端产生如
(2)或(3)的组合电路。
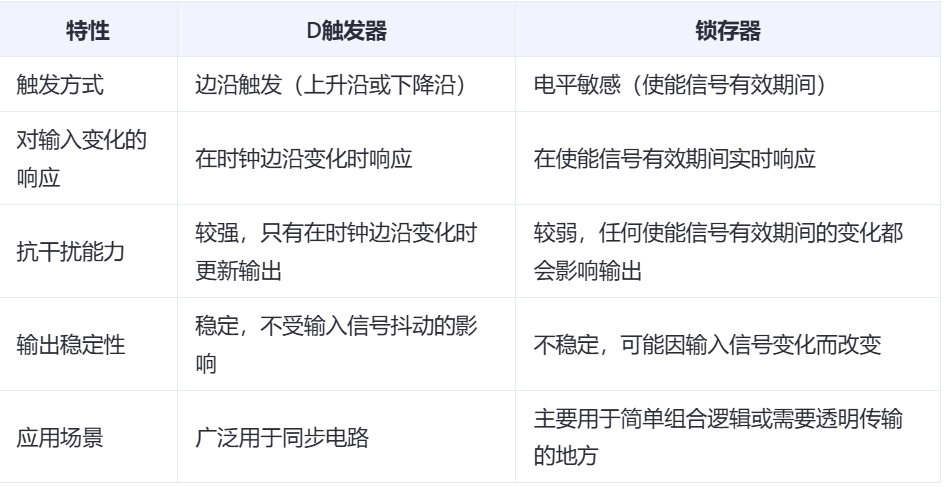
在function 中,if语句
(5)会产生组合电路。条件完全会产生如(2)或(3)的组合电路。条件不完全,则默认其它条件
下被赋值变量的值为0。
总结
选项 C 的说法是错误的,因为 casez 是完全可综合的。
正确答案是:CD. casez 是不可综合的
16.在Verilog 代码中,对有符号数进行比特选择或拼接,其结果是无符号数
A.正确
B.错误
分析:
有符号数的比特选择:当你从一个有符号数中选择某些位时(例如 a[3:0]),这些被选择出来的比特将被视为无符号数。这是因为比特选择操作只是提取出一部分比特,并没有保留原始数值的符号信息。
有符号数的拼接:当使用拼接操作符 {} 将多个信号组合在一起时,结果同样不会自动继承任何部分的符号属性。拼接的结果是一个无符号数。
在文档中提到:
Verilog根据表达式中变量的长度对表达式的值自动地进行调整。
当一个负数赋值给无符号变量如reg时,Verilog自动完成二进制补码计算。
因此,在Verilog中,如果你对有符号数进行比特选择或拼接,结果将是无符号数。
结论:
正确答案是:A. 正确
https://blog.csdn.net/soulermax/article/details/147078428?sharetype=blogdetail&sharerId=147078428&sharerefer=PC&sharesource=soulermax&spm=1011.2480.3001.8118
17.reg [0:31] little_vect; little_vect[0+:8]是多少?
A. little‐vect[0 : 7]
B. 1ittle_vect[7: 0]
正确答案是:A. little_vect[0 : 7]
解析:
举例说明:
reg [31:0] big_vect;
reg [0:31] little_vect;
问题:
big_vect[0 +:8] 转化后一定是 big_vect[较大的数值 : 较小的数值]
little_vect[0 +:8] 转化后一定是 little_vect[较小的数值 : 较大的数值]
reg [31:0] big_vect;为大端,那么转化后的也一定是大端,形式不变
big_vect [0+: 8] 从 0 开始,升序,位宽为 8 ======》》》》》big_vect [7 :0]
little_vect [0 +: 8] 从 0 开始,升序,位宽为 8 ======》》》》》little_vect [0 :7]
big_vect [15 ‐: 8] 从 15 开始,降序,位宽为 8 ======》》》》》big_vect [15 :8]
little_vect [15 ‐: 8] 从 15 开始,降序,位宽为 8 ======》》》》》little_vect [8:15]
18.时序逻辑always语句中,if‐else如果else的分支缺乏,会综合成latch
A.正确
B.错误
正确答案是:B. 错误
以下是详细分析:
时序逻辑中的 if-else 语句
在 Verilog 中,always 块用于描述组合逻辑或时序逻辑。if-else 语句的使用方式会影响综合结果,特别是在时序逻辑中。
- 时序逻辑的特点
时序逻辑通常由触发器(如 D 触发器)实现。
时序逻辑的 always 块通常包含时钟信号(如 posedge clk 或 negedge clk)和可选的异步复位/置位信号。
在时序逻辑中,if-else 结构通常用于控制触发器的更新条件。 - 缺少 else 分支的影响
组合逻辑中的情况:
如果 always 块描述的是组合逻辑(即敏感列表中没有时钟信号),缺少 else 分支会导致综合工具推断出锁存器(latch)。这是因为组合逻辑需要对所有可能的输入条件给出明确的输出值,否则电路会保持前一个状态,形成锁存器。
时序逻辑中的情况:
在时序逻辑中,always 块通常只在时钟边沿触发。如果 if-else 语句中缺少 else 分支,综合工具不会生成锁存器,而是默认保持当前状态不变。
这是因为触发器本身具有存储特性,在未满足 if 条件时,触发器会保持之前的值,而不会引入额外的锁存器。
示例代码
以下是一个典型的时序逻辑代码:
Verilog
深色版本
always @(posedge clk or posedge reset) begin
if (reset)
q <= 0; // 异步复位
else if (enable)
q <= d; // 数据更新
// 缺少 else 分支
end
在这段代码中,else 分支缺失并不会导致锁存器的生成。
当 enable 为低电平时,触发器会保持当前状态不变(即 q 不会被更新),这是触发器的默认行为。
总结
在组合逻辑中,缺少 else 分支可能导致锁存器的生成。
在时序逻辑中,缺少 else 分支不会生成锁存器,而是保持触发器的当前状态。
选项分析
A. 正确:
错误。在时序逻辑中,缺少 else 分支不会生成锁存器。
B. 错误:
正确。在时序逻辑中,缺少 else 分支不会生成锁存器。
最终答案
正确答案是:B. 错误
19.关于功耗,以下描述不正确的是:
A.设计者需要关注平均功耗、峰值功耗和功耗跳变
B.改变芯片的供电电压和时钟频率都会对芯片功耗产生影响
C.对于可关断的摸块,使用时钟门控即可降低功耗
D.芯片的功耗会受实际信号的影响,所以功耗测试需要结合业务来开展。
正确答案是:C. 对于可关断的模块,使用时钟门控即可降低功耗
以下是详细分析:
选项分析
A. 设计者需要关注平均功耗、峰值功耗和功耗跳变
正确:
平均功耗:决定了芯片的整体能耗,对电池供电设备尤为重要。
峰值功耗:影响电源网络设计和散热需求,过高的峰值功耗可能导致电源不稳定或芯片损坏。
功耗跳变:快速的功耗变化会引起电源噪声和电压波动,可能影响电路的稳定性。
因此,设计者确实需要同时关注这三方面。
B. 改变芯片的供电电压和时钟频率都会对芯片功耗产生影响
正确:
功耗与电压的平方成正比,与时钟频率成正比。因此,降低供电电压或时钟频率都可以显著降低功耗。
C. 对于可关断的模块,使用时钟门控即可降低功耗
错误:
时钟门控的作用:通过关闭模块的时钟信号,可以减少动态功耗(因为没有时钟翻转,触发器和组合逻辑不会切换状态)。
但仅靠时钟门控并不能完全降低功耗:
如果模块仍然保持供电,即使没有时钟信号,静态功耗(如漏电流)仍然存在。
对于真正需要关断的模块,通常需要结合电源门控(Power Gating),即直接切断模块的电源,才能有效降低静态功耗。
因此,仅依赖时钟门控并不足以完全降低功耗。
D. 芯片的功耗会受实际信号的影响,所以功耗测试需要结合业务来开展
正确:
芯片的实际功耗与输入信号的特性密切相关。例如,高频切换的信号会导致更高的动态功耗。
因此,为了准确评估功耗,必须结合具体的业务场景和实际工作负载进行测试。
总结
选项 C 的说法不正确,因为对于可关断的模块,仅使用时钟门控无法完全降低功耗。还需要结合电源门控等技术来进一步优化静态功耗。
正确答案是:C. 对于可关断的模块,使用时钟门控即可降低功耗
20.一个D触发器, 其数据Tsu=2ns,Tcq=3ns,Thd=1ns,则此触发器的最高工作频率为: (注:Tsu数据相对时钟的建立时间,Thd数据相对时钟的保持时间,Tcq输出相对时钟的延迟)
A.200MHz
B.500MHz
C.100MEz
D.333MHz
正确答案是:A. 200MHz
Tmin=Tcq+Tgate+Tsu‐Tskew=2+3=5ns
*21.在Verilog HDL 中,timescale 编译器指令格式为: timescale AB.其中 A 指的是时延精度,
B 指的是时延单位。
A. 正确
B. 错误
解析: A是时延单位,B是时延精度。
正确答案是:B. 错误
timescale 指令的格式与含义 在 Verilog HDL 中,timescale 编译器指令用于定义仿真中的时间单位和时间精度。其格式为:
Verilog
深色版本
timescale <时间单位> / <时间精度> 时间单位(A): 表示仿真中延迟值(如 #10)的基本单位。 例如,如果时间单位是 1ns,那么 #10 表示 10 纳秒。 时间精度(B): 表示仿真的最小时间分辨率。 时间精度必须小于或等于时间单位。 例如,如果时间精度是 1ps,那么仿真可以分辨到皮秒级的时间变化。 题目分析 题目中说 A 是时延精度,B 是时延单位,这是错误的。 正确的说法是: A 是时延单位。 B 是时延精度。 示例 以下是一个 timescale 的使用示例:
Verilog
深色版本
`timescale 1ns / 1ps
时间单位:1ns,表示延迟值的基本单位是纳秒。
时间精度:1ps,表示仿真可以分辨到皮秒级别。
如果写成:
Verilog
深色版本
`timescale 10ns / 1ns
时间单位:10ns,表示延迟值的基本单位是 10 纳秒。
时间精度:1ns,表示仿真可以分辨到纳秒级别。
总结
根据解析,题目说法错误。
正确答案是:B. 错误
22.reg signed [0:4] b, b=8’sh8f,赋值后 b 的值是多少?
A. 5’h1F
B. 5’h0F
C. 8’h8F
关键点
变量 b 的位宽和符号性
reg signed [0:4] b 表示 b 是一个 5 位有符号寄存器,范围 -16 到 15。
位序 [0:4]:0 是最高位(MSB),4 是最低位(LSB)。
赋值 8’sh8f 的含义
8’sh8f 表示 8 位有符号十六进制数 0x8F。
二进制形式:8’b1000_1111(最高位 1 表示负数)。
十进制值:
原码:1000_1111 → -15(假设符号+数值)。
补码计算:1000_1111 → 取反 0111_0000 → 加 1 → 0111_0001 = -113(正确补码值)。
赋值时的位宽截断
b 是 5 位,8’sh8f 是 8 位,赋值时会发生 截断。
Verilog 截断规则:
直接取低 5 位(8’sh8f 的低 5 位是 0_1111)。
符号性由目标变量决定(b 是 signed,所以截断后的 5’b0_1111 会被视为有符号数)。
截断后的结果
8’sh8f = 8’b1000_1111 → 取低 5 位 0_1111(5’b01111)。
b 是 signed,所以 5’b01111 的十进制值是 +15(最高位 0 为正)。
十六进制表示:5’h0F。
验证
仿真验证(假设 b 是 5 位有符号):
verilog
复制
module test;
reg signed [0:4] b;
initial begin
b = 8’sh8f; // 8’b1000_1111 → 截断为 5’b01111
$display(“b = %h”, b); // 输出 5’h0F
end
endmodule
输出:b = 0f(即 5’h0F)。
选项分析
A. 5’h1F → 5’b11111(-1),错误(未正确截断)。
B. 5’h0F → 5’b01111(+15),正确。
C. 8’h8F → 错误(b 是 5 位,不能是 8 位)。
结论
正确答案是 B. 5’h0F。
reg signed [0:4] b 和 reg signed [4:0] b 的区别
在 Verilog 中,reg signed [0:4] b 和 reg signed [4:0] b 都声明了一个 5 位有符号寄存器变量 b,它们的 数值范围相同(-16 到 15),但在 位序(bit ordering) 和 存储方式 上有区别:
- 位序(Bit Ordering)不同
(1) reg signed [0:4] b
高位在左,低位在右(Big-Endian 风格,类似于书写顺序)。
b[0] 是符号位(MSB),b[4] 是最低位(LSB)。
示例:
verilog
复制
b = 5’sb10110; // 存储为:b[0]=1, b[1]=0, b[2]=1, b[3]=1, b[4]=0
(2) reg signed [4:0] b
低位在左,高位在右(Little-Endian 风格,类似于 C 数组)。
b[4] 是符号位(MSB),b[0] 是最低位(LSB)。
示例:
verilog
复制
b = 5’sb10110; // 存储为:b[4]=1, b[3]=0, b[2]=1, b[1]=1, b[0]=0
2. 赋值和访问时的差异
(1) 赋值方式
[0:4] 风格:
verilog
复制
b[0] = 1; // 设置符号位
b[4] = 0; // 设置最低位
[4:0] 风格:
verilog
复制
b[4] = 1; // 设置符号位
b[0] = 0; // 设置最低位
(2) 位选择(Bit-select)
[0:4]:
verilog
复制
wire msb = b[0]; // 取符号位
wire lsb = b[4]; // 取最低位
[4:0]:
verilog
复制
wire msb = b[4]; // 取符号位
wire lsb = b[0]; // 取最低位
3. 对数值的影响
数值计算无区别:
无论是 [0:4] 还是 [4:0],b 的 十进制值相同(由补码决定)。
例如:
verilog
复制
reg signed [0:4] b1 = 5’b10110; // -10
reg signed [4:0] b2 = 5’b10110; // -10
但位序会影响仿真和调试时的观察方式。
- 实际应用建议
推荐使用 [4:0](更常见,与 C 语言数组一致)。
[0:4] 在某些旧代码或特定协议中使用(如某些网络协议采用 Big-Endian)。
避免混用,否则可能导致位序混乱。
总结
特性 reg signed [0:4] b reg signed [4:0] b
位序 b[0]=MSB, b[4]=LSB b[4]=MSB, b[0]=LSB
赋值风格 Big-Endian(高位在前) Little-Endian(低位在前)
数值范围 -16 到 15(相同) -16 到 15(相同)
适用场景 旧代码、某些协议 常见写法,与 C 语言一致
结论:
功能上无区别(数值计算相同)。
位序不同,影响仿真调试时的观察方式。
推荐使用 [4:0],除非有特殊需求。
23.在GVIM编译器中,将全英文的字符串old全部替换成字符串new,正确的命令是:
A. s/o1d/new/
B. s/o1d/new/g
C. s/o1d/new/g
D. s/o1d/new/
:%s/old/new/g
解题步骤
理解操作符:
-
^ 是按位异或(XOR)操作符。
-
是按位取反(NOT)操作符。
计算 a ^ b:
a = 4’b0101 (二进制:0101)
b = 4’b1010 (二进制:1010)
按位异或(XOR)的规则:相同为0,不同为1。
第一位:0 ^ 1 = 1
第二位:1 ^ 0 = 1
第三位:0 ^ 1 = 1
第四位:1 ^ 0 = 1
因此,a ^ b = 4’b1111
计算 ~(a ^ b):
a ^ b = 4’b1111
按位取反(NOT):
~1 = 0
~1 = 0
~1 = 0
~1 = 0
因此,~(a ^ b) = 4’b0000
验证选项:
A. 4’b0000 → 正确
B. 1’b1 → 错误(结果应为4位,且值为0000)
C. 1’b0 → 错误(同上)
D. 4’b1111 → 错误(这是a ^ b的值,不是取反后的值)
可能的误区
忽略按位操作的性质:~和^都是按位操作,不是逻辑操作(逻辑操作会返回1位结果)。
混淆和!:!是逻辑非(返回1位),是按位非(返回与输入相同位宽)。
直接猜测:看到异或后是全1,可能误以为取反后是全0就是D选项(但D是4’b1111,是未取反的值)。
正确答案
A. 4’b0000
25.timescale 1ns/10ps,其中 1ns 代表 time unit,10ps 代表 time precision.
A.正确
B.错误
解题步骤
理解 `timescale:
timescale 是 Verilog 和 SystemVerilog 中的一种编译指令,用于定义仿真时间单位和精度。
语法:timescale <time_unit> / <time_precision>
<time_unit>:仿真时间的基本单位,所有延迟值均基于此单位。
<time_precision>:仿真时间的精度,即仿真器可以处理的最小时间步长。
题目解析:
timescale 1ns/10ps:
1ns(1 纳秒)是 time_unit(时间单位)。
10ps(10 皮秒)是 time_precision(时间精度)。
题目描述“1ns 代表 time unit,10ps 代表 time precision”完全符合 timescale 的定义。
验证选项:
A. 正确 → 题目描述与 timescale 的定义一致。
B. 错误 → 无依据。
可能的误区
混淆 time_unit 和 time_precision 的顺序:
正确的顺序是 time_unit 在前,time_precision 在后。
题目描述顺序正确。
不理解 time_precision 的作用:
time_precision 是仿真器的最小时间步长,不影响 time_unit 的定义。
题目描述未涉及功能,仅涉及定义,因此无需深入。
正确答案
A. 正确
26.generate for 循环语句中使用的标尺变量可定义为integer
A.正确
B.错误
解题步骤
理解 generate for 的作用:
generate for 是 Verilog 中的一种生成块语法,用于在编译时根据条件重复生成硬件结构(如模块实例化、逻辑代码等)。
它的循环变量(即“标尺变量”)必须在生成块中声明,且专门用于控制生成逻辑的迭代。
明确循环变量的类型要求:
Verilog 标准规定:generate for 的循环变量必须声明为 genvar 类型。
例如:
genvar i; // 正确声明
generate
for (i = 0; i < 4; i = i + 1) begin
// 实例化模块或生成逻辑
end
endgenerate
integer 的用途:
integer 是 Verilog 中的一种通用整数类型,主要用于仿真中的行为级建模(如循环计数、临时变量等)。
不能 用于 generate for 循环的索引变量,因为 generate 块需要在编译时展开,而 integer 是动态的、运行时的变量。
验证题目描述:
题目声称“标尺变量可定义为 integer”,这与 Verilog 标准 冲突。
实际开发中,若尝试用 integer 代替 genvar,编译器会报错(例如:Illegal variable declaration in generate loop)。
排除可能的误区:
混淆 genvar 和 integer:
genvar 是静态的、编译时的索引变量,专用于生成块。
integer 是动态的、运行时的变量,用于行为级代码(如 always 块)。
特殊版本的例外?:
无论是 Verilog-2001 还是 SystemVerilog,均严格规定 generate for 的循环变量必须为 genvar 类型,无例外。
需要注意三点:
①generate‐for 语句必须用genvar 关键字定义for 的索引变量;
②for 的内容必须用begin…end 块包起来,哪怕只有一句;
③begin…end 块必须起个名字。
正确答案
B. 错误
理由:
generate for 的循环变量必须声明为 genvar 类型,而非 integer。
试图使用 integer 会导致编译错误。
27.在PerI 脚本中,使用( )退出当前循环
A. last
B. break
C. next
D. exit
解题步骤
理解 Perl 中的循环控制语句:
Perl 提供了多种循环控制语句,用于控制循环的执行流程。
常见的循环控制语句包括:
last:立即退出当前循环(类似于 C 语言中的 break)。
next:跳过当前循环的剩余部分,直接进入下一次循环(类似于 C 语言中的 continue)。
redo:重新执行当前循环,不更新循环变量。
exit:退出整个程序,而不是仅退出循环。
分析选项:
A. last:
last 是 Perl 中用于立即退出当前循环的关键字。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: ….10) { if (i == 5) {
last; # 退出循环
}
print “$i\n”;
}
输出:1 2 3 4(循环在 $i == 5 时退出)。
B. break:
break 是 C 语言中用于退出循环的关键字,但在 Perl 中 无效。
若在 Perl 中使用 break,会导致语法错误。
C. next:
next 用于跳过当前循环的剩余部分,直接进入下一次循环,而不是退出循环。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: …..5) { if (i == 3) {
next; # 跳过本次循环
}
print "KaTeX parse error: Undefined control sequence: \n at position 2: i\̲n̲"; } 输出:1 2 4 5…i == 3 时跳过打印)。
D. exit:
exit 用于退出整个程序,而不是仅退出当前循环。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: …..5) { if (i == 3) {
exit; # 退出程序
}
print “$i\n”;
}
输出:1 2(程序在 $i == 3 时终止)。
验证题目描述:
题目要求“退出当前循环”,last 是唯一符合要求的选项。
其他选项要么无效(break),要么功能不符(next 和 exit)。
排除可能的误区:
混淆 last 和 break:
last 是 Perl 中的关键字,break 是 C 语言中的关键字。
混淆 next 和 last:
next 是跳过当前循环,last 是退出循环。
混淆 exit 和 last:
exit 是退出程序,last 是退出循环。
正确答案
A. last
理由:
last 是 Perl 中用于退出当前循环的关键字,完全符合题目要求。
其他选项要么无效,要么功能不符。
28.多bit 信号的异步处理时,可以用打两拍的方式,也可以用异步fifo
A.正确
B.错误
解题步骤
- 理解异步信号处理的背景
异步信号:来自不同时钟域的信号,其时钟频率和相位关系不确定。
问题:直接传递异步信号可能导致亚稳态(Metastability),即信号在采样时处于不确定状态,导致系统错误。 - 分析多 bit 信号的处理方法
A. 打两拍的方式(双触发器同步器)
原理:将信号通过两级触发器传递,第一级用于减少亚稳态概率,第二级用于稳定信号。
适用场景:
单 bit 信号:效果较好,能有效降低亚稳态风险。
多 bit 信号:不适用,因为多 bit 信号可能存在位间偏移(Bit Skew),导致数据不一致。
例如:8-bit 信号中,某些位可能被新值采样,某些位仍为旧值,导致错误。
B. 异步 FIFO
原理:使用双端口 RAM 和读写指针,通过格雷码(Gray Code)同步读写指针,确保数据跨时钟域传递时的一致性。
适用场景:
多 bit 信号:最佳选择,能有效处理位间偏移和亚稳态问题。
单 bit 信号:也可使用,但通常双触发器同步器更简单高效。
3. 验证题目描述
题目声称“多 bit 信号的异步处理时,可以用打两拍的方式,也可以用异步 FIFO”。
打两拍的方式:不适用于多 bit 信号,因为无法解决位间偏移问题。
异步 FIFO:适用于多 bit 信号,是标准解决方案。
因此,题目描述 不完全正确。
4. 排除可能的误区
混淆单 bit 和多 bit 信号的处理方法:
单 bit 信号:双触发器同步器是标准方法。
多 bit 信号:异步 FIFO 是标准方法。
忽略位间偏移问题:
多 bit 信号不能简单地用双触发器同步器处理,因为位间偏移会导致数据错误。
跨时钟域处理中的信号延展(Pulse Stretching)与核心方法配合
- 信号延展(Pulse Stretching)的作用
信号延展是解决 高速→低速时钟域 单 bit 信号传输的补充技术,核心目的是 确保低速时钟能稳定捕捉高速脉冲。
问题场景:高速时钟域的脉冲宽度可能小于低速时钟周期,导致漏采(例如:100MHz 脉冲传到 10MHz 时钟域)。
解决方法:将高速脉冲展宽至至少 1.5 倍低速时钟周期,再通过双触发器同步器传递。
2. 信号延展与核心方法的配合流程
场景:高速时钟域 → 低速时钟域(单 bit 信号)
延展脉冲:
在高速时钟域,通过计数器或状态机将短脉冲展宽。
例如:原脉冲宽度为 1 个高速周期 → 展宽至 2-3 个低速周期。
// 脉冲展宽示例(展宽到 3 个高速时钟周期)
always @(posedge fast_clk) begin
if (pulse_in) stretch_cnt <= 3;
else if (stretch_cnt > 0) stretch_cnt <= stretch_cnt - 1;
end
assign stretched_pulse = (stretch_cnt > 0);
同步处理:
将展宽后的信号通过 双触发器同步器 传递到低速时钟域。
always @(posedge slow_clk) begin
sync_reg <= {sync_reg[0], stretched_pulse};
end
assign pulse_out = sync_reg[1];
脉冲还原(可选):
若需要恢复原始脉冲宽度,可在低速域检测信号边沿。
多 bit 信号场景
直接使用异步 FIFO,无需信号延展(FIFO 的写指针更新已隐含速率适配)。
3. 低速→高速时钟域的补充技术
场景:低速时钟域 → 高速时钟域(单 bit 信号)
无需延展:高速时钟自然能捕捉低速信号,但需注意:
消抖(Debouncing):若低速信号是机械开关等抖动信号,需在低速域先滤波。
同步器仍必要:直接使用双触发器同步器消除亚稳态。
多 bit 信号
异步 FIFO 是唯一可靠方案,无需额外处理速率差异。
4. 关键配合原则
技术 适用场景 配合方法
信号延展 高速→低速单 bit 短脉冲 延展后 + 双触发器同步器
双触发器同步器 单 bit 信号(任何方向) 直接使用或配合延展
异步 FIFO 多 bit 信号(任何方向) 独立使用,无需额外处理速率差异
5. 反例分析
错误做法:
对多 bit 信号仅使用延展 + 双触发器同步器 → 位间偏移仍会导致数据错误。
对低速→高速信号过度延展 → 增加延迟,无实际收益。
正确流程:
判断信号类型(单 bit / 多 bit)。
判断时钟方向(高速→低速 / 低速→高速)。
选择组合:
单 bit + 高速→低速 → 延展 + 同步器。
多 bit → 异步 FIFO。
总结
信号延展是 高速→低速单 bit 场景 的补充技术,需与双触发器同步器配合;而异步 FIFO 是 多 bit 传输 的终极解决方案,无需依赖延展。实际设计中需根据信号类型和时钟关系选择组合方法。
正确答案
B. 错误
理由:
打两拍的方式 不适用于 多 bit 信号的异步处理,因为它无法解决位间偏移问题。
异步 FIFO 是处理多 bit 异步信号的 标准方法。
因此,题目描述不完全正确。
多选
题目1:initial 和 always 的区别是(多选)
选项:
A. initial 只执行 1 次,always 执行多次
B. initial 不可以被综合,always 可以综合
C. always 中时序和过程语句描述与 initial 相同
解题步骤
1. 理解 initial 和 always 的作用
initial块:- 用于仿真中的初始化操作,仅在仿真开始时执行 一次。
- 不可综合(即不能用于生成实际硬件电路)。
- 示例:
initial begin a = 0; // 初始化信号 a #10; // 延迟 10 个时间单位 a = 1; // 修改信号 a end
always块:- 用于描述硬件行为,根据敏感列表(如时钟边沿或信号变化) 重复执行。
- 可综合(用于生成实际硬件电路)。
- 示例:
always @(posedge clk) begin q <= d; // 在时钟上升沿更新寄存器 q end
2. 分析选项
A. initial 只执行 1 次,always 执行多次
- 正确:
initial仅在仿真开始时执行一次。always根据敏感列表重复执行。
B. initial 不可以被综合,always 可以综合
- 正确:
initial仅用于仿真,不可综合。always可用于描述硬件行为,可综合。
C. always 中时序和过程语句描述与 initial 相同
- 错误:
initial仅执行一次,通常用于初始化或仿真测试。always根据敏感列表重复执行,用于描述硬件行为。- 两者的时序和过程语句描述 不同。
3. 验证题目描述
- 题目要求选择
initial和always的区别。 - 选项 A 和 B 均正确描述了二者的区别。
- 选项 C 错误,可直接排除。
4. 排除可能的误区
- 混淆
initial和always的执行次数:initial只执行一次,always重复执行。
- 混淆综合性质:
initial不可综合,always可综合。
- 混淆功能描述:
initial用于仿真初始化,always用于硬件行为描述。
正确答案
A. initial 只执行 1 次,always 执行多次
B. initial 不可以被综合,always 可以综合
理由:
- A 和 B 均正确描述了
initial和always的区别。 - C 错误,因为
always和initial的时序和过程语句描述不同。
题目回顾2
题目:在设计中,可以被用于进行不同时钟域隔离的 memory 类型为(多选)
选项:
A. two-port Register File
B. single-port RAM
C. single-port Register File
D. dual-port RAM
解题步骤
1. 理解时钟域隔离的需求
- 时钟域隔离:在不同时钟域之间传递数据时,需要避免亚稳态(Metastability)和数据不一致问题。
- 解决方案:使用 双端口存储器(Dual-port Memory),允许两个时钟域独立访问数据。
2. 分析各选项
A. two-port Register File
- Register File:一种基于寄存器的存储器,通常用于小规模数据存储。
- two-port:支持两个端口,可以分别连接到不同时钟域。
- 适用性:可以用于时钟域隔离,但通常容量较小,适合特定场景。
B. single-port RAM
- single-port:只有一个端口,无法同时支持两个时钟域的访问。
- 适用性:不能用于时钟域隔离。
C. single-port Register File
- single-port:只有一个端口,无法同时支持两个时钟域的访问。
- 适用性:不能用于时钟域隔离。
D. dual-port RAM
- dual-port:支持两个独立端口,可以分别连接到不同时钟域。
- 适用性:是时钟域隔离的 标准解决方案,广泛应用于跨时钟域数据传递。
3. 验证题目描述
- 题目要求选择可用于时钟域隔离的 memory 类型。
- 双端口存储器(two-port Register File 和 dual-port RAM)可以满足需求。
- 单端口存储器(single-port RAM 和 single-port Register File)无法满足需求。
4. 排除可能的误区
- 混淆端口数量与功能:
- 只有双端口存储器才能支持两个时钟域的独立访问。
- 忽略存储器的类型:
- Register File 和 RAM 均可用于时钟域隔离,只要它们是双端口的。
正确答案
A. two-port Register File
D. dual-port RAM
理由:
- 只有双端口存储器(two-port Register File 和 dual-port RAM)可以支持不同时钟域的隔离访问。
- 单端口存储器(single-port RAM 和 single-port Register File)无法满足需求。
1. 题目内容(题号:3)
题目内容:有如下的代码,下面 $cast 返回值为 1 的有( )
class A;
endclass;
class B extends A;
endclass;
class C extends B;
endclass;
A a = new(…);
B b = new(…);
C c = new(…);
选项:
A. a = c; $cast(b, a)
B. $cast(b, c)
C. $cast(b, a)
D. a = b; $cast(b, a)
2. 解题步骤
1. 理解 $cast 的作用
$cast是 SystemVerilog 中的动态类型转换操作,用于在运行时检查对象类型是否兼容。- 如果转换成功,返回
1;否则返回0。
2. 分析类继承关系
- 类继承关系:
C extends B extends AC是B的子类,B是A的子类。- 因此:
C对象可以赋值给B或A类型变量(向上转型)。B或A类型变量不能直接赋值给C类型变量(向下转型需$cast)。
3. 逐项分析选项
A. a = c; $cast(b, a)
a = c:向上转型,合法。$cast(b, a):将A类型变量a转换为B类型变量b。a实际指向C对象,C是B的子类,因此转换成功。
- 返回值:
1
B. $cast(b, c)
$cast(b, c):将C类型变量c转换为B类型变量b。C是B的子类,向上转型,合法。
- 返回值:
1
C. $cast(b, a)
$cast(b, a):将A类型变量a转换为B类型变量b。a实际指向A对象,A不是B的子类,转换失败。
- 返回值:
0
D. a = b; $cast(b, a)
a = b:向上转型,合法。$cast(b, a):将A类型变量a转换为B类型变量b。a实际指向B对象,B是B的自身类型,转换成功。
- 返回值:
1
4. 总结
- 返回值为
1的选项:A、B、D - 返回值为
0的选项:C
3. 最终答案
正确答案:A、B、D
理由:
- A、B、D 中的
$cast操作均满足类型兼容性,转换成功,返回1。 - C 中的
$cast操作类型不兼容,转换失败,返回0。
1. 题目内容(题号:4)
题目内容:如下时钟组合中,哪些是同步时钟?
选项:
A. 不同 PLL 产生的相位不同,频率相同的时钟
B. 相同 PLL 产生的 2 分频时钟和 4 分频时钟
C. 同一 PLL 产生的相位相差 180°,频率相同的时钟
D. 不同 PLL 产生的频率不同的时钟
2. 解题步骤
1. 理解同步时钟的定义
- 同步时钟:两个时钟信号具有固定的相位关系,且频率相同或成整数倍关系。
- 关键特征:
- 频率相同或成整数倍关系。
- 相位关系固定(即使有偏移,也是固定的)。
2. 分析各选项
A. 不同 PLL 产生的相位不同,频率相同的时钟
- 分析:
- 频率相同,但相位关系不固定(不同 PLL 可能导致相位漂移)。
- 结论:异步时钟。
B. 相同 PLL 产生的 2 分频时钟和 4 分频时钟
- 分析:
- 频率成整数倍关系(4 分频是 2 分频的 2 倍)。
- 来自同一 PLL,相位关系固定。
- 结论:同步时钟。
C. 同一 PLL 产生的相位相差 180°,频率相同的时钟
- 分析:
- 频率相同,相位关系固定(相差 180°)。
- 结论:同步时钟。
D. 不同 PLL 产生的频率不同的时钟
- 分析:
- 频率不同,且相位关系不固定。
- 结论:异步时钟。
3. 总结
- 同步时钟的选项:B、C
- 异步时钟的选项:A、D
3. 最终答案
正确答案:B、C
理由:
- B 和 C 中的时钟频率相同或成整数倍关系,且相位关系固定,符合同步时钟的定义。
- A 和 D 中的时钟频率相同但相位不固定,或频率不同,属于异步时钟。
好的,后续如果需要输出公式,我会统一采用 Python 代码文本形式。以下是更新后的格式示例:
1. 题目内容(题号:5)
题目内容:影响 CMOS 电路动态功耗的因素有哪些?
选项:
A. 工艺
B. 翻转率
C. 供电电压
D. 温度
2. 解题步骤
1. 理解 CMOS 动态功耗的公式
CMOS 电路的动态功耗(P_dynamic)主要由以下公式决定:
P_dynamic = alpha * C * V**2 * f
其中:
alpha:翻转率(Switching Activity,信号从 0→1 或 1→0 变化的概率)。C:负载电容(与工艺、布线、晶体管尺寸相关)。V:供电电压。f:时钟频率。
2. 分析各选项
A. 工艺
- 影响:工艺决定了晶体管的尺寸、寄生电容
C和漏电特性。 - 是否影响动态功耗:是(工艺影响
C)。
B. 翻转率
- 影响:翻转率
alpha直接决定动态功耗。 - 是否影响动态功耗:是(公式中的
alpha)。
C. 供电电压
- 影响:供电电压
V以平方关系影响动态功耗。 - 是否影响动态功耗:是(公式中的
V**2)。
D. 温度
- 影响:温度主要影响漏电功耗(静态功耗),对动态功耗无直接影响。
- 是否影响动态功耗:否(动态功耗主要由公式中的
alpha,C,V,f决定)。
3. 总结
- 直接影响动态功耗的选项:A(工艺影响
C)、B(翻转率)、C(供电电压)。 - 不直接影响动态功耗的选项:D(温度)。
3. 最终答案
正确答案:A、B、C
理由:
- 工艺(A)、翻转率(B)、供电电压(C)均直接参与动态功耗的计算。
- 温度(D)主要影响静态功耗,不直接影响动态功耗。
注:
- 若题目明确区分动态功耗和静态功耗,温度(D)不选。
- 若题目未明确区分,需结合上下文判断(本题选项 D 不选)。
关于温度对短路功耗的影响
1. 短路功耗的公式
短路功耗(P_short_circuit)的公式为:
P_short_circuit = alpha * f * V_DD * I_peak * t_sc
其中:
alpha:信号翻转率;f:时钟频率;V_DD:电源电压;I_peak:短路电流峰值;t_sc:短路时间。
2. 温度对短路功耗的影响
- 温度升高 → 载流子迁移率降低 →
I_peak下降 → 短路功耗降低。 - 温度升高 → 阈值电压
V_th降低 → 晶体管更容易导通,但迁移率下降的效应通常占主导 → 净效应仍是 短路功耗降低。 - 温度升高 → 电路延迟增大 →
t_sc略微增加,但电流下降更显著 → 总体 短路功耗降低。
3. 结论
- 短路功耗受温度影响(高温时降低),但动态功耗不受直接影响。
- 原题答案(A/B/C)仍正确,因题目可能默认讨论动态功耗(温度不选)。
- 若题目包含短路功耗,需补充说明温度的影响。
最终建议
- 考试/做题:按题目明确范围选择(动态功耗不选 D,短路功耗需考虑 D)。
- 工程实践:高温下总功耗可能因静态功耗(漏电)上升而增加,但动态和短路功耗可能下降。需结合具体工艺数据。
注:本题选项中未明确区分动态与短路功耗,建议按动态功耗理解(不选 D)。若需严谨性,题目应明确功耗类型。
7. 题目内容
Verilog 中关于任务和函数,描述正确的有( )。
1. 解题步骤
1.1 理解任务(Task)和函数(Function)的区别
- 任务(Task):
- 支持时序控制(如
#,@,wait) - 可调用其他任务或函数
- 支持 input/output/inout 端口
- 无返回值
- 支持时序控制(如
- 函数(Function):
- 禁止时序控制(必须单周期完成)
- 仅可调用其他函数
- 必须有 return 返回值
- 仅允许 input 端口
1.2 选项分析
| 选项 | 内容 | 正确性 | 依据 |
|---|---|---|---|
| A | 任务可以调用函数 | ✓ | 任务允许调用无时序控制的函数 |
| B | 函数可以调用函数 | ✓ | 函数可嵌套调用,但需保持纯组合逻辑 |
| C | 任务可以调用任务 | ✓ | 任务支持嵌套调用,但需注意避免无限递归 |
| D | 函数可以调用任务 | ✗ | 函数禁止调用含时序控制的任务(违反单周期执行约束) |
2. 最终答案
正确答案:A、B、C
判题依据:
- 函数调用限制(D错误)是Verilog语法强制约束,违反将导致编译错误
- 任务调用权限(A/C正确)由其支持时序控制的特性决定
- 函数嵌套调用(B正确)需确保无组合逻辑环路
3. 工程注意事项
- 递归风险:任务嵌套调用需设置终止条件(如最大调用深度)
- 仿真性能:函数嵌套层级过多可能导致综合器优化困难
- 代码规范:建议任务/函数调用关系绘制成调用关系图,避免循环依赖
注:SystemVerilog对函数功能有扩展(如void函数),但本题限定Verilog标准语法。
8. 题目内容
逻辑函数可以有的表达式为( )。
1. 解题步骤
1.1 理解逻辑函数的表示形式
逻辑函数是描述输入与输出之间逻辑关系的数学函数,常用以下形式表示:
- 真值表(Truth Table):列出所有输入组合及其对应的输出值。
- 卡诺图(Karnaugh Map):用于简化逻辑表达式的图形化工具。
- 逻辑表达式(Logical Expression):用逻辑运算符(如与、或、非)表示的代数式。
- 组合图(Combinational Diagram):用逻辑门(如与门、或门、非门)组成的电路图。
1.2 分析各选项
| 选项 | 内容 | 正确性 | 依据 |
|---|---|---|---|
| A | 真值表 | ✓ | 真值表是逻辑函数的标准表示形式之一 |
| B | 卡诺图 | ✓ | 卡诺图用于逻辑函数的简化和优化 |
| C | 逻辑表达式 | ✓ | 逻辑表达式是逻辑函数的代数表示形式 |
| D | 组合图 | ✓ | 组合图是逻辑函数的电路实现形式 |
2. 最终答案
正确答案:A、B、C、D
判题依据:
- 真值表、卡诺图、逻辑表达式和组合图均是逻辑函数的有效表示形式
- 每种形式在不同场景下有其独特优势(如真值表用于验证,卡诺图用于简化,逻辑表达式用于分析,组合图用于实现)
3. 工程注意事项
- 真值表:适用于输入变量较少的情况,变量过多时表格规模指数增长
- 卡诺图:适用于简化 4-6 变量的逻辑函数,变量过多时难以绘制
- 逻辑表达式:需注意表达式的简化和优化,避免冗余逻辑
- 组合图:需考虑逻辑门的延迟和功耗,优化电路设计
注:本题选项 D 中的“组合图”通常指逻辑门组成的电路图,是逻辑函数的硬件实现形式。
9. 题目内容
基于FPGA和ASIC芯片设计的差异需要关注的有( )。
1. 解题步骤
1.1 理解FPGA与ASIC的核心差异
| 特性 | FPGA | ASIC |
|---|---|---|
| 可重构性 | 可重复编程 | 固定功能 |
| 开发周期 | 短(直接编程) | 长(需流片) |
| 性能 | 较低(依赖通用逻辑单元) | 高(定制化电路) |
| 功耗 | 较高(静态功耗大) | 低(优化后静态功耗小) |
| 成本 | 单件成本高,无流片费用 | 流片成本高,量产成本低 |
1.2 分析各选项的关键差异
| 选项 | 内容 | FPGA设计特点 | ASIC设计特点 | 差异点 |
|---|---|---|---|---|
| A | 上下电流程 | 需考虑配置加载顺序(如Bitstream加载) | 固定电源时序,需严格满足芯片规格 | FPGA需配置,ASIC需时序验证 |
| B | 时钟频率 | 受布线延迟限制(通常≤500MHz) | 可定制高频电路(可达GHz) | 频率上限差异显著 |
| C | 时钟复位 | 复位信号需同步化处理 | 复位网络需全局优化(低偏斜) | 复位网络设计复杂度不同 |
| D | Memory控制 | 依赖内置Block RAM(固定架构) | 可定制Memory接口(如SRAM/DRAM控制器) | 灵活性不同 |
2. 最终答案
正确答案:A、B、C、D
关键差异说明:
- 上下电流程(A):
- FPGA:需管理配置文件的加载顺序(如先供电再加载Bitstream)。
- ASIC:需严格遵循电源时序要求(如Power-On Reset电路设计)。
- 时钟频率(B):
- FPGA:时钟频率受布线资源和PLL性能限制。
- ASIC:可通过定制时钟树实现更高频率。
- 时钟复位(C):
- FPGA:复位信号需同步化以避免亚稳态。
- ASIC:需全局复位网络优化(如低偏斜复位树)。
- Memory控制(D):
- FPGA:使用固定架构的Block RAM,接口标准化。
- ASIC:可定制Memory接口(如带宽、时序优化)。
3. 工程实践建议
- FPGA设计:
- 优先使用厂商提供的IP核(如Xilinx的Clock Wizard)。
- 避免异步复位,推荐同步复位设计。
- ASIC设计:
- 需进行Sign-off时序分析(如STA)。
- 定制Memory控制器时需考虑工艺库特性(如SRAM时序模型)。
注:FPGA与ASIC在验证方法(如仿真覆盖率要求)、DFT(可测试性设计)等方面也存在显著差异,但本题未涉及。
10. 题目内容
异步电路的处理方式包括( )。
1. 解题步骤
1.1 理解异步电路的处理方法
异步电路的数据传输需要解决亚稳态和信号完整性问题,常用方法包括:
- 握手协议(Handshake Protocol):通过请求(Req)和应答(Ack)信号确保数据安全传输。
- 格雷码(Gray Code)同步:用于多比特信号,每次仅变化1位,降低亚稳态风险。
- 异步FIFO:通过双端口RAM和格雷码指针实现跨时钟域数据缓冲。
- 双触发器同步(2-FF Synchronizer):单比特信号的标准同步方法。
1.2 分析各选项
| 选项 | 内容 | 有效性 | 适用场景 |
|---|---|---|---|
| A | 多bit DMUX同步 | ✗ | DMUX非标准异步处理方法,存在风险 |
| B | 握手协议同步 | ✓ | 适用于控制信号(如Req/Ack) |
| C | 多bit格雷码同步 | ✓ | 适用于状态机或计数器(如异步FIFO指针) |
| D | 异步FIFO同步 | ✓ | 多比特数据流的标准解决方案 |
2. 最终答案
正确答案:B、C、D
排除依据:
- 选项A(DMUX同步):非常规方法,无法保证多比特信号的同步可靠性。
- 其他选项:
- 握手协议(B)适用于控制信号同步。
- 格雷码(C)用于多比特信号的低风险同步。
- 异步FIFO(D)是数据流传输的工业标准方案。
3. 工程注意事项
- 格雷码限制:仅适用于连续变化的信号(如计数器),不适用于随机多比特数据。
- 异步FIFO深度:需满足最坏情况下的数据速率差(
深度 > (写速率 - 读速率) × 最大延迟)。 - 握手协议开销:引入额外的延迟(需2次握手完成传输)。
注:选项D的“影步FIFO”应为“异步FIFO”,可能是笔误。