目录
需求
第一次尝试
运行环境
思路
存储
排序
触发排序操作
如何实现高效的排序
关键1
关键2
关键3 磨刀不误砍柴工
关键4
代码
效果
卡顿原因分析
原因1
原因2
第二次尝试
需求
1 我的qt程序通过表格显示30000条数据。数据来自udp,udp每隔10秒发一次,一次含两个包。每包含有15000个数据。
2 每条数据有三个属性,在表格中通过3列显示这三个属性。其中一个属性是区分“左”和“右”的。udp发送的两个包,一个包全是“左”属性,另一个包全是"右"属性。
3 当用户点击三列中某一列的表头时,触发程序针对该列对应的属性进行排序。排序又分升序和降序。假如某列上一次使用升序排列,那么当用户再次点击该列表头时,该列变为降序排列。
4 假如当前针对表格的第一列排序,当用户点击第二列表头后,表格就改为采用第二列排序,第一列排序作废。
5 udp发来的新数据将覆盖上一次的旧数据。假如覆盖前,表格采用第三列排序,收到新数据后,程序自动调用排序算法针对新数据的第三列排序。
第一次尝试
下面涉及的所有函数、变量都出自同一套代码。代码在我的资源【免费】qt表格排序示例,使用mv结构资源-CSDN文库中下载。
运行环境
win10 vs2019 + Qt6.4.3 debug编译
思路
存储
采用MV(model-view)结构。表格数据保存于Model中。Model是QAbstractTableModel的派生类。这种MV结构的使用在我前面的博客《MV结构下设置Qt表格的代理》已经介绍了。在本例中,实际数据保存在成员变量m_vec_qstrlst之中,类型是std::vector<QStringList>。vector的每一个元素是QStringList类型,代表一行的内容。每一行的具体内容按列依次排在QStringList的每个元素里面。
表格显示什么内容由QAbsractTableModel::data()决定。
排序
触发排序操作
点击表头将触发信号QHeaderView::sectionClicked,通过此信号触发排序操作即可。
如何实现高效的排序
关键1
排序通过函数vSortByColumn()实现。这个函数根据变量m_arrOrder进一步调用函数vSortAscending或者vSortDescending,分别完成升序排序和降序排序。
前面提到了,真正的数据保存在m_vec_qstrlst之中。注意,排序不能直接作用于m_vec_qstrlst。原因是m_vec_qstrlst的每个元素都是QStringList,是比较复杂的类型。排序时,后面的元素排到前面,前面的元素排到后面,将导致频繁的QStringList析构和构造,拉低效率。
解决问题的方法有两个:
1 m_vec_qstrlst里面不要直接存放QStringList,而是使用指针。移动指针不会触发构造和析构。如果你担心指针造成内存泄漏,可以使用智能指针。
2 另外建立一个成员变量m_vecOrder,类型为std::vector<int>。元素个数与m_vec_qstrlst的元素个数相同,第0个元素=0,第1个元素=1,...最后一个元素=m_vec_qstrlst.size()-1。排序时,不修改m_vec_qstrlst的次序,而是对m_vecOrder的次序进行重排。由于m_vecOrder的元素类型是int,所以排序带来的开销远远小于直接对m_vec_qstrlst排序。
本例采用第二种做法。
关键2
具体排序时,我也有两个选择:
1 C++标准库提供排序函数sort(),复杂度为O(nlog(n))。
2 从八种排序算法中选择一个,自己用C++实现。
这里我选择手写冒泡算法实现排序。后面的博客会看到,手写的效率是低于使用std::sort函数的。
关键3 磨刀不误砍柴工
从直觉上说,我只要从m_vec_qstrlst里面提取两个相邻的QStringList,根据排序的列号来获取对应在QStringList中的元素,然后转化为int 或者float就能比较了。但这样涉及大量的容器访问,以及字符串到数值型的转化,开销也很大。更何况冒泡排序的复杂度是O(n^2)。所以我在执行冒泡排序之前,先遍历m_vec_qstrlst,把待比较的那一列数据专门提取出来,存入数组vecVal,通过vecVal来执行排序。遍历m_vec_qstrlst的复杂度是O(n),相比O(n^2),我还是赚的。此外,遍历后,产生的新vector结构比原始容器简单,可以降低cache-miss,更有利于提高效率。
关键4
release 模式比debug模式快。同为debug编译的程序,运行模式又比调试模式快。后面会提到。
代码
这里只给出核心的Model代码。完整代码及测试数据从我的资源【免费】qt表格排序示例,使用mv结构资源-CSDN文库下载
#ifndef MODELFREQDETECT_H
#define MODELFREQDETECT_H
#include <QAbstractTableModel>
class ModelFreqDetect : public QAbstractTableModel
{
Q_OBJECT
public:
ModelFreqDetect(QStringList, int, int, QObject * parent = 0);
int iAddRows(bool bLeft, std::vector<QStringList> &);
void vSortByColumn(int iCol);
protected:
int rowCount(const QModelIndex &) const override;
int columnCount(const QModelIndex &) const override;
QVariant data(const QModelIndex &index, int role) const override;
QVariant headerData(int section, Qt::Orientation orientation, int role) const override;
const int m_cnst_iLeftSize;
const int m_cnst_iRightSize;
//数据保存在m_vec_qstrlst
std::vector<QStringList> m_vec_qstrlst;
QStringList m_qstrlstHeader;
private:
QScopedArrayPointer<int> m_arrOrder;
int m_iMajorCol;
const int m_cnst_iMaxRowCount;//表格最大行数,本示例中是30000
//m_vecOrder的元素是m_vec_qstrlst中每个成员的序号。元素的相对次序决定了排序结果
std::vector<int> m_vecOrder;
void vSortDescending(std::vector<QStringList> & vecInput, int);
void vSortAscending(std::vector<QStringList> & vecInput, int);
};
#endif // MODELFREQDETECT_H
#include "ModelFreqDetect.h"
ModelFreqDetect::ModelFreqDetect(QStringList qstrlst, int iLeftSize, int iRightSize, QObject * parent): QAbstractTableModel(parent),
m_qstrlstHeader(qstrlst), m_iMajorCol(2), m_cnst_iLeftSize(iLeftSize),
m_cnst_iRightSize(iRightSize),
m_arrOrder(new int[m_qstrlstHeader.size()]), m_cnst_iMaxRowCount(iLeftSize + iRightSize),
m_vec_qstrlst(iLeftSize + iRightSize)
{
m_vecOrder.resize(0);
for(int k = 0; k < m_qstrlstHeader.size(); k++)
{
m_arrOrder[k] = Qt::AscendingOrder;
}
}
int ModelFreqDetect::iAddRows(bool bLeft, std::vector<QStringList> & vec_qstrlst)
{
//m_vec_qstrlst并不是手工排序后的结果,而是采用默认排序
//所谓默认排序,指的是左结果排在右前面。每个包内部的次序按照udp发来的次序
int iLoc = bLeft ? 0 : m_cnst_iLeftSize;
//假如送来的vec_qstrlst代表左阵面信息,则从m_vec_qstrlst.begin()开始覆盖;
//否则就是代表右信息,从m_vec_qstrlst.begin()开始跳过m_cnst_iLeftSize,覆盖右
std::copy(vec_qstrlst.begin(), vec_qstrlst.end(), m_vec_qstrlst.begin() + iLoc);
if(m_iMajorCol > -1 && m_iMajorCol < m_qstrlstHeader.size())
{
//排序
if((Qt::SortOrder)(m_arrOrder[m_iMajorCol]) == Qt::AscendingOrder)
vSortAscending(m_vec_qstrlst, m_iMajorCol);
else
vSortDescending(m_vec_qstrlst, m_iMajorCol);
}
emit dataChanged(createIndex(0, 0), createIndex(m_cnst_iMaxRowCount - 1, m_qstrlstHeader.size() - 1));
return vec_qstrlst.size();
}
int ModelFreqDetect::rowCount(const QModelIndex & parent) const
{
return m_cnst_iMaxRowCount;
}
int ModelFreqDetect::columnCount(const QModelIndex & parent) const
{
return m_qstrlstHeader.size();
}
QVariant ModelFreqDetect::data(const QModelIndex &index, int role) const
{
int i = index.row(), j = index.column();
if ((i >= 0) && (i < qMin(m_cnst_iMaxRowCount, (const int)(m_vecOrder.size()))))
{
if(role == Qt::DisplayRole)
{
if (0 <= j && j < m_qstrlstHeader.size())
{
QStringList qstrlst = m_vec_qstrlst.at(i);
if(qstrlst.size() > j)
{
//return qstrlst.at(j);
return m_vec_qstrlst.at(m_vecOrder.at(i)).at(j);
}
}
}
else
{
}
}
else if(role == Qt::TextAlignmentRole)
return Qt::AlignCenter;
else
{
}
return QVariant();
}
//ok
QVariant ModelFreqDetect::headerData(int section, Qt::Orientation orientation, int role) const
{
if(role == Qt::DisplayRole)
{
if(orientation == Qt::Horizontal)
{
if(section < m_qstrlstHeader.size())
{
QString qstrOrder;
if(section == m_iMajorCol)
{
if(Qt::AscendingOrder == m_arrOrder[m_iMajorCol])
qstrOrder = "^";
else
qstrOrder = "v";
}
else
{
qstrOrder = "";
}
return m_qstrlstHeader.at(section) + qstrOrder;
}
}
else
{
return QString("%1").arg(section);
}
}
else if(role == Qt::TextAlignmentRole)
{
return Qt::AlignCenter;
}
else
{
}
return QAbstractTableModel::headerData(section, orientation, role);
}
void ModelFreqDetect::vSortByColumn(int iCol)
{
if(Qt::AscendingOrder == m_arrOrder[iCol])
{
m_arrOrder[iCol] = Qt::DescendingOrder;
}
else if(Qt::DescendingOrder == m_arrOrder[iCol])
m_arrOrder[iCol] = Qt::AscendingOrder;
else
m_arrOrder[iCol] = Qt::AscendingOrder;
m_iMajorCol = iCol;
//然后排序,排序结果保存在m_vecOrder
if((Qt::SortOrder)(m_arrOrder[iCol]) == Qt::AscendingOrder)
vSortAscending(m_vec_qstrlst, iCol);
else
vSortDescending(m_vec_qstrlst, iCol);
//更新界面
emit dataChanged(createIndex(0, 0), createIndex(m_cnst_iMaxRowCount - 1, m_qstrlstHeader.size() - 1));
}
void ModelFreqDetect::vSortDescending(std::vector<QStringList> & vecInput, int iCol)
{
//冒泡排序
//1 先把用来排序的那一列的数据提取出来,并且无效的序号不要计入m_vecOrder
std::vector<float> vecVal;
std::vector<int> vecIdx;
for(int k = 0; k < vecInput.size(); k++)
{
if(vecInput.at(k).isEmpty())
{
vecVal.push_back(0);
}
else
{
vecIdx.push_back(k);
vecVal.push_back(iCol == 0 ? (vecInput.at(k).at(iCol).compare("left")) : vecInput.at(k).at(iCol).toFloat());
}
}
//2 排序
int iTail = vecIdx.size()-1;
while(iTail > 0)
{
for(int k = 0; k < iTail; k++)
{
float f1 = vecVal.at(vecIdx.at(k));
float f2 = vecVal.at(vecIdx.at(k+1));
if(f1 < f2)
{
//默认是降序
int iTmp = vecIdx.at(k);
vecIdx[k] = vecIdx[k+1];
vecIdx[k+1] = iTmp;
}
}
iTail--;
}
m_vecOrder.swap(vecIdx);
}
void ModelFreqDetect::vSortAscending(std::vector<QStringList> & vecInput, int iCol)
{
//冒泡排序
//1 先把用来排序的那一列的数据提取出来,并且无效的序号不要计入m_vecOrder
std::vector<float> vecVal;
std::vector<int> vecIdx;
for(int k = 0; k < vecInput.size(); k++)
{
if(vecInput.at(k).isEmpty())
{
vecVal.push_back(0);
}
else
{
vecIdx.push_back(k);
vecVal.push_back(iCol == 0 ? (vecInput.at(k).at(iCol).compare("left")):vecInput.at(k).at(iCol).toFloat());
}
}
//2 排序
int iTail = vecIdx.size()-1;
while(iTail > 0)
{
for(int k = 0; k < iTail; k++)
{
float f1 = vecVal.at(vecIdx.at(k));
float f2 = vecVal.at(vecIdx.at(k+1));
if(f1 > f2)
{
//默认是降序
int iTmp = vecIdx.at(k);
vecIdx[k] = vecIdx[k+1];
vecIdx[k+1] = iTmp;
}
}
iTail--;
}
m_vecOrder.swap(vecIdx);
}
效果
下面的视频展示了点击第三列的表头之后,界面卡顿大约10秒才完成排序的现象:
30000条数据排序,很卡顿。优化后的对比视频稍后上传
测试数据见【免费】排序测试数据,分两部分,一个是属性为左,另一个属性为右两者各15000条数据资源-CSDN文库
卡顿原因分析
原因1
没有使用std::sort.下一篇博客,我将使用std::sort来排序,并与本篇的结果做对比。
原因2
刚才的测试运行在调试模式下。
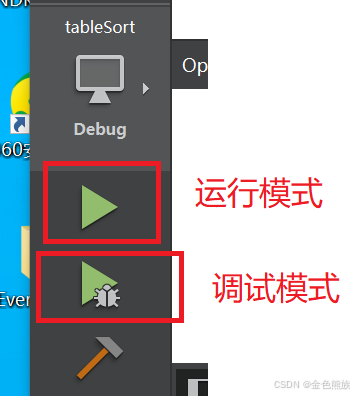
在运行模式下,程序运行更快。
第二次尝试
仍然使用同一套在debug下产生的程序,唯一的区别是在运行模式下执行。排序耗时大约3秒。
运行模式,排序时间降到约三秒