Flink Kafka Connector 新旧 API 深度解析与迁移指南
一、Flink Kafka Connector 演进背景
Apache Flink 作为实时计算领域的标杆框架,其 Kafka 连接器的迭代始终围绕性能优化、语义增强和API 统一展开。Flink 1.20 版本将彻底弃用基于 FlinkKafkaConsumer/FlinkKafkaProducer 的旧 API(标记为 @Deprecated),全面转向基于新 Source/Sink API(FLIP-27/FLIP-143)的 KafkaSource/KafkaSink。这一变革不仅带来了架构上的革新,更通过流批统一、精确一次语义和动态分区管理等特性,显著提升了用户体验。
二、新旧 API 核心差异对比
Apache Flink 在 1.13+ 版本逐步引入了全新的 Source/Sink API(也称为 FLIP-27 架构),取代了旧的 SourceFunction/SinkFunction 架构。这一变化旨在解决旧架构在扩展性、批流统一、状态管理等方面的局限性。
1. 新架构实现
这里我们从新 Source 举例,来了解新架构及实现原理:
开始了解 - 新 Source 原理 :
Flink 原先数据源一直使用的是 SourceFunction。实现它的 run 方法,使用 SourceContextcollect 数据或者发送 watermark 就实现了一个数据源。但是它有如下问题(来源于FLIP-27: Refactor Source Interface - Apache Flink - Apache Software Foundation翻译):
-
同一类型数据源的批和流模式需要两套不同实现。
-
“work发现”(分片、分区等)和实际 “读取” 数据的逻辑混杂在 SourceFunction 接口和 DataStream API 中,导致实现非常复杂,如 Kafka 和 Kinesis 源等。
-
分区/分片/拆分在接口中不是明确的。这使得以与 source 无关的方式实现某些功能变得困难,例如 event time 对齐、每个分区水印、动态拆分分配、工作窃取。例如,Kafka 和 Kinesis consumer 支持每个分区的 watermark,但从 Flink 1.8.1 开始,只有 Kinesis 消费者支持 event time 对齐(选择性地从拆分中读取以确保我们在事件时间上均匀推进)。
-
Checkpoint 锁由 source function “拥有”。实现必须确保进行元素发送和 state 更新时加锁。 Flink 无法优化它处理该锁的方式。
锁不是公平锁。在锁竞争下,一些线程可能无法获得锁(checkpoint线程)。这也妨碍使用 actor/mailbox 无锁线程模型。 -
没有通用的构建块,这意味着每个源都自己实现了一个复杂的线程模型。这使得实施和测试新 source 变得困难,并增加了对现有 source 的开发贡献的标准。
为了解决这些问题,Flink 引入了新的 Source 架构。
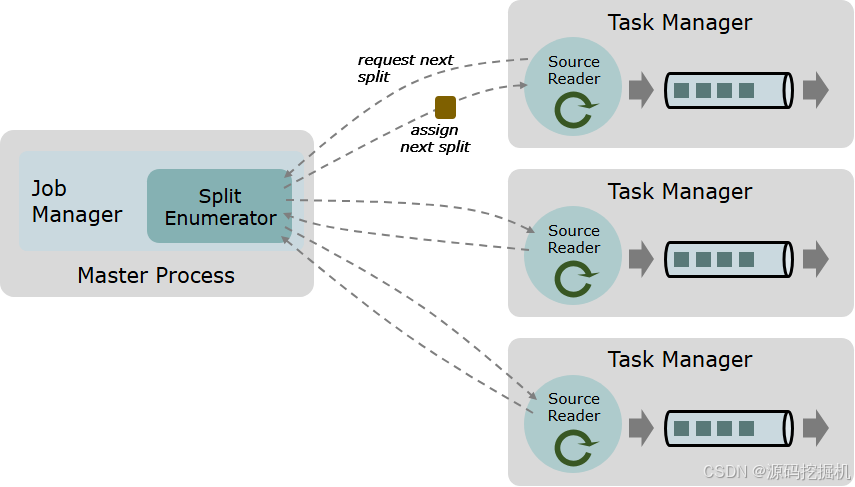
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
-
分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
-
源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
-
分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。
参考原文内容:https://blog.csdn.net/bigdatakenan/article/details/141064429
总的来说,Flink 新 Source/Sink 架构的本质是通过组件解耦和动态分片机制,以实现更加灵活、精细化的资源管理。
2. 核心类与依赖
| 特性 | 旧 API(1.12 之前) | 新 API(1.13+) |
|---|---|---|
| Source 实现类 | FlinkKafkaConsumer | KafkaSource |
| Sink 实现类 | FlinkKafkaProducer | KafkaSink |
| 依赖坐标 示例 | flink-connector-kafka_2.11:1.12 | flink-connector-kafka:1.20 |
| 批流统一 | 需要不同 API | 同一 API 支持流批 |
| 资源效率 | 静态并行度 | 动态分片分配 |
| 并发与锁管理 | 全局锁导致高竞争 | 分片级并发 |
3. 关键功能介绍
(1)动态分区发现
旧 API 通过 flink.partition-discovery.interval-millis 配置分区发现间隔。
新 API 通过 partition.discovery.interval.ms 配置分区发现间隔。
// 设置动态分区发现,间隔为 10 秒
// 旧 API
Properties props = new Properties();
...
props.setProperty("flink.partition-discovery.interval-millis", "10000");
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"topic-name",
new SimpleStringSchema(),
props
);
// 新 API
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(Config.KAFKA_SERVER)
.setValueOnlyDeserializer(new SimpleStringSchema())
...
.setProperty("partition.discovery.interval.ms", "10000")
.build();
(2)起始偏移量控制
旧 API 通过 auto.offset.reset 参数 或 flinkKafkaConsumer.setStartFromEarliest()的方法配置 offset 。
新 API 提供更细粒度的 offset 控制:
// 旧 API
Properties props = new Properties();
props.setProperty("auto.offset.reset", "earliest");
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"topic-name",
new SimpleStringSchema(),
props
);
// 或
flinkKafkaConsumer.setStartFromEarliest();
// 新 API
// 从最早可用偏移量(earliest offset)开始消费,忽略消费者组已提交的偏移量。
KafkaSource.builder()
.setStartingOffsets(OffsetsInitializer.earliest())
.build();
// 优先使用消费者组已提交的偏移量(若存在),如果无提交的偏移量(如首次启动消费者组),则回退到 EARLIEST 偏移量
KafkaSource.builder()
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
.build();
// 从大于或等于指定时间戳(Unix 毫秒时间戳)的 Kafka 消息开始消费
KafkaSource.builder()
.setStartingOffsets(OffsetsInitializer.timestamp(1657256257000L))
.build();
(3)事务性写入
相较于旧 API ,新 API 配置事务方式更加简洁和易读。
Properties props = new Properties();
...
props.setProperty("enable.idempotence", true);
props.setProperty("transaction.timeout.ms", "900000");
// 旧 API Exactly-Once Sink
FlinkKafkaProducer<String> flinkKafkaProducer = new FlinkKafkaProducer<>(
"topic",
new SimpleStringSchema(),
props,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE // 旧 API 语义配置
)
flinkKafkaProducer.setTransactionalIdPrefix("flink-transactional-id-");
// 新 API Exactly-Once Sink
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(Config.KAFKA_SERVER)
.setRecordSerializer(...)
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // 新 API 语义配置
.setTransactionalIdPrefix("flink-transactional-id-")
.setKafkaProducerConfig(props)
.build();
三、迁移实战指南
1. 依赖升级
<!-- 旧 API 依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.x</version>
</dependency>
<!-- 新 API 依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.20.x</version>
</dependency>
2. Source 迁移示例(ConsumerRecord 版)
(1)旧 API 实现
Properties properties = new Properties();
properties.setProperty("consumer.topic", "test_123");
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "group_id_001");
properties.setProperty("auto.offset.reset", "earliest");
FlinkKafkaConsumer<ConsumerRecord<byte[], byte[]>> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
properties.getProperty("consumer.topic"),
new KafkaDeserializationSchema<ConsumerRecord<byte[], byte[]>>(){
@Override
public TypeInformation getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<byte[], byte[]>>() {});
}
@Override
public ConsumerRecord<byte[], byte[]> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
return new ConsumerRecord<>(
record.topic(),
record.partition(),
record.offset(),
record.timestamp(),
record.timestampType(),
record.checksum(),
record.serializedKeySize(),
record.serializedValueSize(),
record.key(),
record.value()
);
}
@Override
public boolean isEndOfStream(ConsumerRecord<byte[], byte[]> nextElement) {
return false;
}
},
properties
);
env.addSource(flinkKafkaConsumer);
(2)新 API 实现
KafkaSource<ConsumerRecord<String, String>> source = KafkaSource.<ConsumerRecord<String, String>>builder()
.setBootstrapServers(Config.KAFKA_SERVER)
.setTopics(Config.KAFKA_TOPIC)
.setGroupId(Config.KAFKA_GROUP_ID)
.setStartingOffsets(OffsetsInitializer.earliest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new KafkaDeserializationSchema<ConsumerRecord<String, String>>() {
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>() {
});
}
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {
return false;
}
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
return new ConsumerRecord<String, String>(
record.topic(),
record.partition(),
record.offset(),
record.timestamp(),
record.timestampType(),
record.checksum(),
record.serializedKeySize(),
record.serializedValueSize(),
record.key() == null ? "" : new String(record.key(), StandardCharsets.UTF_8),
record.value() == null ? "" : new String(record.value(), StandardCharsets.UTF_8)
);
}
}))
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "New Flink Kafka Source");
3. Sink 迁移示例(ProducerRecord 版)
(1)旧 API 实现
Properties props = new Properties();
properties.setProperty("producer.topic", "test_123");
props.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaProducer<byte[]> flinkKafkaProducer = new FlinkKafkaProducer<>(
properties.getProperty("producer.topic"),
new KafkaSerializationSchema<byte[]>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
KafkaSerializationSchema.super.open(context);
}
@Override
public ProducerRecord<byte[], byte[]> serialize(byte[] element, @Nullable Long timestamp) {
return new ProducerRecord<>(
properties.getProperty("producer.topic"),
"my_key_id".getBytes(StandardCharsets.UTF_8),
element);
}
},
properties,
FlinkKafkaProducer.Semantic.AT_LEAST_ONCE
);
env.fromElements("apple", "banana", "orange")
.map(i -> i.getBytes(StandardCharsets.UTF_8))
.addSink(flinkKafkaProducer);
(2)新 API 实现
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(Config.KAFKA_SERVER)
.setRecordSerializer((KafkaRecordSerializationSchema<String>) (element, context, timestamp) -> {
String keyId = "my_key_id";
byte[] key = keyId.getBytes(StandardCharsets.UTF_8); // 指定 key
byte[] value = element.getBytes(StandardCharsets.UTF_8); // 指定 value
return new ProducerRecord<>(Config.KAFKA_TOPIC, key, value);
})
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
env.fromElements("apple", "banana", "orange")
.sinkTo(sink);
四、总结与展望
通过Flink KafkaSource/KafkaSink 的连接器 API,用户在使用时不仅获得了更简洁的编程模型,还享受到更便捷的动态分区管理、精确一次语义和性能优化等高级特性。建议用户尽早迁移至新 API,以充分利用 Flink 1.20 的增强功能。
Flink 1.20 版本的发布标志着 Flink 在流批一体和云原生架构方面迈出了重要的一步,进一步巩固了其作为实时流数据处理平台的地位。这一版本在功能上进行了诸多增强,还在性能和易用性方面做出了显著改进,为用户提供了更强大的工具来处理复杂的流批任务。
Flink 1.20 核心改进总结【官宣|Apache Flink 1.20 发布公告】:
-
Flink SQL 物化表(Materialized Table)
- 功能特性
- 通过声明式 SQL 定义动态表结构与数据新鲜度(如
FRESHNESS = INTERVAL '3' MINUTE),引擎自动构建流批统一的数据加工链路。 - 支持流式持续刷新、批式全量刷新、增量刷新三种模式,用户可根据成本灵活切换(如大促时秒级实时,日常天级批处理)。
- 简化运维操作:暂停/恢复数据刷新(
SUSPEND/RESUME)、手动回刷历史分区(REFRESH PARTITION)。
- 通过声明式 SQL 定义动态表结构与数据新鲜度(如
- 价值
- 降低 ETL 开发复杂度,无需分别维护流/批作业,提升实时数仓构建效率。
- 功能特性
-
状态与检查点优化
- 统一检查点文件合并机制
- 将零散小文件合并为大文件,减少元数据压力,需配置
execution.checkpointing.file-merging.enabled=true。 - 支持跨检查点合并(
execution.checkpointing.file-merging.across-checkpoint-boundary=true)及文件池模式选择(阻塞/非阻塞)。
- 将零散小文件合并为大文件,减少元数据压力,需配置
- RocksDB 优化
- 后台自动合并小 SST 文件,避免因文件数量膨胀导致检查点失败。
- 统一检查点文件合并机制
-
批处理容错能力增强
- JobMaster 故障恢复机制
- 通过
JobEventStore持久化执行状态(如任务进度、算子协调器状态),故障后从外部存储恢复进度,避免重跑已完成任务。 - 需启用集群高可用(HA)并配置
execution.batch.job-recovery.enabled=true。
- 通过
- JobMaster 故障恢复机制
-
API 演进
- DataSet API 弃用
- 推荐迁移至 DataStream API 或 Table API/SQL,实现流批统一编程模型。
- DataStream API 增强
- 支持全量分区数据处理(
fullWindowPartition),补齐批处理能力。
- 支持全量分区数据处理(
- DataSet API 弃用









![[蓝桥杯] 求和](https://i-blog.csdnimg.cn/direct/f1ce0cd7ae424ae88240815b1441c9b9.png)