摘要:归纳程序合成,或称示例编程,要求从输入输出示例中合成能够泛化到未见输入的函数。尽管大型语言模型代理在自然语言指导下的编程任务中展现出了潜力,但它们在执行归纳程序合成方面的能力仍待深入探索。现有的评估协议依赖于静态的示例集和保留测试集,当合成的函数不正确时无法提供反馈,且未能反映现实世界场景,如逆向工程。我们提出了CodeARC,即代码抽象与推理挑战,这是一个新的评估框架,其中代理通过与隐藏的目标函数交互,使用新输入进行查询,合成候选函数,并利用差分测试预言器迭代地精炼其解决方案。这种交互式设置鼓励代理基于反馈执行函数调用和自我修正。我们构建了第一个针对通用归纳程序合成的大规模基准,其中包含1114个函数。在评估的18个模型中,o3-mini表现最佳,成功率为52.7%,凸显了这项任务的难度。对LLaMA-3.1-8B-Instruct在精心挑选的合成轨迹上进行微调,可使性能相对提升高达31%。CodeARC为评估基于LLM的程序合成和归纳推理提供了一个更现实且更具挑战性的测试平台。Huggingface链接:Paper page,论文链接:2503.23145
研究背景和目的
研究背景:
随着人工智能技术的飞速发展,大型语言模型(LLMs)在各个领域的应用日益广泛。特别是在程序合成领域,LLMs展现出了巨大的潜力。然而,传统的程序合成方法往往依赖于领域特定的语言和搜索算法,限制了其通用性和扩展性。归纳程序合成(Inductive Program Synthesis),或称示例编程(Programming by Example),作为一种从输入输出示例中合成能够泛化到未见输入的函数的方法,为解决这一问题提供了新的思路。这种方法不需要自然语言描述,而是直接通过示例来指导程序合成,更加贴近实际编程场景。
尽管LLMs在自然语言处理和编程任务中取得了显著进展,但它们在归纳程序合成方面的能力仍待深入探索。现有的评估协议多依赖于静态的示例集和保留测试集,无法提供合成函数不正确时的反馈,且难以反映现实世界中的复杂场景,如逆向工程等。因此,需要一种更加现实且富有挑战性的评估框架来全面测试LLMs在归纳程序合成中的推理能力。
研究目的:
本研究旨在提出一个新的评估框架——CodeARC(Code Abstraction and Reasoning Challenge),用于评估LLMs在归纳程序合成中的推理能力。通过构建一个交互式的评估环境,使代理能够通过与隐藏目标函数的交互,不断查询新输入、合成候选函数,并利用差分测试预言器迭代地精炼其解决方案。这种设置不仅能够测试LLMs的归纳推理能力,还能鼓励代理基于反馈进行自我修正,从而更加贴近实际编程场景。
此外,本研究还旨在构建一个针对通用归纳程序合成的大规模基准数据集,为未来的研究提供一个标准的测试平台。通过评估多种LLMs在该基准上的表现,揭示它们在归纳程序合成中的优势和局限性,为未来的模型改进和应用提供指导和参考。
研究方法
问题定义:
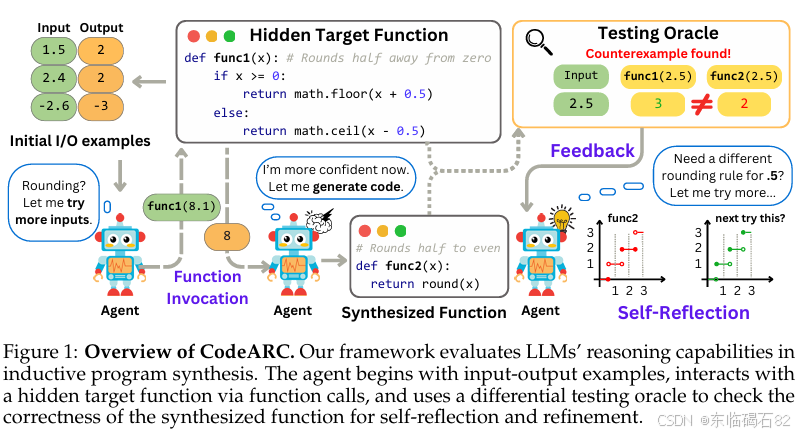
归纳程序合成任务被正式定义为:给定一个隐藏的目标函数f,该函数将输入x映射到输出y,合成器被提供一组初始的输入输出示例E0={(xi, yi)},其中yi=f(xi),目标是合成一个程序f,使得f等价于f,即对于所有x∈X,都有^f(x)=f(x)。为了评估合成的函数f是否正确,我们引入了一个差分测试预言器O。该预言器接收合成的函数f和隐藏的目标函数f*作为输入,并尝试找到使两者行为不一致的输入。
交互式评估协议:
为了评估LLMs在归纳程序合成中的推理能力,我们提出了一种交互式评估协议。该协议允许代理在评估过程中与隐藏的目标函数和差分测试预言器进行交互。具体步骤如下:
- 初始信息:在任务开始时,代理被提供一组初始的输入输出示例E0。
- 动作空间:在评估过程中,代理可以采取两种类型的动作。首先,它可以向隐藏的目标函数f查询特定输入x的输出f(x),从而扩充其观察到的输入输出对集合。其次,它可以合成一个候选程序f,并调用差分测试预言器O(f*, f)来检查该程序是否正确。
- 自我修正:如果差分测试预言器返回失败,并提供一个反例(即一个使^f和f行为不一致的输入),代理将使用这个反例来进行自我修正,要么通过向f发出更多查询,要么合成新的程序。
- 预算约束:代理在评估过程中受到两个预算参数的限制:B_io限制了代理可以从隐藏目标函数f*观察到的输入输出对的总数;B_oracle限制了代理可以调用差分测试预言器O的次数。
基准数据集构建:
为了全面评估LLMs在归纳程序合成中的推理能力,我们构建了一个大规模的基准数据集。该数据集包含1114个通用目的的Python函数,这些函数从三个现有的代码生成基准(HumanEval、MBPP和APPS)中精心挑选而来。为了确保评估的公正性,我们提供了两个版本的数据集:注释版本和匿名版本。在注释版本中,函数名反映了其预期功能;而在匿名版本中,所有函数名都被替换为通用标识符。
模型评估与微调:
为了评估不同LLMs在CodeARC基准上的表现,我们选取了18个大型语言模型进行测试。为了进一步提升模型性能,我们还探索了通过监督微调来增强模型归纳推理能力的方法。具体地,我们使用GPT-4o作为教师模型来合成候选函数,并记录其多轮对话历史。然后,我们使用LLaMA-3.1-8B-Instruct作为学生模型,通过模仿教师模型的推理和合成行为来进行微调。
研究结果
主要结果:
在CodeARC基准上,我们评估了18个大型语言模型的表现。实验结果表明,推理模型(如o3-mini、o1-mini和DeepSeek-R1)在匿名数据集上取得了最高的成功率,均超过40%。这表明这些模型具有较强的归纳推理能力。此外,所有模型在匿名数据集上的表现均低于注释数据集,但整体排名保持一致。这说明尽管有意义的函数名提供了一些帮助,但强大的归纳推理能力仍然是高性能的关键因素。
我们还发现,随着模型规模的增大,其在CodeARC基准上的表现也逐步提升。这表明通过增加模型参数数量,可以进一步提高LLMs在归纳程序合成中的推理能力。
消融研究:
为了深入理解不同因素对模型性能的影响,我们还进行了一系列消融研究。实验结果表明,增加输入输出查询预算和差分测试预言器调用次数可以显著提升模型的成功率。这验证了交互式评估协议的有效性,并表明通过提供更多的反馈信息,可以进一步提高LLMs在归纳程序合成中的表现。
案例研究:
我们还通过案例研究来展示模型在CodeARC基准上的实际表现。一个典型的案例是,模型首先通过向隐藏目标函数查询边缘案例输入来探索其行为,然后合成一个候选解决方案。尽管该方案通过了初始示例测试,但在差分测试预言器的检查下失败。根据错误信息,模型正确地推断出隐藏目标函数会引发一个TypeError,而它自己的函数则没有。在第二次尝试中,模型采用了一个基于集合的解决方案,并成功通过了差分测试预言器的检查。这个案例展示了模型如何通过函数调用和差分测试预言器的反馈来进行自我修正和归纳推理。
研究局限
尽管本研究在评估LLMs归纳推理能力方面取得了显著进展,但仍存在一些局限性:
- 基准数据集规模:尽管我们构建了一个包含1114个函数的大规模基准数据集,但其规模仍然有限,可能无法全面反映归纳程序合成的复杂性。未来的研究可以进一步扩展数据集规模,以涵盖更多类型的函数和更复杂的场景。
- 模型泛化能力:尽管我们在匿名数据集上评估了模型的泛化能力,但现实世界中的归纳程序合成任务可能更加复杂和多变。未来的研究可以探索如何通过改进模型架构和训练方法,进一步提高LLMs在归纳程序合成中的泛化能力。
- 交互式评估效率:虽然交互式评估协议能够提供更丰富的反馈信息,但其效率可能受到输入输出查询预算和差分测试预言器调用次数的限制。未来的研究可以探索如何在保证评估准确性的同时,提高交互式评估的效率。
未来研究方向
针对当前研究的局限性,我们提出以下未来研究方向:
- 扩展基准数据集:进一步扩展CodeARC基准数据集的规模,涵盖更多类型的函数和更复杂的场景,以更全面地评估LLMs在归纳程序合成中的推理能力。
- 增强模型泛化能力:通过改进模型架构和训练方法,提高LLMs在归纳程序合成中的泛化能力。例如,可以探索使用更复杂的网络结构和更先进的训练技术来增强模型的表示学习能力和归纳推理能力。
- 提高交互式评估效率:研究如何在保证评估准确性的同时,提高交互式评估的效率。例如,可以探索使用更高效的差分测试预言器或采用更智能的查询策略来减少不必要的输入输出查询和差分测试预言器调用次数。
- 结合其他技术:探索将归纳程序合成与其他技术(如强化学习、知识蒸馏等)相结合的方法,以进一步提高LLMs在归纳程序合成中的表现。例如,可以使用强化学习来优化模型的查询策略和自我修正过程;或者使用知识蒸馏来将大型模型的知识迁移到更高效的小型模型中。