文章目录
- 概要
- 整体架构流程
- 前期的技术探索
- 技术构造
- 技术细节
- 小结
概要
根据之前博客使用的docker技术,如果换公司了,我可能就要重新搭建环境了,哎,公司没资源给我,给我一台带不走的电脑,哎,这可是我这种数据科学人调试好的电脑,这套服务就值几千了。
算了,留着给他们玩吧,深度学习他们姑且也听不懂,和天书一样,我现在要实现一个RAG和一个简单的模型微调,ChatGLM6B,感谢清华团队的开源,让我这种穷逼也能玩一下大模型,我还是非常尊敬知识的。
虽然知道模型的架构什么样,但是我不配玩,所以我现在在创造大模型方面一点经验都没有。
目前,为了纪念我离开这家经过我父亲推荐我过来的这家公司,我会做一个接入公司文档的服务给他们用,本来我还在想要不要做一整套GIS服务的系统给他们,不过看这边的技术人员都走的差不多了,那我还不如趁此把大模型微调的经验积累一下,然后离开这家让我成长但在工资待遇上没有给我太多帮助的公司,我首先还是要感谢我的父母,至少我还是成长了,不然我就要用技术开发AI黑客攻击了,我有这个实力,不过现在我也释然了,一切的命运都有定数罢了,既然不让我在这个国家过的好,估计后面我会在国外玩起来吧,死在国外我也不拍,死了就死了而已,人生对我来说就是玩。
不过想想也是,我总算知道李白为什么那么痛苦了,人生得意须尽欢,有了技术就是搞破坏,反正我有技术用不到正途,那就用到别处去。
整体架构流程
搜索资料以及问AI这构思玩意,主要提到的技术有
RAG技术
大模型微调技术
前后端技术
主要功能
RAG技术建立公司文档知识库,每天定时任务,处理所有文档并使用WordVec进行向量化导入到PostgresSQL。
前期的技术探索
了解什么是模型?
先随便了解一下Qwen1.5B模型的架构
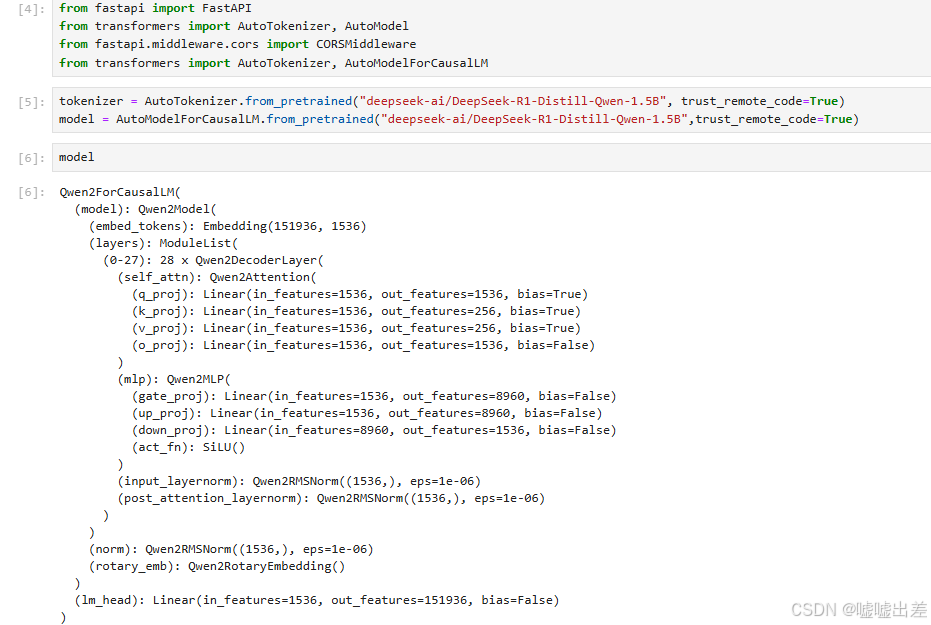
门控卷积,MLP,以及输出头,Embadding这些玩意都需要一个一个了解,不过这些东西只是架构罢了,他们也是一点一点证明这些架构有什么用的,聚合信息,跳转信息,都是实验的结果,想了解这些架构得自己看实验结果去,基本上每人会去研究这些架构,全是一些调用API的玩意,技术也就只有业务技术了,全是死玩意。
q,k,v,o这个架构很经典,想学深一点可以去学学,我玩图像的深度学习的时候玩出花来。
tokenizer这个东西,怎么看?
我用代码来解释一下,这玩意你可以称之为“翻译官”,模型就是“歪果仁”
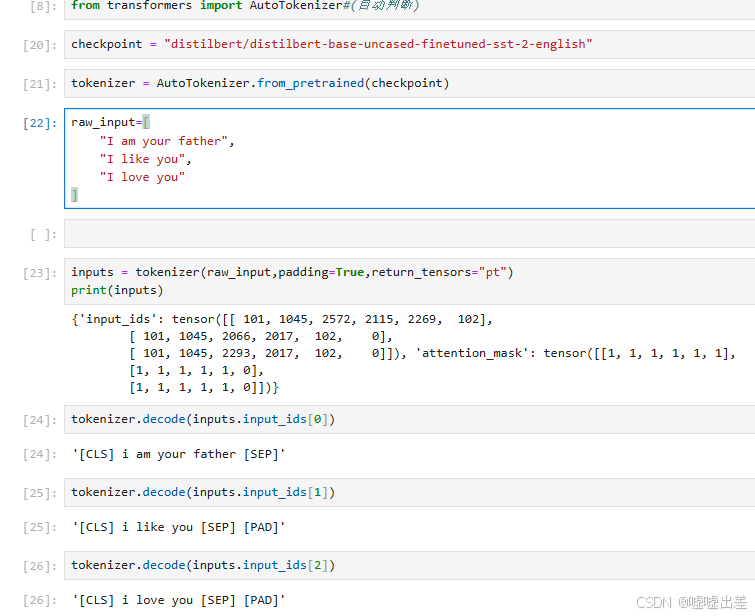
里面raw_input的句子被变成了机器种族的数字语言,然后我又叫翻译官给我又翻译回来,数字上的零就是翻译官翻译时的pad,意思是填充,attention_mask,就是指注意力掩码,像填充的pad就是0,意思是不配被注视。
想微调模型要学会什么?
答案是做数据集,不过我们要先尝试,后续再把数据处理流程给写光,不过如果是以前,人们都要苦于怎么做dataset,但是transformer有它的DataCollatorWithPadding,这极大的帮助了人们,但不知道的就要遭罪喽。
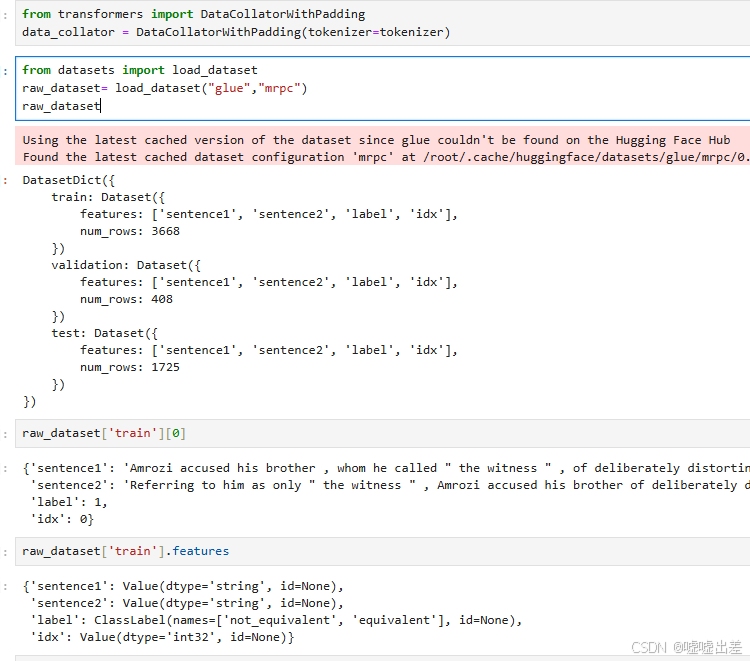
这个数据集,只有句子1,句子2,标签(情感分析的标签),以及有利于管理的idx。
通过tokenier翻译官把数据集变成机器种族的语言,就能开始我们的训练了,这也叫微调。
训练是什么玩意?
额,没亲手写过代码的肯定不清楚训练干了什么,如果连训练的概念都不知道,我只能说,别学这玩意了,因为人家一点机会都不给你,早早就封装了这个库,几行代码就可以开始训练和微调。
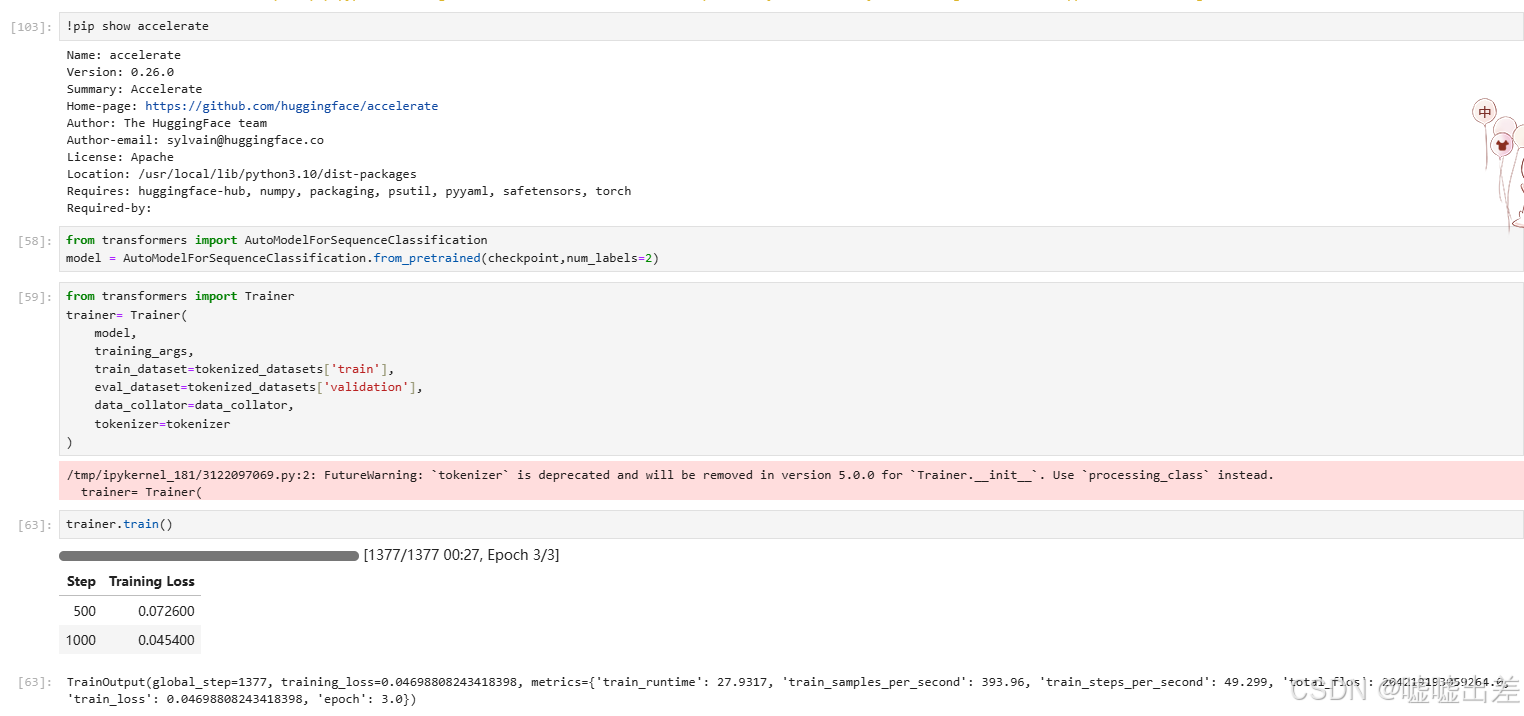
前沿的技术已经决定了如何更好的更深刻的了解大模型,不过我也没办法,大模型太大了我玩不了,我只能玩小模型。
技术构造
我有看过大模型微调,似乎现在用到的是LLama-Factory,所以我直接docker给它拉过来
进入容器并启动WebUI
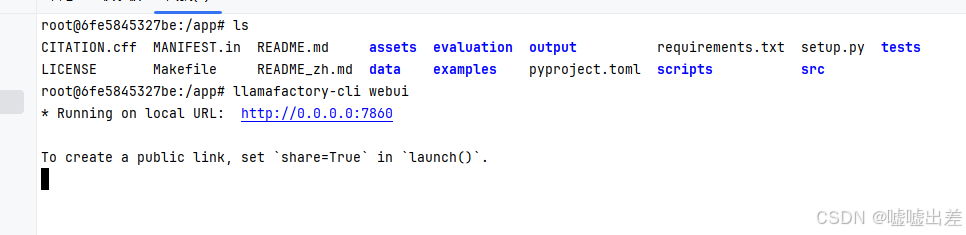
打开后就是微调、训练等的界面
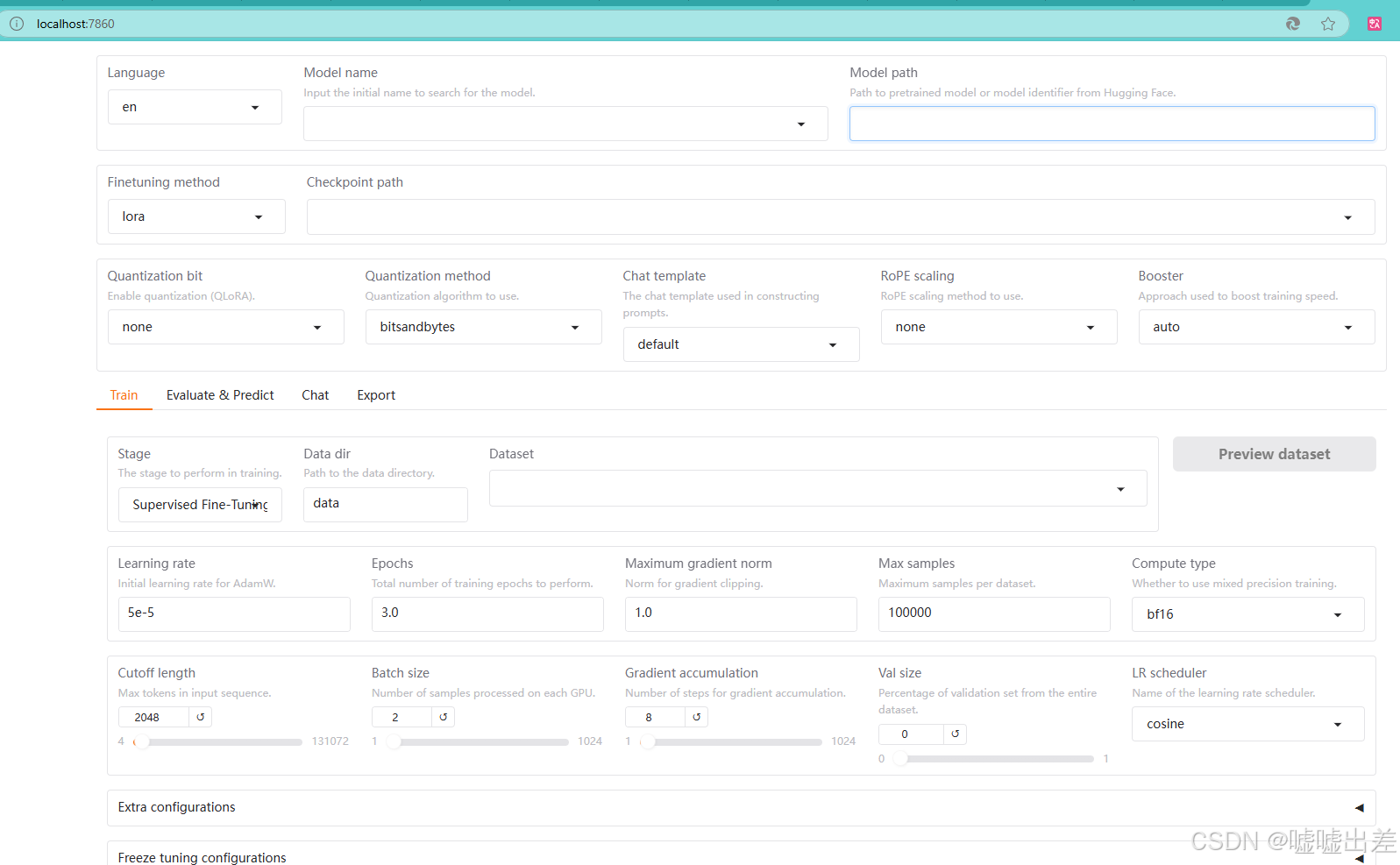
点开模型可以看到那群公司要的Deepseek
说实话,没学过训练的可能都能来训练,至于设备会不会坏就不是我的事了,把数据集准备好,模型下载好,参数和一些方法选一下,一个简单的训练器就完成了,如果说是个水硕出来,当当调参侠也挺好的,只是不会怎么写这种代码而已,不过这个东西已经是集成了很多优点了,小孩子只要会选择,就能当一个大模型的微调师傅,叫手下人把参数都选好,当最后那个点击训练的人哈哈哈。
技术细节
我肯定不会写一些烂技术,不过这个技术可以给人培养兴趣,毕竟只有看到了结果,才有可能有兴趣去做事。
主要技术内容:提示工程、RAG、微调、更换大模型、使用多模态大模型

我用PPT随便画了一个架构图
后续我会开发一个基于ChatGLM来做的模型微调实验,供大家伙有一个模型微调的经验
小结
前期的探索已完成,后续直接进行开发系统














![[Windows] 批量为视频或者音频生成字幕 video subtitle master 1.5.2](https://i-blog.csdnimg.cn/direct/a2054854ba8b48bf8d7ca828340deb9f.png)