3.1 Hadoop的运行模式
先去官方看一看Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster.
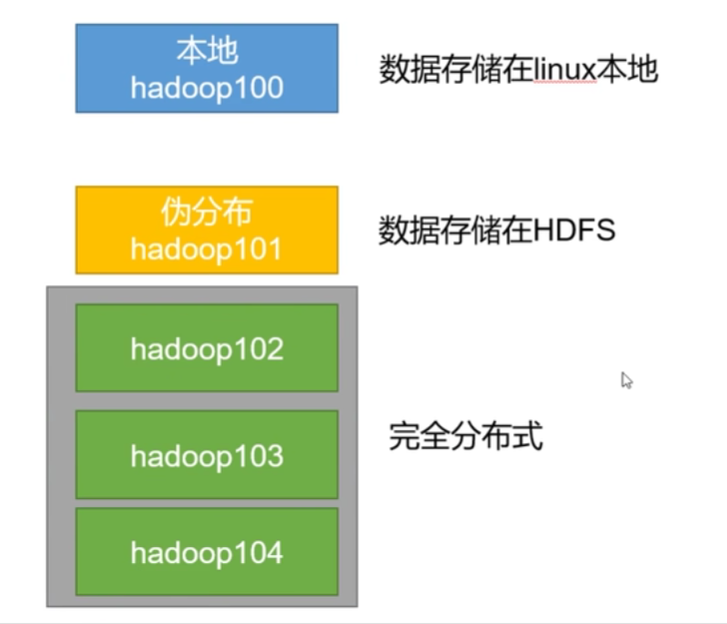
本地模式:数据直接存放在Linux的磁盘上,测试时偶尔用一下
伪分布式:数据存放在HDFS,公司资金不足的时候用
完全分布式:数据存储在HDFS/多台服务器工作,企业中大量使用
3.2 使用一下本地模式的hadoop
现在hadoop 的文件目录下创建一个wcinput的文件夹,然后再wcinput的的目录下创建一个word.txt的文件里面写几个单词
banzhang
bobo
cls cls
ss ss
yangge
然后退回到hadoop的目录下
输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcout wcinput/ ./wcoutputbin目录下的hadoop命令 调用share下的jar 实现单词计数功能然后去指定目录下,就可以看到统计的结果
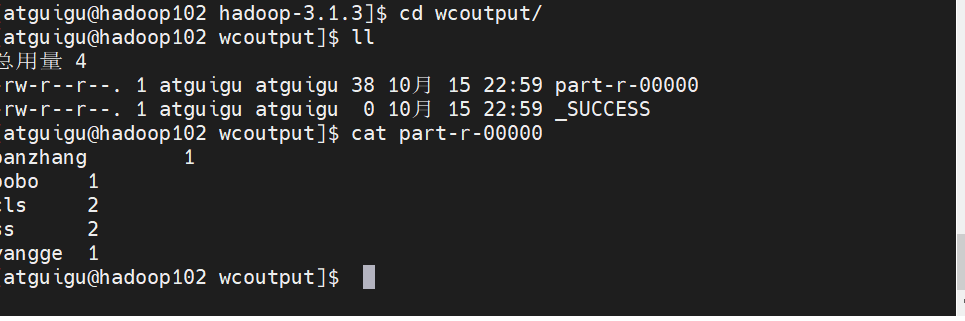
值得一提的是你输出的目录,必须是一个不存在的目录
3.3 完全分布式运行模式
前期准备:
1)准备三台客户机(关闭防火墙、静态IP,主机名称)
2)安装JDK
3)配置环境变量
4)安装hadoop
5)配置环境变量
6)配置集群
7)单节点启动
8)配置ssh
9)群起并测试集群
3.3.1 编写集群分发脚本
1)scp (secure copy)安全拷贝
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝
(2)基本语法
scp -r $pdir/$fname $user@host:$pdir/$fname
命令 递归 要拷贝的文件名/路径 目的地用户@主机:目的地路径/名称具体的使用方法就是
当我们处于hadoop102的服务器时
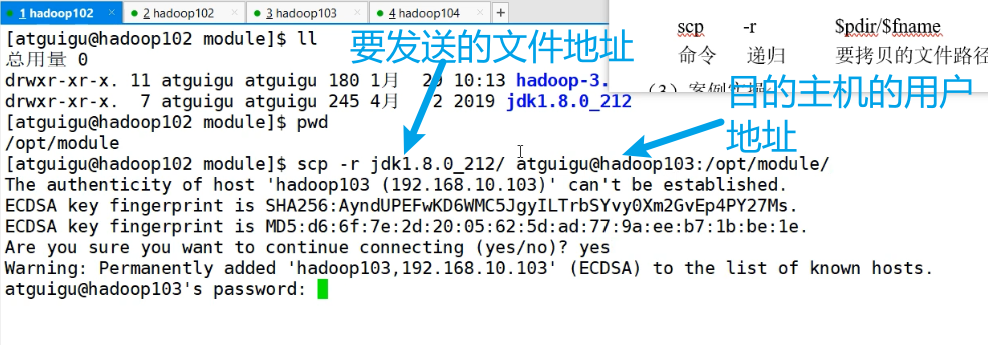
要输入目的主机的账户对应的密码
也可以从对应主机向本地拉取文件,文件所在地址加上用户和地址,
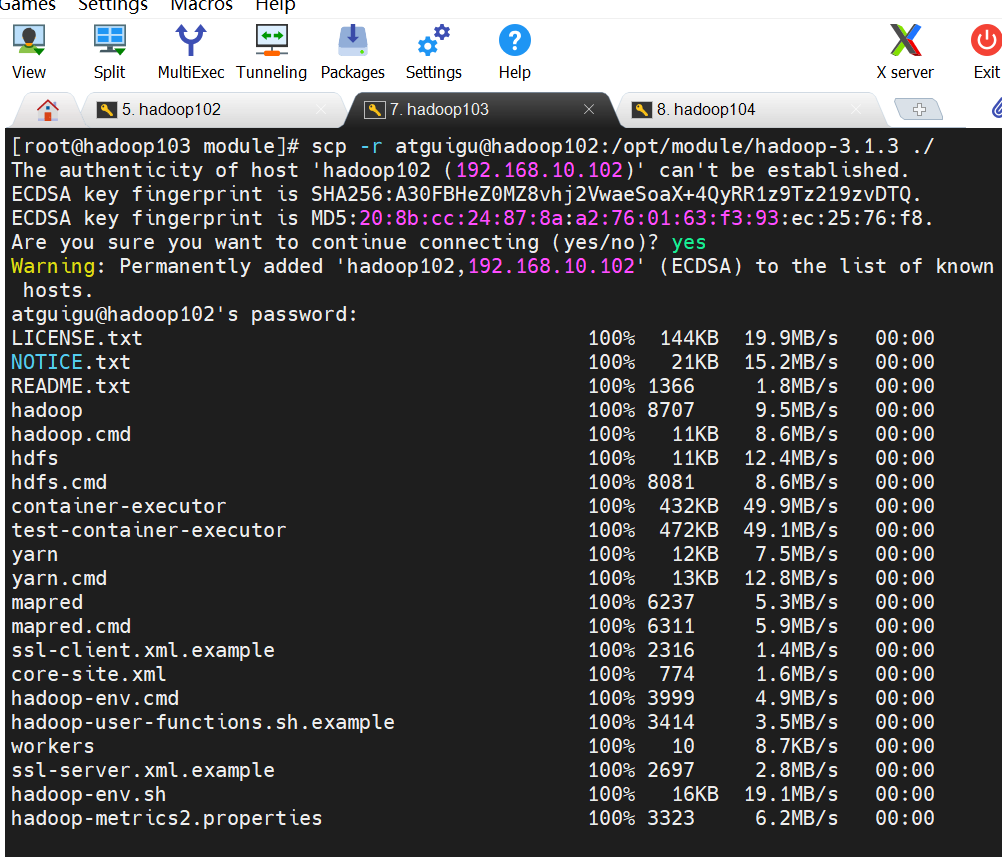
也可以我们在hadoop103主机,从Hadoop102向Hadoop104传输文件

2)rsyc远程同步工具
rsyc的主要用于备份和镜像。具有速度快、避免复制重复相同内容和支持符号连接的优点。
rsyc和scp的主要区别:
用rsyc做文件复制要比scp要快,rsyc只对差异文件做更新。scp是把所有文件都复制过去
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的地址
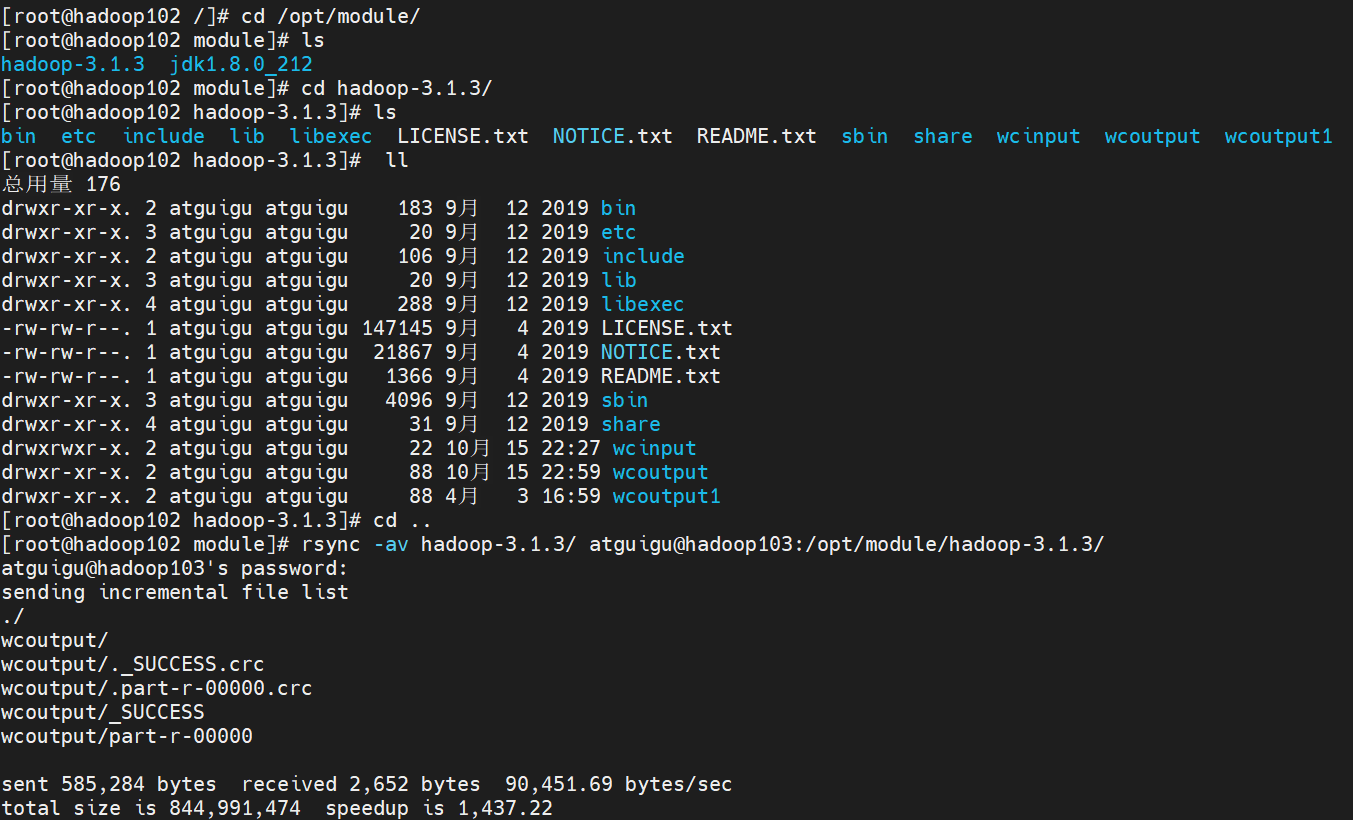
然后我们把hadoop103上的wcoutput1文件给删除了,然后执行一下命令
rsync -av hadoop-3.1.3/ atguigu@hadoop103:/opt/module/hadoop-3.1.3/然后就是在这时候就会只同步存在差异的文件
3)xsync集群的分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt(b)期望脚本
xsync要同步的文件名称
(c)期望脚本在任何路径下都可以实现
只需要脚本放在已经声明的全局环境变量中

(3)在home下创建bin目录然后创建xsync脚本
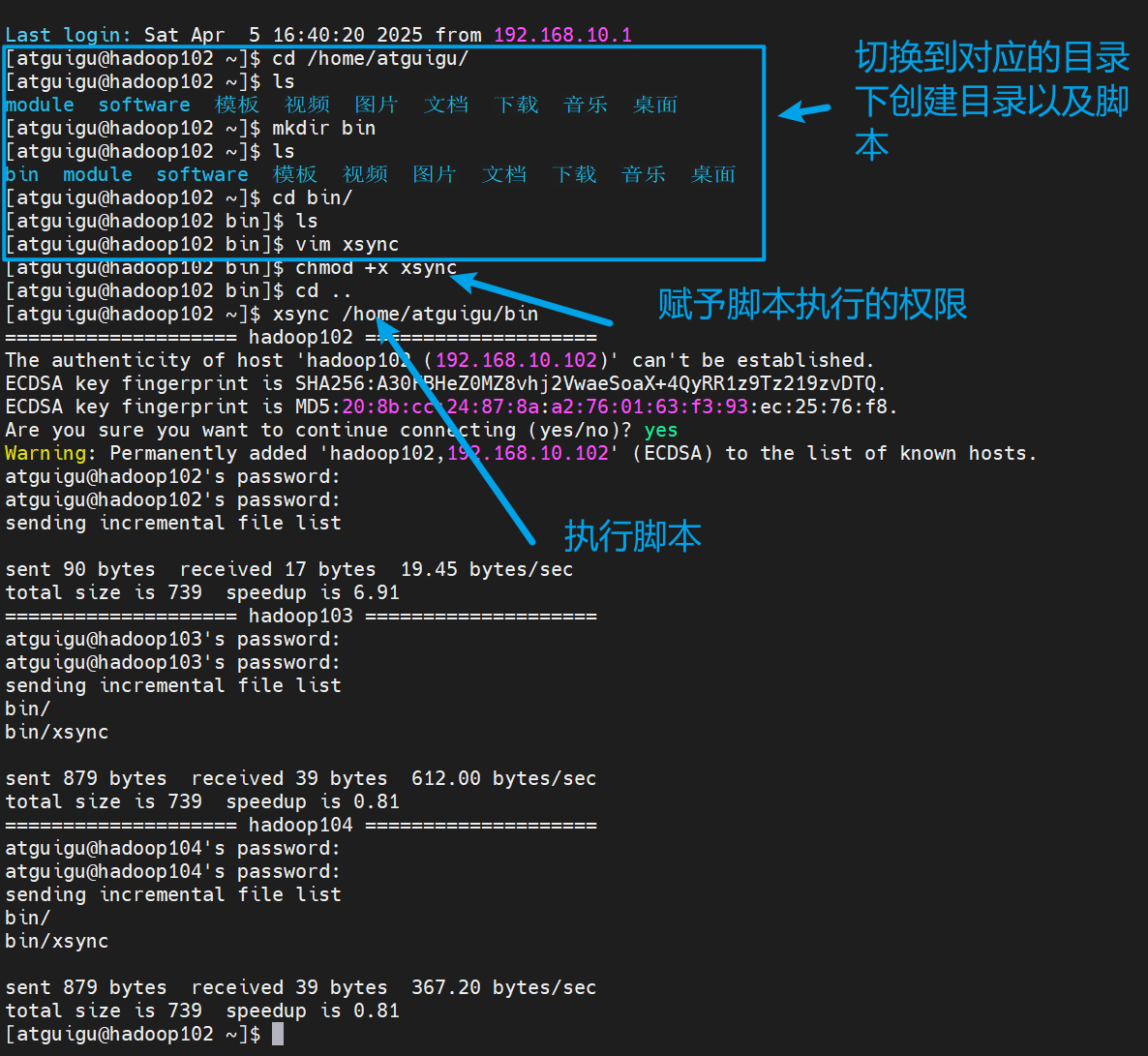
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
#-P就是不报错的意思
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done然后把环境变量也都分发一下
xsync /etc/profile.d/my_env.sh但是在直接分发的时候会发现有一个问题
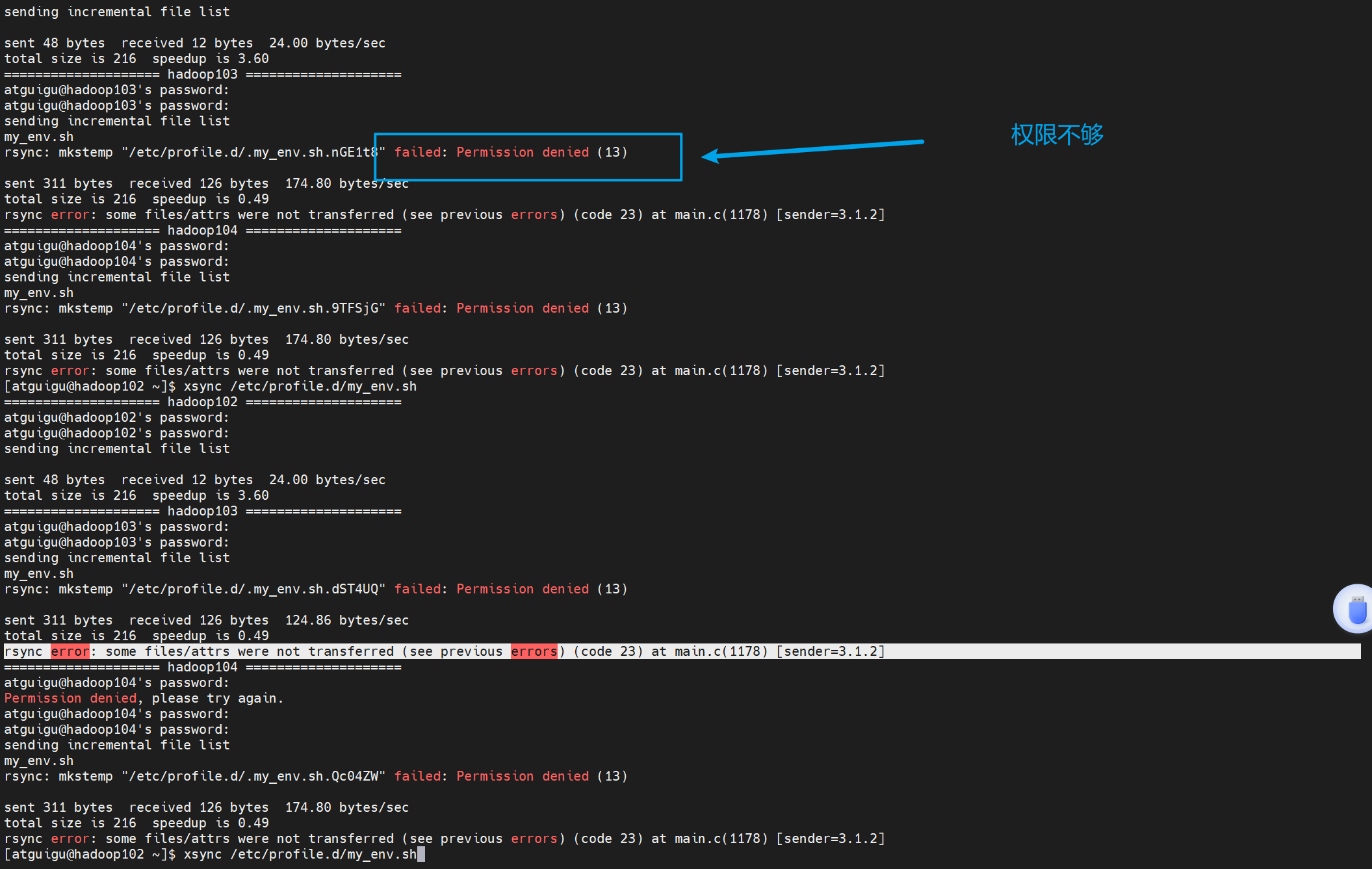
是没有这个文件的,我们就尝试用sudo +命令的形式去执行一下看看

这个的原因就是我们的命令是在/home/atguigu/bin目录下的,root用户找不到这个命令,所以就会报错,那我们就告诉root用户我们的命令在哪里,让他来执行
sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh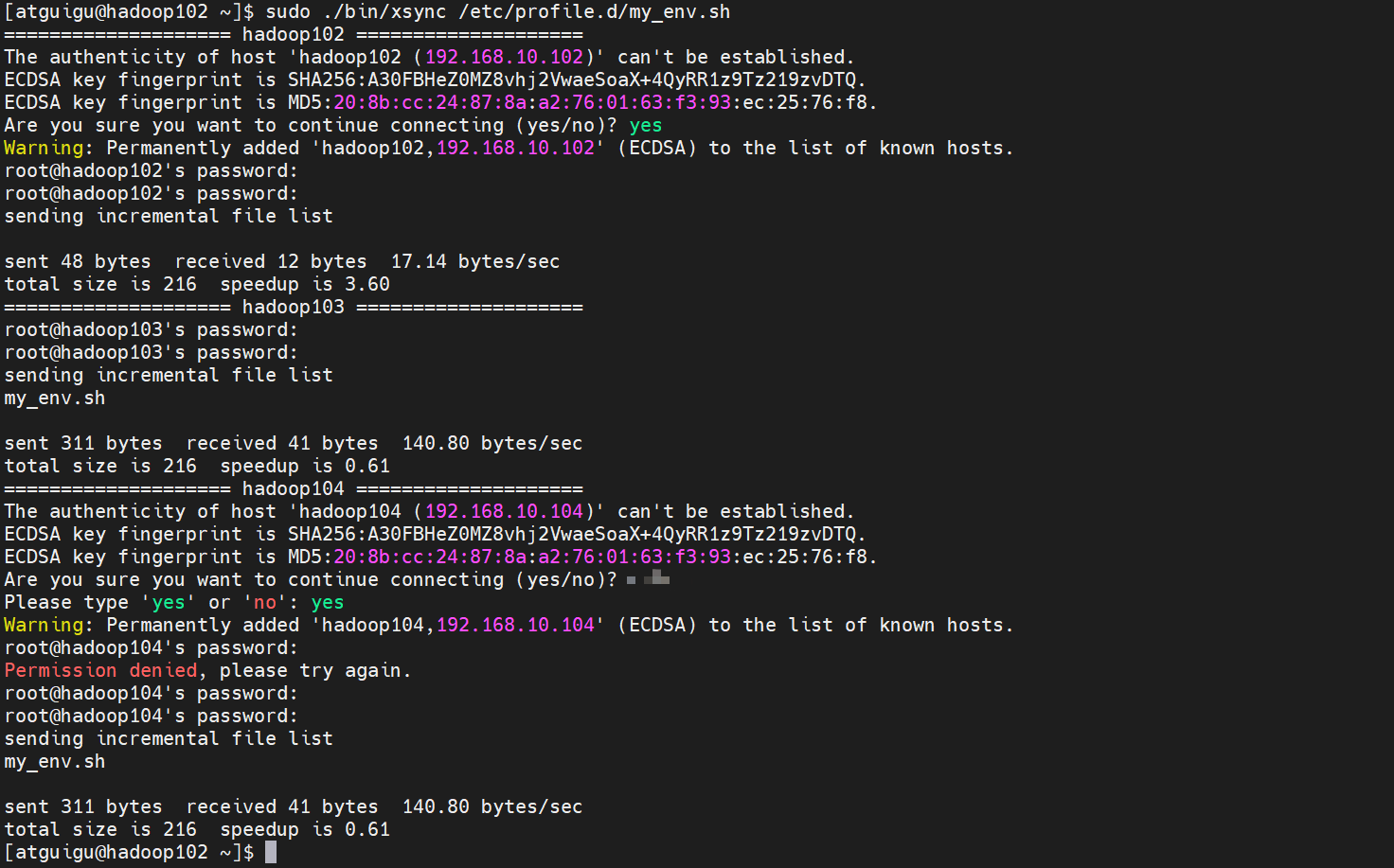
hadoop103
hadoop104

3.3.2 SSH 无密登录配置
1)ssh命令
ssh 另一台电脑的ip

就可以远程登录另一台服务器了
2)免密登录原理
a. 在本服务器生成一对密钥,分为公钥和私钥
b. 公钥是发给对方的服务器的,私钥是自己留存的
c. 然后我们会用私钥加密数据发给对方的服务器
d. 对方的服务器查看自己是否收到了我们曾经发过去的公钥,要是收到了,使用公钥解密
e. 把对方要的数据使用公钥加密传输过去
f. 我们接收到后在使用私钥解密
以下是具体的操作
首先我们要看一下我们的本目录下是否有.ssh目录
ls -al
cd .ssh
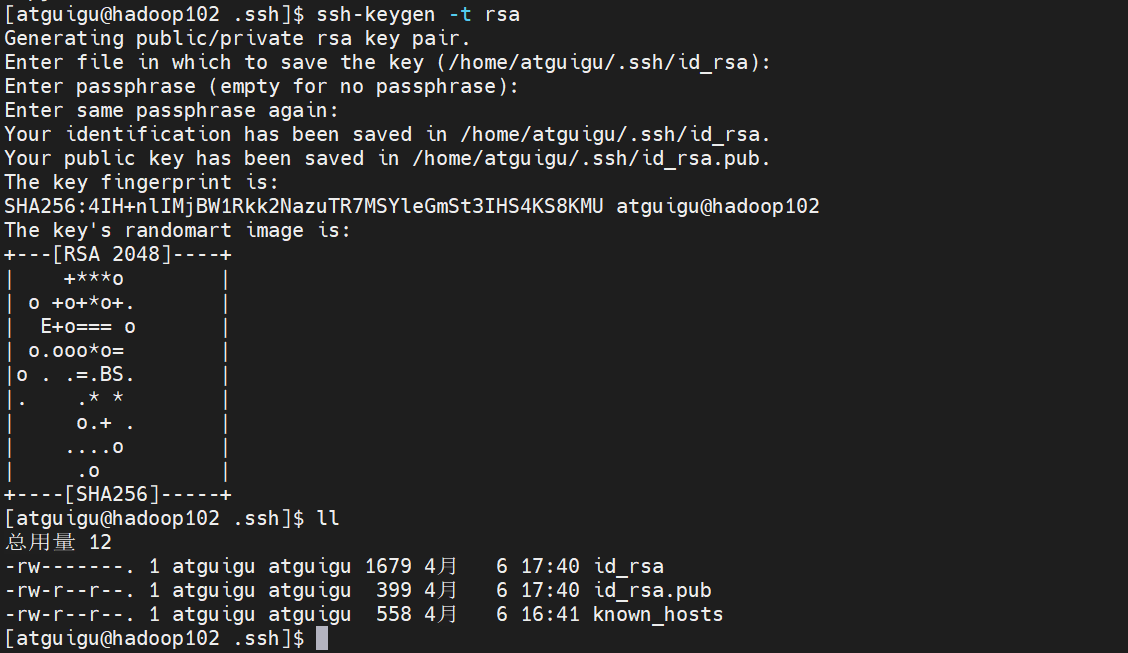
#生成公钥和私钥
ssh-keygen -t rsa
ll
#拷贝
ssh-copy-id Hadoop103
exit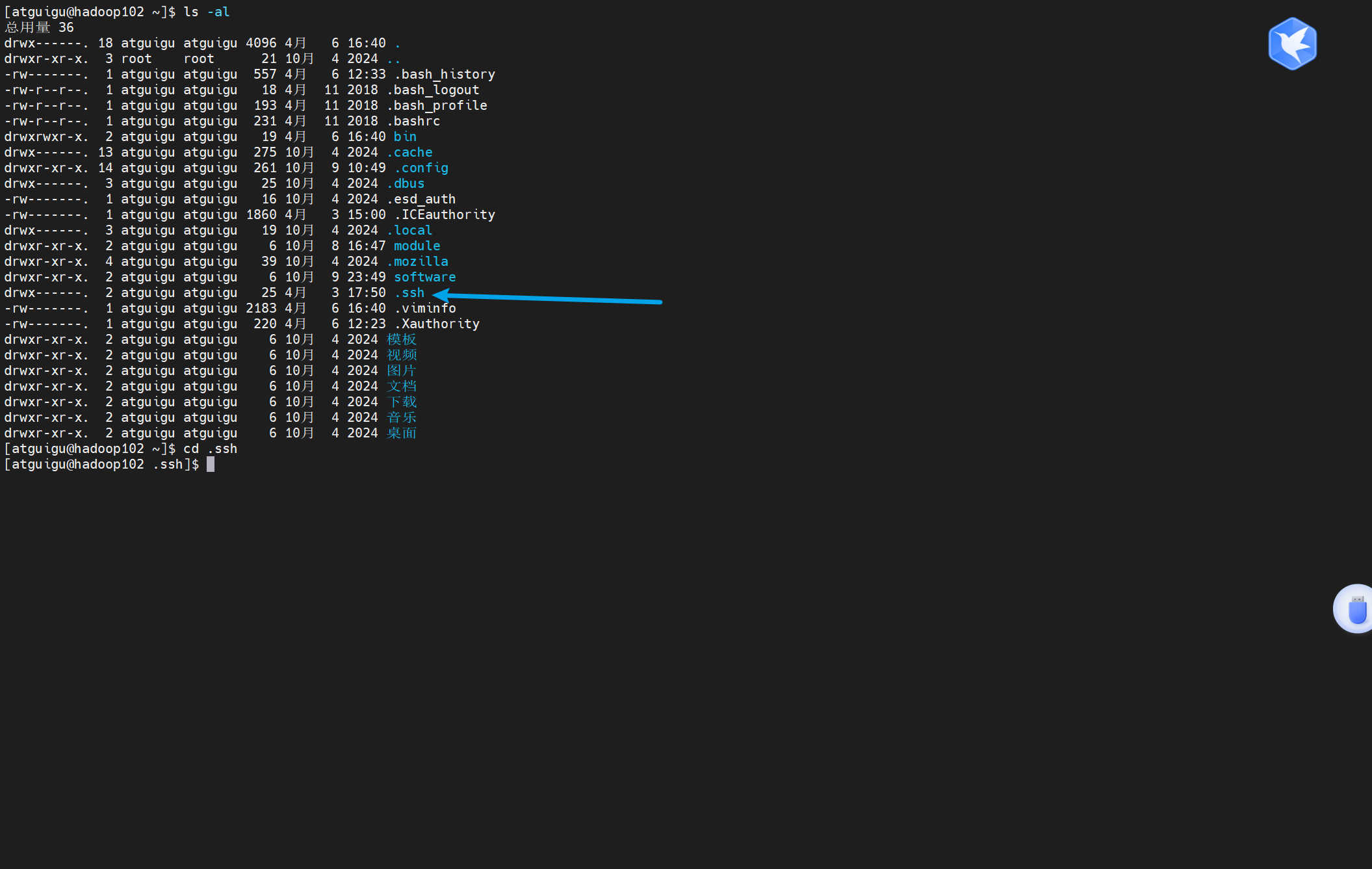

注意:我们仅仅是在atguigu用户下完成了ssh密钥的分发,所以可以免密登录,但是当我们切换root用户的时候就不可以免密登录了
我们需要再hadoop102上配置atguigu和root用户对hadoop102、hadoop103和hadoop104上免密登录
hadoop103上配置atguigu用户对于hadoop102、hadoop103和hadoop104上免密登录
hadoop104上配置atguigu用户对于hadoop102、hadoop103和hadoop104上免密登录
3.3.3集群配置
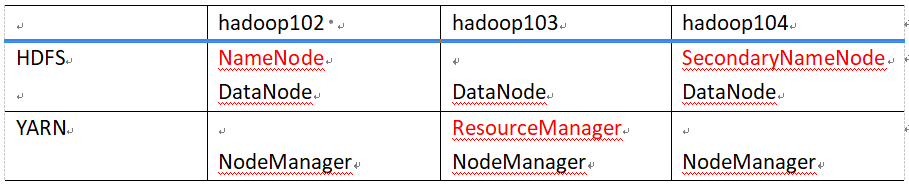
1)集群部署规划
NameNode和SecondaryNameNode不要安装到一台服务器上
ResourceManager不要和NameNode,SecondaryNameNode不要安装到一台服务器上
参考尚硅谷给出的
2)配置文件说明
默认配置文件
自定义配置文件

自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
3)配置集群
(1)核心配置
配置 core-site.xml
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>4)HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>5)YARN配置文件
配置yarn-site.xml
vim yarn-site.xml文件中添加的内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>6)MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>7)在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/分发好了去hadoop103和hadoop104上看一下 分发的情况
3.3.4 群起集群
(1)配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers文件中添加
hadoop102
hadoop103
hadoop104
(2)启动集群
1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format2)启动HDFS
sbin/start-dfs.sh3)在配置了ResourceManager的节点(hadoop103)启动YARN
sbin/start-yarn.sh
4)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
3.3.4 测试集群
hadoop fs -mkdir /input
#上传小文件
hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
#上传大文件
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /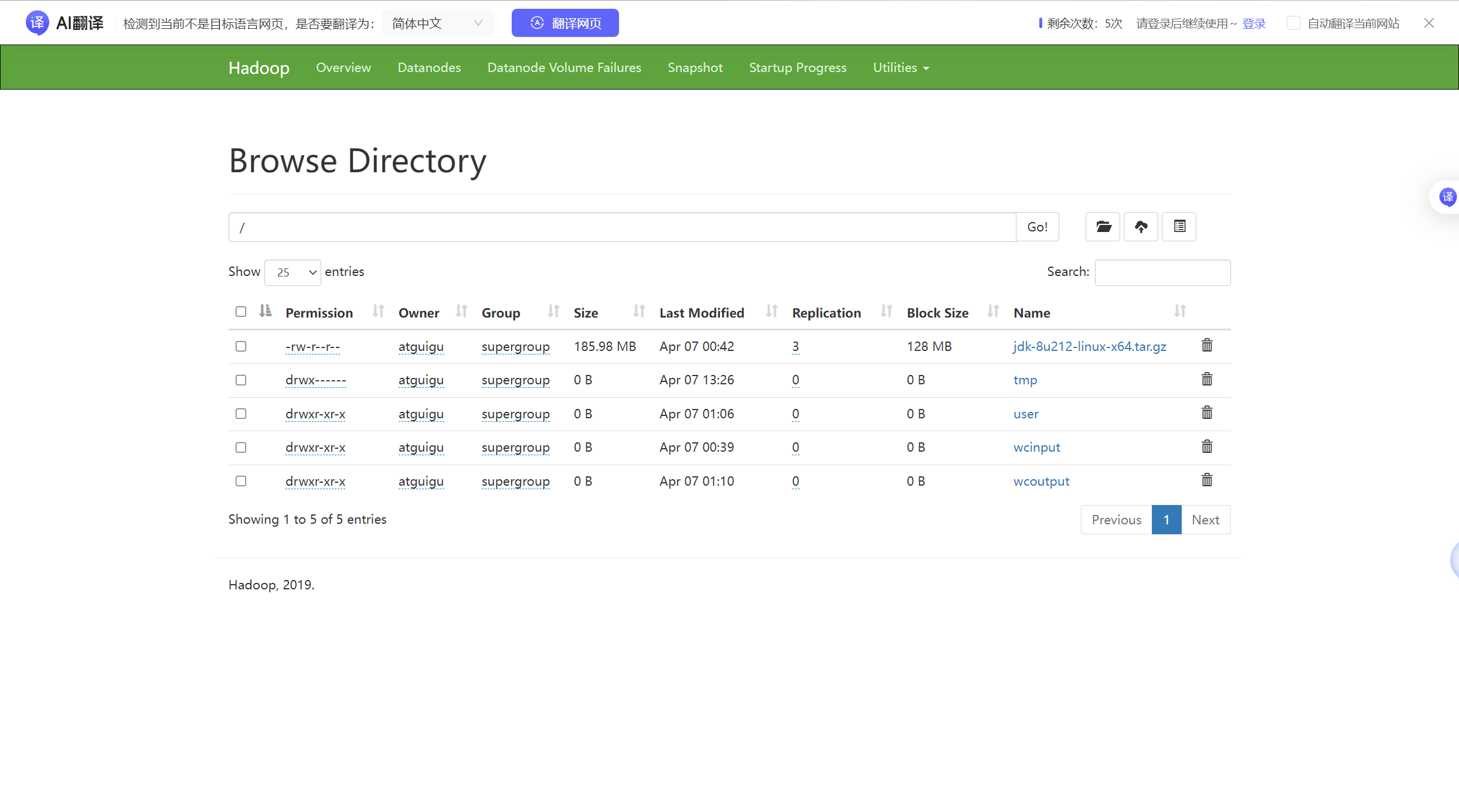
以上笔记参考尚硅谷hadoop搭建的笔记







![STM32单片机入门学习——第27节: [9-3] USART串口发送串口发送+接收](https://i-blog.csdnimg.cn/direct/78b47428511c414fa7d92cd547a7a3c6.png)



![[蓝桥杯] 挖矿(CC++双语版)](https://i-blog.csdnimg.cn/direct/58e77d0bd1dd4b398ad4bc5ddc9c1dd8.png)