目录
文章目录
- 目录
- RoCE
- RoCEv2 v.s. IB
- RoCEv2 协议栈
- RoCEv2 需要 Lossless Network
- Lossless Network 拥塞控制技术
- 网络拥塞的原因
- PFC 基于优先级的流量控制
- PFC Unfairness (带宽分配不公平)的问题
- PFC HOL(队头拥塞)的问题
- PFC Deadlock(死锁)的问题
- PFC Storm(风暴)的问题
- ECN 显式拥塞通知拥塞控制
- ECN 拥塞控制滞后的问题
- Lossless Network 多路径传输技术
RoCE
RDMA 协议栈最早在 Infiniband 网络设备上实现,但由于 IB 网络一家独大且价格昂贵,所以业界设备厂商组成 RDMA Consortium 联盟,意图把 RDMA 协议栈移植到更广泛的 Ethernet 网络上,以此来对抗技术垄断和抢占市场份额。
2010 年,以 IEEE/IETF 组织为媒介发布了基于传统以太网的 RDMA 协议栈,即:RoCE(RDMA over Converged Ethernet,基于聚合以太网的 RDMA 协议)。

RoCEv2 v.s. IB
优势:
- IB 成本的 25%
- 开放生态好,设备厂商多,自研空间大
劣势:
3. RoCEv2 性能更低
4. IB 采用基于 credit token 的无损网络;RoCEv2 采用基于 PFC/ECN 的无损网络。后者运维难度大,网管要求高,需要投入更多的 RD 和 OP 成本。


RoCEv2 协议栈
RoCE 协议栈的发展经历了 v1、v2 这两个版本,其中:
-
RoCEv1:只有 L2 采用了 IEEE 802.3 标准的 Ethernet Header,L3 依旧使用的是 IB GRH Header,所以无法应用于部署了 IB Router 的网络中进行 L3 Subnet 的跨子网通信,而是只能应用于一个 L2 LAN(同时只允许在同一个 VLAN 中的两台主机进行 RoCEV1 通信 ),应用场景非常受限。
-
RoCEv2:L3 使用 IP/UDP Header 封装,克服了 RoCEv1 的缺陷,可以实现 L3 Subnet 之间的通信。同时,由于 UDP 支持基于 srcPort 的 HASH,所以也解决了 ECMP 负载均衡等问题。
RoCEv2 由于其性价比优势,目前已经逐渐成为了 RDMA 的主流实现,以 NVIDIA/Mellanox、Intel 为代表的 RNIC 厂商,均已经支持 RoCEv2 的硬件卸载能力。

RoCEv2 需要 Lossless Network
实际上,RDMA over RoCEv2 对丢包率(网络抖动)非常敏感,有以下主要原因:
-
RoCEv2 L3 使用了无连接、非可靠的 UDP 作为封装协议。相对于 TCP 而言,UDP 的优势是速度快、占用 CPU 资源少,避免了 TCP 协议重传机制导致的网络拥塞加剧问题。相对的,UDP 的缺点是没有滑动窗口、ACK 确认响应等机制来实现可靠传输。所以,UDP 协议一旦出现丢包,RoCEv2 就需要依靠上层 Application 来检查并进行重传,这会大大降低 RDMA Application 的传输效率。
-
UDP 协议没有 TCP 协议那样有分片保序机制。所以,UDP 协议要求对于同一条数据流(具有相同五元组的数据包)不得改变其收/发包的顺序。因此,一旦出现丢包,就只能采用 go back N 重传机制,比如:网络链路上已经发送了 1,2,3,4,5 个数据包,假如当 2 这包丢掉了,那么 3,4,5 这三个包都要重传,重传的成本非常大。
如下图所示,一旦发生丢包重传,RDMA 的性能就会急剧下降。例如:大于 0.001% 的丢包率,就会导致网络有效吞吐急剧下降,尤其当 0.01% 的丢包率甚至使 RDMA 的吞吐率下降为 0。要让 RDMA 满速率传输,就要让丢包率必须保证在 1e-05(十万分之一)以下,最好为零丢包。如下图所示。
由此,RoCEv2 需要依赖一个 Lossless Network 来保障 0 丢包。而网络丢包的诸多原因可以分为 2 大类,下面我们分别讨论:
- 网络拥塞(Networking Congestion):网络流量超过了 Router、Switch、RNIC 等硬件设备的处理和缓存能力而导致的丢包。
- 物理链路故障:网络物理链路断开导致的传输中断。

Lossless Network 拥塞控制技术

网络拥塞的原因
如下图所示,当主机发送到网络中的报文数量在其承载能力范围之内时,Send 和 Receive 之间的报文数量成正比例增长。直到负载接近承载能力时,就会出现急剧的网络拥塞,同时延迟也会急剧上升。

理论上,当我们拥有一个永远够用的、能力超强的网络设备缓存区时,这个网络就不会丢包。但实际上这不可能实现,有以下原因:
- 网络设备的缓冲区非常昂贵,尤其在一个大规模网络中设备数量庞大。
- 网络带宽的大小无法准确预测,例如非预期的业务高峰、网络攻击等。
具体而言,现实中的以下场景更容易导致丢包:
- 带宽收敛比不合适:从成本效益的角度出发,网络的上下行链路会设计一个非对称的带宽。这在满负载的 RoCEv2 场景中会导致丢包。所以 Lossless Network 通常采用 1:1 的上下行链路带宽收敛比。
- ECMP 大象流:网络设备会根据 IP 5-tuple 等扰动因子来进行 HASH 选路,但不会考虑所选链路本身是否拥塞,所以会存在大象流、老鼠流的场景。在 RoCEv2 分部署存储场景中尤为常见大象流导致的丢包。
- TCP Incast 多打一:如下图,当 Parent 节点同时请求一群 Node 节点后,就会出现 “多打一” 的响应数据,继而出现突发性的流量毛刺激增,造成丢包。常见于云数据中心网络,有大量的 scale-out 分布式架构应用,例如:Hadoop、MapReduce、HDFS 等。

既然无法依赖网络设备的缓冲区,那么就需要引入拥塞控制技术来控制链路上的流量大小,减轻设备缓冲区的压力,避免丢包。拥塞控制技术旨在充分利用网络带宽容量以及充分降低传输延迟的前提之下,尽可能的保障网络不会拥塞丢包。
值得注意的是,拥塞控制和流量控制有所区别:
- 流量控制:是一个局部视角,只关注收发双方之间的流量。
- 拥塞控制:是一个全局视角,保障整个网络的质量。所以拥塞控制涵盖了流量控制的部分,但需要考虑的范围更广,例如:在一个大规模的网络中要同时满足 0 丢包、低时延、高吞吐的 “博弈三角”。

PFC 基于优先级的流量控制
为了实现 RoCEv2 Lossless Network,IEEE 在 Ethernet Header 上定义了 IEEE 802.1Qbb PFC(Priority-based Flow Control,基于优先级的流量控制)协议,是 IEEE 802.3X FC 的增强版本,由 Router、Switch、NIC 等设备实现。
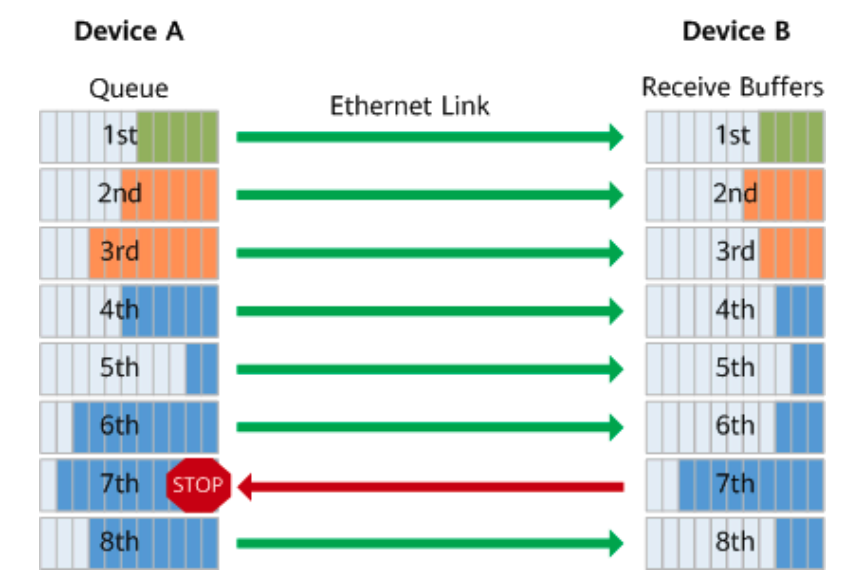
FC(Flow Control)的基本原理是当 Receiver 的 buffer queue 达到水位阈值时,就会通知 Sender 暂停发送报文,从源头截流,避免丢包(注:Receiver/Sender 指任意 Router、Switch、NIC 设备)。如下图所示,当 G0/1–2 传输 1G 流量时,F0/1–2 就会拥塞丢包。在 Switch Port 开启了 FC 之后:
- 当 F0/1 的 buffer queue 超过水位后,由 G0/2 向 G0/1 发送 XOFF PAUSE(暂停)帧,通知 G0/1 暂停一段时间(PAUSE 帧内指定),不再发出报文。
- PAUSE 帧中携带了暂停时长,G0/1 在超时老化或接收到 XON 帧之后,继续恢复报文发送。

FC 的不足在于没有对 Flow 进行分类,低价值 Flow 会影响到高价值 Flow 的转发性能。
为此,PFC 在 FC 的基础上增加了 Priority 的概念:
- PFC 为不同的 Flow 设置相应的 Priority 分类,网络设备转发报文时,通过 Priority 映射到响应的 buffer queue 中进行调度和转发。
- PFC 优先级分类机制使得低价值 Flow 的拥塞,不会影响到高价值 Flow 的正常转发。
具体的,PFC 定义了 8 条 VL(Virtual Line,虚拟通道),每条 VL 都可以设置一个 Priority,允许任意 VL 单独 Pause(暂停)和 Resume(恢复)。PFC 将流量控制从 Port 粒度细化为了 VL 粒度。支持 RoCEv2 的 RNIC 通常也会支持 PFC 协议,8 个 VL 对应到 8 个 Tx queues,分别被命名为 TC0~7(Traffic Class)。

在协议实现层面,设备可以使用 Frame Header 中的 IEEE 802.1q VLAN 中的 PCP(Priority Code Point)字段中的 3bits 来设置 Priority 值。

也可以使用 Frame Header PCP 结合 IP Header DSCP(优先级服务质量)字段来共同设置 Priority 值。如下图。目前大多数设备厂商都支持基于 DSCP 字段的 PFC。

更进一步的,IEEE 还定义了 802.1Qaz 标准 ETS(Enhanced Transmission Selection,优先级服务质量保证)字段。它是 DCB (Data Center Bridging)标准的一部分,用于将流量分配到不同的队列,为每个队列分配一个权重,控制每个流量队列能够使用的带宽百分比,保证高优先级的流量,如 RDMA 流量通常会分配足够的带宽资源。
PFC Unfairness (带宽分配不公平)的问题
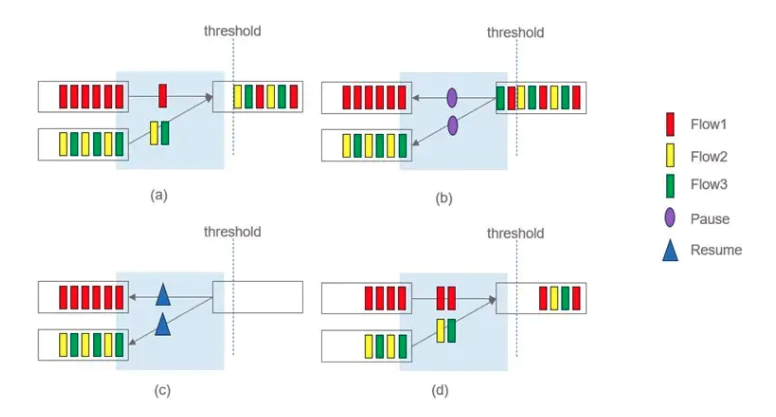
如下图:
- (a)F1、F2 和 F3 分别通过 2 个 srcPort 向同一个 dstPort 发送流量。
- (b)当 dstPort buffer 超过水线,则分别发送 PAUSE 帧给 2 个 srcPort。
- (c)当 dstPort 缓过来之后,则分别发送 XON 帧给 2 个 srcPort。
- (d)此时,F1 就会占用了比 F2、F3 更多的带宽。从而导致了不同 Flow 之间的带宽分配不公平问题。
PFC HOL(队头拥塞)的问题
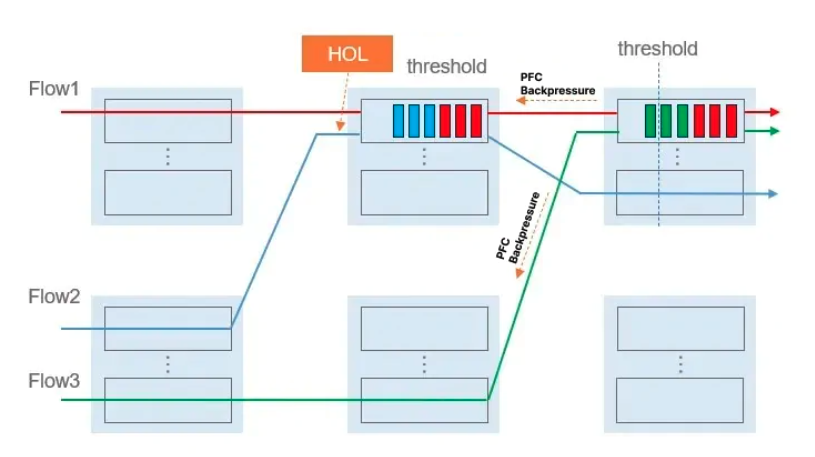
如下图:F1 和 F3 造成的 PAUSE 帧被反压到了 F2 的 Port 中,即便 F2 在整个链路中没有造成阻塞,但在某个节点中也会被它的队头 F1 影响到。
PFC Deadlock(死锁)的问题
然而,PFC 只支持一种粗粒度的报文分类,仅支持 PortNum + Priority 进行分类,不支持 Per-flow 级别的分类。所以 PFC 可能会导致拥堵蔓延现象(Congestion-spreading),进而出现 PFC Deadlock(PFC 死锁)、PFC Storm(PFC 风暴)等一系列性能问题。
PFC Deadlock 是指当多个 Switches 之间同时发生拥塞,且各 Ports 的 pkts buffer 都超过了阈值,而 Switch 之间又相互等待对方释放资源时,就出现了一种所有 Switches 上的流量被永久阻塞的网络状态。如下图所示。
更具体而言,当一台 Switch 拥塞时,它会反压 PAUSE 帧到上游 Switch,依次循环直到 Sender 暂停发报文为止。但在某些特殊情况下,例如链路或设备故障时,BGP 路由重新收敛过程中可能会出现的短循环,从而产生循环依赖的 PFC Decdlock。
PFC Decdlock 由于 PFC 的 PAUSE 反压效应,整个网络或部分网络的吞吐量将快速跌零。并且,即使在无环路的网络中形成了短环路,也有可能产生 Decdlock。

要解除 PFC Deadlock 问题,一方面需要网络做好环路预防,另一方面需要网络设备的网管平台支持 PFC Deadlock 检测功能,可以检测出 Deadlock 状态后的某个时间里忽略收到的 PFC PAUSH 帧,对 buffer 中的报文进行转发或者丢弃。例如:可以配置定时器每 10ms 检查 1 次,共 10 次,是否都收到了 PFC PAUSE 帧,如果是则说明产生了死锁。
PFC Storm(风暴)的问题
前面提到,PFC 反压会产生死锁等严重问题,尤其在大规模组网的场景,PFC PAUSH 反压报文会形成风暴。
避免全网 PFC 风暴的手段之一就是控制组网规模,例如千节点以内的规模,将 RDMA 网络约束在一个 Fabric POD 内部署。但显然的这里面存在 2 个问题:
- 规模受限,在云计算场景中增加了管理复杂度。
- 云盘业务网络要求计算和存储节点在同一个 POD 内,会导致不同 POD 间资源无法共享。
ECN 显式拥塞通知拥塞控制
PFC 存在 Deadlock、Storm 等问题的本质是无法精确管理每条 Flow,只能粗暴的关闭流量,而不能动态调整发送速率。另外,由于 PFC 会上下游网络设备之间的层层反压,所以在大规模 Lossless Network 中,效率很低。因此,PFC 往往还需要结合更高效的拥塞控制算法,例如:ECN、DC-QCN 等,在不同的业务场景中采用合适的算法是重中之重。
ECN(Explicit Congestion Notification,显式拥塞通知)在 RoCEv2 的 L3 和 L4 层生效,是一种 E2E 的拥塞通知机制,可以有效减少拥塞的扩散和加剧。如下图所示,当网络设备一旦拥塞时,就会在 IP Header 中标记 ECN 字段。当 Receiver 接收到 ECN 标记后,就会发送 CNP(Congestion Notification Packets,拥塞通知包)消息通知 Sender 要降低发送速度。


可见,ECN 和 PFC 的本质区别在于,ECN 流控是基于 IP 单播的 E2E 流控,流控发生在 Receiver 和 Sender 之间,网络中间件如 Switch 等设备只负责打标即可。而 PFC 流控需要网络中所有的 Switches 等设备都参与流控,层层反压。

在 ECN 拥塞控制算法中,IP Header 的 ECN 字段用于打标识别拥塞,而 CNP 才是用于通知 Sender 降速的消息体。CNP 报文格式如下图所示,其作用于 IB L4 传输层的 BTH,用于指示 Sender 对指定的 QP 进行降速,而不是对整个 Port 进行降速,依旧是一种细粒度的流控。
IB L4 BTH 用于建立 Channel 连接(基于 Queue 的多路复用)、发送与接收、分片与重组报文。帮助 Receiver 理解该 RDMA 报文属于哪个 Channel 以及如何处理接收到的报文,包括验证报文的顺序、识别操作类型等等。
- OpCode(操作码):8bit。
- 前 3bit 代表服务类型,有:RC 可靠连接、UC 不可靠连接、RD 可靠数据报、UD 不可靠数据报、RAW 数据报等类型;
- 后 5bit 代表操作类型,有:SEND、RECEVICE、READ、WRITE、ACK 等类型。
- Partition Key(分区键):在 IB 网络中用于将一个 RDMA 网络分为多个逻辑分区。而在 RoCEv2 网络中,则可以采用 VxLAN 技术代替。
- ECN(显示拥塞通知):在 IB 网络中用于拥塞控制,包含 Forward 和 Backward 两个 bit,分别表示在发送和返回路径上遇到了拥塞。在 RoCEv2 中被 IP Header 中的 ECN 字段代替。
- Destination QP(Queue Pair Number):与 TCP Port num 类似,用于标识一个多路复用的 RDMA Channel 的目的端。与 TCP Port num 不同的是,一个 QP 由 Send/Recv 两个队列组成,使用同一个号码标识。
- Packet Sequence Number(包序列号):与 TCP 序列号类似,用于检查 RDMA 报文的传输顺序,可靠传输时生效。

ECN 的基本工作流程如下:
- Sender 发送的 IP 报文支持 ECN(10);
- Switch 在拥塞的情况下收到该 IP 报文,并将 ECN(10) 改为 ECN(11) 并转发,网络中其他 Switch 会透传该报文。
- Receiver 收到 ECN(11) 报文,识别拥塞。
- Receiver 向 Sender 每 ms 发送一个 CNP 消息,ECN(01),指示降速的 DestQP。
- Switch 正常转发 CNP 消息,该消息不会被网络丢弃。
- Sender 收到 ECN(01) 后,解析报文,并对相应 RDMA QP 应用限速算法。

- https://enterprise-support.nvidia.com/s/article/rocev2-cnp-packet-format-example
ECN 拥塞控制滞后的问题
值得注意的是,尽管有 ECN 算法来缓解 PFC 的不足,但 ECN 依旧存在 “响应速度慢”、不能根除 “网络拥塞控制滞后” 的问题。因为,拥塞标记首先要经过数跳 Switches 到达 Receiver,然后 CNP 也要再经过数跳 Switches 到达 Sender,最后才开始降速。这之间显然存在至少一个 RTT(Round-Trip Time,传输往返时间)的 “滞后”,也会存在 CNP 丢包和重传的情况。所以,在 “流量毛刺” 和 “严重拥塞” 的场景中,需要使用 Fast ECN、Fast CNP 等辅助技术来防止在降速之前就丢包了。
而相对的 PFC 响应速度快,因为 PFC 直接影响上联设备,但 PFC Unfairness、HOL 等问题,所以 PFC 应该作为最后的兜底保证。在带宽容量水位设计时,通常会让 ECN 的缓冲水位低于 PFC,使 ECN 先于 PFC 触发,即:先让 Sender Host 主动降速,实在不行,再让网络设备反压降速,此时整个网络的吞吐性能会降低,但不再丢包。
可见,高效的 HPN Lossless 网络往往需要一个非常强大的网管平台提供监控、告警、下配、可视化等运维支撑,尤其网络的规模越大,跳数越多,越难以管控。目前业界仍在不断探索更优的 CC 方案,例如:
- 基于 WRED/ECN 的 CC:微软 DC-QCN
- 基于 Credit 的 CC:NVIDIA Infiniband
- 基于 INT 的 CC:阿里云 HPCC
- 基于 RTT 的 CC:Google TIMELY 和 AWS SRD
Lossless Network 多路径传输技术
现代数据中心广泛采用了 CLOS 网络架构,使用大量的 Switchs 在 Servers 之间构造出 ECMP(Equal Cost Multiple Path,等价多条路径),继而实现大规模的无阻塞网络。但是,由于 ECMP 本身是一种 Stateless(无状态)的局部负载均衡决策机制,适用于老鼠流且流的数量多的场景,而不适用于大象流且流数量比较少的场景。
在后一种场景中,由于 ECMP 很容易将多个大象流 HASH 到同一个路径中,尤其在有网络链路发生故障时,所以 ECMP 往往会造成路径冲撞,进而导致链路带宽无法被均衡且充分的利用,进而造成业务性能较大程度的下降。为了缓解这一问题,可以采用 Multi-path RDMA(RDMA 的多路径传输)技术,将 HASH 打散的粒度从 IP 5-tuple 更细化为 Packet 粒度。
先进 Switch 支持 AR 技术,可以实现将一条 Flow 中的所有 Packets 都分散到多个等价路径上。但值得注意的是,AR 技术异常依赖 Lossless Network,因为基于 Packets 粒度的打散,如果丢包就会极大地提高了乱序的可能性,尤其不适用于跨 AZ 的远程传输场景。
对此,相关的研究提出结合 RNIC 上实现的 Multi-path 传输层逻辑进行报文组装处理,例如:拥塞感知的流量切分、解决接收端乱序(out-of-order)等。具体思想可以参考微软亚研院的工作《Multi-Path Transport for RDMA in Datacenters,NSDI 2018》。



















