RNN的高级用法
循环dropout(recurrent dropout):这是dropout的一种变体,用于在循环层中降低过拟合。
循环层堆叠(stacking recurrent layers):这会提高模型的表示能力(代价是更大的计算量)。
双向循环层(bidirectional recurrent layer):它会将相同的信息以不同的方式呈现给RNN,可以提高精度并缓解遗忘问题。
我们将使用这3种方法来完善温度预测RNN.
利用循环dropout降低过拟合
我们回头来看基于LSTM的模型,它是第一个能够超越常识基准的模型。观察这个模型的训练曲线和验证曲线(图10-5),可以明显看出,尽管模型只有很少的单元,但很快就出现过拟合,训练损失和验证损失在几轮过后就开始明显偏离。你已经熟悉了降低过拟合的经典方法—dropout,即让某一层的输入单元随机为0,其目的是破坏该层训练数据中的偶然相关性。但如何在RNN中正确使用dropout,并不是一个简单的问题。人们早就知道,在循环层之前使用dropout会妨碍学习过程,而不会有助于正则化。2016年,Yarin Gal在他关于贝叶斯深度学习的博士论文中,确定了在RNN中使用dropout的正确方式:在每个时间步都应该使用相同的dropout掩码(相同模式的舍弃单元),而不是在不同的时间步使用随机变化的dropout掩码。此外,为了对GRU和LSTM等层的循环门得到的表示做正则化,还应该对该层的内部循环激活应用一个不随时间变化的dropout掩码(循环dropout掩码)。在每个时间步使用相同的dropout掩码,可以让神经网络沿着时间传播其学习误差,而随时间随机变化的dropout掩码则会破坏这个误差信号,不利于学习过程。
Keras中的每个循环层都有两个与dropout相关的参数:一个是dropout,它是一个浮点数,指定该层输入单元的dropout比率;另一个是recurrent_dropout,指定循环单元的dropout比率。对于第一个LSTM示例,我们向LSTM层中添加循环dropout,看一下它对过拟合的影响,如代码清单10-22所示。由于使用了dropout,我们不需要过分依赖网络尺寸来进行正则化,因此我们将使用具有两倍单元个数的LSTM层,希望它的表示能力更强(如果不使用dropout,这个网络会马上开始过拟合,你可以试试看)。由于使用dropout正则化的网络总是需要更长时间才能完全收敛,因此我们将模型训练轮数设为原来的5倍。
代码清单10-22 训练并评估一个使用dropout正则化的LSTM模型
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(32, recurrent_dropout=0.25)(inputs)
x = layers.Dropout(0.5)(x) ←----这里在LSTM层之后还添加了一个Dropout层,对Dense层进行正则化
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm_dropout.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=50,
validation_data=val_dataset,
callbacks=callbacks)
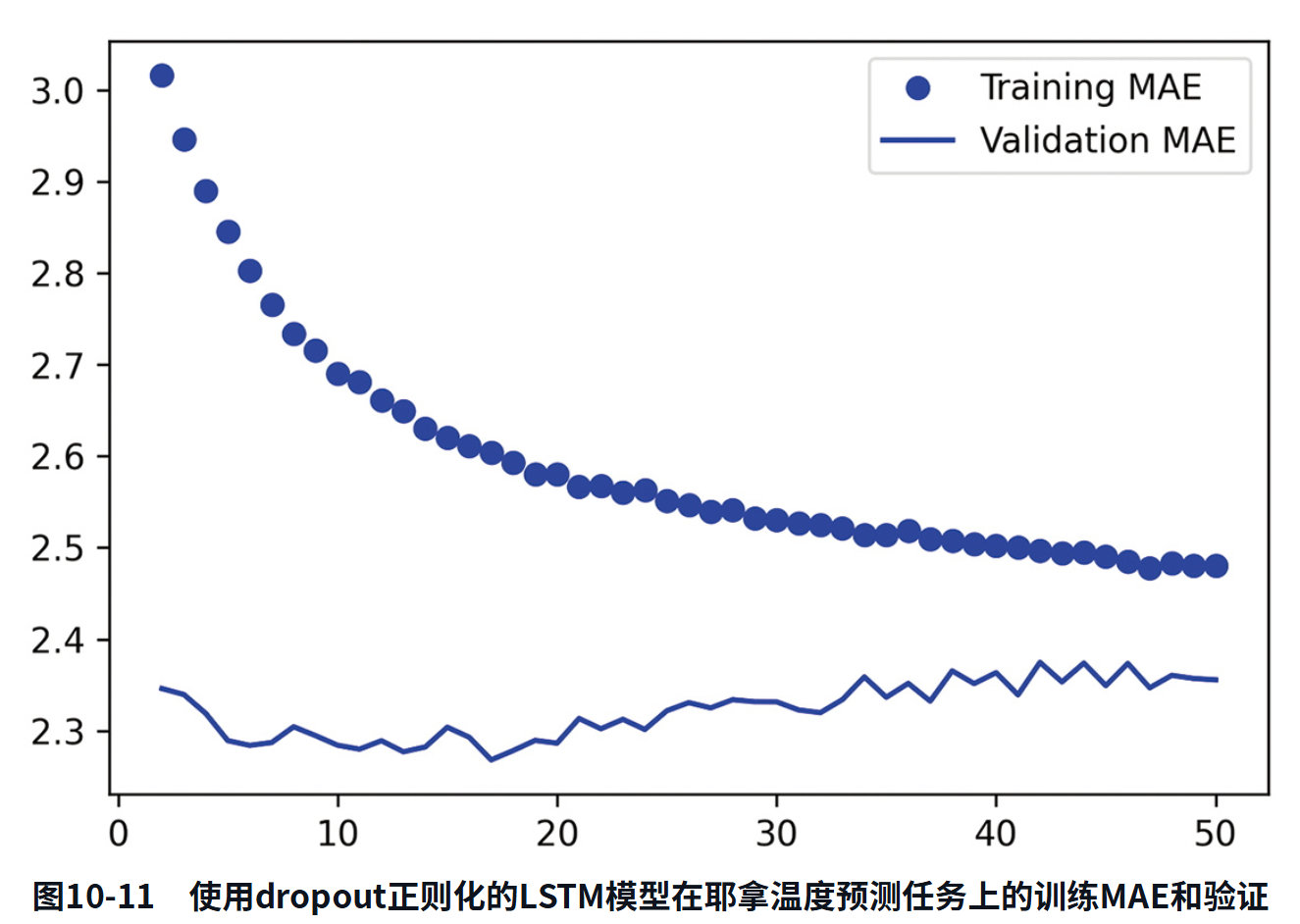
模型结果如图10-11所示。成功!模型在前20轮中不再过拟合。验证MAE低至2.27摄氏度(比不使用机器学习的基准改进了7%),测试MAE为2.45摄氏度(比基准改进了6.5%),还不错
RNN的运行时性能
对于参数很少的循环模型(比如本章中的模型),在多核CPU上的运行速度往往比GPU上快很多,因为这种模型只涉及小矩阵乘法,而且由于存在for循环,因此乘法链无法很好地并行化。但较大的RNN则可以显著地受益于GPU运行时。使用默认关键字参数在GPU上运行Keras LSTM层或GRU层时,该层将利用cuDNN内核。这是由NVIDIA提供的低阶底层算法实现,它经过高度优化。cuDNN内核有利有弊:速度快,但不够灵活。如果你想做一些默认内核不支持的操作,将会遭受严重的降速,这或多或少会迫使你坚持使用NVIDIA提供的操作。例如,LSTM和GRU的cuDNN内核不支持循环dropout,因此在层中添加循环dropout,会使运行时变为普通TensorFlow实现,这在GPU上的速度通常是原来的1/5~1/2(尽管计算成本相同)。如果无法使用cuDNN,有一种方法可以加快RNN层的运行速度,那就是将RNN层展开(unroll)。展开for循环是指去掉循环,将循环中的内容重复相应次。对于RNN的for循环,展开有助于TensorFlow对底层计算图进行优化。然而,这样做也会大大增加RNN的内存消耗,因此,它只适用于相对较小的序列(大约100个时间步或更少)。另外请注意,只有当模型事先知道数据中的时间步数时(也就是说,向初始Input()传入的shape不包含None),才能使用这种方法。它的工作原理如下。
inputs = keras.Input(shape=(sequence_length, num_features)) ←---- sequence_length不能是None
x = layers.LSTM(32, recurrent_dropout=0.2, unroll=True)(inputs) ←----传入unroll=True将该层展开
循环层堆叠
模型不再过拟合,但似乎遇到了性能瓶颈,所以我们应该考虑增加神经网络的容量和表示能力。回想一下机器学习的通用工作流程,增大模型容量通常是好的做法,直到过拟合成为主要障碍(假设你已经采取了基本措施来降低过拟合,比如使用dropout)。只要过拟合不是太严重,那么模型就很可能容量不足。增加网络容量的通常做法是增加每层单元个数或添加更多的层。循环层堆叠是构建更加强大的循环网络的经典方法,比如,不久之前谷歌翻译算法就是7个大型LSTM层的堆叠—这个模型很大。在Keras中堆叠循环层,所有中间层都应该返回完整的输出序列(一个3阶张量),而不是只返回最后一个时间步的输出。前面说过,这可以通过指定return_sequences=True来实现。在下面这个示例中,我们尝试堆叠两个使用dropout正则化的循环层,如代码清单10-23所示。不同的是,我们将使用门控循环单元(gated recurrent unit,GRU)层代替LSTM层。GRU与LSTM非常类似,你可以将其看作LSTM架构的精简版本。它由Kyunghyun Cho等人于2014年提出,当时RNN刚刚开始在不大的研究群体中重新引起人们的兴趣。
代码清单10-23 训练并评估一个使用dropout正则化的堆叠GRU模型
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.GRU(32, recurrent_dropout=0.5, return_sequences=True)(inputs)
x = layers.GRU(32, recurrent_dropout=0.5)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_stacked_gru_dropout.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=50,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_stacked_gru_dropout.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")
模型结果如图10-12所示。测试MAE为2.39摄氏度(比基准改进了8.8%)。可以看到,增加一层确实对结果有所改进,但效果并不明显。此时你可能会发现,增加网络容量的回报在逐渐减小。