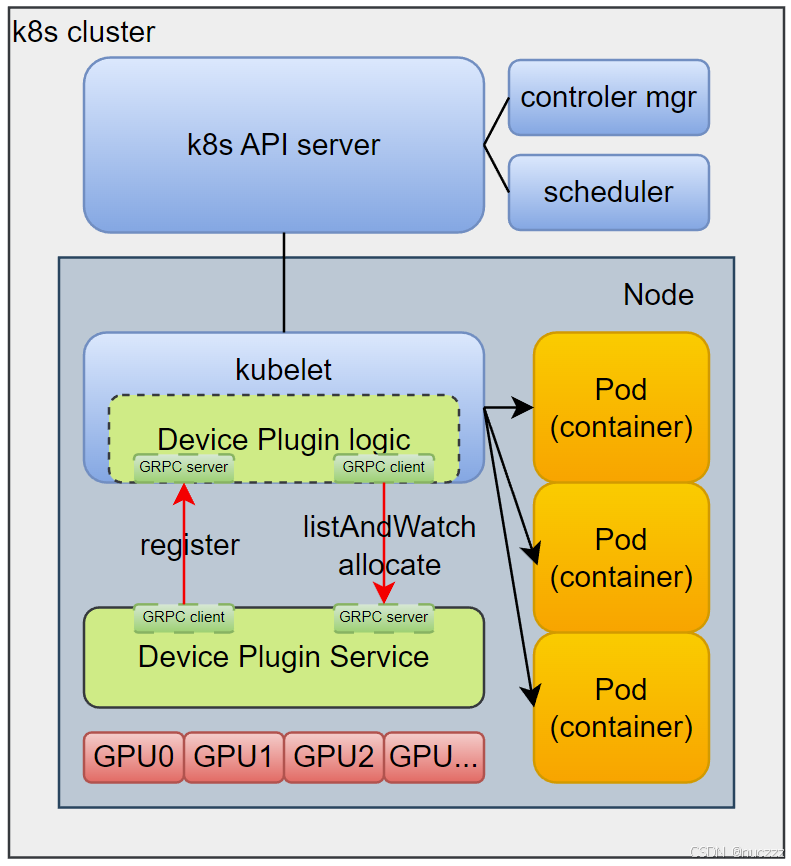
主流大语言模型中Token的生成过程本质是串行的
flyfish
1. 串行生成
-
自回归模型的核心逻辑:
大模型(如GPT-2)采用自回归架构,每个Token的生成必须基于已生成的完整历史序列。例如,生成“今天天气很好”时:输入:<start> 输出1:"今" → 输入更新:<start>今 输出2:"天" → 输入更新:<start>今天 输出3:"天" → 输入更新:<start>今天天 ...(重复或乱码可能因模型困惑导致)每个Token的生成必须依赖前一步的结果,形成严格的链式依赖。
-
计算与生成的分离:
虽然模型内部的矩阵运算(如注意力计算)通过GPU并行加速,但生成顺序必须严格串行。例如:- 第1步:计算第一个Token的概率分布(基于空输入)。
- 第2步:将第一个Token加入输入,计算第二个Token的概率分布。
- 依此类推,无法跳过或提前生成后续Token。
例如:
# 假设模型需生成 "ABC"
步骤1:生成A(依赖空输入)
步骤2:生成B(依赖A)
步骤3:生成C(依赖A+B)
即使步骤1和步骤2的计算在硬件层面并行,生成顺序仍必须是A→B→C。
2. 优化方法的局限性
Beam Search等算法通过维护多个候选序列提升效率,但本质仍是串行生成:
# Beam Search示例(Beam Size=2)
步骤1:生成2个候选("今", "天")
步骤2:基于每个候选生成下一个Token(如"今天" → "气","天天" → "气")
步骤3:依此类推,每次扩展候选序列的长度
每个候选序列的Token仍需按顺序生成,无法并行生成整个序列。
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载 GPT-2 模型和分词器
model_path = r"gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)
input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 使用 top - k 采样生成文本
output = model.generate(
input_ids,
max_length=20,
top_k=50,
temperature=0.7
)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("生成的文本:", generated_text)
生成的文本: Once upon a time, the world was a place of great beauty and great danger. The world was
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载 GPT-2 模型和分词器
model_path = r"gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)
# 输入文本
input_text = "Once upon a time"
# 对输入文本进行分词
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 初始化生成的序列
generated_sequence = input_ids
# 定义最大生成长度
max_length = 20
print("顺序生成的 token:")
for step in range(max_length):
# 使用模型进行预测
with torch.no_grad():
outputs = model(generated_sequence)
logits = outputs.logits[:, -1, :] # 获取最后一个 token 的预测结果
# 选择概率最大的 token
next_token_id = torch.argmax(logits, dim=-1).unsqueeze(0)
# 将生成的 token 添加到序列中
generated_sequence = torch.cat([generated_sequence, next_token_id], dim=-1)
# 解码并打印生成的 token 及其位置
next_token = tokenizer.decode(next_token_id[0].item())
print(f"步骤 {step + 1}: 生成 token '{next_token}',当前序列长度: {generated_sequence.shape[1]}")
# 解码并打印完整的生成序列
generated_text = tokenizer.decode(generated_sequence[0], skip_special_tokens=True)
print("\n完整生成的文本:", generated_text)
顺序生成的 token:
步骤 1: 生成 token ',',当前序列长度: 5
步骤 2: 生成 token ' the',当前序列长度: 6
步骤 3: 生成 token ' world',当前序列长度: 7
步骤 4: 生成 token ' was',当前序列长度: 8
步骤 5: 生成 token ' a',当前序列长度: 9
步骤 6: 生成 token ' place',当前序列长度: 10
步骤 7: 生成 token ' of',当前序列长度: 11
步骤 8: 生成 token ' great',当前序列长度: 12
步骤 9: 生成 token ' beauty',当前序列长度: 13
步骤 10: 生成 token ' and',当前序列长度: 14
步骤 11: 生成 token ' great',当前序列长度: 15
步骤 12: 生成 token ' danger',当前序列长度: 16
步骤 13: 生成 token '.',当前序列长度: 17
步骤 14: 生成 token ' The',当前序列长度: 18
步骤 15: 生成 token ' world',当前序列长度: 19
步骤 16: 生成 token ' was',当前序列长度: 20
步骤 17: 生成 token ' a',当前序列长度: 21
步骤 18: 生成 token ' place',当前序列长度: 22
步骤 19: 生成 token ' of',当前序列长度: 23
自回归架构是许多大语言模型顺序生成Token的根本原因,并且其链式依赖特性确实有助于确保生成过程的逻辑连贯性。
自回归架构与Token生成
-
自回归机制:
- 在自回归模型中,比如GPT系列模型,生成下一个Token的过程依赖于前面已经生成的所有Token。具体来说,生成第 t t t个Token时,模型会基于前 t − 1 t-1 t−1个Token来计算概率分布,然后从中采样或选择最有可能的下一个Token。
- 这种链式依赖关系(即每个Token的生成依赖于之前的全部或部分Token)保证了文本生成的逻辑一致性和连贯性。
-
串行生成 vs 并行生成:
- 串行生成:传统的大语言模型如GPT系列,在推理阶段通常是逐个Token串行生成的。这是因为每个新Token的生成都需要利用到之前所有已生成的Token作为上下文输入,这种依赖关系限制了并行处理的可能性。
- 尝试并行化:尽管存在一些研究和方法试图提高生成效率,例如通过投机解码(Speculative Decoding)或者使用多个模型同时预测不同位置的Token,但这些方法并没有完全改变基本的自回归生成机制。大多数情况下,核心的Token生成步骤仍然是串行进行的,因为当前Token的生成必须等待前面的Token确定下来才能开始。
3. 数学本质的"自相关性"
自回归(Autoregressive)模型中的"自",自回归的核心在于当前输出仅依赖于自身历史输出。用数学公式表示为:
x
t
=
ϕ
1
x
t
−
1
+
ϕ
2
x
t
−
2
+
⋯
+
ϕ
p
x
t
−
p
+
ϵ
t
x_t = \phi_1 x_{t-1} + \phi_2 x_{t-2} + \dots + \phi_p x_{t-p} + \epsilon_t
xt=ϕ1xt−1+ϕ2xt−2+⋯+ϕpxt−p+ϵt
- 自相关性:模型通过自身序列的滞后项( x t − 1 , x t − 2 x_{t-1}, x_{t-2} xt−1,xt−2等)预测当前值
- 内生性:所有变量均来自同一序列,区别于普通回归模型中的外生变量
例如,股票价格预测模型中, x t x_t xt(今日股价)仅依赖于过去5天的股价( x t − 1 x_{t-1} xt−1到 x t − 5 x_{t-5} xt−5),而非外部因素如新闻、财报等。
4. 生成过程的"自我迭代"
在自然语言处理中,这种"自"特性体现为:
- 链式生成:每个Token的生成必须基于已生成的Token序列
- 因果掩码:Transformer架构中,每个位置i的注意力被限制在1到i-1的位置
- 动态更新:每生成一个Token,模型的内部状态(隐藏层激活值)会被更新
以GPT-2生成句子为例:
输入:"今天天气"
生成过程:
1. 预测第一个Token:"很"(基于"今天天气")
2. 预测第二个Token:"好"(基于"今天天气很")
3. 预测第三个Token:"啊"(基于"今天天气很好")
5. 与其他模型的对比
| 模型类型 | 是否"自"依赖 | 典型应用场景 |
|---|---|---|
| 自回归模型 | 仅依赖自身历史 | 文本生成、时间序列预测 |
| 非自回归模型 | 不依赖自身历史 | 图像超分辨率、语音识别 |
| 混合模型 | 部分依赖自身历史 | 对话系统(结合外部知识) |